引言
RetroMAE,中文题目为 通过掩码自编码器预训练面向检索的语言模型。
尽管现在已经在许多重要的自然语言处理任务上进行了预训练,但对于密集检索来说,仍然需要探索有效的预训练策略。
本篇工作,作者提出RetroMAE,一个新的基于掩码自编码器(Masked Auto-Encoder,MAE)的面向检索的预训练范式。主要有三个关键设计:
- 一个新颖的MAE工作流,其中输入句子用不同的掩码进行了编码器和解码器的污染(pollute)。句子的嵌入是从编码器的掩码输入中生成的,然后,根据句子嵌入和解码器的掩码输入通过MLM来恢复成原始句子。
- 使用不对称的模型结构,采用类BERT的Transformer作为编码器,单层Transformer作为解码器。
- 使用不对称的掩码率,对于编码器使用1530%的掩码率,解码器使用5070%。
总体介绍
越来越多的研究关注于开发检索导向的预训练模型。一种流行的策略是利用对比学习,模型通过训练来区分正负样本和数据增强。然而,对比学习受限于数据增强的质量。此外,需要大量的负样本。
另一种策略依赖于自编码,它不受数据增强和负采样的限制。但如何探索更有效的检索导向的自编码框架仍然是一个开放问题。
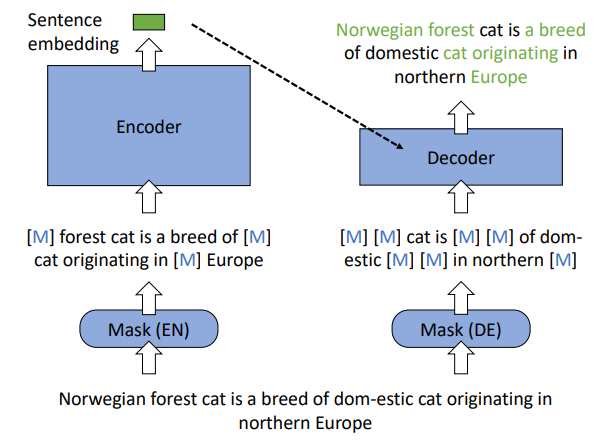
作者认为对于基于自编码的预训练需要考虑两个关键因素: 1) 重构任务必须对






![[H5动画制作系列]坐标转化问题一次搞清,一了百了](https://img-blog.csdnimg.cn/45839170544b4cf292e242a498fb82b3.png)