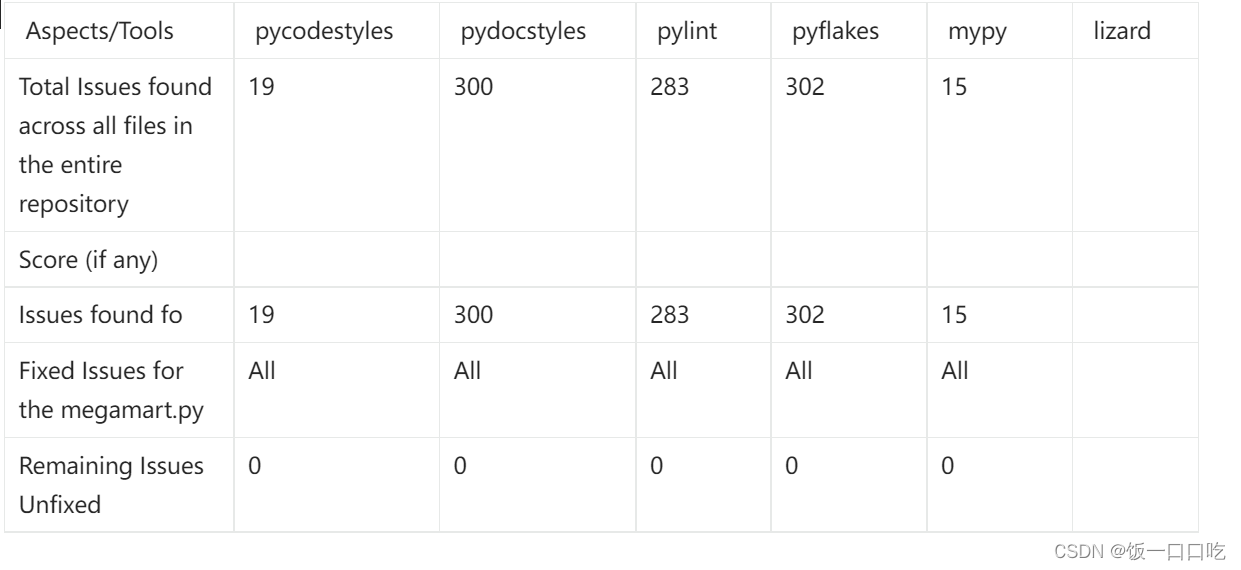
下文是用requests库编写的爬虫程序,用于爬取toutiao上的图片。程序使用了代理服务器,代理服务器的地址为duoip,端口号为8000。

import requests
from bs4 import BeautifulSoup# 设置代理服务器
proxy_host = 'duoip'
proxy_port = 8000
proxy = {'http': 'http://' + proxy_host + ':' + str(proxy_port),'https': 'http://' + proxy_host + ':' + str(proxy_port)}# 发送GET请求
url = 'toutiao'
response = requests.get(url, proxies=proxy)# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')# 找到所有img标签
images = soup.find_all('img')# 打印图片的src属性
for image in images:print(image.get('src'))
这个程序首先设置了代理服务器,然后使用requests库发送了一个GET请求到toutiao。请求使用了设置的代理服务器。然后,使用BeautifulSoup库解析了返回的HTML内容。最后,程序找到了所有img标签,并打印出了它们的src属性,这些属性就是图片的URL。