目录
程序地址空间回顾
进程地址空间
宏观理解
谈细节
1、进程地址空间究竟是什么?
2、管理地址空间
3、页表
总结几个问题:
1、为什么要有进程地址空间?
2、进程切换
3、进程具有独立性,怎么做到的?
程序地址空间回顾
我们之前学习C语言的时候,应该见过下面的空间布局图

现在我问大家一个问题,这个东西是内存吗?其实不是!我们这里先把它叫做地址空间。是什么地址空间后面再来说。
现在我们先来用代码验证一下上面这张图。
代码:
1 #include<stdio.h>2 #include<stdlib.h>3 4 int g_val_1;5 int g_val_2 = 100;6 int main()7 {8 printf("code addr: %p\n", main);//代码区9 const char *str = "hello bit";10 printf("read only string addr: %p\n", str);//字符常量区,str存放的是字符串首元素的地址,也就是h的地址11 printf("init global value addr: %p\n", &g_val_2);//已初始化全局变量12 printf("uninit global value addr: %p\n", &g_val_1);//未初始化全局变量13 char *mem = (char*)malloc(100);14 char *mem1 = (char*)malloc(100);15 char *mem2 = (char*)malloc(100);16 printf("heap addr: %p\n", mem);//堆区,这里直接打印men就行,因为要的是堆区地址17 printf("heap addr: %p\n", mem1);18 printf("heap addr: %p\n", mem2);19 printf("stack addr: %p\n", &str);//str是在main中创建的,所以是str的地址是栈上创建的20 printf("stack addr: %p\n", &mem);//mem是在main中创建的,所以是mem的地址是栈上创建的21 int a = 0;22 int b;23 int c;24 printf("a = stack addr: %p\n", &a);25 printf("stack addr: %p\n", &b);26 printf("stack addr: %p\n", &c);27 28 return 0;29 }
~
运行结果:

我们在上面代码中把变量a改为static变量
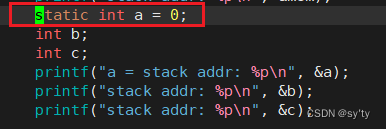
运行结果:

我们发现static修饰的局部变量的地址是在全局数据区的,也就是说虽然static修饰的局部变量作用域是在函数内,但是他的声明周期已经是全局变量了。
我们再来看下面这一段代码:
1: myproc.c ⮀ ⮂⮂ buffers 1 #include<stdio.h> 2 #include<stdlib.h> 3 #include<unistd.h> 4 5 int g_val = 100; 6 7 int main() 8 { 9 pid_t id = fork(); 10 if(id == 0) 11 { 12 int cnt = 5; 13 // 子进程 14 while(1) 15 { 16 printf("i am child, pid : %d, ppid : %d, g_val: %d, &g_val: %p\n", getpid(), getppid(), g_val, &g_val); 17 sleep(1); 18 if(cnt) cnt--; 19 else { 20 g_val=200; 21 printf("子进程change g_val : 100->200\n"); 22 cnt--; 23 } 24 } 25 } 26 else 27 { 28 // 父进程 29 while(1) 30 { 31 printf("i am parent, pid : %d, ppid : %d, g_val: %d, &g_val: %p\n", getpid(), getppid(), g_val, &g_val); 32 sleep(1); 33 } 34 } return 0; 35 } 运行结果:
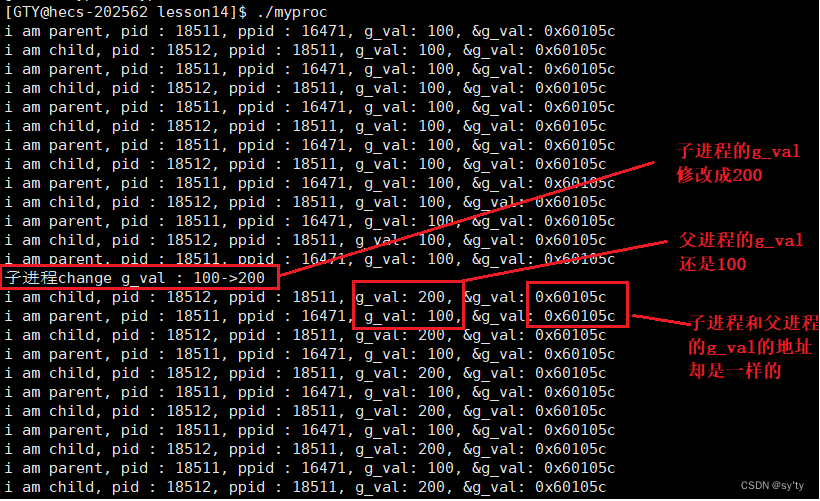
看完结果我们会有疑问:怎么可能父子进程中g_val变量的地址是一样的,同时读取,打印出来的值却是不一样的。
如果变量的地址是物理地址,是不可能存在上面的现象的。
所以我们这里先给出以下结论:
- 变量内容不一样,所以父子进程输出的变量绝对不是同一个变量
- 但地址值是一样的,说明绝对不可能是物理地址。
- 在Linux地址下,这种地址叫做 虚拟地址
- 我们在用C/C++语言所看到的地址,全部都是虚拟地址!物理地址,用户一概看不到,由OS统一管理。
注意:OS必须负责将 虚拟地址 转化成 物理地址
进程地址空间
宏观理解
所以之前说‘程序的地址空间’是不准确的,准确的应该说成 进程地址空间 ,那该如何理解呢?
我们来看下面这张图并从宏观层面上理解上面遗留的问题——为什么父子进程中g_val变量的地址是一样的,同时读取,打印出来的值却是不一样的?

- 每个进程=内核数据结构(task_struct&&地址空间(mm_struct)&&页表)+程序的代码和数据。
- 页表是一个key value结构,地址空间的虚拟地址可以通过页表映射到物理内存当中的物理地址。
当子进程要对g_val进行修改时,操作系统识别到子进程要将“0x60105c”进行写入,然后就通过页表映射到对应物理地址。但是操作系统发现,这段物理地址是和父进程共享的。因为进程是具有独立性的,修改数据的时候不能影响到对方,操作系统进行了写时拷贝(是由操作系统自动完成的),这里写时拷贝的本质其实就是在物理内存重新开辟了一段空间,然后将子进程的虚拟地址指向新的物理地址。然后再将g_val修改成200。
注意:在这个过程中,左侧的虚拟地址是0感知的,不会影响它。
谈细节
1、进程地址空间究竟是什么?
举个例子:
我们每中国人想要游玩自己的国家,我们都有960万平方公里的空间让我们去访问,即使我们没有去过所有地方。
下面我们再来举一个例子:
有个美国富人有10亿美金,但是他的私生活比较混乱,有3个私生子。
但是每个私生子并不知道他们的父亲还有其他的私生子, 所以每个私生子都认为自己在独占大富翁的财富。
三个私生子都认为自己是独自继承老爹的10亿的,所以他们都认为自己有10亿,因此也就会出现下面这种情况:
私生子1今天说:我想买台车,老爹你给我200w吧,老爹说:没问题。
私生子2今天说:我想买块表,老爹你给我40w吧,老爹说:没问题。
私生子3今天说:我想娶个老婆,老爹你先给100w吧,老爹说:没问题。
因为他们三个都是这个富翁的私生子,富翁会去尽可能的满足他们的要求。
富翁对私生子1说:你要好好读博士,等爸爸老了之后财产就由你来继承。
富翁对私生子2说:你要好好的工作,多历练历练,积累一下工作经验,等爸爸老了之后财产就由你来继承。
富翁对私生子3说:你要好好的打篮球,成为一名职业的篮球运动员,等爸爸老了之后财产就由你来继承。
这个时候私生子1觉得自己继承了老爹的财产之后,自己就会拥有10亿,然后去投资等等行为。同样的私生子2和私生子3也会绝对自己继承了老爹的财产之后会有10亿,然后想着如何去处理这10亿。
但其实这都是富翁对私生子们画的大饼。这里的大饼就相当于进程地址空间。富翁相当于操作系统。进程就相当于这里的私生子。

总结:每个私生子都被画了一张大饼,都认为自己有10亿,但是富翁并不会把自己所以的钱给任何一个进程,也就是说每个进程都有一个地址空间,都认为自己在独占物理内存。
所以,所谓的进程地址空间,本质是一个描述进程可视范围的大小。
2、管理地址空间
地址空间本质是内核的一个数据结构对象,类似PCB一样,在Linux当中进程地址空间由结构体mm_struct实现。地址空间也是要被操作系统管理的: 先描述,再组织
那么问题又来了,如何通过mm_struct这个结构体去描述进程地址空间里面特定的区域的呢?
我们来举个例子:
小胖和小花是小学同桌,但是小胖不太讲卫生,天天鼻涕口水留个不停还往桌子上面蹭,他的同桌是一个小花,因为小胖不讲卫生,所以就特别嫌弃小胖。因此小花就拿尺子给桌子划了一条线:三八线!!!小花对小胖说:你要是越过这条线我就打你。
这里小花划线的本质其实就是——划分区域!!!
我们用c语言描述这个过程,就相当于定义一个结构体,里面存放了小胖和小花的各自的空间,我们只需要将他们的起始位置和结束位置记录下来即可。
所谓的空间区域调整变大,或者变小如何理解?
比如小胖越过38线了,小花将小胖的空间没收一部分,就只需要修改结构体中的小胖的结束位置,和小花的起始位置即可。
那我们如何判断小胖有没有越界呢?
只要当我们访问的地址不在小胖的起始位置和结束位置,就可以判断小胖越界了。
但在范围内,连续的空间中,每一个最小单位都可以有地址,这个地址可以被小胖直接使用!!!
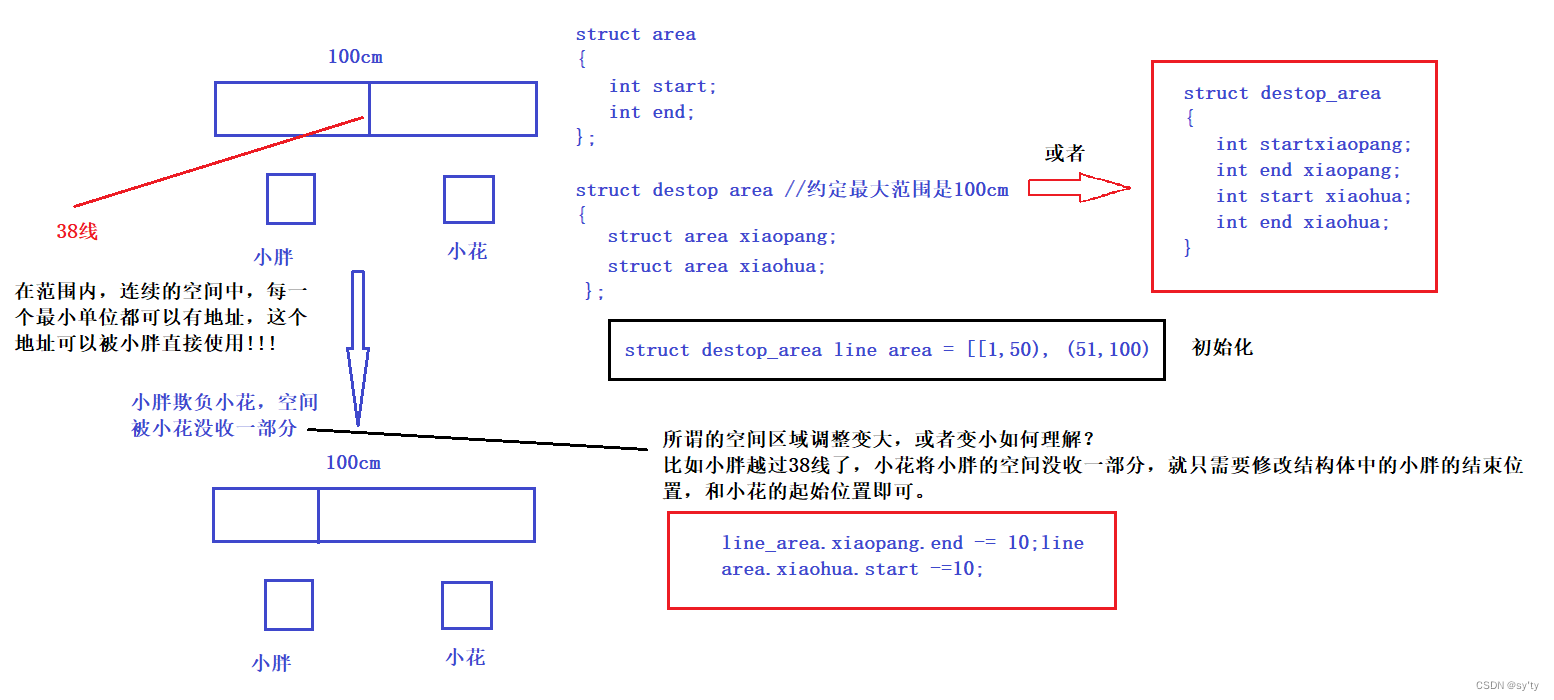
类似的,我们mm_struct也可以通过这样的方式来给进程地址空间划分区域从而去描述它。
地址空间内一定要存在各种区域划分,也对线性地址进行start,和end即可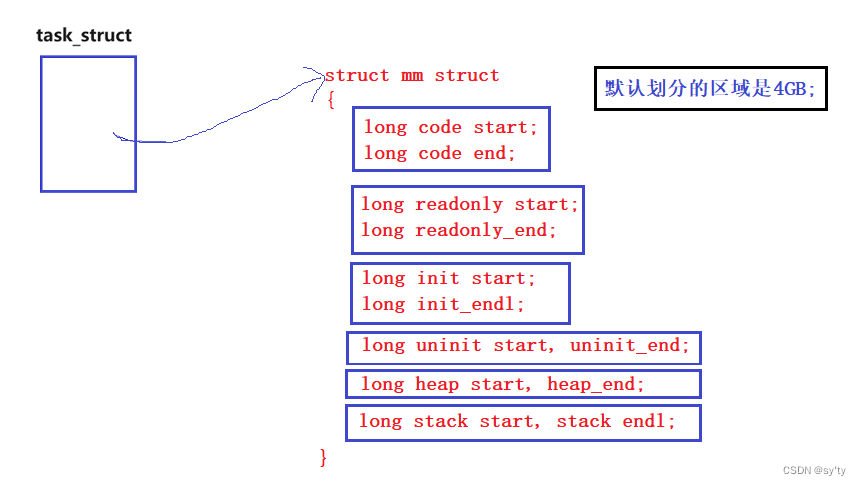
虽然这里只有start和end但是每个进程都可以认为mm_struct代表整个内存,且所有的地址为0x00000000~0xffffffff。因为虚拟地址是由0x00000000到0xffffffff线性增长的,因此虚拟地址又叫做线性地址。
每个进程都认为地址空间的划分是按照4GB空间划分的,换言之也就是说每个进程都认为自己拥有4GB。
现在我知道了mm_struct是如何描述进程地址空间的,那么我现在又有一个问题:
3、页表
前面我们讲到,页表是一个key value结构,地址空间的虚拟地址可以通过页表找到物理内存当中的物理地址。
首先进程必须是处于运行阶段才能访问到自己的内存,每个进程是由内核数据结构(task_struct&&地址空间(mm_struct)&&页表)+程序的代码和数据组成的。task_struct中存放了自己的地址空间的地址。系统为了能够实现虚拟地址到物理地址之间的映射,维护了页表结构。
接下来我们补充几个关于页表的知识点
(1)进程在进行虚拟地址转换到物理地址的时候,会不会找不到页表呢?
答案是不会的,我们来看下面这个图

CPU中有一个cr3寄存器,里面存放了当前进程的页表起始地址,而我们的寄存器存放的页表地址本质上属于进程的硬件上下文,当进程切换的时候会被带走,当进程重新运行的时候页表地址就会被重新加载到CPU,所以每个进程自始至终都能找到自己的页表,不存在找不到页表地址的情况。
当我们要进行虚拟地址向物理地址映射的时候,CPU通过cr3寄存器中的页表地址找到页表,然后进行虚拟地址向物理地址映射。
(2)页表还有权限标志位,可以很好的进行权限管理
我们先来看一段代码:
1 #include<stdio.h>2 #include<stdlib.h>3 #include<unistd.h>4 5 int main()6 {7 char *str = "hello process";8 *str = 'H'; 9 return 0;10 }
运行结果:

可以编译,但是执行报错
我们知道这里str是字符串hello process的首地址,也就是字符h的地址,*str就是h,我们将h改为H明显是不行的,因为h是属于字符常量区,字符常量区是只读的,不可以修改。
但上面的结论我们之前都是记住的,现在我们想知道为什么代码区和字符常量区是只读?怎么做到的呢?
我们来看下面这个图

其实页表条目当中还有对应的标志位,来标识当前的物理内存是可读还是可写,假设我们虚拟地址为0x123456的变量是可读可写的,对应页表的读写标志位就是可读可写的。
比如现在代码区有虚拟地址0x1111映射到了物理内存的0x12位置,但是页表当中标记的这个位置是只读的。如果我们这个时候要往这个位置进行写入。CPU将虚拟地址0x1111通过页表转换到物理地址0x12,发现这个位置是标记成只读的。如果我们这个时候想向该位置进行写入,就相当于是非法操作,系统就会进行拦截,把我们这个进程给挂掉。所以,页表可以给我们很好的进行权限管理。
同样的,这时候我们就可以解决上面的问题,代码区和字符常量区他们在页表当中所匹配的虚拟地址和物理地址的映射,他们的页表映射标志位这里全都是只读的,所以我们在对代码区和字符常量区进行写入操作时,操作系统才能够拦截我们,我们写的时候进程才会挂掉。
(3) 页表条目还有一个标志位,来标识我们要访问的数据是否已经加载到内存当中
进程是可以被挂起的(挂起时我们如何知道进程的代码数据,在不在内存呢??)
我们先谈一个共识:现代操作系统,几乎不做任何浪费空间和浪费时间的事情
我们来讲一个例子:
相信大家都在电脑上打过游戏,不管是使命召唤,原神,还是其它的游戏,基本上都是几十个G,但我们的物理内存可能只有4GB,为什么我们的电脑能够运行呢?
其实是因为操作系统对大文件可以实现分批加载,在处理大文件时,一次性将整个文件加载到内存中可能会导致内存不足或性能下降。因此,操作系统可以采用分批加载的方法,将文件分成多个块,逐块读取和处理。
我们知道了操作系统可以对大文件进行分批加载,可是如果我们加载了500M的空间,但是我们的代码还是一行一行的去跑的,也就是说,即便加载了500M的空间,但是我们短期之内可能只能用5M,那么我们就有一个问题,剩下的495MB,我们用不用把他们提前加载到内存呢?
我们把数据和代码扔到内存,但是由于进程调度,CPU配置,时间片等原因,这些代码和数据大概率是跑不完的,所以这些空间大概率还不会被使用,这就造成了把空间给你,但却没有被使用,这就违背了我们前面讲到的一个共识——现代操作系统,几乎不做任何浪费空间和浪费时间的事情。
所以操作系统对可执行程序加载的策略,实际上是一种惰性加载,也就是我们承诺给可执行程序这么大的空间,但是实际上在物理内存,几乎是用多少给多少。比如现在我们的游戏是2GB,我们可能就先给几kb,因为剩下的内存就算给了短期内也访问不到。本来这块内存还可以给其他进程的。这样内存的使用率就不高了。所以操作系统使用了惰性加载的方式。
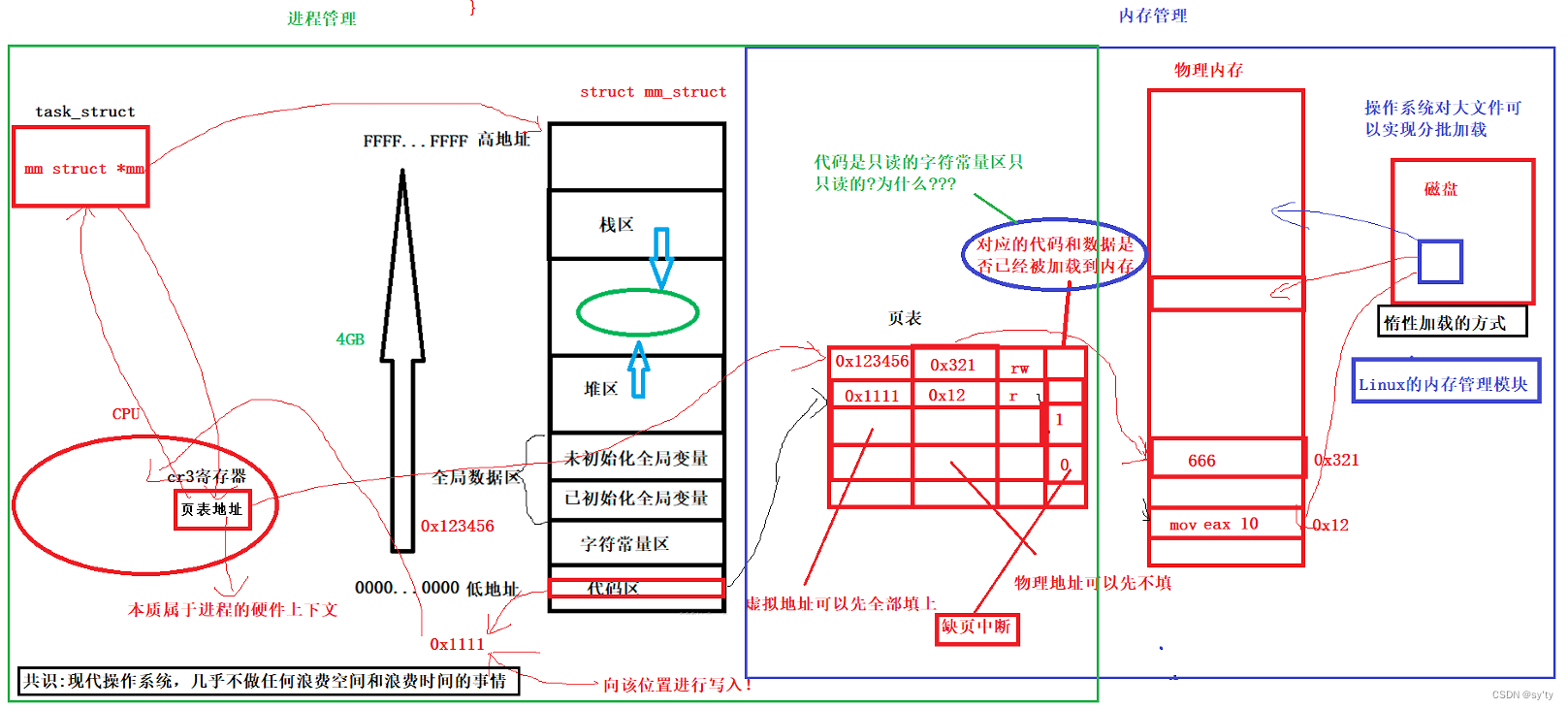
惰性加载:比如我们的正文代码段可能有500M,在外面的页表当中我们可以把虚拟地址全部填上,但是物理地址这边我们可以先只填一小部分。并且页表当中还有一个标记位,用来记录对应的代码和数据是否已经加载到内存。为0表示未加载,为1 表示已经加载。所以当我们在访问虚拟地址,就会查对应的页表上的标记位,看看对应的的代码和数据是否已经加载到内存,如果标志位为1,说明已经被加载,我们就直接读取物理地址直接访问。如果标志位为0,这个时候操作系统就需要触发一个概念——缺页中断,操作系统就会找到可执行程序,然后再在物理内存申请一块空间,把这个可执行程序剩下的代码和数据加载到这个物理内存里。然后把这段物理地址填到对应的页表当中,这样就实现边使用边加载。这个时候,我们再来访问就可以访问到对应的代码和数据了。其实我们的写时拷贝也是缺页中断的原理。
现在我们来问一个问题,进程在被创建的时候,是先创建内核数据结构呢? 先加载对应的可执行程序呢??
学习了上面的原理,我们再来解答这个问题,进程在被创建的时候,一定是先创建内核数据结构的,把进程的PCB,地址空间,页表给维护起来,再来加载对应的内存(惰性加载)。
内存管理模块:我们前面讲到的如果我们要访问的虚拟地址对应的标志为0,要进行缺页中断,那么我们要在物理内存哪里申请空间,加载到物理内存上面地方,填写到页表上面地方,这一系列的过程就叫Linux的内存管理模块。
那么我们这一系列的过程包括申请内存释放内存,填写页表等,我们的进程知道吗?我们进程进行调度、切换的时候,我们有没有管过内存怎么释放的,其实是不需要管的。正是因为有页表和地址空间的存在,所以我们的进程管理(进程怎么调度怎么切换)根本就不需要关心内存管理,进程只需要使用虚拟地址,没有了内存管理自己会使用缺页中断,操作系统自己会调用内存管理的功能。所以,操作系统把进程管理和内存管理实现了软件层面上的解耦!!!
总结几个问题:
1、为什么要有进程地址空间?
(1)让进程以统一的视角看待内存
如果没有进程地址空间和页表,进程的PCB在物理内存当中,代码和数据也只能在物理内存当中,所以进程就要记录自己的代码和数据在代码和数据在哪个地址处,从哪开始从哪结束,每个进程都需要这么做,而且每个进程直接使用物理内存了。这样进程就要对自己的代码和数据的使用情况进行管理工作。比如现在我们的进程因为阻塞被挂起了,代码和数据需要被换出,当他重新被换入的时候,他的代码和数据对应的物理地址可能已经变了,我们就需要重新修改PCB,这样的话太麻烦了,而有了进程地址空间和页表,我们就不需要关心我们的代码和数据在物理内存的什么位置。
有了进程地址空间和页表,每个进程都是通过进程地址空间和页表的映射,找到对应物理内存上的物理地址,这样的方式让每个进程以统一的视角看待内存。
(2)增加进程虚拟地址空间可以让我们访问内存的时候,增加一个转换的过程,在这个转化的过程中,可以对我们的寻址请求进行审查,所以一旦异常访问,直接拦截,该请求不会到达物理内存,保护物理内存。
(3)因为有地址空间和页表的存在,将进程管理模块,和内存管理模块进行解耦合!
如果地址空间和页表的存在,我们进程直接进行物理内存的申请和释放,这种强耦合的代码一旦出现问题,那么内存管理出现问题,一定会影响进程调度。
2、进程切换
- 我们对于进程就有了新的理解:进程=内核数据结构(task_struct&&进程地址空间(mm_struct)&&页表)+程序的代码和数据。
- 进程在进行切换的时候,不仅仅要切换PCB,也要切换地址空间,也要切换页表。只要切换了进程的PCB ,它所匹配的地址空间自动被切换,因为PCB指向对应的地址空间,又因为存放页表的地址的cr3寄存器属于进程的上下文,所以进程寄存器上下文只要已切换,那么页表自动被切换,所以归根结底,进程切换,我们只需要把CPU内的上下文一切换,那么PCB,地址空间,页表就全部切换了。所以我们每个进程就可以有这一整套东西了。
3、进程具有独立性,怎么做到的?
- 每个进程都有自己的PCB,地址空间,页表,所以在内存数据结构上,所有的进程是互相独立的。所以父子进程都有自己的内核数据结构。
- 还体现在在物理内存当中,我们加载到物理内存的代码和数据,不同进程虚拟地址可以完全一样,但是物理地址可以完全不一样,我们只需要让页表映射到物理内存的不同区域,这样每个进程的代码和数据就互相解耦了,即便是父子关系,只需要代码区一样,数据区不一样,也实现解耦了。所以我们的进程一旦异常,释放地址空间,释放PCB,释放页表,释放页表映射的物理内存,并不会影响其他进程。