OpenAI CLIP模型是一个创造性的突破; 它以与文本相同的方式处理图像。 令人惊讶的是,如果进行大规模训练,效果非常好。

在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 3D场景编辑器
CLIP 将图像视为一系列不重叠的补丁,每个补丁都是一个视觉标记(类似于 NLP 中的文本标记或单词)。 因此,图像只是一系列视觉标记,可以使用旧的转换器像文本一样进行处理。
训练数据是从网络上抓取的图像标题对。 CLIP 模型经过训练,可以使用对比损失将图像/文本转换为向量嵌入。 经过训练的 CLIP 模型将在同一向量空间中生成图像和文本嵌入,使我们能够通过计算 (i) 图像嵌入和 (ii) 文本嵌入之间的余弦相似度来计算 (i) 图像和 (ii) 一段文本的相似度。
将任意图像/文本转换为矢量嵌入正在成为一种基本的人工智能原语。 它免费解锁了许多人工智能功能,而这些功能之前需要数周/数月的训练数据收集和模型训练工作。 实际上,它允许对许多用例进行零样本预测,例如 图像分类、图像分割与目标检测。本文将介绍如何利用CLIP实现这三种图像预测任务。
1、图像分类
给定 (i) 一张图像和 (ii) 可能的类(文本)列表,我们要求 CLIP 生成 (i) 图像嵌入和 (ii) 类(文本)嵌入。 预测的类别是其嵌入最接近图像嵌入的类别。
以下是改编自 zero-shot-prediction 的伪代码:
classes = ["credit card", "driver's license", "passport"]model, preprocess = clip.load('ViT-B/32')image_input = preprocess(image)
text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in classes])image_features = model.encode_image(image_input)
text_features = model.encode_text(text_inputs)# Pick the most similar class for the image
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
2、图像分割
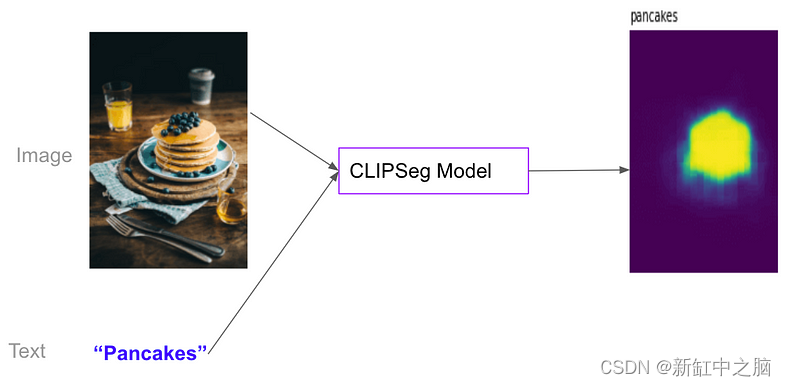
同样,CLIPSeg 是基于 CLIP 的图像分割模型。 给定(i)图像和(ii)任意文本(例如“煎饼”),它可以找到与图像中文本相对应的轮廓。
CLIPSeg 上的一个优秀的 Hugging Face 博客:使用 CLIPSeg 进行零样本图像分割:
3、对象检测
最后,OWL-ViT 是一个基于 CLIP 的对象检测模型。 给定(i)图像和(ii)任意文本(例如“煎饼”),它可以找到与图像中的文本相对应的边界框(矩形)。
点击这里查看HF上的 OWL-ViT 演示。
4、CLIP加速产品迭代速度
至关重要的是,没有模型训练步骤! 此外,CLIP可以进行图像分类、图像分割和任意类别的对象检测(开放词汇设置)。 使用自定义模型,每次我们必须预测新类别时,我们都需要收集新类别(标签)的训练数据,并训练新模型。 这是一个非常耗时的过程,通常需要几周到几个月的时间。 有了 CLIP,所有这些步骤都被消除了; CLIP 可以预测任意类别!
因此,对于能够容忍潜在较高错误率的用例,基于 CLIP 的模型可以加快产品迭代速度,而只有对于精度要求较高的用例才需要训练自定义模型。
原文链接:用CLIP分类、分割和检测 — BimAnt