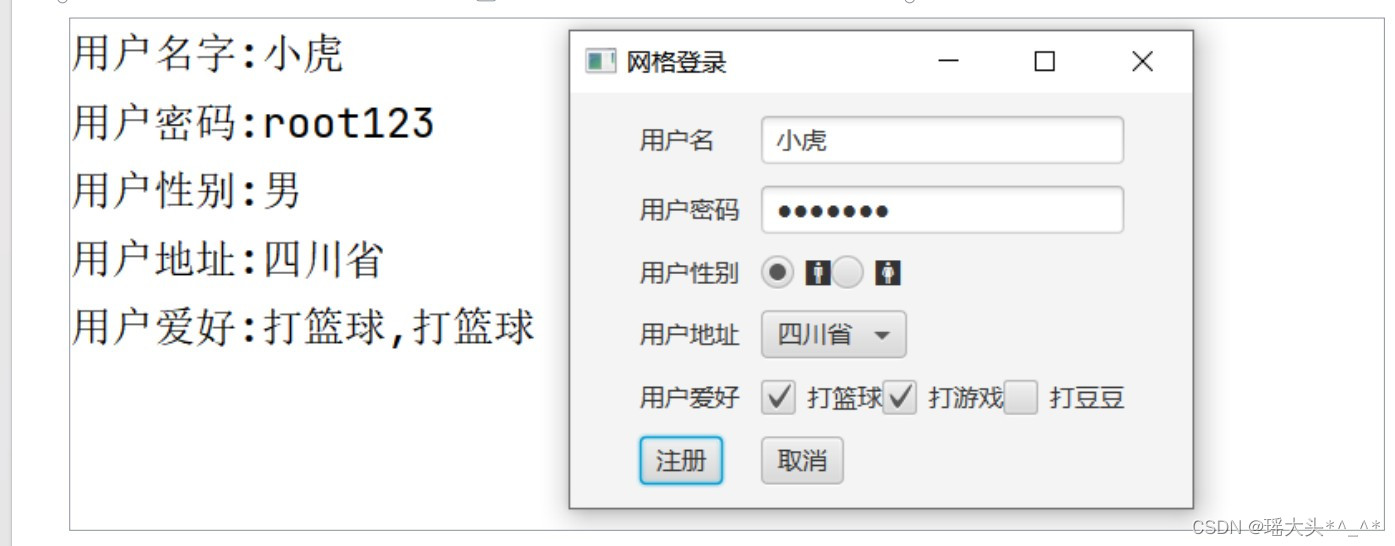
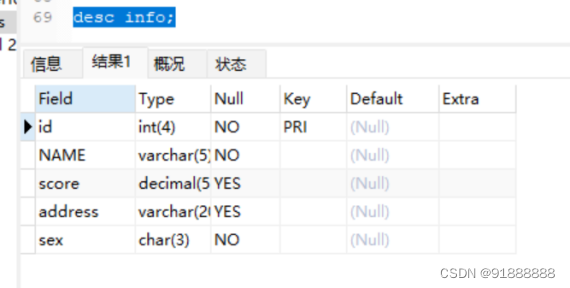
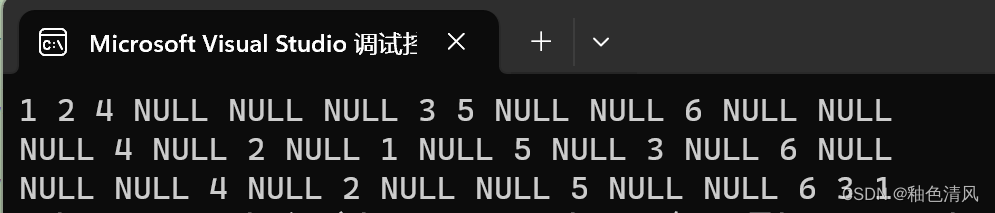
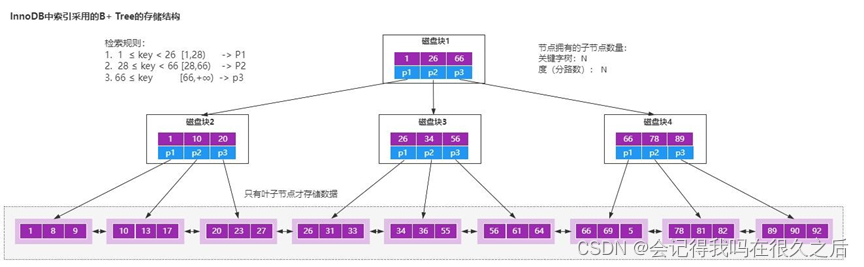
文章目录
- Abstract
- Introduction
- 介绍前人的工作
- 提出问题
- 解决
- YOLOX
- YOLOX-DarkNet53
- Implementation details
- YOLOv3 baseline
- Decoupled head
- Strong data augmentation
- Anchor-free
- Multi positives
- SimOTA
- End-to-end YOLO
- Other Backbones
- Modified CSPNet in YOLOv5
- Tiny and Nano detectors
- Model size and data augmentation
- Comparison with the SOTA
- 1st Place on Streaming Perception Challenge(WAD at CVPR 2021)
- Conclusion
论文链接
源代码
Abstract
在本报告中,我们对YOLO系列进行了一些改进,形成了一种新的高性能探测器- YOLOX。我们将YOLO检测器转换为无锚点方式,并进行其他先进的检测技术,即解耦头和领先的标签分配策略SimOTA,以在大范围的模型中实现最先进的结果
对于只有0.91M参数和1.08G FLOPs的YOLO- Nano,我们在COCO上获得25.3%的AP,比NanoDet高出1.8%;对于工业中应用最广泛的探测器之一YOLOv3,我们将其在COCO上的AP提高到47.3%,比目前的最佳实践高出3.0% AP;对于参数数量与YOLOv4- CSP、YOLOv5-L大致相同的YOLOX-L,我们在Tesla V100上以68.9 FPS的速度在COCO上实现了50.0%的AP,比YOLOv5-L高出1.8% AP。此外,我们使用单个YOLOX-L模型获得了流感知挑战赛(CVPR 2021自动驾驶研讨会)的第一名
我们希望这份报告能在实际场景中为开发人员和研究人员提供有用的经验,同时我们也提供了支持ONNX、TensorRT、NCNN和Openvino的部署版本
Introduction
介绍前人的工作
随着目标检测技术的发展,YOLO系列一直在追求实时应用中速度和精度的最佳权衡,他们提取了当时可用的最先进的检测技术(例如,YOLOv2的锚点,YOLOv3的残差网络),并优化了最佳实践的实现
提出问题
尽管如此,在过去两年中,目标检测学术界的主要进展集中在无锚点检测器,先进标签分配策略和端到端(无nms)检测器,而这些还没有被整合到YOLO家族中,如yolo4和YOLOv5仍然是基于锚点的检测器,使用手工制定的训练分配规则
解决
这就是把我们带到这里的原因,通过经验丰富的优化,我们为YOLO系列提供这些最新的进步,我们选择YOLOv3作为起点(我们将YOLOv3- spp设置为默认的YOLOv3)
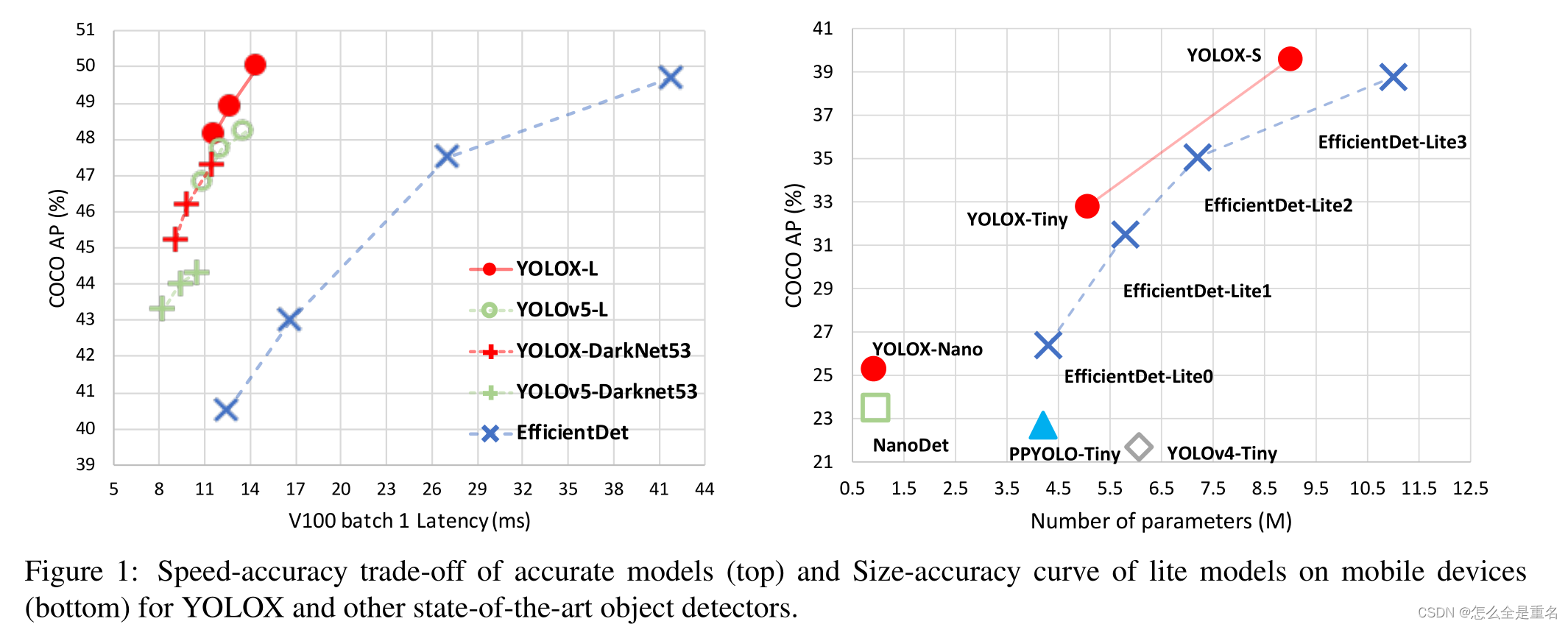
如图1所示,我们在640 × 640分辨率的COCO上将YOLOv3的AP提高到47.3% (YOLOv3 - darknet53),大大超过了目前YOLOv3的最佳实践(44.3% AP, ultralytics version2)
更重要的是,当切换到采用先进的CSPNet骨干网和额外的PAN头的先进YOLOv5架构时,YOLOX-L在640 × 640分辨率的COCO上达到50.0%的AP,比对应的YOLOv5- L高出1.8%的AP
我们还在小尺寸模型上测试了我们的设计策略(右图)。YOLOX-Tiny和YOLOX-Nano(仅0.91M参数和1.08G FLOPs)分别比对应的YOLOv4-Tiny和NanoDet3分别高出10%和1.8%的AP
YOLOX
YOLOX-DarkNet53
我们选择YOLOv3与Darknet53作为我们的baseline(即参照物)
Implementation details
我们的训练设置从baseline到最终模型基本上是一致的。我们在COCO train2017上对模型进行了总共300次的训练,其中有5次warmup。我们使用随机梯度下降(SGD)进行训练。我们使用的学习率为lr×BatchSize/64(线性缩放),初始lr = 0.01,余弦lr调度。权重衰减为0.0005,SGD动量为0.9。典型的8 gpu设备的批处理大小默认为128,本报告中的FPS和延迟都是在单个Tesla V100上以fp16精度和batch=1测量的
YOLOv3 baseline
我们的baseline采用了DarkNet53骨干网和SPP层的架构,在一些论文中称为YOLOv3-SPP。与原始实现相比,我们略微改变了一些训练策略,增加了EMA权值更新、余弦调度、IoU损失和IoU感知分支。我们将BCE Loss用于训练类和对象分支,IoU Loss用于训练区域分支
对于数据增强,我们只执行RandomHorizontalFlip, ColorJitter和multi-scale,而放弃RandomResizedCrop策略,因为我们发现RandomResizedCrop与计划的mosaic增强有点重叠
有了这些改进,我们的baseline在COCO val上达到38.5%的AP,如表2所示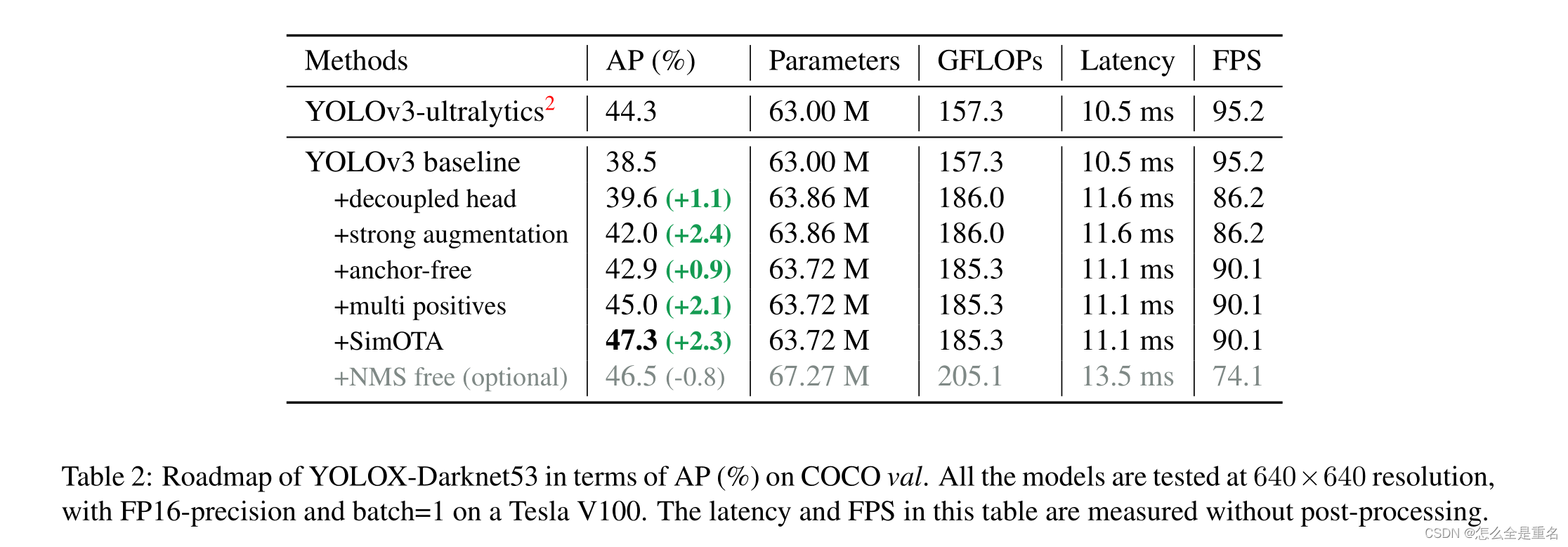
Decoupled head
在目标检测中,分类任务和回归任务之间的冲突是一个众所周知的问题。因此,解耦头部分类和定位被广泛应用于大多数一阶段和二阶段检测器中。然而,随着YOLO系列的主干和特征金字塔(如FPN、PAN)的不断演化,它们的检测头仍然保持耦合,如图2所示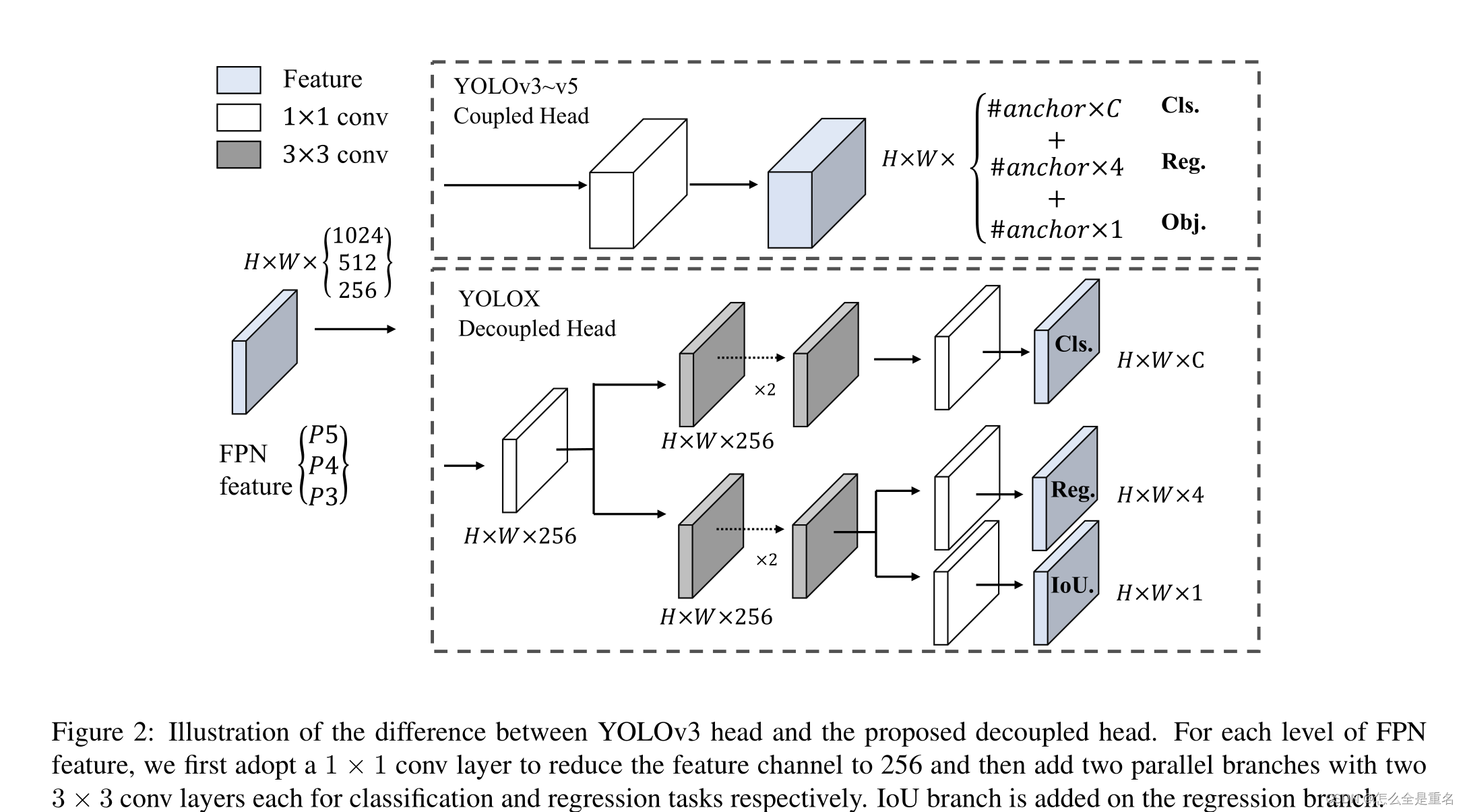
对于每一层FPN特征,我们首先采用1 × 1的conv层将特征通道减少到256个,然后添加两个并行分支,每个分支有两个3 × 3的conv层,分别用于分类和回归任务,并在回归分支上添加IoU分支
我们的两个分析实验表明,耦合检测头可能会损害性能:1)将YOLO的头部替换为解耦的头部,大大提高了收敛速度,如图3所示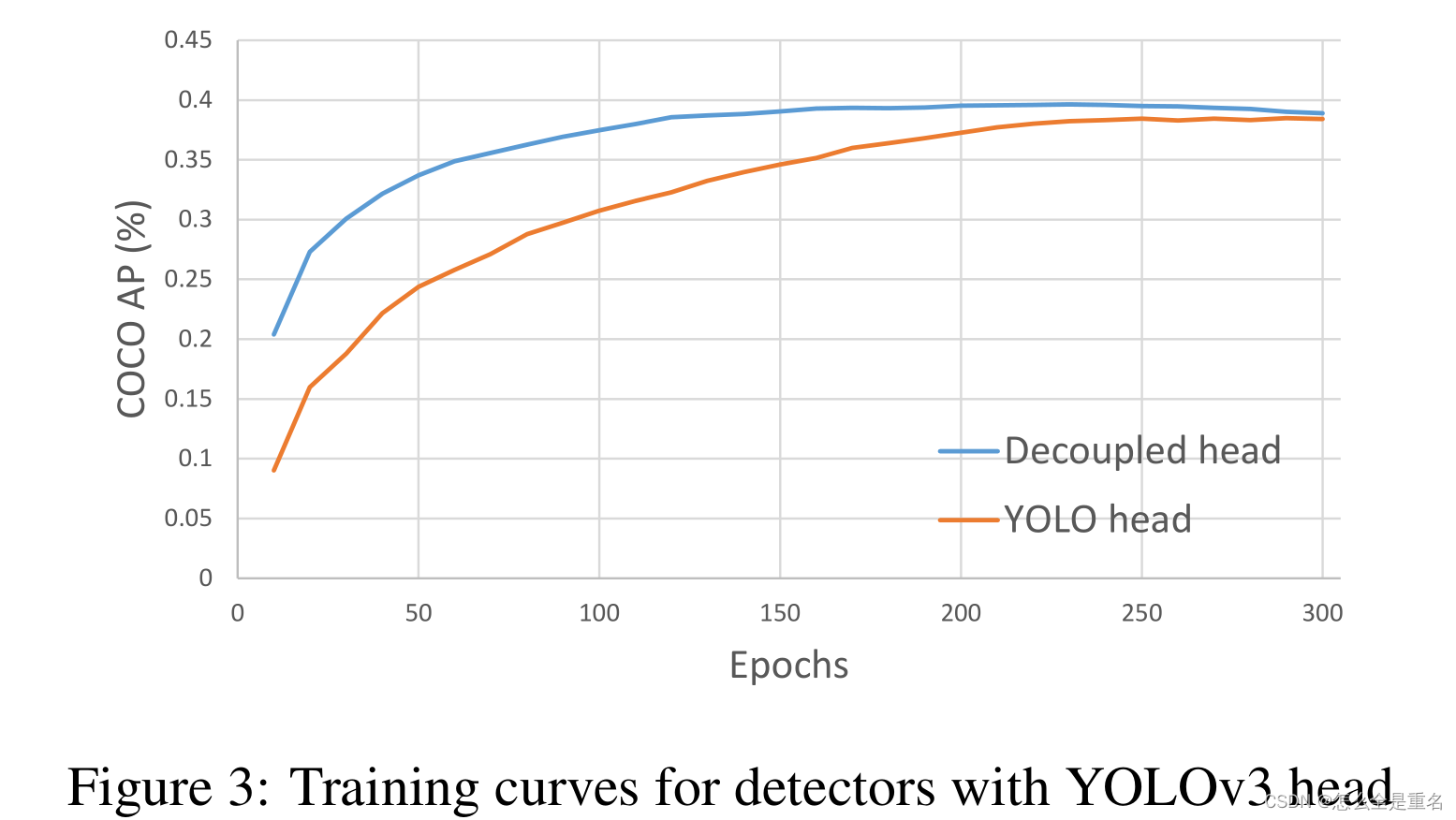
2)解耦头对于端到端版本的YOLO至关重要
从表1可以看出,耦合封头的端到端特性降低了4.2% AP,而解耦封头的端到端特性降低到0.8% AP
Strong data augmentation
我们将Mosaic和MixUp添加到我们的增强策略中,以提高YOLOX的性能,结果见表2,提示了2.4的AP
Anchor-free
YOLOv4和YOLOv5都遵循了YOLOv3原有的基于锚点的管道。然而,锚点机制有许多已知的问题
首先,为了达到最优的检测性能,需要在训练前进行聚类分析,确定一组最优的锚点。这些聚集的锚点是特定于领域的,泛化程度较低
其次,锚定机制增加了检测头的复杂性,以及每个图像的预测数量。在一些边缘AI系统中,在设备之间移动如此大量的预测(例如,从NPU到CPU)可能会成为整体延迟方面的潜在瓶颈
无锚机制显著减少了需要启发式调优的设计参数的数量和涉及的许多技巧(例如,Anchor Clustering , Grid Sensitive),以获得良好的性能,使检测器,特别是其训练和解码阶段,相当简单
将YOLO切换到无锚的方式非常简单。我们将每个位置的预测从3个减少到1个,并使它们直接预测4个值,即网格左上角的两个偏移量,以及预测框的高度和宽度,我们将每个对象的中心位置指定为正样本,并预先定义刻度范围,以指定每个对象的FPN级别
Multi positives
为了与YOLOv3的分配规则保持一致,上述无锚版本为每个对象均值只选择一个阳性样本(中心位置),而忽略其他高质量的预测。然而,优化这些高质量的预测也可能带来有益的梯度,这可能会缓解训练过程中正/负抽样的极端不平衡
我们简单地将中心3×3区域赋值为阳性,在FCOS中也称为“中心采样”。如表2所示,检测器的性能提高到45.0% AP,已经超过了当前的最佳实践ultralytics-YOLOv3 (44.3% AP)
SimOTA
高级标签分配是近年来目标检测的又一重要进展。基于我们自己的研究OTA,我们总结了高级标签分配的四个关键见解:1).损失/质量意识,2).中心先验,3).每个基本真理的正锚点的动态数量(简称为动态top-k), 4).全局视图。OTA满足上述所有四条规则,因此我们选择它作为候选标签分配策略
具体而言,OTA从全局角度分析标签分配问题,并将分配过程表述为一个最优运输(Optimal Transport, OT)问题,从而产生当前分配策略之间的SOTA性能。然而,在实践中,我们发现使用Sinkhorn-Knopp算法求解OTA问题会带来25%的额外训练时间,这对于训练300个epoch来说是相当昂贵的。因此,我们将其简化为动态top-k策略,称为SimOTA,以获得近似解
SimOTA不仅减少了训练时间,而且避免了Sinkhorn-Knopp算法中额外的求解器超参数。如表2所示,SimOTA将检测器的AP从45.0%提高到47.3%,比SOTA ultralytics-YOLOv3高3.0% AP,显示了高级分配策略的强大
关于OTA的详细介绍
End-to-end YOLO
我们遵循通过消除启发式nms,使目标检测变得更简单
添加两个额外的转换层、一对一的标签分配和停止梯度。这使得检测器能够以端到端方式执行,但会略微降低性能和推理速度,如表2所示。因此,我们将其作为一个可选模块,不涉及我们的最终模型
Other Backbones
除了DarkNet53之外,我们还在其他不同尺寸的骨干上测试了YOLOX,其中YOLOX对所有相应的对应部件都取得了一致的改进
Modified CSPNet in YOLOv5
为了进行公平的比较,我们采用了完全相同的YOLOv5的主干,包括修改后的CSPNet、SiLU激活和PAN头。YOLOX- S、YOLOX- m、YOLOX- l、YOLOX- x型号也遵循其缩放规则。与表3中的YOLOv5相比,我们的模型得到了一致的改善,AP提高了~ 3.0%至~ 1.0%,只有边际时间增加(来自解耦的头部)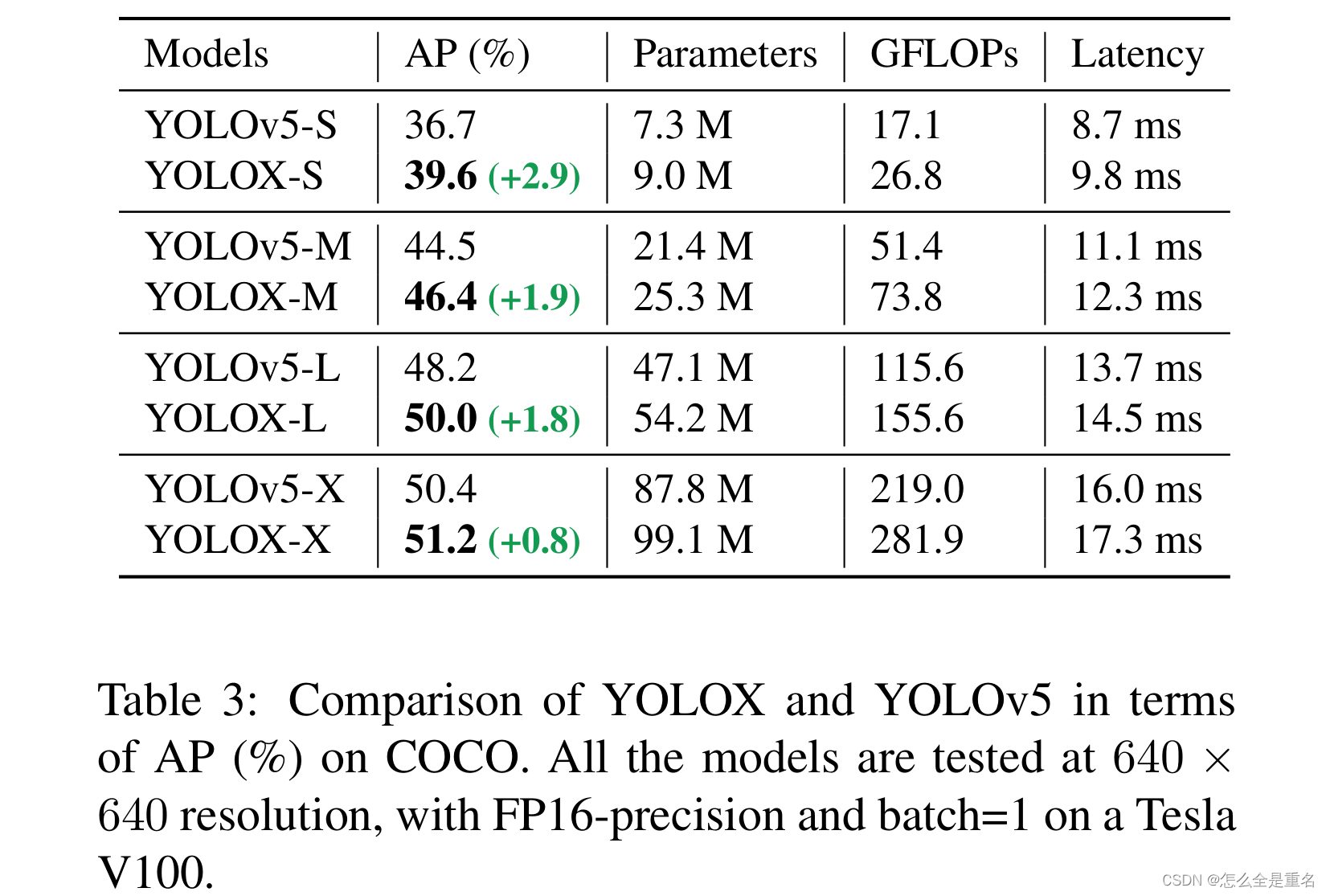
Tiny and Nano detectors
我们进一步将模型缩小为YOLOX-Tiny,与YOLOv4-Tiny进行比较。对于移动设备,我们采用深度卷积构建了一个只有0.91M pa参数和1.08G FLOPs的YOLOX-Nano模型。如表4所示,YOLOX在更小的模型尺寸下表现良好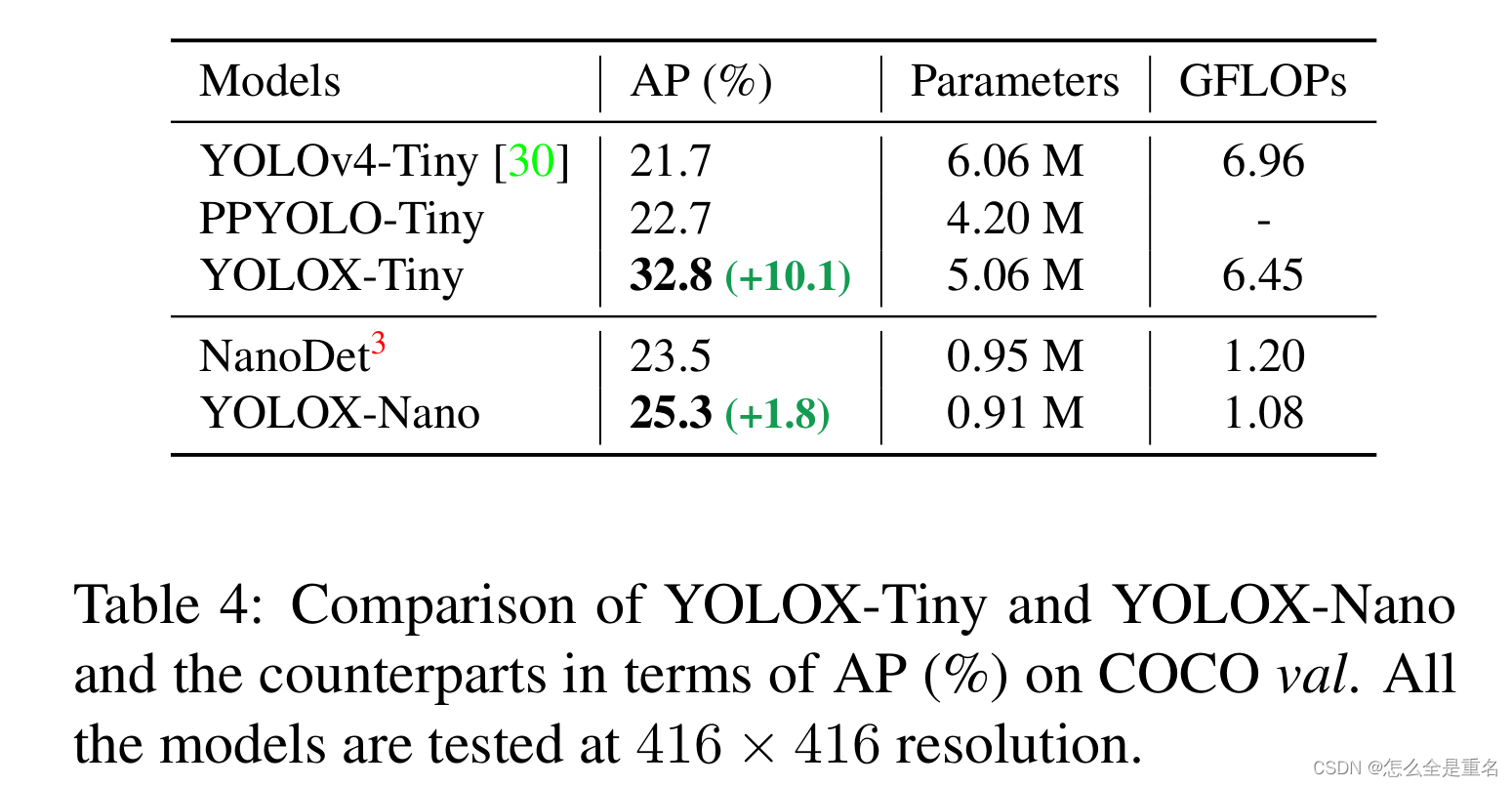
Model size and data augmentation
我们发现,不同尺寸的模型,合适的增强策略是不同的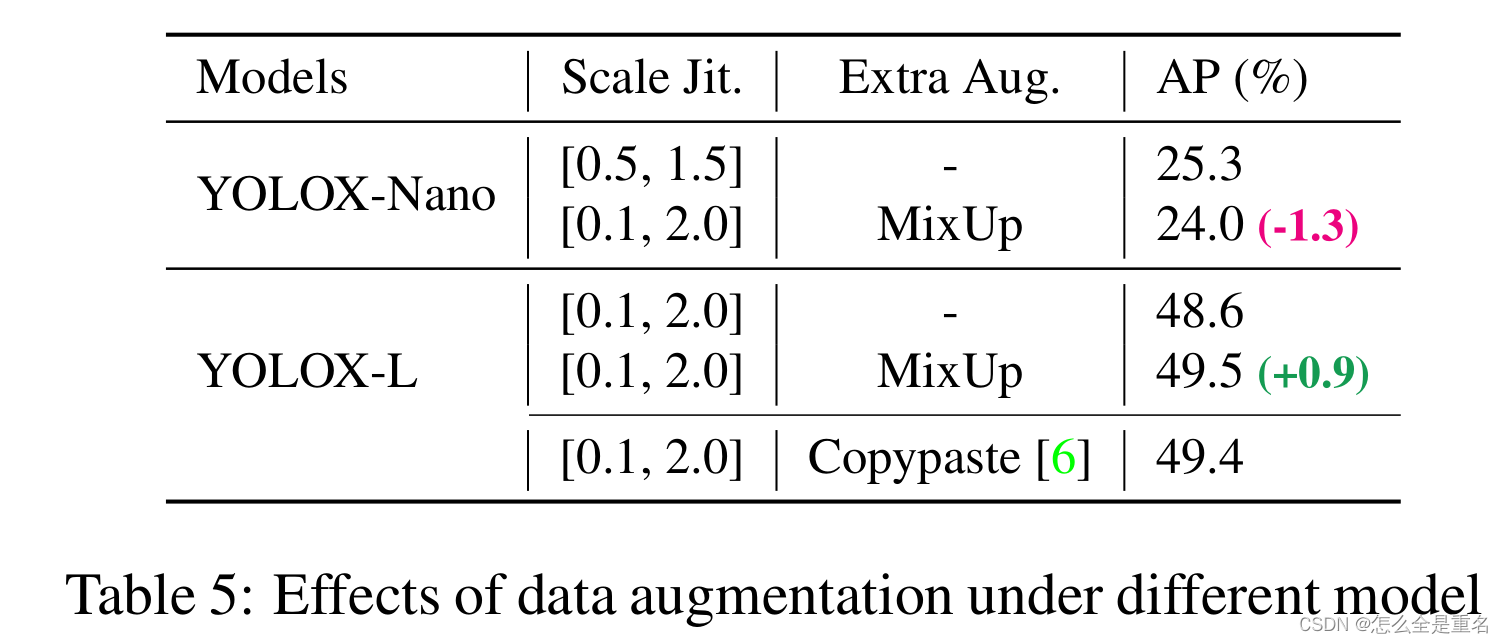
Comparison with the SOTA
如表6所示,该表中模型的推理速度通常是不受控制的,因为速度随软件和硬件的不同而变化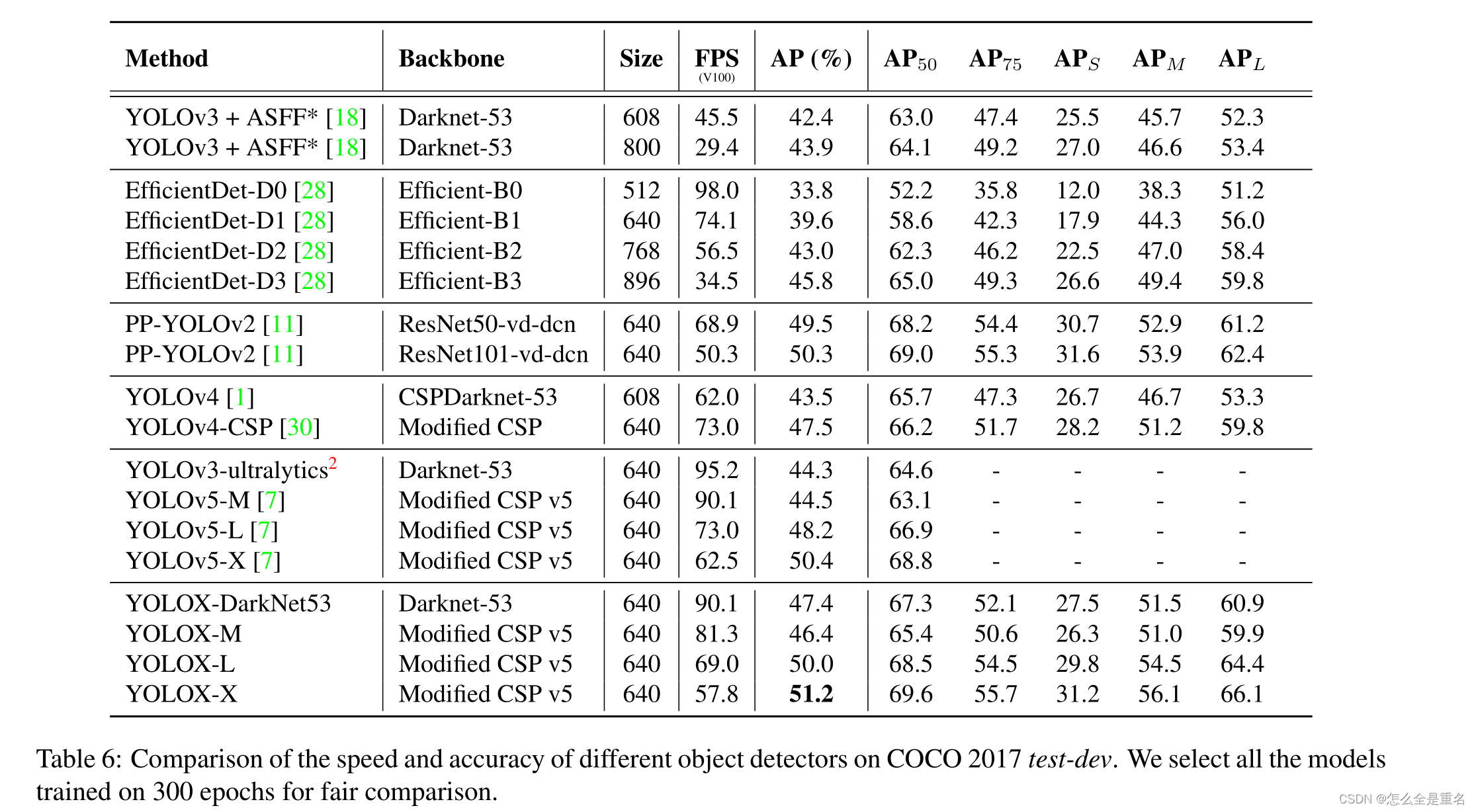
1st Place on Streaming Perception Challenge(WAD at CVPR 2021)
WAD 2021上的流感知挑战是通过最近提出的度量:流精度 来对准确性和延迟进行联合评估
streaming accuracy
这个指标背后的关键见解是在每个时刻联合评估整个感知堆栈的输出,迫使堆栈考虑在计算发生时应该忽略的流数据量。我们发现在30fps数据流上度量的最佳折衷点是一个推理时间≤33ms的强大模型。因此,我们采用YOLOX-L模型和TensorRT来制作我们的最终模型,以获得第一名的挑战
Conclusion
在本报告中,我们介绍了YOLO系列的一些经验更新,它形成了一个高性能的anchor-free检测器,称为YOLOX。配备了一些最新的先进检测技术,即解耦头部,无锚点和先进的标签分配策略,YOLOX在所有模型尺寸上都比其他同类产品在速度和准确性之间取得了更好的平衡
值得注意的是,我们将YOLOv3的架构提升到了47.3%的AP,超过了目前最佳实践的3.0% AP