消息中间件
1、简介
消息中间件也可以称消息队列,是指用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息队列模型,可以在分布式环境下扩展进程的通信。
当下主流的消息中间件有RabbitMQ、Kafka、ActiveMQ、RocketMQ等。
2、作用
1、消息中间件主要作用
-
冗余(存储)
-
扩展性
-
可恢复性
-
顺序保证
-
缓冲
-
异步通信
2、消息中间件的两种模式
1、P2P模式
P2P模式包含三个角色:消息队列(Queue)、发送者(Sender)、接收者(Receiver)。每个消息都被发送到一个特定的队列,接收者从队列中获取消息。队列保留着消息,直到它们被消费或超时。
P2P的特点:
-
每个消息只有一个消费者(Consumer),即一旦被消费,消息就不再在消息队列中
-
发送者和接收者之间在时间上没有依赖性,也就是说当发送者发送了消息之后,不管接收者有没有正在运行它不会影响到消息被发送到队列
-
接收者在成功接收消息之后需向队列应答成功
-
如果希望发送的每个消息都会被成功处理的话,那么需要P2P模式
2、Pub/Sub模式
Pub/Sub模式包含三个角色:主题(Topic)、发布者(Publisher)、订阅者(Subscriber) 。多个发布者将消息发送到Topic,系统将这些消息传递给多个订阅者。
Pub/Sub的特点:
-
每个消息可以有多个消费者
-
发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息
-
为了消费消息,订阅者必须保持运行的状态
-
如果希望发送的消息可以不被做任何处理、或者只被一个消息者处理、或者可以被多个消费者处理的话,那么可以采用Pub/Sub模型
3、常用中间件介绍与对比
1、Kafka
Kafka是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache顶级项目。Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输。0.8版本开始支持复制,不支持事务,对消息的重复、丢失、错误没有严格要求,适合产生大量数据的互联网服务的数据收集业务。
2、RabbitMQ
RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。AMQP协议更多用在企业系统内对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。
3、RocketMQ
RocketMQ是阿里开源的消息中间件,它是纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。RocketMQ思路起源于Kafka,但并不是Kafka的一个Copy,它对消息的可靠传输及事务性做了优化,目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。
RabbitMQ比Kafka可靠,Kafka更适合IO高吞吐的处理,一般应用在大数据日志处理或对实时性(少量延迟),可靠性(少量丢数据)要求稍低的场景使用,比如ELK日志收集。
RabbiMQ
RabbiMQ简介
RabbiMQ是⽤Erang开发的,集群⾮常⽅便,因为Erlang天⽣就是⼀⻔分布式语⾔,但其本身并不⽀持负载均衡。支持高并发,支持可扩展。支持AJAX,持久化,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
2、RabbitMQ 特点
-
可靠性
-
扩展性
-
高可用性
-
多种协议
-
多语言客户端
-
管理界面
-
插件机制
3、什么是消息队列
MQ 全称为Message Queue, 。是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。
消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信。
RabbiMQ模式
注意:RabbitMQ模式⼤概分为以下三种:
(1)单⼀模式。
(2)普通模式(默认的集群模式)。
(3) 镜像模式(把需要的队列做成镜像队列,存在于多个节点,属于RabbiMQ的HA⽅案,在对业务可靠性要求较⾼的场合中⽐较适⽤)。要实现镜像模式,需要先搭建⼀个普通集群模式,在这个模式的基础上再配置镜像模式以实现⾼可⽤。
了解集群中的基本概念:
RabbitMQ的集群节点包括内存节点、磁盘节点。顾名思义内存节点就是将所有数据放在内存,磁盘节点将数据放在磁盘。如果在投递消息时,打开了消息的持久化,那么即使是内存节点,数据还是安全的放在磁盘。
一个rabbitmq集 群中可以共享 user,vhost,queue,exchange等,所有的数据和状态都是必须在所有节点上复制的。
ConnectionFactory(连接管理器):应用程序与Rabbit之间建立连接的管理器,程序代码中使用; Channel(信道):消息推送使用的通道; Exchange(交换器):用于接受、分配消息; Queue(队列):用于存储生产者的消息; RoutingKey(路由键):用于把生成者的数据分配到交换器上; BindingKey(绑定键):用于把交换器的消息绑定到队列上; Broker:简单来说就是消息队列服务器实体 vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离. producer:消息生产者,就是投递消息的程序。 consumer:消息消费者,就是接受消息的程序。 user:用户
安装Rabbitmq软件
关闭防火墙与selinux
上传了俩个包直接上传下载即可
rz
上传上来,然后安装依赖,安装rabbitmq
[root@localhost ~]# lserlang-21.3.8.21-1.el7.x86_64.rpm rabbitmq-server-3.7.10-1.el7.noarch.rpm[root@localhost ~]# yum install -y epel-release gcc-c++ unixODBC unixODBC-devel openssl-devel ncurses-devel[root@localhost ~]# yum -y install erlang-21.3.8.21-1.el7.x86_64.rpm [root@localhost ~]# yum -y install rabbitmq-server-3.7.10-1.el7.noarch.rpm 测试
[root@localhost ~]# erlErlang/OTP 20 [erts-9.3] [source] [64-bit] [smp:1:1] [ds:1:1:10] [async-threads:10] [hipe] [kernel-poll:false]Eshell V9.3 (abort with ^G)
1>启动
启动,用systemctl管理
[root@rabbitmq-1 ~]# systemctl daemon-reload
[root@rabbitmq-1 ~]# systemctl start rabbitmq-server
[root@rabbitmq-1 ~]# systemctl enable rabbitmq-server启动方式二:
[root@rabbitmq-1 ~]# /sbin/service rabbitmq-server status ---查看状态
[root@rabbitmq-1 ~]# /sbin/service rabbitmq-server start ---启动每台都操作开启rabbitmq的web访问界面:
[root@localhost ~]# rabbitmq-plugins enable rabbitmq_managementEnabling plugins on node rabbit@localhost:
rabbitmq_management
The following plugins have been configured:rabbitmq_managementrabbitmq_management_agentrabbitmq_web_dispatch
Applying plugin configuration to rabbit@localhost...
The following plugins have been enabled:rabbitmq_managementrabbitmq_management_agentrabbitmq_web_dispatchstarted 3 plugins.
创建用户
添加用户和密码
[root@localhost ~]# rabbitmqctl add_user zyq 123456
Adding user "zyq" ...设置管理员
[root@localhost ~]# rabbitmqctl set_user_tags zyq administrator
Setting tags for user "zyq" to [administrator] ...查看用户
[root@localhost ~]# rabbitmqctl list_users
Listing users ...
user tags
zyq [administrator]
guest [administrator]此处设置权限时注意'.*'之间需要有空格 三个'.*'分别代表了conf权限,read权限与write权限 例如:当没有给
newrain设置这三个权限前是没有权限查询队列,在ui界面也看不见
[root@localhost ~]# rabbitmqctl set_permissions -p "/" zyq ".*" ".*" ".*"
Setting permissions for user "zyq" in vhost "/" ...
开启用户远程登录
[root@rabbitmq-1 ~]# cd /etc/rabbitmq/
[root@rabbitmq-1 rabbitmq]# cp /usr/share/doc/rabbitmq-server-3.7.10/rabbitmq.config.example /etc/rabbitmq/rabbitmq.config
[root@rabbitmq-1 rabbitmq]# ls
enabled_plugins rabbitmq.config
[root@rabbitmq-1 rabbitmq]# vim rabbitmq.config
修改如下: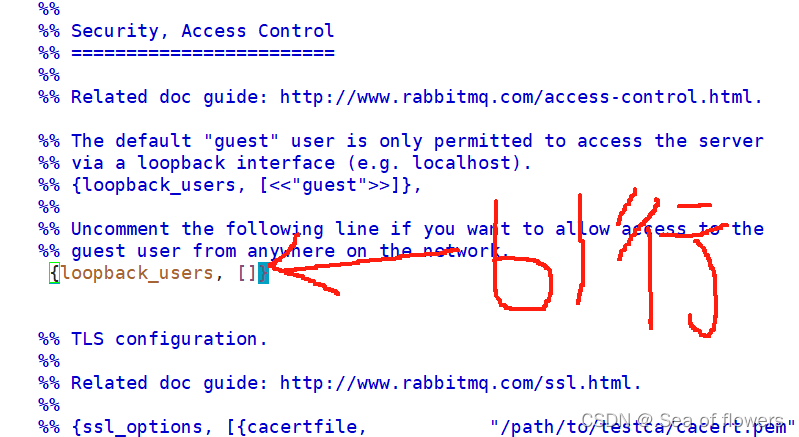
将61行的注释打开,并将最后行尾的 逗号 删除即可。
重启服务
systemctl restart rabbitmq-server查看端口
[root@localhost rabbitmq]# netstat -nplt
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:25672 0.0.0.0:* LISTEN 14396/beam.smp
tcp 0 0 0.0.0.0:4369 0.0.0.0:* LISTEN 14592/epmd
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 917/sshd
tcp 0 0 0.0.0.0:15672 0.0.0.0:* LISTEN 14396/beam.smp
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1137/master
tcp6 0 0 :::5672 :::* LISTEN 14396/beam.smp
tcp6 0 0 :::4369 :::* LISTEN 14592/epmd
tcp6 0 0 :::22 :::* LISTEN 917/sshd
tcp6 0 0 ::1:25 :::* LISTEN 1137/master 4369 -- erlang发现端口
5672 --程序连接端口
15672 -- 管理界面ui端口
25672 -- server间内部通信口
访问:192.168.231.192:15672
这里需要注意:
rabbitmq默认管理员用户:guest 密码:guest
新添加的用户为:newrain 密码:123456
压力测试
第一步是获取源代码 ,执行完在前台运行,直接打开浏览器即可
git clone https://gitea.beyourself.org.cn/newrain001/rabbitmq-test.git && \
cd rabbitmq-test && yum install -y python3 python3-devel && \
pip3 install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple && \
export FLASK_ENV=development ; flask run --reload -p 80 -h 0.0.0.0
观察
开始部署集群 三台机器
192.168.231.192 rabbit-1
192.168.231.193 rabbit-2
192.168.231.194 rabbit-3
安装上面的步骤进行域名解析[root@rabbit-1 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.36.192.100 package.qf.com
192.168.231.192 rabbit-1
192.168.231.193 rabbit-2
192.168.231.194 rabbit-3复制到另外俩台服务器
scp /etc/hosts/ 192.168.231.193:/etc/hostsscp /etc/hosts/ 192.168.231.194:/etc/hosts创建数据存放目录和日志存放目录。三台机器都做相同的操作
[root@rabbitmq-1 ~]# mkdir -p /data/rabbitmq/data
[root@rabbitmq-1 ~]# mkdir -p /data/rabbitmq/logs
[root@rabbitmq-1 ~]# chmod 777 -R /data/rabbitmq
[root@rabbitmq-1 ~]# chown rabbitmq.rabbitmq /data/ -R创建配置文件
[root@rabbitmq-1 ~]# vim /etc/rabbitmq/rabbitmq-env.conf
[root@rabbitmq-1 ~]# cat /etc/rabbitmq/rabbitmq-env.conf
RABBITMQ_MNESIA_BASE=/data/rabbitmq/data
RABBITMQ_LOG_BASE=/data/rabbitmq/logs重启服务
[root@rabbitmq-1 ~]# systemctl restart rabbitmq-serverRabbitmq的集群是依附于erlang的集群来⼯作的,所以必须先构建起erlang的集群景象。Erlang的集群中
各节点是经由过程⼀个magic cookie来实现的,这个cookie存放在/var/lib/rabbitmq/.erlang.cookie中,⽂件是400的权限。所以必须保证各节点cookie⼀致,不然节点之间就⽆法通信.
如果执行# rabbitmqctl stop_app 这条命令报错:需要执行
#如果执行# rabbitmqctl stop_app 这条命令报错:需要执行
#chmod 400 .erlang.cookie
#chown rabbitmq.rabbitmq .erlang.cookie(官方在介绍集群的文档中提到过.erlang.cookie 一般会存在这两个地址:第一个是home/.erlang.cookie;第二个地方就是/var/lib/rabbitmq/.erlang.cookie。如果我们使用解压缩方式安装部署的rabbitmq,那么这个文件会在{home}目录下,也就是$home/.erlang.cookie。如果我们使用rpm等安装包方式进行安装的,那么这个文件会在/var/lib/rabbitmq目录下。)
[root@rabbit-1 ~]# cat /var/lib/rabbitmq/.erlang.cookie
ISOGGRKUABBYNHYKQKZN⽤scp的⽅式将rabbitmq-1节点的.erlang.cookie的值复制到其他两个节点中。
[root@rabbit-1 ~]# scp /var/lib/rabbitmq/.erlang.cookie root@192.168.231.193:/var/lib/rabbitmq/[root@rabbit-1 ~]# scp /var/lib/rabbitmq/.erlang.cookie root@192.168.231.194:/var/lib/rabbitmq/将mq-2、mq-3作为内存节点加⼊mq-1节点集群中
在mq-2、mq-3执⾏如下命令:
[root@rabbitmq-2 ~]# systemctl restart rabbitmq-server
[root@rabbitmq-2 ~]# rabbitmqctl stop_app
[root@rabbitmq-2 ~]# rabbitmqctl reset
[root@rabbitmq-2 ~]# rabbitmqctl join_cluster --ram rabbit@rabbitmq-1
Clustering node 'rabbit@rabbitmq-2' with 'rabbit@rabbitmq-1' ...
[root@rabbitmq-2 ~]# rabbitmqctl start_app
Starting node 'rabbit@rabbitmq-2' ...
======================================================================
[root@rabbitmq-3 ~]# systemctl restart rabbitmq-server
[root@rabbitmq-3 ~]# rabbitmqctl stop_app
Stopping node 'rabbit@rabbitmq-3' ...
[root@rabbitmq-3 ~]# rabbitmqctl reset
Resetting node 'rabbit@rabbitmq-3' ...
[root@rabbitmq-3 ~]# rabbitmqctl join_cluster --ram rabbit@rabbitmq-1
Clustering node 'rabbit@rabbitmq-3' with 'rabbit@rabbitmq-1' ...
[root@rabbitmq-3 ~]# rabbitmqctl start_app
Starting node 'rabbit@rabbitmq-3' ...(1)默认rabbitmq启动后是磁盘节点,在这个cluster命令下,mq-2和mq-3是内存节点,
mq-1是磁盘节点。
(2)如果要使mq-2、mq-3都是磁盘节点,去掉--ram参数即可。
(3)如果想要更改节点类型,可以使⽤命令rabbitmqctl change_cluster_node_type
disc(ram),前提是必须停掉rabbit应⽤
注:
#如果有需要使用磁盘节点加入集群[root@rabbitmq-2 ~]# rabbitmqctl join_cluster rabbit@rabbitmq-1[root@rabbitmq-3 ~]# rabbitmqctl join_cluster rabbit@rabbitmq-1执行rabbitmqctl stop_app 停止节点 出现报错,将终端退出 然后重新登录即可
最好将三个服务器都退出终端 重新登录
查看集群状态
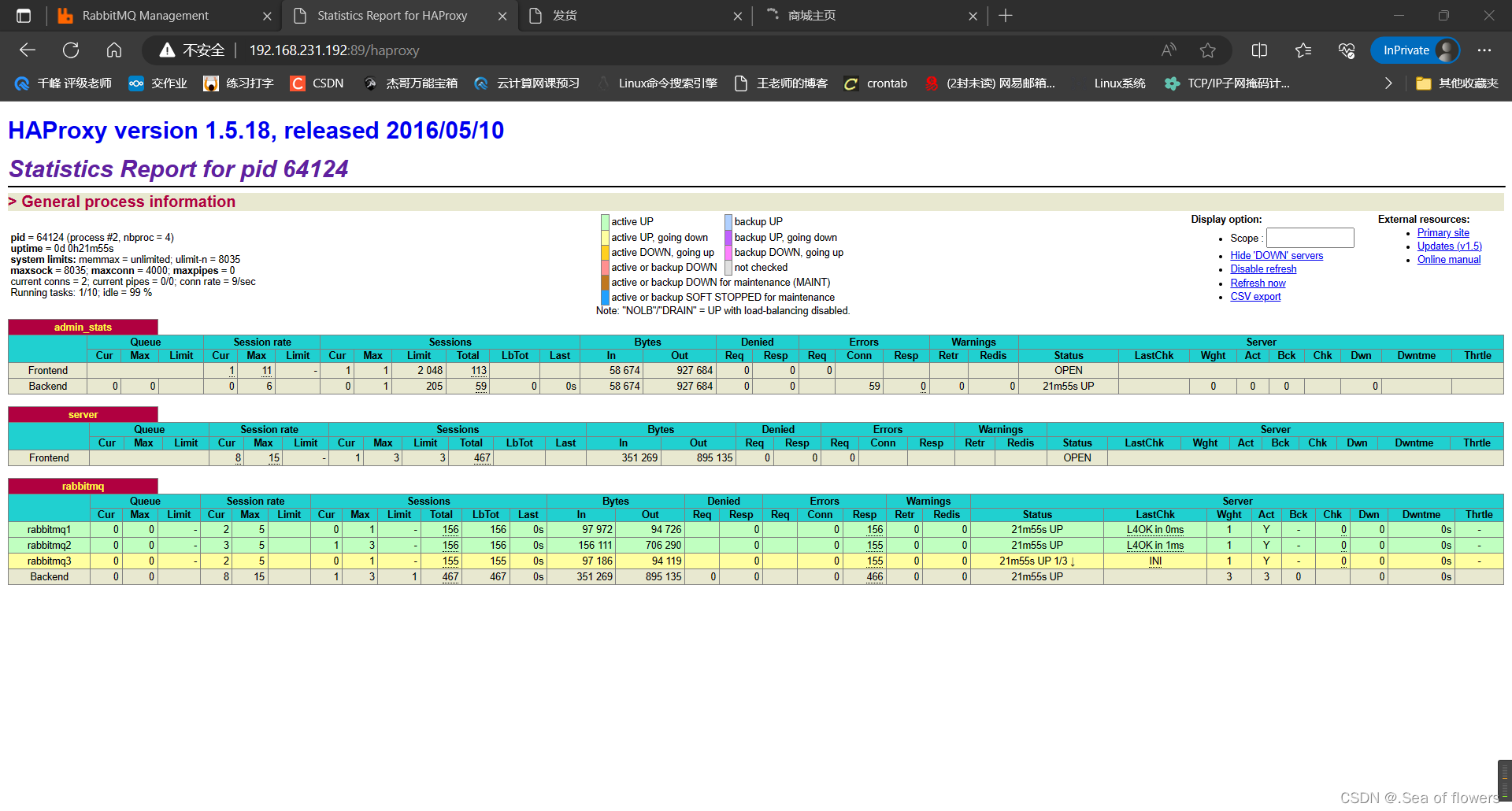
在 RabbitMQ 集群任意节点上执行 rabbitmqctl cluster_status来查看是否集群配置成功。
在mq-1磁盘节点上面查看
[root@rabbit-1 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit-1 ...
[{nodes,[{disc,['rabbit@rabbit-1']},{ram,['rabbit@rabbit-3','rabbit@rabbit-2']}]},{running_nodes,['rabbit@rabbit-2','rabbit@rabbit-3','rabbit@rabbit-1']},{cluster_name,<<"rabbit@rabbit-1">>},{partitions,[]},{alarms,[{'rabbit@rabbit-2',[]},{'rabbit@rabbit-3',[]},{'rabbit@rabbit-1',[]}]}]
在web页面查看
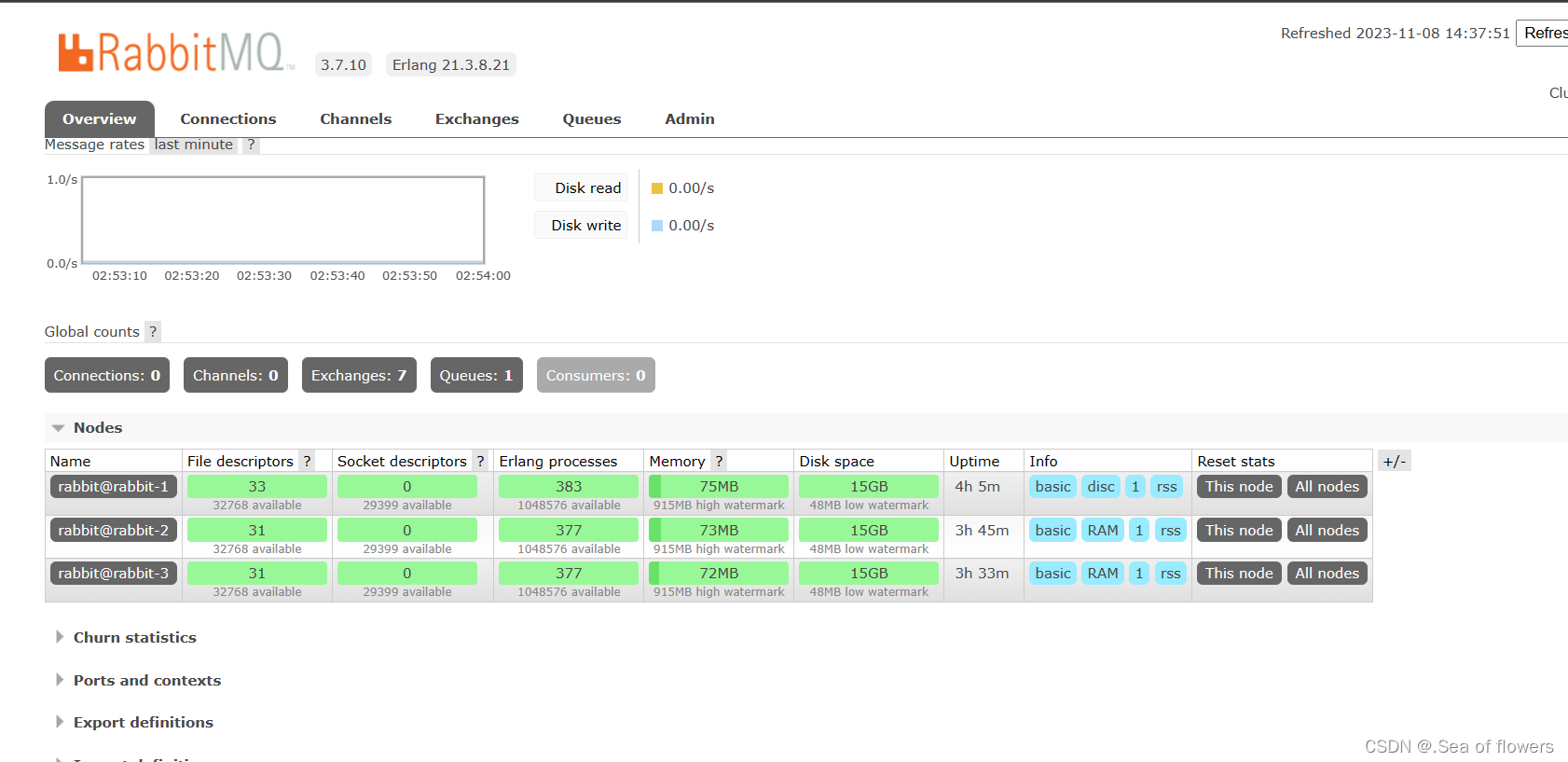
登录rabbitmq web管理控制台,创建新的队列
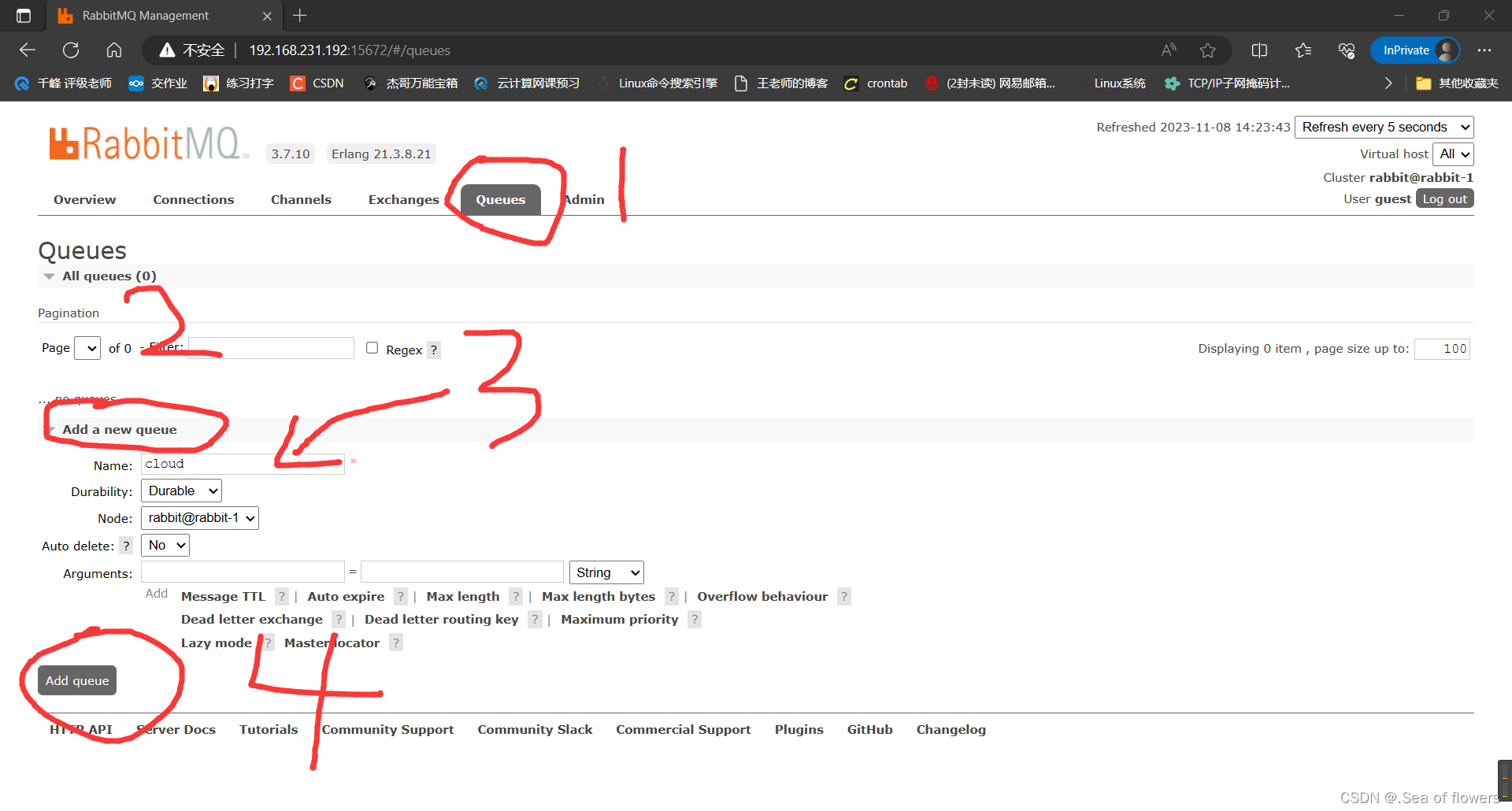
只有一个
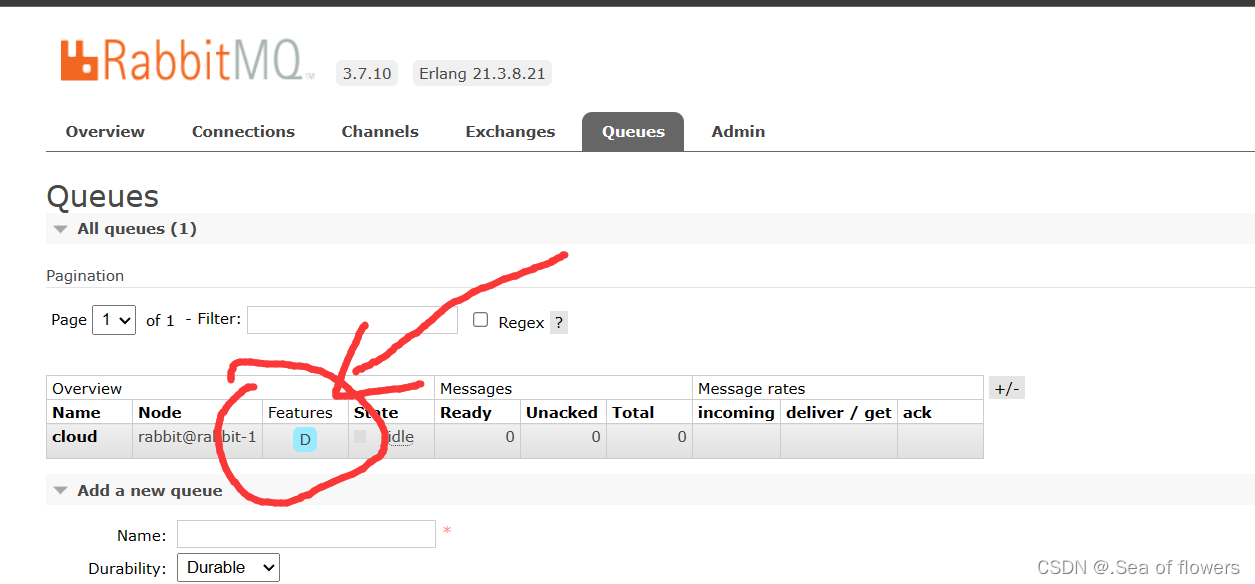
在RabbitMQ集群集群中,必须⾄少有⼀个磁盘节点,否则队列元数据⽆法写⼊到集群中,当
磁盘节点宕掉时,集群将⽆法写⼊新的队列元数据信息。
创建镜像集群:
rabbitmqctl set_permissions ".*" ".*" ".*" (后面三个”*”代表用户拥有配置、写、读全部权限)[root@rabbitmq-1 ~]# rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
[root@rabbitmq-2 ~]# rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
[root@rabbitmq-3 ~]# rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'再次查看队列已经同步到其他两台节点:
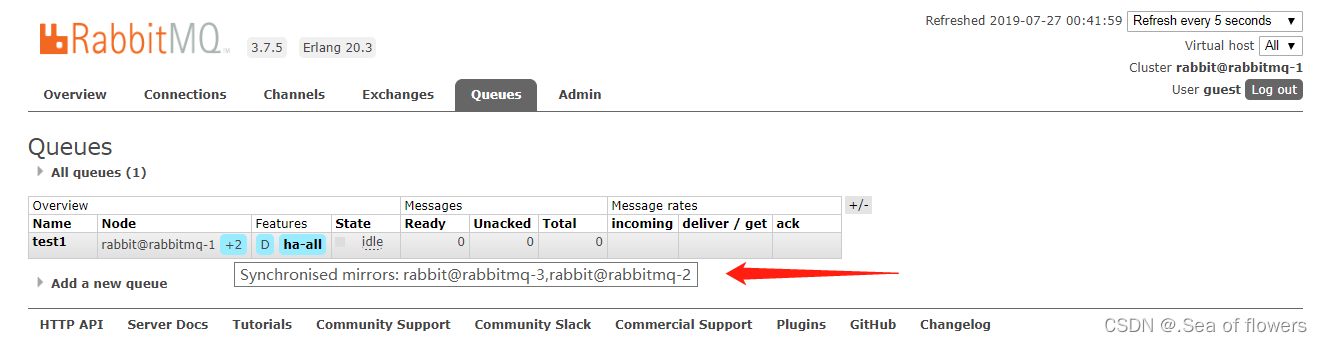
则此时镜像队列设置成功。(这里的虚拟主机是代码中需要用到的虚拟主机,虚拟主机的作用是做一个消息的隔离,本质上可认为是一个rabbitmq-server,是否增加虚拟主机,增加几个,这是由开发中的业务决定,即有哪几类服务,哪些服务用哪一个虚拟主机,这是一个规划)。
安装并且配置负载均衡器HA
如果使用阿里云,可以使用阿里云的内网slb来实现负载均衡,不用自己搭建HA。
在192.168.231.192上安装haproxy
yum -y install haproxy
修改 /etc/haproxy/haproxy.cfg
备份配置文件,防止出错
[root@rabbitmq-1 ~]# cp /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak编写配置文件
[root@rabbitmq-1 ~]# vim /etc/haproxy/haproxy.cfg
globallog 127.0.0.1 local2chroot /var/lib/haproxypidfile /var/run/haproxy.pidmaxconn 4000user haproxygroup haproxynbproc 4daemon# turn on stats unix socketstats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
defaultsmode httplog globalretries 3timeout connect 10stimeout client 1mtimeout server 1mtimeout check 10smaxconn 2048
#---------------------------------------------------------------------
##监控查看本地状态#####
listen admin_statsbind *:80 ####与python3端口冲突,后续如果做python3实验可以改端口mode httpoption httplogoption httpcloselog 127.0.0.1 local0 errstats uri /haproxystats auth admin:123456 ####登录监控的用户 密码stats refresh 30s
####################################
###反代监控
frontend serverbind *:5670 ####haproxy的监听端口log globalmode tcp#option forwardfordefault_backend rabbitmqmaxconn 3
backend rabbitmqmode tcplog globalbalance roundrobinserver rabbitmq1 192.168.231.192:5672 check inter 2000s rise 2 fall 3server rabbitmq2 192.168.231.193:5672 check inter 2000s rise 2 fall 3server rabbitmq3 192.168.231.194:5672 check inter 2000s rise 2 fall 3以上三行是负载均衡rabbitmq集群的IP重启haproxy
systemctl start haproxy浏览器输入192.168.231.192/haproxy 查看rabbitmq状态