💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。
- 推荐:kwan 的首页,持续学习,不断总结,共同进步,活到老学到老
- 导航
- 檀越剑指大厂系列:全面总结 java 核心技术点,如集合,jvm,并发编程 redis,kafka,Spring,微服务,Netty 等
- 常用开发工具系列:罗列常用的开发工具,如 IDEA,Mac,Alfred,electerm,Git,typora,apifox 等
- 数据库系列:详细总结了常用数据库 mysql 技术点,以及工作中遇到的 mysql 问题等
- 懒人运维系列:总结好用的命令,解放双手不香吗?能用一个命令完成绝不用两个操作
- 数据结构与算法系列:总结数据结构和算法,不同类型针对性训练,提升编程思维,剑指大厂
非常期待和您一起在这个小小的网络世界里共同探索、学习和成长。💝💝💝 ✨✨ 欢迎订阅本专栏 ✨✨

博客目录
- 一.分布式理论
- 1.CAP 理论
- 2.分布式系统类型
- 3.Base 理论
- 4.集群对比
- 5.链式调用
- 6.框架中的 COW
- 7.时间轮算法
- 8.分布式痛点问题有哪些?
- 二.分布式事务
- 1.分布式事务解决方案
- 2.如何解决 TCC 中悬挂问题?
- 3.如何回滚 MQ 和 Redis?
- 4.最终一致性
- 5.分布式 session 共享问题
- 6.注册中心脑裂问题?
- 三.分布式锁
- 1.分布式锁与单机锁的区别?
- 2.分布式锁的特征?
- 3.分布式锁的种类
- 4.分布式锁的实现?
- 5.分布式锁的续期?
- 6.Redisson 分布式锁公平锁
- 7.Redisson 分布式锁非公平锁
- 8.Redisson 实现分布式锁读写锁
- 四.高并发高可用
- 1.什么是接口幂等性?
- 2.幂等和防重提交的区别
- 3.幂等在项目中的应用?
- 4.一致性 hash 在项目中的应用?
- 5.什么是布隆过滤器?
- 6.布隆过滤器作用?
- 7.常见的分布式日志方案?
- 8.简介 prometheus
- 9.简介 Grafana
- 五.分布式协议与算法
- 1.选举算法
- 2.Bully 算法
- 3.Raft 算法
- 4.ZAB 算法
- 4.Paxos 协议
- 5.选举算法对比
- 1.zookeeper 主从选举
- 2.ES master 选举
- 3.Redis 哨兵选举
- 4.Redis cluster 选举
- 5.kafka parition 选举
- 六.Raft 算法
- 1.Raft 算法基本原理
- 2.Raft 三个子问题
- 3.Raft 算法核心流程
- 4.raft 协议角色
- 5.领导选举
- 6.Raft 整个底层实现原理:
- 七.限流算法
- 1.限流算法
- 2.固定窗口限流算法
- 3.滑动窗口算法?
- 4.漏桶算法
- 5.令牌桶算法
- 6.令牌桶算法种类
- 7.什么是计数器算法?
- 8.令牌桶和漏桶算法区别
- 八.架构设计
- 1.设计一个 IM 系统
- 2.项目优化
- 3.大数据量压测调优
- 4.查询时间几十秒?
- 1.问题描述
- 2.问题模拟
- 3.优化手段
- 4.数据库层面优化
- 5.应用层优化
- 6.分布式缓存
- 7.加入本地缓存
- 8.网关层面优化
- 9.调优小结
- 5.BigKey 问题
- 1.什么是 BigKey?
- 2.BigKey 导致的问题
- 3.解决方案
- 6.重复提交问题?
- 7.接口幂等性设计?
- 8.超卖解决方案
- 9.消息推送的设计?
- 10.多级缓存
- 11.如何给接口限流?
- 九.解决方案
- 1.数据迁移方案
- 2.64 亿的 url,如何去重?
- 3.什么是脑裂问题?
- 4.如何解决脑裂问题?
- 5.什么是雪花算法?
- 6.雪花算法时钟回拨问题?
- 7.关于语雀挂了思考?
一.分布式理论
1.CAP 理论
CAP 理论,也被称为 CAP 定理,是一个与分布式系统和数据库系统相关的理论,由计算机科学家埃里克·布鲁尔(Eric Brewer)在 2000 年提出。该理论描述了分布式计算系统中三个关键概念之间的权衡:
-
一致性(Consistency):在分布式系统中的所有节点看到的数据副本都是一致的。换句话说,如果一个节点在某次操作之后读取了数据,那么其他节点在同一时间也应该能够读取到相同的数据。 -
可用性(Availability):系统在有限时间内对于客户端请求的响应能力。即使系统中的某些节点出现故障,也应该尽量保持对外提供服务,而不是完全不可用。 -
分区容错性(Partition Tolerance):系统能够继续运行,即使网络中的某些部分无法通信,导致消息在节点之间可能会丢失或延迟。
CAP 理论指出,在分布式系统中,无法同时满足一致性、可用性和分区容错性这三个要求。在任何分布式系统中,只能满足其中的两个。这是因为当分布式系统遇到网络分区或故障时,如果要保持一致性,可能会牺牲可用性,反之亦然。
2.分布式系统类型
根据 CAP 理论的划分,分布式系统可以分为以下三种类型:
-
CP:保证一致性和分区容错性,可能牺牲可用性。这意味着系统在遇到网络分区或节点故障时,会停止对外提供服务,以确保数据的一致性。 -
CA:保证一致性和可用性,但可能会牺牲分区容错性。这种情况下,分布式系统在面临网络分区时,会选择保持一致性和可用性,但可能无法对所有请求都提供响应。 -
AP:保证可用性和分区容错性,但可能牺牲一致性。在这种情况下,系统会继续对外提供服务,即使数据在节点之间不一致。
需要注意的是,CAP 理论的描述是一个理论性的极端情况,实际系统往往会在这三个属性之间进行权衡,根据具体的需求和应用场景做出合适的选择。
3.Base 理论
BASE 理论是一个与分布式数据库系统和分布式系统设计相关的概念,它是对 CAP 理论的一种实际应用和权衡。BASE 是一个缩写,代表着三个关键属性:
-
基本可用性(Basically Available):系统保证在有限时间内对客户端的请求做出响应,即使系统发生部分故障或者数据不一致。 -
软状态(Soft state):系统中的数据状态可能会随着时间的推移而发生变化,即时不同节点间的数据副本不一致。 -
最终一致性(Eventual Consistency):系统保证在一段时间内,如果不再发生更新,系统中的所有数据副本最终会达到一致的状态。这与强一致性(如 ACID)不同,强一致性要求在任何时间点都保持数据一致,而最终一致性允许在一段时间内存在不一致的状态。
BASE 理论的思想是,分布式系统可以放松强一致性的要求,从而获得更高的可用性和性能。在分布式系统中,由于网络延迟、节点故障等因素,实现强一致性可能会导致性能问题。相反,采用最终一致性的策略,允许数据在一段时间内不同步,但会在后续的处理中逐渐达到一致状态,从而更好地满足系统的可用性和性能需求。
需要注意的是,BASE 理论并不是绝对的,它适用于某些分布式系统和应用场景,但不适用于所有情况。在设计分布式系统时,根据具体的业务需求和性能要求,可以选择适当的一致性级别和数据管理策略。
4.集群对比
- rebalance 数据重分配
- 扩容
- 是否有副本
- 是否有分片
- 是否主从
- 如何负载均衡
- 集群节点发现
- 宕机自修复
- 是否节点对等
5.链式调用
-
spring 中的 FilterChain,链式调用 filter
-
netty 中的 ChannelHandler
-
sentinel 中的 slot chain
-
java8 中的 stream 处理
-
spring 中的状态机模式定义
-
gatway 中的谓词 router
6.框架中的 COW
框架中用到的写时复制,copy on write
- Redis 的 Aof 文件重写
- SpringCloud Alibaba 中的 Sentinel 中的 slotChain
- ArrayList 扩容时
7.时间轮算法
时间轮算法(Time Wheel Algorithm)是一种用于处理定时事件的数据结构和算法。它主要用于操作系统、网络通信和其他需要按时间调度任务的场景。时间轮算法基于一个循环的时间轮结构,类似于一个时钟,其中每个刻度代表一个时间单位,例如毫秒或秒。
时间轮算法的主要思想是将时间分成若干个连续的间隔,每个间隔称为一个刻度(tick)。每个刻度上都可以安排一个或多个任务,这些任务都会在对应的刻度触发执行。当时间轮转动时,当前刻度会不断变化,触发相应刻度上的任务执行。
算法的基本步骤如下:
-
初始化时间轮:创建一个循环数组(或链表),每个元素代表一个刻度,每个刻度上存储需要执行的任务列表。
-
插入任务:将需要定时执行的任务插入到对应的刻度上。如果任务需要在未来的几个刻度后执行,可以在相应的刻度上存储任务信息。
-
时间前进:随着时间的推移,时间轮会不断前进。每次时间轮前进一个刻度,当前刻度会指向下一个刻度,这时候会触发当前刻度上存储的所有任务执行。
-
处理任务:当时间轮前进时,会触发当前刻度上存储的任务执行。这些任务可以是需要执行的函数、事件通知等。
-
移除任务:一旦任务被执行,它可以从时间轮中移除。如果任务是重复性的,可以在执行后重新插入到合适的刻度上,实现周期性执行。
时间轮算法的优势在于它适用于需要精确时间控制的场景,同时具有较高的效率。然而,时间轮也有其局限性,例如在需要更高时间精度或动态调整定时任务的情况下可能不太适用。
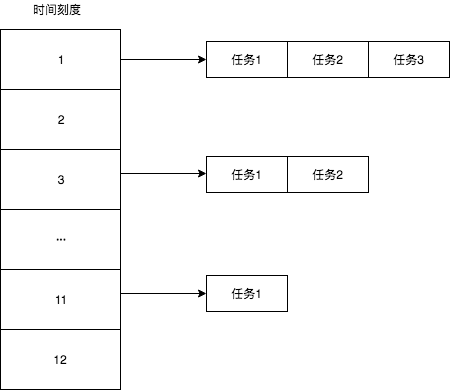
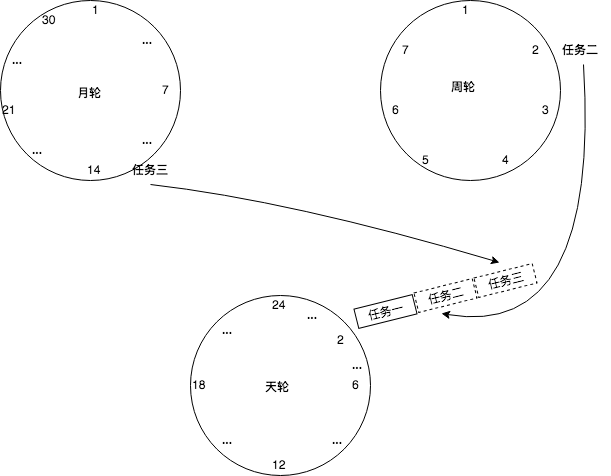
分层时间轮:
8.分布式痛点问题有哪些?
需要了解诸如秒杀抢购等场景的架构实现方案,以及方案解决的痛点问题,这类问题往往需要先提炼痛点问题,再针对痛点问题做优化。
分布式系统是由多台计算机或服务器组成的系统,它们通过网络相互通信和协作,以完成复杂的任务。然而,分布式系统也面临着许多痛点和挑战,以下是一些常见的问题:
-
通信延迟和带宽限制: 分布式系统中的计算机之间需要进行网络通信,这会导致通信延迟和带宽限制。这可能会影响系统的性能和响应时间。
-
数据一致性: 在分布式系统中,多个节点可能并发地读写数据,因此需要解决数据一致性的问题。维护一致性通常需要使用复杂的算法和协议,如分布式事务。
-
故障处理: 分布式系统中的节点可能会因为硬件故障、网络问题或软件错误而失败。因此,需要实现故障检测和故障恢复机制,以确保系统的可用性和可靠性。
-
分布式存储: 数据的分布式存储和管理是一个复杂的问题。需要考虑数据的分片、备份、恢复等方面,以确保数据的可靠性和可用性。
-
负载均衡: 在分布式系统中,需要确保各个节点之间的负载均衡,以避免某些节点过载,而其他节点空闲的情况。
-
安全性: 分布式系统需要保护数据的机密性和完整性,同时还需要考虑身份验证、授权和防止网络攻击等安全问题。
-
系统复杂性: 分布式系统往往比单一系统更加复杂,因为涉及到多个节点、多个组件和多个网络连接。这增加了开发、调试和维护的难度。
-
性能调优: 在分布式系统中,性能调优是一个挑战,需要仔细设计和配置系统,以确保在高负载时仍能提供良好的性能。
-
扩展性: 随着业务的增长,分布式系统可能需要扩展,这要求系统具备良好的可扩展性,能够容易地添加新的节点或资源。
-
监控和诊断: 对于分布式系统,监控和诊断问题变得更加复杂。需要使用专业的工具和技术来监控系统的健康状况,并快速定位和解决问题。
这些问题只是分布式系统中的一部分挑战,解决它们需要深入的技术知识和合适的工具和方法。因此,分布式系统的设计和管理是一项复杂而具有挑战性的任务。
二.分布式事务
1.分布式事务解决方案
分布式事务是在分布式系统中处理跨多个资源、服务或数据库的事务操作的问题。由于分布式系统的特性,确保一致性和可靠性变得更加复杂。为了解决这个问题,出现了多种分布式事务解决方案。以下是一些常见的分布式事务解决方案:
-
两阶段提交(Two-Phase Commit,2PC):在这种协议中,有一个协调者(Coordinator)和多个参与者(Participants)。在第一阶段,协调者询问所有参与者是否准备好提交事务。如果所有参与者都准备好了,协调者会发送一个提交请求,然后进入第二阶段。在第二阶段,所有参与者会执行实际的提交操作。如果有一个参与者出现问题,整个事务会回滚。
-
三阶段提交(Three-Phase Commit,3PC):3PC 在 2PC 的基础上增加了一个准备阶段,以减少某些情况下的阻塞和超时问题。在第一阶段,协调者询问所有参与者是否准备好提交事务。在第二阶段,协调者会告知所有参与者是否要提交或中止事务。在第三阶段,所有参与者执行实际的提交或回滚操作。
-
XA 协议(Two-Phase Commit): XA 协议是一种传统的分布式事务协议,它通过协调器(Coordinator)来确保分布式事务的一致性。在这个协议中,参与事务的各个资源管理器(Resource Manager)会向协调器报告事务的执行状态,并在协调器的协调下执行事务的提交或回滚。XA 协议具有强一致性,但也有较高的性能开销和单点故障的风险。
-
TCC(Try-Confirm-Cancel):TCC 是一种补偿型的分布式事务解决方案,它将事务分为三个阶段:尝试(Try)、确认(Confirm)和取消(Cancel)。在尝试阶段,参与者会尝试执行事务操作,但不会真正提交。在确认阶段,参与者确认操作,并提交更改。如果有问题,可以在取消阶段进行回滚操作。
-
Saga 模式:Saga 是一种长时间运行的事务,通过将大事务分解为一系列较小的子事务来处理。每个子事务负责自己的提交和回滚逻辑。如果一个子事务失败,相应的补偿操作将会触发。Saga 模式依赖于应用程序的逻辑来处理一致性和回滚。
-
消息队列:使用消息队列作为分布式事务的一部分,将事务操作封装为消息,并将其发送到队列中。接收者在处理消息时执行相应的操作。如果操作失败,可以通过消息重试机制或者定制的补偿操作来处理。
-
基于时间戳的一致性:通过记录操作的时间戳和状态信息来实现一致性。参与者可以根据时间戳来判断是否可以执行操作,从而避免冲突。
-
GTM(Global Transaction Manager): GTM 是一种集中式的全局事务管理器,它负责协调分布式事务的提交和回滚。不同于 Seata,GTM 通常将事务数据存储在单独的数据库中,而不是嵌入到应用的业务数据库中。
每种解决方案都有其优缺点,具体的选择要取决于应用程序的需求、性能要求以及容忍的一致性级别。在实际应用中,根据业务场景的不同,可能需要结合多种解决方案来实现分布式事务的一致性和可靠性。
2.如何解决 TCC 中悬挂问题?
TCC(Try-Confirm-Cancel)是一种用于分布式事务处理的模式,它将一个大的事务拆分为三个阶段:尝试(Try)、确认(Confirm)和取消(Cancel)。每个阶段对应一个操作,而整个事务的一致性由这三个操作共同保证。TCC 模式能够在分布式环境中实现较高的事务一致性和可靠性。
悬挂问题是 TCC 模式中的一个关键挑战,指的是在执行过程中,一个分支事务的确认操作成功,但由于某些原因导致其后续的分支事务的确认或取消操作无法继续执行。这可能会导致部分事务的状态不一致,影响整个分布式事务的一致性。
以下是解决 TCC 中悬挂问题的一些方法:
-
超时机制: 在 TCC 模式中,可以为每个分支事务设置一个超时时间。如果一个分支事务的确认或取消操作在超时时间内未完成,系统可以自动执行一些补救操作,如执行重试、回滚等,以确保事务的完整性。
-
事务状态标记: 在 TCC 模式中,可以为每个分支事务引入状态标记,表示事务的当前状态(尝试、确认、取消)。当一个分支事务的确认操作成功时,将状态标记为“已确认”;当取消操作成功时,将状态标记为“已取消”。系统可以定期扫描未完成的事务,检查状态标记,然后采取相应的补救措施。
-
异步通知与补偿: 当一个分支事务的确认操作成功时,可以异步地通知其他相关的分支事务进行确认或取消操作。这样即使一个分支事务的确认操作悬挂,其他事务可以继续执行,然后系统可以通过补偿操作来纠正状态不一致的情况。
-
定时任务: 引入定时任务来检查未完成的事务,发现悬挂事务并进行处理。这可以是一个周期性的任务,负责扫描系统中的事务状态并执行相应的补救操作。
-
日志和审计: 在 TCC 模式中,记录详细的事务日志和审计信息。这些信息可以帮助系统管理员或开发人员识别和解决悬挂问题,以及执行必要的恢复操作。
解决 TCC 中悬挂问题需要结合超时机制、事务状态标记、异步通知与补偿、定时任务以及日志审计等方法,以确保在分布式环境中维护事务的一致性和可靠性。
3.如何回滚 MQ 和 Redis?
在分布式事务场景中,涉及到 Redis 和消息队列(MQ)的回滚是一个复杂的问题,因为这涉及到多个不同的存储系统之间的一致性。回滚策略可以根据具体的业务需求和技术选型来确定。以下是关于如何处理分布式事务中的 Redis 和 MQ 回滚的一些一般策略:
Redis 回滚:
Redis 本身不支持传统的分布式事务,但您可以通过以下方法来实现一定程度的回滚:
-
操作日志: 在进行分布式事务操作时,将涉及到的 Redis 操作记录到一个日志中。如果事务的后续步骤发生错误,您可以根据日志信息进行回滚,即撤销已执行的操作。
-
备份和恢复: 在事务开始之前,可以将涉及到的 Redis 数据进行备份。如果事务失败,您可以使用备份数据来恢复到事务之前的状态。
-
使用 MULTI/EXEC 命令: Redis 提供了
MULTI和EXEC命令来创建事务块。您可以在事务块中执行多个命令,并在执行失败时使用DISCARD命令来取消事务,或者使用EXEC命令提交事务。如果事务失败,您可以使用DISCARD来回滚之前的操作。
消息队列(MQ)回滚:
在消息队列中处理回滚通常需要考虑以下策略:
-
事务消息: 一些消息队列系统(如 Apache Kafka)支持事务消息。您可以将数据库操作和消息发送放在同一个事务中,然后在提交事务时同时提交消息和数据库操作,或者在回滚时同时进行回滚。
-
消息状态管理: 如果消息队列不支持事务消息,您可以在数据库中维护消息的状态。当事务开始时,将消息状态设置为“待处理”。如果事务成功,则将消息状态设置为“已处理”。如果事务失败,则将消息状态设置为“待处理”,以便稍后重新处理。
-
死信队列: 一些消息队列支持死信队列,用于处理处理失败的消息。您可以将处理失败的消息移动到死信队列,并在稍后处理。
需要注意的是,处理分布式事务回滚是一个复杂的问题,需要根据具体的业务需求和技术选型来选择合适的回滚策略。在实际应用中,您可能需要结合数据库事务和消息队列的特性,设计适合自己应用场景的回滚机制。
4.最终一致性
分布式最终一致性是指在分布式系统中,尽管在一段时间内数据副本之间可能存在不一致的状态,但经过一段时间后,系统最终会达到一致的状态。这种一致性模型允许在分布式系统中的各个节点之间存在一段时间的数据不一致,但最终数据会收敛到一致状态,从而保证系统的可用性和可靠性。
分布式最终一致性通常涉及以下几种策略和模式:
-
异步复制: 分布式系统中的数据副本可能会异步地复制到其他节点,导致在某个时间点上节点之间的数据状态不一致。但随着时间的推移,副本会趋于一致。
-
事件驱动: 将系统中的数据变更表示为事件,并通过消息队列将这些事件传播到其他节点。每个节点按照接收到的事件按序处理数据更新,最终达到一致状态。
-
版本控制: 为每个数据副本引入版本控制,记录每次数据变更,然后通过协调机制在副本之间传播这些变更,确保数据最终一致。
-
定时同步: 定期在各个节点之间进行数据同步,通过定时任务将数据从一个节点同步到其他节点,逐步实现数据的一致性。
-
基于时间戳: 在数据副本上附加时间戳,然后使用时间戳来解决数据冲突和合并问题,使数据逐渐趋于一致。
-
基于版本号: 为每个数据副本引入版本号,允许数据更新时指定版本号,协调机制根据版本号解决并发写入的问题。
分布式最终一致性是一种折衷方案,权衡了分布式系统中的性能、可用性和数据一致性。这种一致性模型适用于一些弱一致性要求,例如社交网络的点赞数、阅读数等数据,在短时间内的不一致并不会严重影响用户体验。然而,对于某些领域,如金融、电子商务等,强一致性可能更为重要,因此需要根据具体的业务需求选择合适的一致性模型。
5.分布式 session 共享问题
分布式 Session 共享是指在一个分布式系统中,多个服务或节点需要共享用户会话(Session)数据,以保持用户在不同请求之间的状态和登录信息。这种情况常见于使用负载均衡、微服务架构或多节点的系统中。然而,实现分布式 Session 共享可能涉及一些挑战和考虑事项。
以下是与分布式 Session 共享相关的问题和解决方案:
问题:
-
一致性问题: 各节点之间的数据一致性可能受到网络延迟和故障的影响,可能会导致不同节点上的 Session 数据不一致。
-
性能问题: 分布式 Session 共享可能涉及跨网络的数据传输,可能会对性能产生一定影响。
-
Session 管理问题: 如何有效管理 Session 的过期和清理是一个挑战,特别是在分布式环境中。
解决方案:
-
共享存储: 使用共享存储(如数据库、缓存系统)作为 Session 存储的后端,以确保各节点可以访问和更新相同的 Session 数据。这种方式需要考虑一致性问题,如使用分布式锁来保护 Session 数据的更新。
-
无状态服务: 将 Session 数据从应用层移至客户端或无状态的服务,以避免 Session 共享的复杂性。使用 Token 验证可以在每个请求中传递用户身份和状态信息,而不依赖于服务器端的 Session 数据。
-
分布式缓存: 使用分布式缓存系统,如 Redis,来存储 Session 数据。这可以提高读写性能并提供一致性保证。同时,要关注缓存的失效策略。
-
一致性算法: 对于需要强一致性的场景,可以使用一致性算法(如 Paxos、Raft)来确保各节点上的 Session 数据保持一致。
-
版本控制: 在 Session 数据中引入版本控制,以便在更新时检测到冲突并解决。
-
定时清理: 使用定时任务来清理过期的 Session 数据,以避免存储占用过多空间。
-
分布式事务: 在需要的情况下,使用分布式事务来确保 Session 数据的一致性。
-
负载均衡策略: 在负载均衡时,尽量确保同一用户的请求被路由到相同的节点,以减少 Session 数据的迁移。
无论选择哪种解决方案,都需要根据具体场景和需求权衡不同的权衡,综合考虑一致性、性能、可靠性等因素。
6.注册中心脑裂问题?
从脑裂问题剖析 Nacos&Eureka&Zookeeper 架构
Nacos、Eureka 和 Zookeeper 都是用于服务注册与发现、配置管理等分布式系统领域的重要工具或框架。下面将分析这三者在面临脑裂问题时的架构特点和应对策略。
Nacos:
Nacos 是一个全面的服务发现、配置管理和服务管理平台。它的架构和应对脑裂问题的方式如下:
-
架构: Nacos 采用集群架构,由多个节点组成。其中,有一个或多个节点被选为主节点,负责协调服务注册、配置管理等任务。
-
应对策略: Nacos 使用心跳机制来监测节点的健康状态。如果一个节点被认为不健康,主节点可以将其标记为不可用,从而避免不一致性。Nacos 也支持使用多数投票(Quorum)来进行决策,确保操作的可靠性。
Eureka:
Eureka 是由 Netflix 开发的服务注册与发现系统。其架构和应对脑裂问题的方式如下:
-
架构: Eureka 由多个相互独立的节点组成,每个节点都可以扮演服务器和客户端角色。每个节点都会维护一个服务注册表,记录可用的服务实例。
-
应对策略: Eureka 使用心跳和定时任务来监测节点和服务实例的状态。当一个节点或实例被认为不可用时,其他节点会进行剔除或标记。Eureka 在节点之间的通信中引入了"自我保护模式",在网络分区等情况下,可以避免错误地移除健康实例。
Zookeeper:
Zookeeper 是一个分布式协调服务,可用于服务发现、配置管理等。其架构和应对脑裂问题的方式如下:
-
架构: Zookeeper 使用集群架构,每个节点都知道其他节点的状态。集群中的节点会选举一个主节点,其他节点作为从节点。
-
应对策略: Zookeeper 使用心跳机制和选主算法来监测节点的状态和选举主节点。在脑裂问题中,如果网络分区导致主节点和从节点无法通信,Zookeeper 的主从选举算法可以确保只有一个主节点被选出,从而避免数据的不一致性。
总体来说,Nacos、Eureka 和 Zookeeper 都考虑了脑裂问题,并采用了不同的机制来应对,如心跳监测、选主算法、多数投票等。无论选择哪个工具或框架,都需要根据实际需求、性能要求和可靠性等因素来进行选择和配置。
三.分布式锁
1.分布式锁与单机锁的区别?
分布式锁和单机锁之间有几个关键区别,这些区别主要涉及到锁的范围、性能、可用性和实现复杂性等方面:
-
锁的范围:
-
单机锁:单机锁是在单个进程或单个计算机上的线程之间使用的锁。它们适用于单个应用程序或单个进程内的并发控制。
-
分布式锁:分布式锁用于在分布式系统中的多个进程或计算机之间进行并发控制。它们用于协调不同计算机上的线程,以确保在整个分布式系统中的互斥操作。
-
-
性能:
-
单机锁:单机锁通常比分布式锁性能更高,因为它们不涉及网络通信和跨进程的同步。单机锁只需要在单个进程内部完成,开销相对较低。
-
分布式锁:分布式锁涉及到网络通信,因此通常比单机锁更消耗资源和时间。分布式锁的性能通常不如单机锁,但在分布式环境中是必要的。
-
-
可用性:
-
单机锁:单机锁的可用性受限于单个进程或计算机的可用性。如果进程或计算机崩溃或不可用,那么与之关联的单机锁也将不可用。
-
分布式锁:分布式锁可以提高可用性,因为它们可以在多个计算机上复制。即使某个计算机或进程不可用,其他计算机上的锁仍然可以正常运行。
-
-
实现复杂性:
-
单机锁:单机锁的实现通常较简单,可以使用内置的 Java 锁(如
synchronized)或标准库中的锁来轻松实现。 -
分布式锁:分布式锁的实现较复杂,需要考虑网络通信、故障恢复、一致性等因素。常见的分布式锁实现包括基于数据库、缓存、ZooKeeper 等技术,这些实现通常需要更多的工程和设计考虑。
-
分布式锁和单机锁之间的主要区别在于它们的范围、性能、可用性和实现复杂性。选择哪种类型的锁取决于您的应用程序需求和环境。在分布式系统中,使用分布式锁可以确保多个进程或计算机之间的数据一致性和互斥操作,但需要额外的开销和复杂性。在单机环境中,通常使用单机锁足以满足并发控制的需求。
2.分布式锁的特征?
- 高性能
- 可重入
- 线程互斥
分布式锁是用于在分布式系统中实现同步和互斥操作的一种机制。它具有以下特征和属性:
-
互斥性(Mutual Exclusion):分布式锁确保在任何给定时间点只有一个客户端或进程可以持有锁。这意味着一旦一个客户端成功获取锁,其他客户端将被阻止或排队,直到锁被释放。
-
可重入性(Reentrancy):分布式锁通常支持可重入性,允许同一个客户端多次获取同一个锁,而不会发生死锁。每次获取锁后,锁计数器会递增,而每次释放锁后,锁计数器会递减,直到为零才能完全释放锁。
-
超时机制(Timeout):分布式锁通常支持超时机制,允许客户端设置获取锁的超时时间。如果在指定的超时时间内无法获取锁,客户端可以选择放弃或重试。
-
阻塞和非阻塞模式:分布式锁通常支持阻塞和非阻塞两种模式。在阻塞模式下,如果无法获取锁,客户端将被阻塞,直到锁可用。在非阻塞模式下,如果无法获取锁,客户端会立即返回,而不会阻塞。
-
高可用性和容错性:分布式锁通常具有高可用性和容错性。它们可以在多个节点上部署,以确保即使某些节点或资源不可用,锁仍然可以正常工作。
-
自动释放(Automatic Release):分布式锁通常支持自动释放机制,以防止锁被长时间持有。客户端通常需要在一段时间后自动释放锁,以防止锁被意外持有。
-
实现方式多样:有多种方式可以实现分布式锁,包括基于数据库、缓存、ZooKeeper、Redis 等技术。每种实现方式都有其自身的特点和适用场景。
-
一致性保证:分布式锁通常会考虑数据一致性的问题,以确保在多个节点上的锁操作是一致的。这包括使用分布式事务或一致性协议来保证锁的正确性。
分布式锁是一种用于分布式系统中的并发控制的重要机制,具有互斥性、可重入性、超时机制、阻塞和非阻塞模式、高可用性、自动释放等特征。选择合适的分布式锁实现方式和配置参数取决于具体的应用场景和需求。
3.分布式锁的种类
分布式锁是用于在分布式系统中实现同步和互斥操作的一种机制。有多种分布式锁的实现方式,以下是一些常见的分布式锁种类:
-
基于数据库的分布式锁:可以使用数据库的事务来实现分布式锁。在这种方式下,数据库表中的某一行记录代表锁,通过数据库的事务来对这行记录进行加锁和释放锁操作。通常使用数据库的行级锁来确保互斥性。
-
基于缓存的分布式锁:使用分布式缓存系统如 Redis 或 Memcached 来实现分布式锁。在这种方式下,锁的状态通常是存储在缓存中的,可以使用缓存的原子操作来实现锁的获取和释放。
-
基于 ZooKeeper 的分布式锁:ZooKeeper 是一个分布式协调服务,可以用于实现分布式锁。通过在 ZooKeeper 中创建临时节点来表示锁的状态,可以确保在同一时刻只有一个客户端能够拥有这个锁。
-
基于文件系统的分布式锁:使用共享文件系统(如 NFS)来实现分布式锁。在这种方式下,锁的状态通常是存储在共享文件系统上的文件或目录,通过文件系统的锁机制来实现互斥操作。
-
基于分布式算法的分布式锁:一些分布式算法(如基于 Paxos 或 Raft 的一致性算法)也可以用于实现分布式锁。这些算法可以确保多个节点之间的数据一致性,从而实现分布式锁。
-
基于数据库乐观锁的分布式锁:使用数据库中的乐观锁机制(例如,版本号或时间戳)来实现分布式锁。客户端尝试通过更新数据库记录来获取锁,并检查是否成功。这种方式下,需要处理冲突和重试。
-
基于消息队列的分布式锁:使用分布式消息队列来实现分布式锁。锁的状态可以作为消息队列中的消息来表示,通过消息队列的原子性操作来实现锁的获取和释放。
每种分布式锁实现方式都有其优点和局限性,选择适合您应用需求的方式取决于多个因素,包括性能、复杂性、可用性和一致性要求等。不同的应用场景可能需要不同类型的分布式锁。
4.分布式锁的实现?
使用 ReentrantLock 的 tryLock 方法进行加锁,ReentrantLock 可以解决重入锁的问题,进而解决续期的问题。
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component
public @interface RedisLock {String value() default "";@AliasFor("key")String name() default "";@AliasFor("name")String key() default "";long expire() default 30000; // 默认锁的过期时间,单位毫秒long timeout() default 0; // 默认获取锁的超时时间,单位毫秒boolean fair() default false; // 是否使用公平锁
}
@Aspect
@Component
@Order(1) // 设置切面优先级
public class RedisLockAspect {private final StringRedisTemplate redisTemplate;public RedisLockAspect(StringRedisTemplate redisTemplate) {this.redisTemplate = redisTemplate;}@Around("@annotation(redisLock)")public Object doWithLock(ProceedingJoinPoint joinPoint, RedisLock redisLock) throws Throwable {String lockKey = getLockKey(redisLock);Lock lock = new ReentrantLock(redisLock.fair());boolean locked = false;try {locked = lock.tryLock(redisLock.timeout(), TimeUnit.MILLISECONDS);if (locked) {if (StringUtils.hasText(lockKey)) {redisTemplate.opsForValue().set(lockKey, "locked", redisLock.expire(), TimeUnit.MILLISECONDS);}return joinPoint.proceed();} else {throw new RuntimeException("Failed to acquire lock.");}} finally {if (locked) {lock.unlock();if (StringUtils.hasText(lockKey)) {redisTemplate.delete(lockKey);}}}}private String getLockKey(RedisLock redisLock) {String lockKey = redisLock.key();if (!StringUtils.hasText(lockKey)) {lockKey = redisLock.name();}return lockKey;}
}
5.分布式锁的续期?
分布式锁的续期是指在某个持有分布式锁的客户端需要延长锁的持有时间,以防止在执行长时间操作时锁过期导致其他客户端获取锁并干扰正在进行的操作。续期分布式锁通常涉及以下步骤:
-
获取锁: 客户端通过某种机制(如 Redis 的
SETNX命令)尝试获取分布式锁。如果成功获取锁,那么锁的持有者就是该客户端。 -
设置锁的过期时间: 在获取锁成功后,客户端可以通过设置锁的过期时间来确保即使在某些情况下锁没有被显式释放,也能在一定时间后自动释放。这通常使用 Redis 的
EXPIRE命令或类似的机制来完成。 -
续期: 在客户端持有锁的过程中,如果该客户端需要继续执行一些耗时的操作,可以选择续期锁的持有时间。续期通常涉及以下步骤:
- 客户端在执行操作时,可以定期检查自己是否还持有锁,以避免过期。
- 在续期时,客户端可以通过更新锁的过期时间,将锁的持有时间延长。
在 Redis 中,可以使用类似于
EXPIRE命令的PEXPIRE(以毫秒为单位的过期时间)来更新键的过期时间,从而实现锁的续期。 -
释放锁: 当客户端操作完成后,它可以通过删除锁的方式来释放锁,或者让锁在过期时自动释放。
需要注意的是,分布式锁的续期需要小心处理,以避免潜在的问题,如死锁或者某个客户端长时间持有锁而不释放。续期应该在合理的时间间隔内进行,以确保其他等待获取锁的客户端有机会获得锁资源。同时,续期操作可能会在某些极端情况下失败,如网络问题或锁服务的故障,因此需要考虑异常情况的处理。
6.Redisson 分布式锁公平锁
在代码和 Lua 中怎么做到加锁、解锁、锁续期
Redisson 是一个基于 Redis 的分布式锁框架,它提供了多种类型的分布式锁,包括公平锁。在 Redisson 中,公平锁的实现会涉及到以下几个关键概念:锁的持有者、锁的等待队列、锁的释放与续期。下面是使用 Redisson 实现公平锁的一些关键细节:
1. 加锁:
使用 Redisson 实现公平锁时,可以通过以下方式加锁:
RLock fairLock = redisson.getFairLock("myFairLock");
fairLock.lock();
try {// 在这里执行被锁保护的代码
} finally {fairLock.unlock();
}
这段代码首先获取一个公平锁对象fairLock,然后调用lock()方法来获取锁。如果锁当前不可用,线程将被阻塞,直到锁可用为止。一旦锁可用,线程就可以执行被锁保护的代码。请注意,使用try-finally块确保锁一定会被释放,以防止死锁。
2. 解锁:
解锁操作是自动的,当调用unlock()方法时,Redisson 会自动释放锁。在上面的示例中,try-finally块确保了在退出锁保护的代码块后一定会释放锁。
3. 锁续期:
Redisson 会自动续期锁的持有时间。如果一个线程在持有锁时出现了长时间的阻塞(例如,由于执行耗时的操作),Redisson 会定期为该锁续期,以确保其他等待锁的线程不会因为锁的过期而获取到锁。
4. 实现细节:
Redisson 在底层使用了 Redis 的原子操作来实现锁。它会使用 Lua 脚本来确保锁的原子性操作。以下是一些细节:
- 当一个线程尝试获取锁时,Redisson 会生成一个唯一的标识符(例如,UUID),然后将该标识符与锁关联,并将其设置为锁的值。
- 如果锁已经被其他线程持有,尝试获取锁的线程会将自己加入到锁的等待队列中。
- 当一个线程释放锁时,Redisson 会检查锁的值是否与其标识符匹配,如果匹配,则释放锁;否则,锁将保持不变,等待持有锁的线程继续执行。
- 续期操作是通过定期更新锁的过期时间来实现的。
使用 Redisson 可以很容易地实现分布式公平锁,Redisson 会处理锁的加锁、解锁和锁的续期等细节,使得在分布式环境中实现锁变得相对简单。在底层,Redisson 利用了 Redis 强大的原子操作能力来确保锁的正确性和一致性。
7.Redisson 分布式锁非公平锁
Redisson 支持非公平锁(Unfair Lock),与公平锁相比,非公平锁允许多个线程争夺锁的时候,不一定按照先来后到的顺序获取锁,而是按照竞争的速度获取锁。以下是使用 Redisson 实现非公平锁的一些关键细节:
1. 加锁:
使用 Redisson 实现非公平锁时,可以通过以下方式加锁:
RLock unfairLock = redisson.getLock("myUnfairLock");
unfairLock.lock();
try {// 在这里执行被锁保护的代码
} finally {unfairLock.unlock();
}
这段代码首先获取一个非公平锁对象unfairLock,然后调用lock()方法来获取锁。与公平锁不同,非公平锁不会保证等待锁的线程按照先后顺序获取锁,而是允许竞争速度更快的线程更早地获取到锁。
2. 解锁:
解锁操作与公平锁一样,也是自动的。当调用unlock()方法时,Redisson 会自动释放锁。
3. 实现细节:
Redisson 在底层使用了 Redis 的原子操作来实现非公平锁。以下是一些细节:
- 当一个线程尝试获取锁时,Redisson 会使用
SET命令来尝试将锁的值设置为一个唯一的标识符(例如,UUID)。 - 如果锁已经被其他线程持有,尝试获取锁的线程将无法成功,但它不会进入等待队列,而是会立即返回。
- 当一个线程释放锁时,Redisson 会检查锁的值是否与其标识符匹配,如果匹配,则释放锁;否则,锁将保持不变。
Redisson 可以轻松实现分布式非公平锁,它使用 Redis 的原子操作来确保锁的正确性和一致性。与公平锁不同,非公平锁允许多个线程竞争锁,并且允许竞争速度更快的线程更早地获取锁,适用于某些场景下对性能更高要求的情况。
8.Redisson 实现分布式锁读写锁
Redisson 是一个基于 Redis 的分布式 Java 对象服务框架,它提供了分布式锁的实现,包括读写锁。下面是使用 Redisson 实现分布式读写锁的一些关键细节:
1. 读写锁的加锁:
Redisson 提供了RLock接口用于表示分布式锁,其中包括读写锁。要使用读写锁,可以通过以下方式加锁:
RReadWriteLock rwLock = redisson.getReadWriteLock("myReadWriteLock");
RLock readLock = rwLock.readLock();
RLock writeLock = rwLock.writeLock();// 获取读锁
readLock.lock();
try {// 执行读操作
} finally {readLock.unlock();
}// 获取写锁
writeLock.lock();
try {// 执行写操作
} finally {writeLock.unlock();
}
这段代码首先获取一个读写锁对象rwLock,然后从中分别获取读锁readLock和写锁writeLock。读锁允许多个线程同时持有,而写锁是互斥的,只允许一个线程持有。
2. 读写锁的释放:
与通常的 Java 锁一样,Redisson 的读写锁也要求在使用完毕后显式释放。在上面的示例中,使用了try-finally块确保锁一定会被释放。
3. 实现细节:
Redisson 使用 Redis 的原子操作来实现读写锁。以下是一些细节:
- 当一个线程获取读锁时,Redisson 会在 Redis 中记录当前持有读锁的线程数量,并且在锁的值中增加一个标识符,表示这个线程持有读锁。
- 当一个线程获取写锁时,Redisson 会将锁的值设置为一个唯一的标识符,表示这个线程持有写锁。此时,其他线程无法获取读锁或写锁。
- 读锁和写锁在释放时会根据锁的类型(读锁或写锁)来更新锁的值,并在不再持有锁的情况下将其清除。
Redisson 还提供了一些其他功能,如读锁的重入性和锁的自动续期等,以增强锁的功能。总之,Redisson 使得在分布式环境中实现读写锁变得相对简单,使用了 Redis 的原子操作来确保锁的正确性和一致性。
四.高并发高可用
1.什么是接口幂等性?
接口幂等性是指无论调用接口的次数是一次还是多次,对系统的影响都是相同的。换句话说,无论接口被调用多少次,最终的结果应该是一致的。这个概念通常在分布式系统、Web 服务、API 设计等领域中讨论,旨在确保系统的稳定性、一致性和可靠性。
幂等性的一个常见用例是在进行写操作时,如创建、更新或删除数据。在这些情况下,如果多次请求接口,结果都应该是相同的,不会产生意外的重复操作或错误。
举个例子,考虑一个银行转账的接口。无论你调用这个接口一次还是多次,最终账户的余额变化应该是一样的。如果接口在多次调用时引发了多次转账,可能会导致账户余额错误或不一致。
确保接口幂等性通常需要以下一些方法:
-
唯一标识符: 在每次请求中使用唯一标识符(如请求 ID、事务 ID)来标识每个请求。服务器端可以使用这些标识符来检测是否已经处理过相同的请求。
-
幂等操作设计: 设计接口的操作,使得多次执行相同的操作不会产生额外的影响。例如,如果已经创建了某个资源,再次创建同一个资源应该返回相同的结果,而不会重复创建。
-
事务和状态管理: 对于需要修改系统状态的操作,使用事务来确保一致性。事务可以在操作失败时回滚之前的状态,从而避免重复修改。
-
幂等性检测: 在服务器端检测已经处理过的请求,如果检测到重复请求,则返回相同的结果而不会产生副作用。
-
幂等性标记: 为接口添加幂等性标记,允许客户端指定请求为幂等操作,从而通知服务器端在处理请求时保持幂等性。
-
响应和状态码: 使用适当的 HTTP 状态码和响应来表示操作的结果。例如,对于重复的幂等请求,可以使用 200 OK 表示之前已经执行过相同的操作。
确保接口的幂等性对于分布式系统和 API 设计至关重要,它可以减少因网络问题、重试或其他因素导致的数据不一致性和错误。
2.幂等和防重提交的区别
幂等性(Idempotence)和防重提交(Prevent Duplicate Submissions)是两个不同概念,它们通常用于描述不同方面的操作和处理,特别是在网络和分布式系统中。下面我会为你解释它们的区别:
-
幂等性(Idempotence):
- 幂等性是指无论对同一个操作执行多少次,结果都是一致的,也就是说,重复执行相同的操作不会产生不同的效果。这对于网络请求和分布式系统中的操作非常重要,因为它可以确保在网络中的各种情况下,操作不会重复执行或导致意外的副作用。
- 举例:HTTP 请求方法中的 GET 和 DELETE 通常是幂等的,因为它们不会更改服务器的状态,并且多次执行相同的请求不会产生不同的结果。
-
防重提交(Prevent Duplicate Submissions):
- 防重提交是一种策略,用于防止用户或系统在同一操作上重复提交数据。这通常与表单提交和数据更新有关。如果不采取防重提交措施,用户可能会多次提交相同的表单或数据,导致不必要的重复操作。
- 举例:当用户提交一个在线表单时,服务器通常会生成一个唯一的标识符(例如,令牌或会话 ID)并将其与提交的数据关联起来。如果用户再次提交相同的表单,服务器会检查该标识符,如果已经处理过相同的请求,则拒绝重复提交。
总结:
幂等性强调相同操作的重复执行不会改变结果,而防重提交则强调防止相同数据或请求的重复提交。在某些情况下,可以同时使用这两个概念,以确保在网络和分布式系统中的操作具有一致性并避免重复处理。
3.幂等在项目中的应用?
幂等性在不同的应用场景中具有重要作用:
幂等性是指对同一操作的多次执行具有相同的效果,无论执行多少次,结果都是一致的。这是在分布式系统中非常重要的概念,因为在网络通信中,消息可能会重复发送或处理。以下是一些应用场景:
-
支付系统: 在金融领域,幂等性非常重要。例如,如果用户多次点击支付按钮,系统应该只执行一次支付操作,而不会多次扣款。
-
消息队列处理: 当消息队列用于分发任务或消息时,消费者应该能够多次接收相同的消息,但只处理一次,以确保任务的幂等性。
-
REST API 设计: 在设计 RESTful API 时,应该使 API 具有幂等性,以便客户端可以多次调用相同的请求而不会产生不一致的结果。
在项目中,应用幂等性具体方式取决于项目的需求和架构。通常,使用幂等性可以确保系统在面对网络中断、消息重复或其他异常情况时仍然能够保持一致性。
4.一致性 hash 在项目中的应用?
一致性哈希是一种用于分布式数据存储和负载均衡的技术,它允许数据在不同节点之间进行分布,同时保持节点的动态可扩展性。以下是一些应用场景:
-
分布式缓存: 一致性哈希可用于将缓存数据分布到多个缓存节点,以实现负载均衡和水平扩展。
-
分布式数据库: 在分布式数据库中,一致性哈希可以用于决定将数据存储在哪个节点上,同时支持节点的动态添加和移除。
-
负载均衡: 一致性哈希可用于在分布式系统中均匀地分布请求,以避免某些节点过载。
-
分布式文件系统: 一致性哈希可用于将文件块分布到不同的存储节点上,以实现高可用性和容错性。
一致性哈希则有助于解决负载均衡和分布式数据存储的问题,提高系统的性能和可扩展性。
5.什么是布隆过滤器?
布隆过滤器(Bloom Filter)是一种空间效率很高的概率数据结构,用于判断一个元素是否存在于一个集合中。它基于哈希函数,可以快速地进行成员查询,但是在查询结果方面存在一定的概率性。
布隆过滤器的主要特点是:
-
快速成员查询: 布隆过滤器能够在常数时间内(与集合大小无关)进行成员查询,无需遍历整个集合,因此在处理大量数据时速度非常快。
-
空间效率高: 布隆过滤器只需要使用很少的额外内存空间来存储元素信息,这使得它在存储大量数据时占用的空间非常小。
-
概率性判断: 布隆过滤器在判断元素存在时是概率性的,即可能存在误判(判断某个元素存在,但实际上不存在)和漏判(判断某个元素不存在,但实际上存在)。
-
不支持元素删除: 布隆过滤器一般不支持从集合中删除元素,因为删除操作可能影响到其他元素的判断。
布隆过滤器的实现原理是通过一系列的哈希函数将每个元素映射到一个位数组(bit array)中的多个位置上,将这些位置置为 1。查询时,将待查询元素经过相同的哈希函数映射到位数组上,如果所有对应位置都为 1,则认为元素可能存在于集合中;如果有任何一个位置不为 1,则元素肯定不存在于集合中。
6.布隆过滤器作用?
由于布隆过滤器存在概率性误判的问题,因此适用于对于判断是否存在的问题,并且可以容忍一定的误判率。常见的应用包括:
- 缓存系统中判断某个数据是否在缓存中,从而避免无效的数据库查询。
- 网络爬虫中避免重复爬取相同的 URL。
- 分布式系统中的去重操作,避免重复处理相同的数据。
需要注意的是,布隆过滤器不能提供精确的查询结果,但在很多场景下,其高效的查询速度和较小的内存占用使其成为一个有价值的工具。
7.常见的分布式日志方案?
分布式日志方案是用于在分布式系统中管理、收集、存储和分析日志数据的解决方案。这些方案旨在处理大量的日志数据,以便识别问题、监控系统健康状况和进行数据分析。以下是一些常见的分布式日志方案:
-
ELK Stack(Elasticsearch, Logstash, Kibana): ELK Stack 是一个开源的分布式日志处理方案,由 Elasticsearch 用于存储和索引日志数据,Logstash 用于采集、处理和转发日志,Kibana 用于展示和可视化日志数据。它们的组合可以提供强大的日志分析和查询功能。
-
Graylog: Graylog 是一个开源的日志管理和分析平台,提供收集、存储、搜索和分析日志的功能。它支持高可用部署、灵活的数据处理流水线以及实时搜索和可视化。
-
Fluentd: Fluentd 是一个开源的日志收集和传输工具,用于将日志从不同的源传输到不同的目标。它支持多种数据源和数据目标,可以将日志聚合到中央存储或分发到多个位置。
-
Splunk: Splunk 是一个商业的日志管理和分析平台,可以用于收集、索引、搜索和分析大量的日志数据。它提供实时搜索、可视化、报表和警报功能,适用于大规模的日志分析需求。
-
Apache Kafka: 虽然 Kafka 主要是用于分布式消息传递,但它也可以用作日志收集工具。通过将日志数据发送到 Kafka 主题中,然后由订阅者消费和处理日志数据,可以实现分布式日志收集。
-
Prometheus: 虽然主要是一个监控和报警系统,Prometheus 也可以用于日志收集。它提供强大的数据存储和查询能力,可用于存储和查询日志数据。
-
Apache Hadoop: Hadoop 生态系统中的组件,如 HDFS 和 HBase,可以用于存储和管理大规模的日志数据。这对于需要进行大数据分析的场景特别有用。
这些分布式日志方案都有其优势和适用场景,选择适合自己需求的方案时,需要考虑数据量、性能需求、可用性、可视化和分析功能等因素。
8.简介 prometheus
Prometheus 是一个开源的监控和警报系统,旨在帮助用户收集、存储、查询和可视化系统和服务的时间序列数据。它由 SoundCloud 开发并于 2012 年开源发布。Prometheus 是一个独立的项目,但也与云原生生态系统和容器技术(如 Kubernetes)紧密集成。
以下是 Prometheus 的一些主要特点和功能:
-
多维数据模型: Prometheus 使用具有标签(Label)的时间序列数据模型,这意味着每个样本数据都带有键-值对标签。这样的模型支持多个维度的灵活查询和聚合。
-
数据采集和存储: Prometheus 支持多种方式的数据采集,可以从各种应用、服务、操作系统和中间件中收集指标数据。收集的数据会存储在本地的时间序列数据库中。
-
查询语言: Prometheus 提供了 PromQL 查询语言,可以用于从存储的数据中进行查询、聚合和计算。PromQL 支持范围查询、聚合操作、数学计算等功能。
-
数据可视化: Prometheus 可以与多种数据可视化工具集成,如 Grafana,用于创建仪表盘和图表,以便对监控数据进行直观的可视化。
-
告警和警报: Prometheus 具有强大的告警机制,可以根据指标数据的阈值设置警报规则,并在条件满足时触发警报通知。
-
自动发现: Prometheus 支持自动发现和目标服务的配置,通过服务发现机制可以动态地添加、删除或更新监控目标。
-
高度可扩展: Prometheus 支持水平扩展,可以通过添加更多的实例来处理更大规模的监控工作负载。
-
云原生集成: Prometheus 与云原生技术(如 Kubernetes)集成紧密,可以自动发现和监控容器、Pod 等资源。
Prometheus 在云原生生态系统中得到广泛应用,适用于监控分布式系统、微服务架构、容器化应用等场景。它的灵活的数据模型、强大的查询语言和可扩展性使其成为了一个流行的监控和告警解决方案。
9.简介 Grafana
Grafana 是一个开源的数据可视化和监控平台,用于创建仪表盘、图表和报表,帮助用户将复杂的数据转化为可视化的图形形式,从而更直观地理解数据。Grafana 最初是为 Graphite 设计的,但现在已经成为一个通用的多数据源监控和可视化平台。
以下是 Grafana 的一些主要特点和功能:
-
多数据源支持: Grafana 支持连接多种不同的数据源,包括时间序列数据库(如 Prometheus、InfluxDB)、日志数据库(如 Elasticsearch)、关系型数据库(如 MySQL、PostgreSQL)等。
-
丰富的可视化选项: Grafana 提供各种可视化选项,包括折线图、柱状图、饼图、仪表盘、地图等,用户可以根据需要选择最适合的图表类型。
-
高度可定制: 用户可以自定义图表的样式、颜色、标签等,以及仪表盘的布局和外观,从而创建符合自己需求的数据可视化界面。
-
告警和警报: Grafana 支持设置告警规则,当指标数据满足预定义条件时,可以触发警报通知,帮助用户及时发现和解决问题。
-
插件生态系统: Grafana 有丰富的插件生态系统,用户可以通过插件扩展功能,集成不同的数据源、图表类型等。
-
团队协作: Grafana 支持多用户和团队协作,可以为不同用户设置权限,共享仪表盘和报表。
-
云原生支持: Grafana 可以与云原生技术(如 Kubernetes)紧密集成,通过自动发现和监控容器、Pod 等资源。
Grafana 的易用性和灵活性使其成为了一个受欢迎的数据可视化和监控平台。无论是在开发者、运维人员,还是数据分析师等角色中,Grafana 都能够帮助用户更好地理解和利用数据。
五.分布式协议与算法
1.选举算法
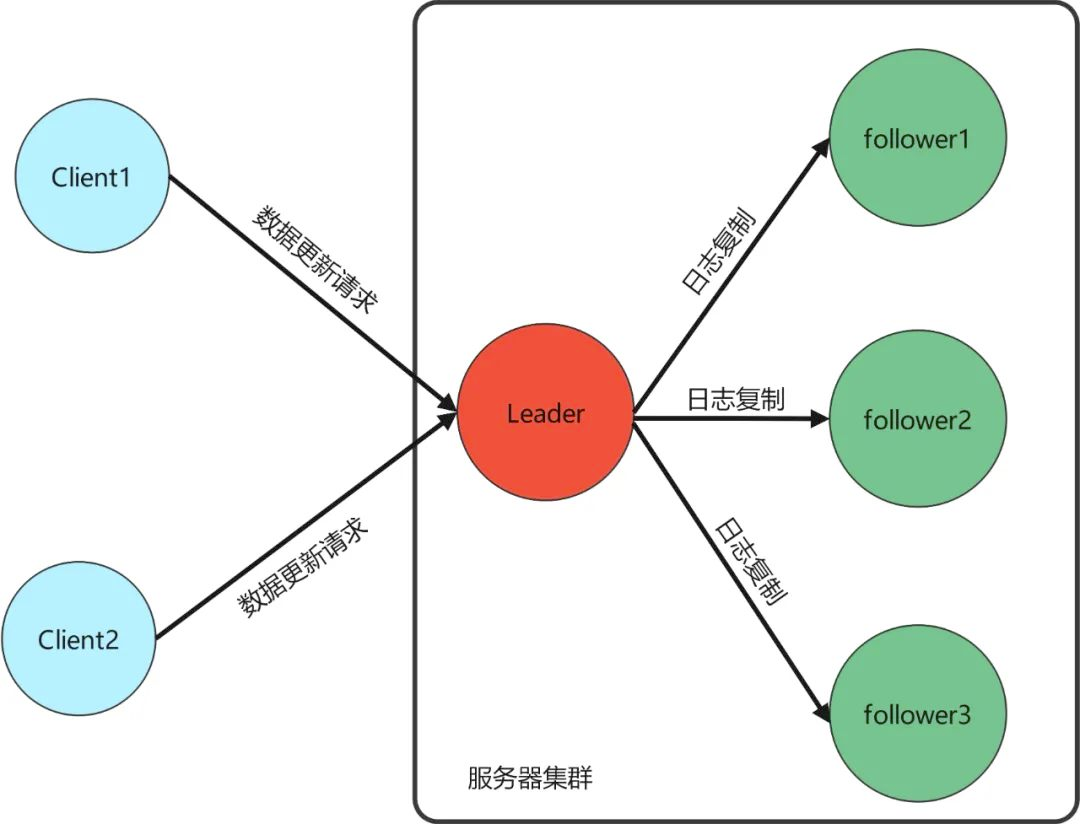
在分布式系统中采用的是主从架构,也就是有一个主节点,若干个从节点。主节点可以执行读写操作,从节点只执行读操作。采用这种一主多从的方案,可以有效保证了数据的一致性(哪怕不是强一致性,也能有效保证最终一致性)。
在开源的 Redis,MongoDB,Zookeeper 等软件中也都采用了的选举算法,常用的选举算法有以下三种:Bully 算法,Raft 算法,ZAB 算法。
2.Bully 算法
Bully 算法是一种简单直接的算法,因为它的选举原则是取 ID 的最大值作为主节点。在 Bully 算法中,有两种节点角色:普通节点和主节点。初始化的时候,所有节点都是普通节点。当主节点挂掉了,才会发起下一轮选举。
在选举中,有三种消息,分别是Election消息,用于发起选举。Alive消息,对Elelction消息的回复。Victory消息是选主成功后向其他节点发送的通知消息。选举过程如下:
-
集群中每个节点判断一下自己的节点 ID 是否为存活节点中最大,如果是则直接发送 Victory 消息,宣布自己为主节点。
-
如果自己不是最大的 ID 节点,则向比自己大的节点发送 Election 消息,等待其他节点回复。
-
在指定时间内没有收到其他节点 Alive 信息,则认为自己是主节点,然后向其他节点发送 Victory 消息,宣布自己是主节点。如果收到比自己 ID 大的节点 Alive 消息,则等待其他节点发送 Victory 消息。
-
如果收到比自己节点 ID 小的消息,则回复 Alive 消息,告诉对方重新选举。
该算法简单易于实现,但是当频繁有节点加入或退出,会造成频繁主节点切换。当应用在节点数量稳定的系统中,该算法的通用性可能还不错。此外,在 MongoDB 中故障迁移也采用了这个算法,它是采用最后操作的时间戳作为节点 ID,在实际生产中,我们还可以使用启动的时间作为 ID。
3.Raft 算法
提起分布式系统,Raft 算法是一个基础的算法。这种算法开创了投票选举的先例。核心思想就是“少数服从多数”,获得投票最多的节点就是主节点。
在 Raft 算法中,节点有三种角色:
-
Leader:主节点,同一时刻只有一个主节点。
-
Candidate:候选节点,节点处于该状态才能选举为 Leader 节点。
-
Follower:Leader 节点的跟随者,不能发起选举。
Raft 选举流程如下:
-
初始化阶段,每个节点都是 Follower 状态。
-
进入选举阶段时,每个节点进入 Candidate 状态,并向其他节点发送选举 Vote 请求。
-
其他节点根据收到选举请求的顺序回复是否同意成为主节点,在每一轮选举中每个候选人只有一张选票。
-
若发起选举的节点超过一半选票,则成为主节点,状态转换为 Leader,其他节点状态有 Candidate 转换为 Follower,leader 和 follower 之间有周期性的心跳包,用于检测主节点存活。
-
Leader 节点的周期到了,会自动降为 Follower,进入下一轮选主。当然了,当前 Leader 节点挂掉了也会由 Follower 发起新一轮选举。
目前集群管理容器 Kubernetes 采用的 etcd 组件就是采用 Raft 选举算法进行的。总之,Raft 算法选举速度快,缺点是要求系统内每个节点都可以通信,因此通信容量大。
Nacos 中集群保证一致性算法采用 Raft 协议模式,采用心跳机制实现选举的。
Raft 协议是分布式系统领域中的一种一致性算法,用于实现分布式系统中多个节点之间的一致性和协调。与 Paxos 等其他一致性算法相比,Raft 协议的设计更加直观和易于理解,因此在教学和实际应用中都得到了广泛的关注和应用。Raft 协议由 Diego Ongaro 和 John Ousterhout 在 2013 年提出。
Raft 协议的核心思想是将分布式一致性问题分解为三个关键的角色:领导者(Leader)、跟随者(Follower)和候选人(Candidate)。协议的运作分为以下几个阶段:
-
领导者选举(Leader Election): 初始状态下,所有节点都是候选人。候选人在一轮选举中请求其他节点的选票,获得大多数选票的候选人成为领导者。领导者负责提出日志条目和复制日志。
-
日志复制(Log Replication): 领导者负责提出日志条目,并将其广播给其他节点。其他节点将接收到的日志条目存储在本地日志中,并向领导者发送确认。一旦领导者确认大多数节点已经存储了特定的日志条目,该条目被视为“已提交”。
-
安全性保障: Raft 协议通过约束性质来确保安全性。具体来说,一个已经提交的日志条目在以后的日志中不会被覆盖或更改。
Raft 协议的主要目标是确保以下性质:
- 一致性: 在任何时间,所有节点的日志内容是一致的。
- 可用性: 只要多数节点可用,系统就能够接受读取和写入请求。
- 安全性: 只有领导者可以提出新的日志条目,而其他节点会遵循领导者的日志来保持一致。
Raft 协议的设计使得它相对于一些复杂的算法(如 Paxos)来说更容易理解和实现,因此在分布式系统领域得到了广泛的应用。许多开源项目和数据库,如 etcd、CockroachDB 等,都使用了 Raft 协议作为底层的一致性算法。
4.ZAB 算法
ZAB算法英文叫 Zookeeper Atomic Broadcast,是改进了 Raft 算法而用于zookeeper分布式协调服务的一种算法。这种算法引入了节点 ID 和数据 ID 作为参考进行选择主节点。节点 ID 或数据 ID 越大,表示数据越新。所以相比 Raft 算法,ZAB 算法尽可能保证了数据的最新。
ZAB 算法有三种角色:
- Laeder 节点。即主节点
- Follower 节点,也就是从节点。
- Obserer 节点,观察节点,无投票权利。
选举过程中,节点拥有四种状态。分别是:
- Looking 状态:即选举状态,当进入这种状态,节点会认为集群中没有主节点,自己会进入选举状态。
- Leading 状态:表示已经选出了主节点,当前节点为 Leader。
- Following 状态:表示集群中已经选出了主节点,其他非主节点更新自己的状态为 Following。
- Observer 状态:当前节点处于该状态没有投票和选举权。
投票过程中,每个节点有一个唯一的三元组(server_id,server_zxid,epoch),其中 Server_id 代表当前节点的 ID,server_zxid代表数据(事务 id),该值越大表示数据越新。epoch 为当前选举轮数。选举原则为 server_zxid 最大为主节点,若相同则 server_id 最大为主节点。
该算法性能很好,对系统无特殊要求,一般采用广播的方式发送消息。但是当集群内集群数据庞大,也容易出现网络风暴。此外,选举过程需要节点 ID 和数据事务 ID,因此选举周期可能稍长。不过有新节点的加入也不一定触发新的选举。
4.Paxos 协议
Paxos 协议是分布式系统领域中的一种一致性算法,用于在分布式系统中实现多个节点之间的一致性和协调。Paxos 协议由 Leslie Lamport 于 1989 年首次提出,它解决了分布式系统中的状态机复制问题,即如何在不同节点之间复制和保持相同的状态。
Paxos 协议的核心思想是通过投票和协商来达成共识,使得多个节点能够就某个值达成一致意见。Paxos 协议分为多个阶段,每个阶段都有不同的角色和任务。主要包括以下几个阶段:
-
提议阶段(Prepare Phase): 在这个阶段,一个节点(称为提议者)向其他节点发送一个提案,请求其他节点在不同条件下对提案进行批准或拒绝。提案包括提案编号和提议的值。
-
批准阶段(Promise Phase): 在收到提案后,其他节点(称为接收者)会比较提案编号,如果提案编号更高且没有承诺过其他提案,则接收者会向提议者发送一个承诺,表示愿意接受提案。
-
提交阶段(Accept Phase): 如果提议者收到足够的承诺,表示提案可以提交。提议者向所有节点发送提案,并要求节点接受该提案作为共识值。
Paxos 协议的主要目标是保证以下性质:
- 一致性: 所有正确的节点最终都会达成相同的共识值。
- 安全性: 如果一个值被选定为共识值,那么它一定是一个被提议者提出过的值。
- 活性: 只要大多数节点是正确的,提案最终会被选定为共识值。
尽管 Paxos 协议是一个经典的一致性算法,但其复杂性使得理解和实现都具有一定难度。因此,许多分布式系统和数据库在实际中使用了基于 Paxos 的变种或改进,如 Multi-Paxos、Fast Paxos、Zookeeper 中的 Zab 协议等,来满足分布式一致性需求。
5.选举算法对比
1.zookeeper 主从选举
zookeeper 作为一个分布式应用程序协调服务,在大型网站中,其本身也是集群部署的,安装 zookeeper 的时候最好是单数节点,因为要选举。Zookeeper 的 leader 节点是集群工作的核心,用来更新并保证 leader 和 server 具有相同的系统状态,Follower 服务器是 leader 的跟随者,用于接收客户端的请求并向客户端返回结果,在选举过程中参与投票。对于客户端而言,每个 zookeeper 都是一样的。
zookeeper 提供了三种选举策略:
LeaderElectionAuthFastLeaderElectionFastLeaderElection
下面主要讲解 FastLeaderElection 的选举原理
1.myId
每个 ZooKeeper 服务器,都需要在数据文件夹下创建一个名为 myid 的文件,该文件包含整个 ZooKeeper 集群唯一的 ID(整数)。例如,某 ZooKeeper 集群包含三台服务器,hostname 分别为 zoo1、zoo2 和 zoo3,其 myid 分别为 1、2 和 3,则在配置文件中其 ID 与 hostname 必须一一对应,如下所示。在该配置文件中,server. 后面的数据即为 myid
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888
2.zxid
服务器的事务 id,数据越新,zxid 越大;
3.epoch
逻辑时钟,在服务端是一个自增序列,每次进入下一轮投票后,就会加 1;
4.服务器状态
- LOOKING: 不确定 Leader 状态。该状态下的服务器认为当前集群中没有 Leader,会发起 Leader 选举。
- FOLLOWING: 跟随者状态。表明当前服务器角色是 Follower,并且知道 Leader 是谁。
- LEADING: 领导者状态。表明当前服务器角色为 Leader 角色,它会维护与 Follower 间的心跳。
- OBSERVING: 观察者状态。表明当前服务器角色是 Observer,与 Follower 的唯一不同在于不参与选举,也不参与集群写操作时的投票。
5.选票的数据结构
每个服务器在进行领导选举时,会发送如下关键信息:
- logicClock 每个服务器会维护一个自增的整数,名为
logicClock,它表示这是该服务器发起的第多少轮投票。 - state 当前服务器的状态。
- self_id 当前服务器的 myid。
- self_zxid 当前服务器上所保存的数据的最大 zxid。
- vote_id 被推举的服务器的 myid。
- vote_zxid 被推举的服务器上所保存的数据的最大 zxid。
6.投票流程
当系统启动或者 leader 崩溃后,就会开始 leader 的选举。
-
状态变更。服务器启动的时候每个 server 的状态时 Looking,如果是 leader 挂掉后进入选举,那么余下的非 Observer 的 Server 就会将自己的服务器状态变更为 Looking,然后开始进入 Leader 的选举状态;
-
发起投票。每个 server 会产生一个(myid,zxid)的投票,系统初始化的时候 zxid 都是 0,如果是运行期间,每个 server 的 zxid 可能都不同,这取决于最后一次更新的数据。将投票发送给集群中的所有机器;
-
接收并检查投票。server 收到投票后,会先检查是否是本轮投票,是否来自 looking 状态的 server;
-
处理投票。对自己的投票和接收到的投票进行 PK:
-
先检查zxid,较大的优先为leader 如果zxid一样,myid较大的为leader 根据PK结果更新自己的投票,在次发送自己的投票 -
统计投票。每次投票后,服务器统计投票信息,如果有过半机器接收到相同的投票,那么 leader 产生,如果否,那么进行下一轮投票;
-
改变 server 状态,一旦确定了 Leader,server 会更新自己的状态为 Following,选举结束。
补充说明:
- 在步骤 2 发送投票的时候,投票的信息除了 myid 和 zxid,还有:
electionEpoch:逻辑时钟,用来判断多个投票是否在同一轮选举周期中,该值在服务端是一个自增序列,每次进入新一轮的投票后,都会对该值进行加 1 操作。peerEpoch:被推举的 Leader 的 epoch。state:当前服务器的状态。
- 为了能够相互投票,每两台服务器之间都会建立网络连接,为避免重复建立 TCP 连接,zk 的 server 只允许 myid 大于自己的服务器与自己建立连接,否则断开当前连接,并主动和对方建立连接。
2.ES master 选举
选举时间点
Elasticsearch 在满足如下时间点的时候会触发选举
- 集群启动初始化。
- 集群 Master 崩溃的时候。
- 任何一个节点发现当前集群中 Master 节点没有得到 n/2+1 个节点的认可的时候,触发选举。
选举流程
1.筛选 activeMaster 列表
Es 的 master 就是从 activeMasters 列表或者 masterCandidates(master 候选节点)列表选举出来,所以选举之前 es 首先需要得到这两个列表。Elasticsearch 节点成员首先向集群中的所有成员发送 Ping 请求,elasticsearch 默认等待 discovery.zen.ping_timeout 时间,然后 elasticsearch 针对获取的全部 response 进行过滤,筛选出其中 activeMasters 列表,activeMaster 列表是其它节点认为的当前集群的 Master 节点。
源码如下:
List<DiscoveryNode> activeMasters = new ArrayList<>();
for (ZenPing.PingResponse pingResponse : pingResponses) {//不允许将自己放在activeMasters列表中if (pingResponse.master() != null && !localNode.equals(pingResponse.master())) {activeMasters.add(pingResponse.master());}
}
可以看到 elasticsearch 在获取 activeMasters 列表的时候会排除本地节点,目的是为了避免脑裂,假设这样一个场景,当前最小编号的节点 P0 认为自己就是 master 并且 P0 和其它节点发生网络分区,同时 es 允许将自己放在 activeMaster 中,因为 P0 编号最小,那么 P0 永远会选择自己作为 master 节点,那么就会出现脑裂的情况。
2.筛选 masterCandidates 列表
masterCandidates 列表是当前集群有资格成为 Master 的节点,如果我们在 elasticsearch.yml 中配置了如下参数,那么这个节点就没有资格成为 Master 节点,也就不会被筛选进入 masterCandidates 列表。
# 配置某个节点没有成为master资格
node.master:false
源代码如下所示:
List<ElectMasterService.MasterCandidate> masterCandidates = new ArrayList<>();
for (ZenPing.PingResponse pingResponse : pingResponses) {if (pingResponse.node().isMasterNode()) {masterCandidates.add(new ElectMasterService.MasterCandidate(pingResponse.node(), pingResponse.getClusterStateVersion()));}
}
3.从 activeMasters 列表选举 Master 节点
activeMaster 列表是其它节点认为的当前集群的 Master 节点列表,如果 activeMasters 列表不为空,elasticsearch 会优先从 activeMasters 列表中选举,选举的算法是 Bully 算法,Bully 算法会涉及到优先级比较, 在 activeMasters 列表优先级比较的时候,如果节点有成为 master 的资格,那么优先级比较高,如果 activeMaster 列表有多个节点具有 master 资格,那么选择 id 最小的节点。
代码如下:
private static int compareNodes(DiscoveryNode o1, DiscoveryNode o2) {if (o1.isMasterNode() && !o2.isMasterNode()) {return -1;}if (!o1.isMasterNode() && o2.isMasterNode()) {return 1;}return o1.getId().compareTo(o2.getId());
}//取ID最小的
public DiscoveryNode tieBreakActiveMasters(Collection<DiscoveryNode> activeMasters) {return activeMasters.stream().min(ElectMasterService::compareNodes).get();
}
4.从 masterCandidates 列表选举 Master 节点
如果 activeMaster 列表为空,那么会在 masterCandidates 中选举,masterCandidates 选举也会涉及到优先级比较,masterCandidates 选举的优先级比较和 activemasters 选举的优先级比较不同。它首先会判断 masterCandidates 列表成员数目是否达到了最小数目 discovery.zen.minimum_master_nodes。如果达到的情况下比较优先级,优先级比较的时候首先比较节点拥有的集群状态版本编号,然后再比较 id,这一流程的目的是让拥有最新集群状态的节点成为 master。
代码如下:
public static int compare(MasterCandidate c1, MasterCandidate c2) {//比较集群状态版本编码,取版本大的,使拥有集群最新状态的节点成为masterint ret = Long.compare(c2.clusterStateVersion, c1.clusterStateVersion);//如果版本号一样,则比较IDif (ret == 0) {ret = compareNodes(c1.getNode(), c2.getNode());}return ret;
}
5.本地节点是 master
经过上述选举之后,会选举出一个准 master 节点, 准 master 节点会等待其它节点的投票,如果有 discovery.zen.minimum_master_nodes-1 个节点投票认为当前节点是 master,那么选举就成功,准 master 会等待 discovery.zen.master_election.wait_for_joins_timeout 时间,如果超时,那么就失败。在代码实现上准 master 通过注册一个回调来实现,同时借助了 AtomicReference 和 CountDownLatch 等并发构建实现
if (clusterService.localNode().equals(masterNode)) {
final int requiredJoins = Math.max(0, electMaster.minimumMasterNodes() - 1);
nodeJoinController.waitToBeElectedAsMaster(requiredJoins, masterElectionWaitForJoinsTimeout,new NodeJoinController.ElectionCallback() {@Overridepublic void onElectedAsMaster(ClusterState state) {joinThreadControl.markThreadAsDone(currentThread);nodesFD.updateNodesAndPing(state); // start the nodes FD}@Overridepublic void onFailure(Throwable t) {logger.trace("failed while waiting for nodes to join, rejoining", t);joinThreadControl.markThreadAsDoneAndStartNew(currentThread);}}
);
本地节点是 Master 的时候,Master 节点会开启错误检测 (NodeFaultDetection 机制),它节点会定期扫描集群所有的成员,将失活的成员移除集群,同时将最新的集群状态发布到集群中,集群成员收到最新的集群状态后会进行相应的调整,比如重新选择主分片,进行数据复制等操作。
6.本地节点不是 master
当前节点判定在集群当前状态下如果自己不可能是 master 节点,首先会禁止其他节点加入自己,然后投票选举出准 Master 节点。同时监听 master 发布的集群状态 (MasterFaultDetection 机制),如果集群状态显示的 master 节点和当前节点认为的 master 节点不是同一个节点,那么当前节点就重新发起选举。
非 Master 节点也会监听 Master 节点进行错误检测,如果成员节点发现 master 连接不上,重新加入新的 Master 节点,如果发现当前集群中有很多节点都连不上 master 节点,那么会重新发起选举。
3.Redis 哨兵选举
哨兵的工作方式:
-
每个 Sentinel(哨兵)进程以每秒一次的频率向整个集群中的 Master 主服务器、Slave 从服务器以及其他哨兵进程发送一个 PING 命令。
-
如果一个实例距离最后一次有效回复 PING 命令的时间超过
down-after-milliseconds选型所指定的值,则这个实例会被哨兵进程标记为主观下线。 -
如果一个
Master主服务器被标记为主观下线,则正在监视这个Master主服务器的所有哨兵进程要以每秒一次的频率来确认Master主服务器是否的确进入了主观下线状态。 -
如果有足够数量(
quorum数量)的哨兵进程认为Master主服务器下线,则Master主服务器会被标记成客观下线。 -
在一般情况下,每个哨兵进程以每秒一次的频率向集群中的所有
master主服务器、Slave从服务器发送 Info 命令。当Master主服务器被标记为客观下线后,Info命令的频率从 10 秒一次改成 1 秒一次。 -
若没有足够数量的
Sentinel(哨兵)进程同意Master主服务器下线,Master主服务器的客观下线状态就会被移除。若Master主服务器重新向Sentinel(哨兵)进程发送PING命令返回有效回复,Master主服务器的主观下线状态就会被移除。
选举方式:
如果一个 Master 主服务器被标记为客观下线,并且 Majority 数量的哨兵都允许进行主备切换(如果没有 Majority 数量的哨兵同一主备切换时,是不允许进行主备切换的),选举一个领头的哨兵进行主备切换。
选举领头的哨兵
选举领头 sentinel 遵循以下规则:
-
所有的 sentinel 都有公平被选择成领头的资格。
-
所有的 sentinel 都只有一次将某个 sentinel 选举成领头的机会(在一轮选举中),一旦选举,则不能修改。
-
先到先得,一旦当前 sentinel 设置了领头 sentinel,以后要求设置 sentinel 都会被拒绝。
-
每个发现服务器客观下线的哨兵,都会要求其他哨兵将自己设置成领头哨兵。
-
当一个哨兵(源哨兵)向另一个哨兵(目标哨兵)发送
is-master-down-by-addr ip port current_epoch runid命令的时候,runid 参数不是*,而是sentinel运行 id,就表示源sentinel要求目标sentinel选举其为领头。 -
源哨兵会检查目标哨兵对其设置成领头的回复,如果回复的
leader_runid和leader_epoch为源哨兵,表示目标哨兵同意将源哨兵设置成领头。 -
如果某个哨兵被半数以上的哨兵设置成领头哨兵,则该哨兵就成为领头哨兵。
-
如果在限定时间内,没有选举出领头哨兵,暂停一段时间,再选举。
Master 主服务器选举
领头哨兵会对已客观宕机的 Master 主服务器和 Slave 从服务器进行主备切换。
选举 Slave 需要考虑以下的信息:
-
如果一个
slave跟master断开连接的时间已经超过了down-after-milliseconds的 10 倍,外加 master 宕机的时长,那么认为该slave不适合选举为master。 -
按照
slave的优先级进行排序,slave priority越低,优先级越高。 -
如果
slave的优先级一致,那么看replica offset,哪个 slave 复制了越多的数据,offset越靠后,优先级就越高。 -
如果优先级和
offset都一样,那么选择一个run ID比较小的那个slave。
4.Redis cluster 选举
判断节点宕机
如果一个节点认为另外一个节点宕机,那么就是 pfail ,主观宕机。如果多个节点都认为另外一个节点宕机了,那么就是 fail ,客观宕机,跟哨兵的原理几乎一样,sdown,odown。
在 cluster-node-timeout 内,某个节点一直没有返回 pong ,那么就被认为 pfail 。
如果一个节点认为某个节点 pfail 了,那么会在 gossip ping 消息中, ping 给其他节点,如果超过半数的节点都认为 pfail 了,那么就会变成 fail 。
Redis Cluster Master 主服务器选举:
对宕机的 master node,从其所有 slave node 中,选择一个切换成 master node。
-
检查每个
slave node与 master node 断开连接的时间,如果超过了 cluster-node-timeout * cluster-slave-validity-factor,那么没有资格切换成 master。 -
每个从节点,根据自己对 master 复制数据的
offset,来设置一个选举时间,offset越大(复制的数据越多)的从节点,选举时间越靠前,优先进行选举。 -
所有的
master node开始slave选举投票,给要进行选举的slave node进行投票,如果大部分master(N/2+1)都投票给某个从节点,那么选举通过,那个从节点可以切换成master。 -
从节点进行主备切换,从节点切换成主节点。
5.kafka parition 选举
Kafka 的 Leader 选举是通过在 zookeeper 上创建 /controller 临时节点来实现 leader 选举,并在该节点中写入当前 broker 的信息 {“version”:1,”brokerid”:1,”timestamp”:”1512018424988”}。利用 Zookeeper 的强一致性特性,一个节点只能被一个客户端创建成功,创建成功的 broker 即为 leader,即先到先得原则,leader 也就是集群中的 controller,负责集群中所有大小事务。当 leader 和 zookeeper 失去连接时,临时节点会删除,而其他 broker 会监听该节点的变化,当节点删除时,其他 broker 会收到事件通知,重新发起 leader 选举。
kafka 在所有 broker 中选出一个 controller,所有 Partition 的 Leader 选举都由 controller 决定。controller 会将 Leader 的改变直接通过 RPC 的方式(比 zookeeper queue 的方式有效)通知给需要为此作出响应的 Broker。同时 controller 也负责增删 Topic 以及 Replica 的分配。
六.Raft 算法
1.Raft 算法基本原理
共识算法就是保证一个集群的多台机器协同工作,在遇到请求时,数据能够保持一致。即使遇到机器宕机,整个系统仍然能够对外保持服务的可用性。
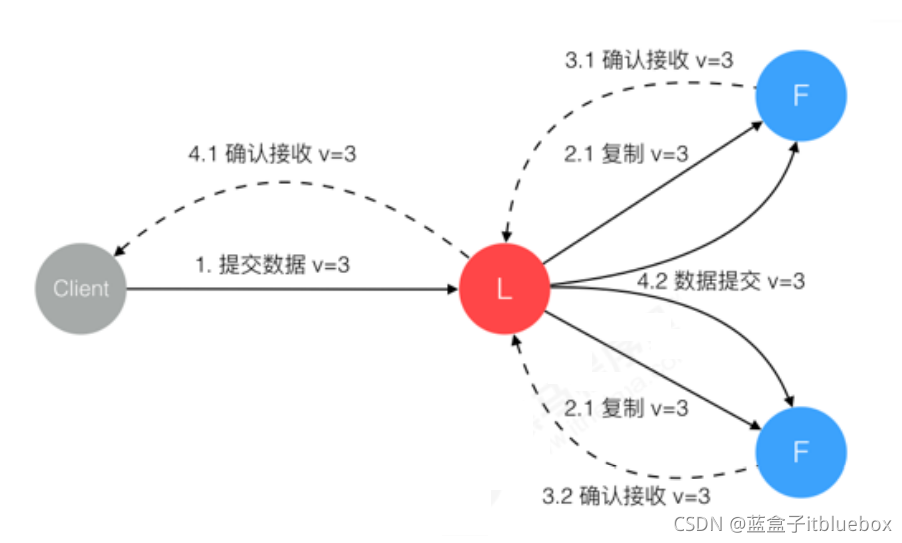
Raft 协议强依赖 Leader 节点来确保集群数据一致性。即 client 发送过来的数据均先到达 Leader 节点,Leader 接收到数据后,先将数据标记为 uncommitted 状态,随后 Leader 开始向所有 Follower 复制数据并等待响应,在获得集群中大于 N/2 个 Follower 的已成功接收数据完毕的响应后,Leader 将数据的状态标记为 committed,随后向 client 发送数据已接收确认,在向 client 发送出已数据接收后,再向所有 Follower 节点发送通知表明该数据状态为 committed。
2.Raft 三个子问题
Raft 将共识问题分解三个子问题:
- Leader election 领导选举:有且仅有一个 leader 节点,如果 leader 宕机,通过选举机制选出新的 leader;
- Log replication 日志复制:leader 从客户端接收数据更新/删除请求,然后日志复制到 follower 节点,从而保证集群数据的一致性;
- Safety 安全性:通过安全性原则来处理一些特殊 case,保证 Raft 算法的完备性;
3.Raft 算法核心流程
Raft 算法核心流程可以归纳为:
- 首先选出 leader,leader 节点负责接收外部的数据更新/删除请求;
- 然后日志复制到其他 follower 节点,同时通过安全性的准则来保证整个日志复制的一致性;
- 如果遇到 leader 故障,followers 会重新发起选举出新的 leader;
4.raft 协议角色
- Leader: 处理所有客户端交互,日志复制等,一般一次只有一个 Leader.
- Follower: 类似选民,完全被动
- Candidate(候选人): 可以被选为一个新的领导人。
Leader 全权负责所有客户端的请求,以及将数据同步到 Follower 中(同一时刻系统中只存在一个 Leader)。
Follower 被动响应请求 RPC,从不主动发起请求 RPC。
Candidate 由 Follower 向 Leader 转换的中间状态
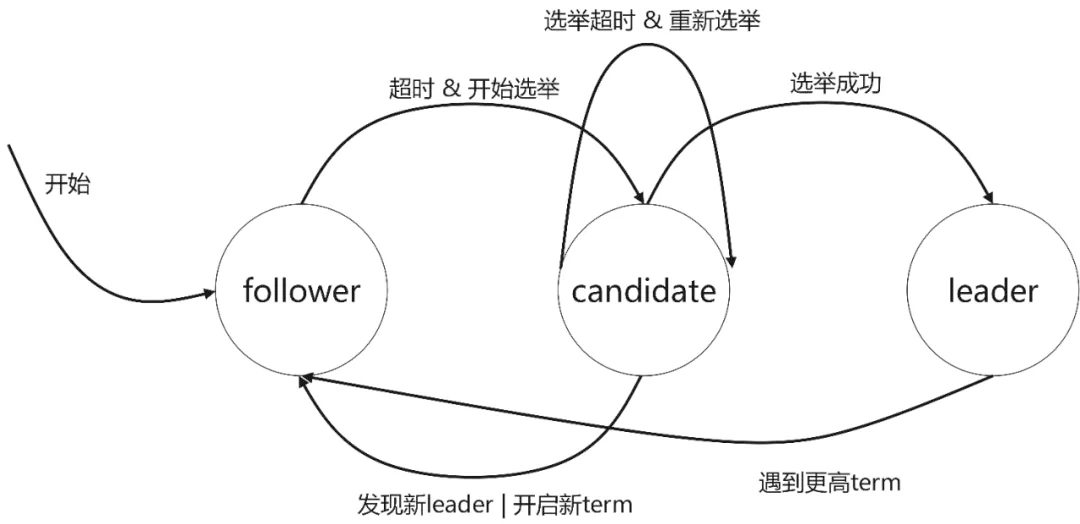
5.领导选举
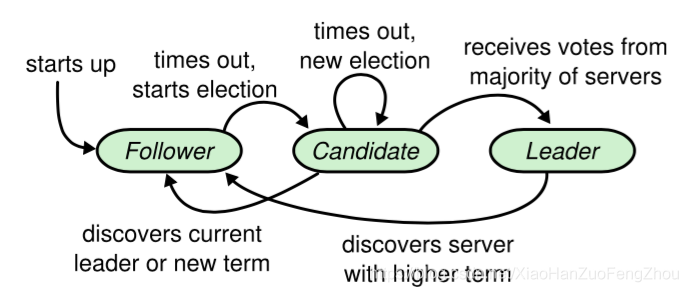
集群中每个节点只能处于 Leader、Follower 和 Candidate 三种状态的一种:
(1)follower 从节点:
- 节点默认是 follower;
- 如果刚刚开始或和 leader 通信超时,follower 会发起选举,变成 candidate,然后去竞选 leader;
- 如果收到其他 candidate 的竞选投票请求,按照先来先得 & 每个任期只能投票一次的投票原则投票;
(2)candidate 候选者:
- follower 发起选举后就变为 candidate,会向其他节点拉选票。candidate 的票会投给自己,所以不会向其他节点投票;
- 如果获得超过半数的投票,candidate 变成 leader,然后马上和其他节点通信,表明自己的 leader 的地位;
- 如果选举超时,重新发起选举;
- 如果遇到更高任期 Term 的 leader 的通信请求,转化为 follower;
(3)leader 主节点:
- 成为 leader 节点后,此时可以接受客户端的数据请求,负责日志同步;
- 如果遇到更高任期 Term 的 candidate 的通信请求,这说明 candidate 正在竞选 leader,此时之前任期的 leader 转化为 follower,且完成投票;
- 如果遇到更高任期 Term 的 leader 的通信请求,这说明已经选举成功新的 leader,此时之前任期的 leader 转化为 follower;
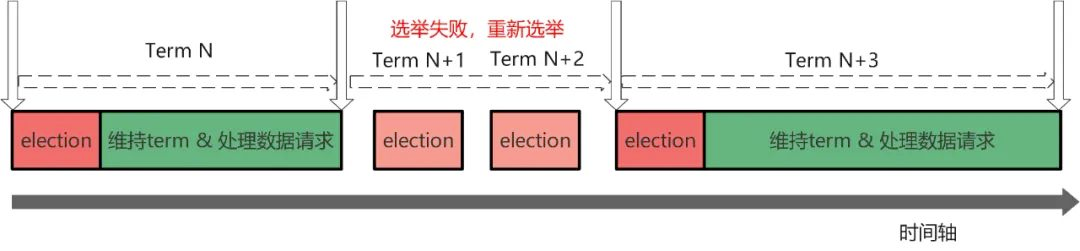
Raft 算法把时间轴划分为不同任期 Term。每个任期 Term 都有自己的编号 TermId,该编号全局唯一且单调递增。如下图,每个任务的开始都 Leader Election 领导选举。如果选举成功,则进入维持任务 Term 阶段,此时 leader 负责接收客户端请求并,负责复制日志。Leader 和所有 follower 都保持通信,如果 follower 发现通信超时,TermId 递增并发起新的选举。如果选举成功,则进入新的任期。如果选举失败,TermId 递增,然后重新发起选举直到成功。
举个例子,参考下图,Term N 选举成功,Term N+1 和 Term N+2 选举失败,Term N+3 重新选举成功。
具体的说,Leader 在任期内会周期性向其他 follower 节点发送心跳来维持地位。follower 如果发现心跳超时,就认为 leader 节点宕机或不存在。随机等待一定时间后,follower 会发起选举,变成 candidate,然后去竞选 leader。选举结果有三种情况:
(1)获取超过半数投票,赢得选举:
- 当 Candidate 获得超过半数的投票时,代表自己赢得了选举,且转化为 leader。此时,它会马上向其他节点发送请求,从而确认自己的 leader 地位,从而阻止新一轮的选举;
- 投票原则**:当多个 Candidate 竞选 Leader 时**
- 一个任期内,follower 只会投票一次票,且投票先来先得;
- Candidate 存储的日志至少要和 follower 一样新(安全性准则),否则拒绝投票;
(2)投票未超过半数,选举失败:
- 当 Candidate 没有获得超过半数的投票时,说明多个 Candidate 竞争投票导致过于分散,或者出现了丢包现象。此时,认为当期任期选举失败,任期 TermId+1,然后发起新一轮选举;
- 上述机制可能出现多个 Candidate 竞争投票,导致每个 Candidate 一直得不到超过半数的票,最终导致无限选举投票循环;
- 投票分散问题解决:Raft 会给每个 Candidate 在固定时间内随机确认一个超时时间(一般为 150-300ms)。这么做可以尽量避免新的一次选举出现多个 Candidate 竞争投票的现象;
(3)收到其他 Leader 通信请求:
- 如果 Candidate 收到其他声称自己是 Leader 的请求的时候,通过任期 TermId 来判断是否处理;
- 如果请求的任期 TermId 不小于 Candidate 当前任期 TermId,那么 Candidate 会承认该 Leader 的合法地位并转化为 Follower;
- 否则,拒绝这次请求,并继续保持 Candidate;
简单地说,Leader Election 领导选举通过若干的投票原则,保证一次选举有且仅可能最多选出一个 leader,从而解决了脑裂问题。
6.Raft 整个底层实现原理:
默认情况下选举的过程:
- 默认情况下每个节点都是跟随者角色;
- 每个节点随机生成一个选举的超时时间,大概为 100-300ms,在这个超时时间内必须要等待。
- 超时时间过后,当前节点的状态由跟随者变为竞选者状态,会给其他节点发出选举的投票通知,只要该竞选者有超过半数以上即可选为领导角色。
核心的设计原理就是谁超时时间最短谁成为领导角色的概率就最大。
故障的重新实现选举:
如果跟随者节点不能够及时的收到领导角色消息,那么这时候跟随者就会将当前自己的状态由跟随者变为京选择角色,会给其他节点发出选举的投票通知,只要该竞选者有超过半数以上即可选为领导角色。
疑问:是否可能会产生两个同事的竞选者呢?
- 如果所有的节点的超市随机数都一样的情况下,当前投票全部作废,重新进入随机生成超时时间;
- 如果有多个节点生成的随机数都是一样的情况下,比较谁的票数最多,谁就是领导。如果票数完全一样的情况下,直接作废,重新进入随机生成超时时间。
注意:建议集群节点为奇数,偶数节点容易造成死循环。
如何实现日志的复制:
- 所有的写的请求都是统一交给领导角色完成,写入该对应的日志,标记该日志为被提交状态;
- 为了提交该日志,领导角色就会将该日志以心跳的形式发送给其他的跟随者节点,只要超过半数的跟随者节点写入该日志,则直接通知其它跟随者节点同步该数据,这个过程称为日志复制的过程。
七.限流算法
1.限流算法
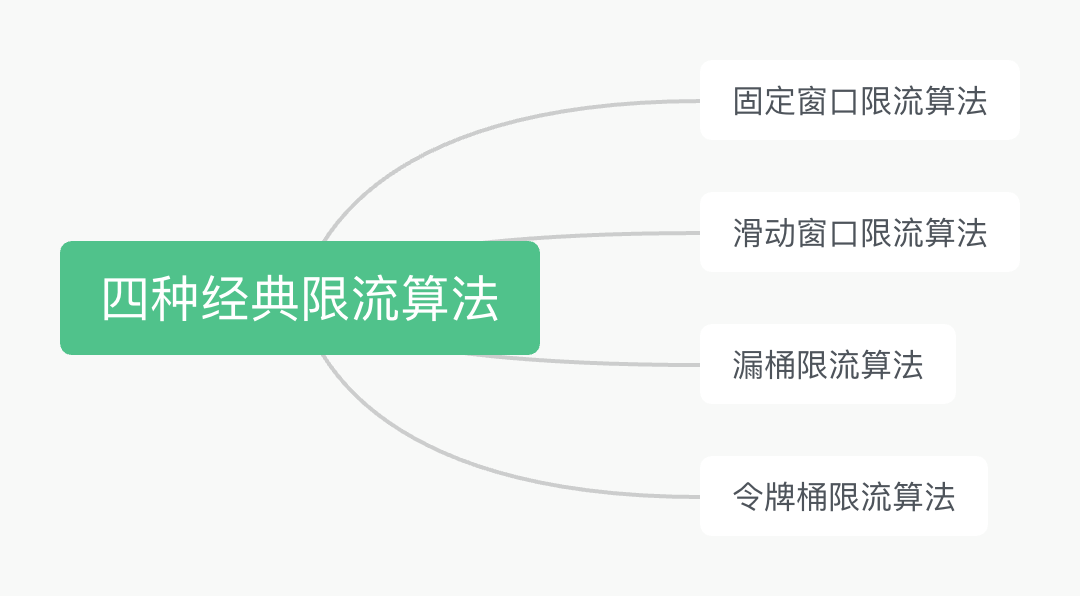
限流算法是一种用于控制流量的技术,通常用于防止系统过载、保护系统资源和提高系统的稳定性。在网络服务、分布式系统以及 API 接口中广泛应用。以下是一些常见的限流算法:
-
令牌桶算法(Token Bucket): 令牌桶算法基于令牌桶的概念,系统以恒定的速率往桶里放入令牌,每个请求需要一个令牌才能被处理。如果桶中没有足够的令牌,请求将被拒绝。这种算法可以平滑地处理突发流量。
-
漏桶算法(Leaky Bucket): 漏桶算法以恒定的速率处理请求,无论流量的突发性如何。如果流量超出了系统能够处理的速率,多余的请求会被缓存在漏桶中,然后按照恒定速率被处理。
-
计数器算法: 这是一种简单的限流方法,基于时间窗口内请求的数量。例如,在一分钟内只允许处理 1000 个请求。一旦达到限制,后续的请求将被拒绝或排队等待。
-
平滑窗口算法: 这种算法将时间分割为多个窗口,每个窗口内有一个请求计数器。旧的计数器会在时间窗口滑动时被清除,新的请求将增加计数器。这可以平滑处理突发流量。
-
基于演化的算法: 一些算法会根据系统的实际情况进行动态调整,例如根据系统的负载、响应时间等动态地调整限流策略。
-
优先级队列算法: 在资源有限的情况下,可以使用优先级队列来确保高优先级的请求能够优先被处理。
-
混合算法: 有时候会将多种限流算法结合起来,以在不同情况下都能够有效地控制流量。
选择适合的限流算法取决于系统的需求、特点以及性能要求。限流算法有助于保护系统免受恶意请求、过载和资源耗尽的影响,从而提高系统的可用性和稳定性。
2.固定窗口限流算法
固定窗口限流算法(Fixed Window Rate Limiting Algorithm)是一种最简单的限流算法,其原理是在固定时间窗口(单位时间)内限制请求的数量。该算法将时间分成固定的窗口,并在每个窗口内限制请求的数量。具体来说,算法将请求按照时间顺序放入时间窗口中,并计算该时间窗口内的请求数量,如果请求数量超出了限制,则拒绝该请求。
假设单位时间(固定时间窗口)是1秒,限流阀值为3。在单位时间1秒内,每来一个请求,计数器就加1,如果计数器累加的次数超过限流阀值3,后续的请求全部拒绝。等到1s结束后,计数器清0,重新开始计数。
固定窗口算法的优缺点:
- 优点:固定窗口算法非常简单,易于实现和理解。
- 缺点:存在明显的临界问题,比如: 假设限流阀值为
5个请求,单位时间窗口是1s,如果我们在单位时间内的前0.8-1s和1-1.2s,分别并发 5 个请求。虽然都没有超过阀值,但是如果算 0.8-1.2s,则并发数高达 10,已经超过单位时间 1s 不超过 5 阀值的定义啦。

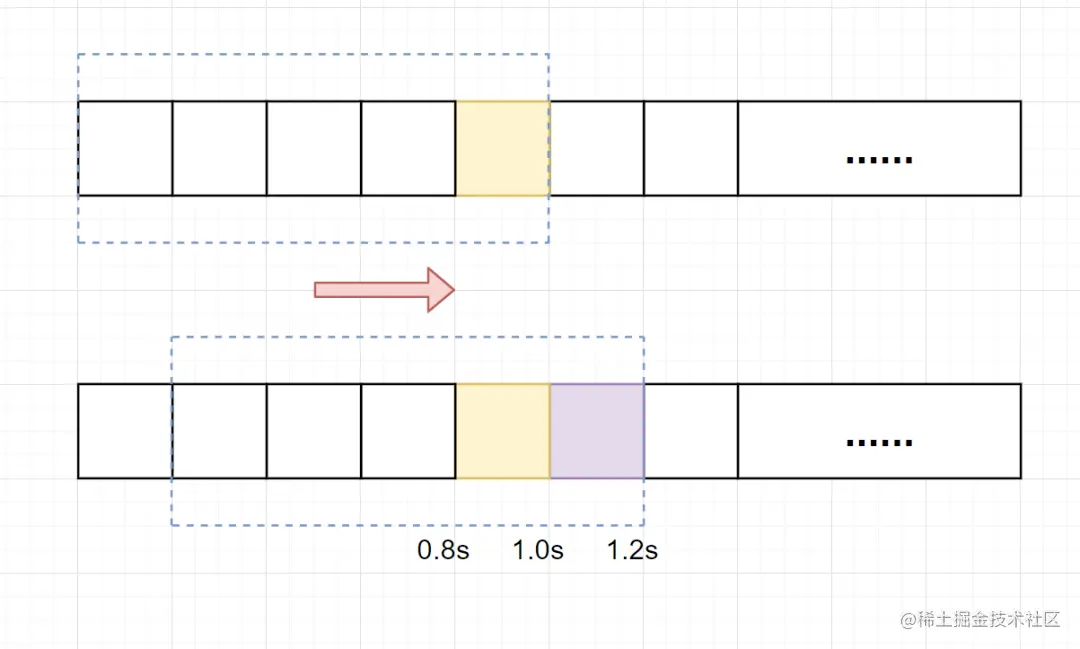
3.滑动窗口算法?
滑动窗口限流算法是一种常用的限流算法,用于控制系统对外提供服务的速率,防止系统被过多的请求压垮。它将单位时间周期分为n个小周期,分别记录每个小周期内接口的访问次数,并且根据时间滑动删除过期的小周期。它可以解决固定窗口临界值的问题。
为了解决计数器算法的临界值的问题,发明了滑动窗口算法。在 TCP 网络通信协议中,就采用滑动时间窗口算
法来解决网络拥堵问题。
滑动时间窗口是将计数器算法中的实际周期切分成多个小的时间窗口,分别在每个小的时间窗口中记录访问次数,然后根据时间将窗口往前滑动并删除过期的小时间窗口。最终只需要统计滑动窗口范围内的小时间窗口的总
的请求数即可。

在上图中,假设我们设置一分钟的请求阈值是 100,我们将一分钟拆分成 4 个小时间窗口,这样,每个小的时间窗口只能处理 25 个请求,我们用虚线方框表示滑动时间窗口,当前窗口的大小是 2,也就是在窗口内最多能处理
50 个请求。随着时间的推移,滑动窗口也随着时间往前移动,比如上图开始时,窗口是 0:00 到 0:30 的这个范围,过了 15 秒后,窗口是 0:15 到 0:45 的这个范围,窗口中的请求重新清零,这样就很好的解决了计数器算法的临界值问题。
在滑动时间窗口算法中,我们的小窗口划分的越多,滑动窗口的滚动就越平滑,限流的统计就会越精确。
滑动窗口限流算法的优缺点:
优点:
- 简单易懂
- 精度高(通过调整时间窗口的大小来实现不同的限流效果)
- 可扩展性强(可以非常容易地与其他限流算法结合使用)
缺点:
- 突发流量无法处理(无法应对短时间内的大量请求,但是一旦到达限流后,请求都会直接暴力被拒绝。酱紫我们会损失一部分请求,这其实对于产品来说,并不太友好),需要合理调整时间窗口大小。
4.漏桶算法
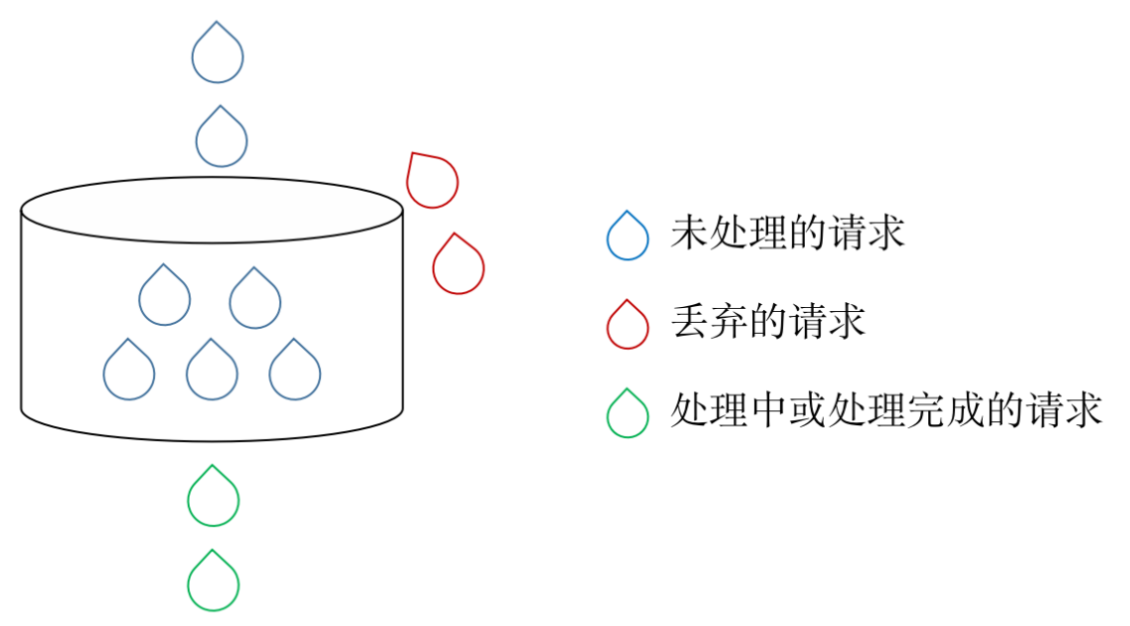
漏桶限流算法(Leaky Bucket Algorithm)是一种流量控制算法,用于控制流入网络的数据速率,以防止网络拥塞。它的思想是将数据包看作是水滴,漏桶看作是一个固定容量的水桶,数据包像水滴一样从桶的顶部流入桶中,并通过桶底的一个小孔以一定的速度流出,从而限制了数据包的流量。
漏桶限流算法的基本工作原理是:对于每个到来的数据包,都将其加入到漏桶中,并检查漏桶中当前的水量是否超过了漏桶的容量。如果超过了容量,就将多余的数据包丢弃。如果漏桶中还有水,就以一定的速率从桶底输出数据包,保证输出的速率不超过预设的速率,从而达到限流的目的。
- 流入的水滴,可以看作是访问系统的请求,这个流入速率是不确定的。
- 桶的容量一般表示系统所能处理的请求数。
- 如果桶的容量满了,就达到限流的阀值,就会丢弃水滴(拒绝请求)
- 流出的水滴,是恒定过滤的,对应服务按照固定的速率处理请求。
漏桶限流算法的优缺点:
优点
- 可以平滑限制请求的处理速度,避免瞬间请求过多导致系统崩溃或者雪崩。
- 可以控制请求的处理速度,使得系统可以适应不同的流量需求,避免过载或者过度闲置。
- 可以通过调整桶的大小和漏出速率来满足不同的限流需求,可以灵活地适应不同的场景。
缺点
- 需要对请求进行缓存,会增加服务器的内存消耗。
- 对于流量波动比较大的场景,需要较为灵活的参数配置才能达到较好的效果。
- 但是面对突发流量的时候,漏桶算法还是循规蹈矩地处理请求,这不是我们想看到的啦。流量变突发时,我们肯定希望系统尽量快点处理请求,提升用户体验嘛。
5.令牌桶算法
令牌桶算法是一种常用的限流算法,可以用于限制单位时间内请求的数量。该算法维护一个固定容量的令牌桶,每秒钟会向令牌桶中放入一定数量的令牌。当有请求到来时,如果令牌桶中有足够的令牌,则请求被允许通过并从令牌桶中消耗一个令牌,否则请求被拒绝。
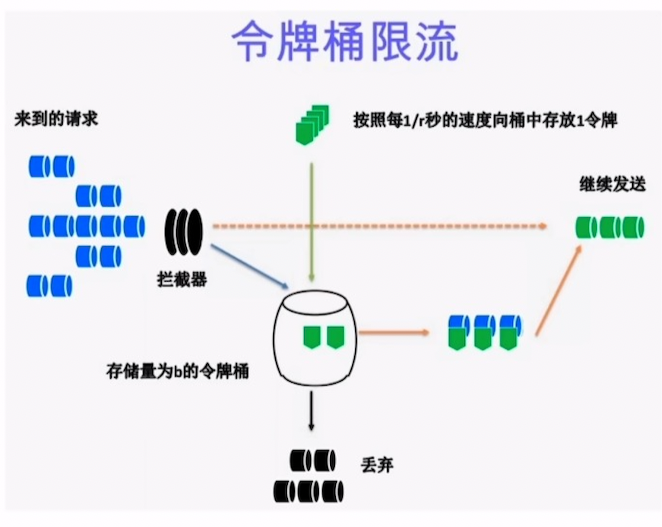
漏桶算法和令牌桶算法都是用于实现流量控制和限流的算法,但它们的原理和适用场景略有不同。
漏桶算法: 漏桶算法模拟了一个漏桶,请求被认为是水滴,以固定的速率流出(漏出)系统。如果流入的请求速率超过了漏桶的容量,多余的请求将会被丢弃或者等待下一个时间段。漏桶算法适用于平滑流量,防止系统被大量突发流量压垮。但是,对于短时间内的突发流量,漏桶算法并不是特别有效,因为它无法快速处理瞬时大量的请求,而只能以固定的速率处理。
令牌桶算法: 令牌桶算法也是一种流量控制算法,它基于一个令牌桶的概念。令牌以一定的速率被添加到桶中,每个请求在处理之前需要获取一个令牌,如果没有可用的令牌,则请求将被暂时阻塞或丢弃。令牌桶算法可以适应瞬时的突发流量,因为当桶中积累足够多的令牌时,可以快速处理突发请求,而不会受限于固定的速率。这使得令牌桶算法更适合处理突发流量的情况。
令牌桶算法的优缺点:
优点:
- 稳定性高:令牌桶算法可以控制请求的处理速度,可以使系统的负载变得稳定。
- 精度高:令牌桶算法可以根据实际情况动态调整生成令牌的速率,可以实现较高精度的限流。
- 弹性好:令牌桶算法可以处理突发流量,可以在短时间内提供更多的处理能力,以处理突发流量。
Guava的RateLimiter限流组件,就是基于令牌桶算法实现的。
缺点:
- 实现复杂:相对于固定窗口算法等其他限流算法,令牌桶算法的实现较为复杂。 对短时请求难以处理:在短时间内有大量请求到来时,可能会导致令牌桶中的令牌被快速消耗完,从而限流。这种情况下,可以考虑使用漏桶算法。
- 时间精度要求高:令牌桶算法需要在固定的时间间隔内生成令牌,因此要求时间精度较高,如果系统时间不准确,可能会导致限流效果不理想。
6.令牌桶算法种类
令牌桶允许一定程度的突发调用,那么关于令牌桶处理数据报文的方式,RFC 中定义了两种令牌桶算法:
单速率三色标记(single rate three color marker,srTCM,RFC2697 定义,或称为单速双桶算法)算法,主要关注报文尺寸的突发。
双速率三色标记(two rate three color marker,trTCM,RFC2698 定义,或称为双速双桶算法)算法,主要关注速率的突发。
两种算法都是为报文打上红、黄、绿三种颜色的标记,所以称为“三色标记”。 根据报文的颜色,设置报文的丢弃优先级,两种算法都可工作于色盲模式和非色盲模式。
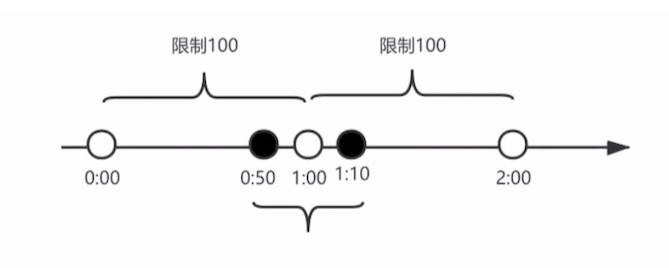
7.什么是计数器算法?
计数器算法,是指在指定的时间周期内累加访问次数,达到设定的阈值时,触发限流策略。下一个时间周期
进行访问时,访问次数清零。此算法无论在单机还是分布式环境下实现都非常简单,使用 redis 的 incr 原子自增
性,再结合 key 的过期时间,即可轻松实现。
从上图我们来看,我们设置一分钟的阈值是 100,在 0:00 到 1:00 内请求数是 60,当到 1:00 时,请求数清零,从 0 开始计算,这时在 1:00 到 2:00 之间我们能处理的最大的请求为 100,超过 100 个的请求,系统都拒绝。
这个算法有一个临界问题,比如在上图中,在 0:00 到 1:00 内,只在 0:50 有 60 个请求,而在 1:00 到 2:00 之间,只在 1:10 有 60 个请求,虽然在两个一分钟的时间内,都没有超过 100 个请求,但是在 0:50 到 1:10 这 20 秒内,确有 120 个请求,虽然在每个周期内,都没超过阈值,但是在这 20 秒内,已经远远超过了我们原来设置的 1 分钟内 100 个请求的阈值。
8.令牌桶和漏桶算法区别
内容上:令牌桶算法是按固定速率生成令牌,请求能从桶中拿到令牌就执行,否则执行失败。漏桶算法是任务进桶速率不限,但是出桶的速率是固定的,超出桶大小的的任务丢弃,也就是执行失败。突发流量适应性上:令牌桶限制的是流入的速率且灵活,允许一次取出多个 token,只要有令牌就可以处理任务,在桶容量上允许处理突发流量。而漏桶算法出桶的速率固定,有突发流量也只能按流出的速率处理任务,所以漏桶算法是平滑流入的速率,限制流出速率。
八.架构设计
1.设计一个 IM 系统
设计一个即时消息(IM)系统涉及许多方面,从基本的架构到具体的技术组件。以下是一个详细的设计示例:
1. 架构选择:
分布式架构是构建高性能、可扩展的 IM 系统的关键。采用微服务架构,将不同的功能模块拆分成独立的服务,可以提高系统的可维护性和扩展性。以下是架构的主要组成部分:
2. 组件设计:
用户认证和授权服务: 负责处理用户的注册、登录、认证和授权。可以使用 OAuth 2.0 或 JWT 等技术来实现安全的用户身份验证。
消息传递服务: 用于处理消息的实时传递。可以采用 WebSocket 协议来实现双向通信,也可以结合轮询或长轮询等技术来确保消息的及时性。
好友管理服务: 处理用户之间的好友关系。存储用户的好友列表,并提供添加、删除好友的功能。
群组管理服务: 用于创建和管理群组聊天。可以实现群组的创建、成员管理、群主权限等功能。
消息存储服务: 负责将消息持久化存储。可以使用数据库(如 MySQL、PostgreSQL)或 NoSQL 数据库(如 MongoDB、Redis)来存储消息。
在线状态服务: 用于跟踪用户的在线状态。可以使用 Redis 等内存数据库来存储用户的在线信息。
推送通知服务: 用于将消息通知推送给离线用户。可以使用 APNs(Apple Push Notification Service)、FCM(Firebase Cloud Messaging)等平台来实现推送通知。
文件传输服务: 处理用户之间的文件传输,可以将文件存储在分布式存储系统(如 Amazon S3、阿里云 OSS)中,并生成访问链接。
日志和监控: 集成日志记录和监控系统,用于追踪系统运行状况、性能指标和错误情况。常见的工具有 ELK(Elasticsearch、Logstash、Kibana)和 Prometheus 等。
3. 技术选择:
编程语言: 使用适合性能和开发效率的语言,如 Java、Kotlin、Go 等。
数据库: 根据数据的特点选择适当的数据库,如关系型数据库(MySQL、PostgreSQL)用于用户信息存储,NoSQL 数据库(MongoDB、Redis)用于消息存储和缓存。
通信协议: 使用 WebSocket 协议实现实时消息传递,HTTP 或其他适当的协议用于服务间通信。
容器和编排: 使用 Docker 容器化应用程序,并使用 Kubernetes 或 Docker Compose 进行容器编排和管理。
安全: 使用 HTTPS 保护数据传输,实现用户认证和授权,防止跨站脚本攻击(XSS)等。
可扩展性: 使用水平扩展策略,根据负载自动添加新的服务器实例。
高可用性: 使用负载均衡、故障转移和备份策略来保证系统的高可用性。
缓存: 使用缓存技术(如 Redis)提高系统性能,减轻数据库压力。
消息队列: 使用消息队列(如 Kafka、RabbitMQ)处理异步任务和消息通知。
实时性能优化: 使用 CDN(内容分发网络)加速消息传递,减少网络延迟。
4. 扩展和优化:
不断监控和优化系统性能,采用水平扩展和负载均衡策略,及时处理热点问题,定期进行数据库性能优化,使用缓存技术提高系统响应速度。
2.项目优化
3.大数据量压测调优
一亿用户量,平均每人每天 10 次的业务量,要求并发数在 5000 以上,峰值在 5w 到 10w 之间,QPS 在 25w 以上, 如何进行压测?如何进行调优?
4.查询时间几十秒?
1.问题描述
在某个大型科技公司用户中台中,组织机构接口的 RT 时间为 70s。
一般系统 RT 要求在 500ms 内,并且越短越好。
2.问题模拟
由于接口查询耗时太长,当前仅采用单机 jmeter 进行压测,模拟 100QPS 的执行情况,
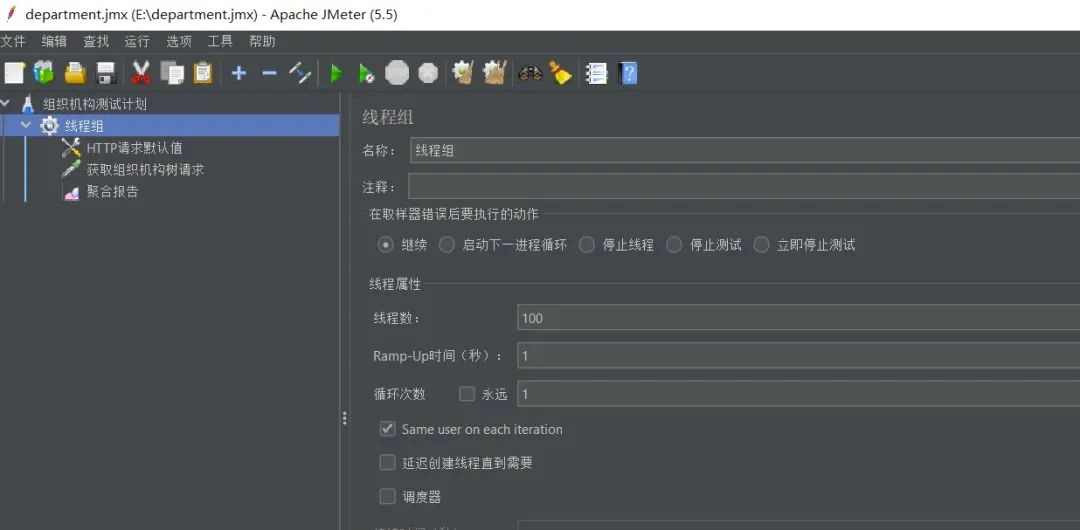
3.优化手段
通过优化数据库表结构、使用缓存技术、合理配置网关等手段,我们可以显著改善组织机构树查询的效率和用户体验。常见的优化思路如下:
- 统一数据源:建立一个中心化的组织机构数据源,将所有部门和团队的组织机构数据集中存储,确保数据的一致性和准确性。
- 数据库优化:设计合适的数据库表结构和索引,以支持高效的组织机构查询操作。使用合适的数据库技术和优化方法,如垂直拆分或水平拆分等,来提高查询性能。
- 缓存机制:使用缓存来存储组织机构数据,如 Redis 等。通过合理的缓存策略,如设置适当的过期时间、使用 LRU 算法等,减少对数据库的频繁查询,提高查询效率。
- 分布式架构:采用分布式架构,将查询负载分散到多个节点上,通过水平扩展来提高查询性能和并发处理能力。
- 异步处理:对于复杂的组织机构查询,可以将其放入异步任务队列中处理,减少前端请求的等待时间,提高系统的并发处理能力。
- 数据同步机制:确保组织机构数据的同步和更新的及时性,使用合适的数据同步技术和机制,如定时任务、事件驱动等,保证数据的一致性。
- 前端优化:采用前端技术和界面设计优化,如数据分页加载、懒加载等方式,减少一次性加载大量组织机构数据所带来的性能压力。
4.数据库层面优化
数据库优化是解决大型科技公司组织机构查询问题的重要一环。下面是一些详细的数据库优化策略和技术:
- 合适的表结构设计:
- 根据组织机构的特点,设计合适的表结构,以支持高效的查询操作。可以采用适当的关系型数据库或者 NoSQL 数据库,根据具体需求选择合适的数据库引擎。
- 使用范式化或者反范式化的设计方式,根据查询需求和数据一致性的要求来决定表结构的规范化程度。
- 使用合适的数据类型来存储组织机构数据,以节省存储空间并提高查询效率。
- 索引优化:
- 通过创建合适的索引来加速组织机构查询。根据查询的字段和条件,为经常被用于查询的列创建索引,以提高查询的速度。
- 选择适当的索引类型,如 B-tree 索引、哈希索引或者全文索引,根据具体查询的需求和数据的特点做出选择。
- 定期进行索引维护和优化,包括索引重建、碎片整理等操作,以保持索引的性能。
- 查询优化:
- 编写高效的查询语句,使用合适的 SQL 语法和操作符,避免不必要的查询或子查询,提高查询的效率。
- 使用合适的查询缓存机制,如数据库自带的查询缓存或者第三方缓存工具,以减少对数据库的频繁查询。
- 避免过度使用 JOIN 操作,尽量减少关联查询的复杂性。考虑使用预加载或延迟加载的方式,根据实际需求来优化查询操作。
- 分析查询执行计划,通过索引优化、表结构调整或者 SQL 重写等手段,改善查询执行计划的性能。
- 数据分区和分片:
- 如果组织机构数据量非常大,可以考虑将数据分区或者分片存储。通过按照一定规则将数据拆分为多个分区或者分片,提高查询的并行度和扩展性。
- 使用分区表或者分片表的方式,将数据均匀地分布到多个物理存储设备或者数据库实例中,提高查询的性能和响应时间。
- 定期数据清理和维护:
- 定期清理不再使用的数据,如过期的组织机构信息或者历史数据。通过删除或者归档这些数据,可以减少数据库的存储压力和提高查询性能。
- 定期进行数据库的维护工作,包括备份、日志清理、统计信息更新等操作,以保持数据库的健康状态和性能
#部门表设计
CREATE TABLE `department` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(100) COLLATE utf8mb4_unicode_ci NOT NULL,`parent_id` int(11) COLLATE utf8mb4_unicode_ci DEFAULT NULL,`remark` varchar(100) COLLATE utf8mb4_unicode_ci DEFAULT NULL,`created_at` datetime DEFAULT NULL,`deleted` tinyint(1) NOT NULL DEFAULT '0',PRIMARY KEY (`id`),KEY `department_parent_id_IDX` (`parent_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='部门';
//java代码逻辑处理优化
public DepartmentDTO findAll() {DepartmentDTO departmentDTO = new DepartmentDTO();departmentDTO.setId(0L);queryChildren(departmentDTO);return departmentDTO;
}// 递归查询
private void queryChildren(DepartmentDTO parent) {List<DepartmentPO> children = departmentDao.queryByParentId(parent.getId());if (CollectionUtils.isEmpty(children)) {return;}for (DepartmentPO po : children) {DepartmentDTO departmentDTO = new DepartmentDTO();BeanUtil.copyProperties(po, departmentDTO);parent.getChildren().add(departmentDTO);queryChildren(departmentDTO);}
}
5.应用层优化
在应用服务里,每次查询一次性从数据库中获取所有数据,在内存里排序、拼装成树形数据,
private void queryChildren2(DepartmentDTO root) {// 一次性取出所有数据List<DepartmentPO> list = departmentDao.findAll(Sort.by("parentId", "id").ascending());Map<Long, DepartmentDTO> departmentMap = new HashMap<>();departmentMap.put(root.getId(), root);// 遍历数据,组成树形结构for(DepartmentPO po : list) {DepartmentDTO departmentDTO = new DepartmentDTO();BeanUtil.copyProperties(po, departmentDTO);departmentMap.put(po.getId(), departmentDTO);DepartmentDTO parent = departmentMap.get(po.getParentId());parent.getChildren().add(departmentDTO);}
}
6.分布式缓存
通过引入分布式缓存,我们可以将组织机构数据缓存在内存中,以避免频繁访问数据库的开销。引入分布式缓存是一种高效的优化策略,通过减少对数据库的访问次数和加速查询响应,可以极大地提升组织机构查询的效率和响应时间,从而提高整体系统的性能和用户体验。
public DepartmentDTO findAll() {// 查询缓存DepartmentDTO departmentDTO = (DepartmentDTO) redisTemplate.opsForValue().get(DEPARTMENT_CACHE_KEY);// 缓存不存在则查询数据库if (Objects.isNull(departmentDTO)) {departmentDTO = new DepartmentDTO();departmentDTO.setId(0L);queryChildren2(departmentDTO);}// 更新缓存redisTemplate.opsForValue().set(DEPARTMENT_CACHE_KEY, departmentDTO, 1, TimeUnit.MINUTES);return departmentDTO;
}
7.加入本地缓存
本地缓存是指将数据缓存在应用程序的内存中,以避免频繁地访问分布式缓存或数据库,从而快速响应查询请求。
引入本地缓存的好处是可以减少对分布式缓存的访问次数,从而降低网络延迟和通信开销。
当应用程序发起组织机构查询时,首先检查本地缓存中是否存在相应的数据。如果数据在本地缓存中命中,则无需进一步访问分布式缓存或数据库,可以直接返回结果,极大地提升了查询的效率和响应时间。
本地缓存的使用需要考虑以下几个关键因素:
- 缓存策略:选择合适的缓存策略,如 LRU(最近最少使用)、LFU(最近最不常用)等,以平衡内存使用和数据命中率。
- 缓存更新机制:在组织机构数据发生变化时,及时更新本地缓存。可以通过订阅数据库或分布式缓存的数据变更事件,保持本地缓存与数据源的一致性。
- 缓存失效处理:设置合理的缓存失效时间,以确保缓存中的数据不过期。可以根据数据更新的频率和重要性进行调整。
- 内存管理:合理管理本地缓存使用的内存,避免因缓存过多导致内存溢出或应用程序性能下降的问题。
引入本地缓存的优化方案需要综合考虑应用程序的特点、数据的更新频率和一致性要求。合理使用本地缓存可以减少对分布式缓存和数据库的访问,提升组织机构查询的效率和响应时间,从而提高系统的整体性能和用户体验。
<dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId><version>3.1.2</version>
</dependency>
@Configuration
@EnableCaching
public class CacheConfig {@Beanpublic Caffeine<Object, Object> caffeineConfig() {return Caffeine.newBuilder().expireAfterWrite(10, TimeUnit.MINUTES) // 设置缓存失效时间为10分钟.maximumSize(10_000) // 设置缓存的最大容量为10_000.recordStats(); // 启用统计信息,可通过Cache.stats()获取缓存命中率等统计数据}@Beanpublic CacheManager cacheManager(Caffeine<Object, Object> caffeine) {CaffeineCacheManager cacheManager = new CaffeineCacheManager();cacheManager.setCaffeine(caffeine);return cacheManager;}
}
@Cacheable("department-cache")
public DepartmentDTO findAll() {// 省略其它代码
}
8.网关层面优化
在网关层面进行优化可以提高组织机构树接口查询的性能和可扩展性。
1.Nginx 压缩:
- 在 Nginx 配置中启用压缩功能,将响应数据进行压缩,减少数据传输的大小,提高网络传输效率和响应速度。
- 配置
gzip指令开启压缩,可以设置合适的压缩级别和压缩类型。
http {gzip on;gzip_types text/plain text/css application/json;gzip_comp_level 5;
}
2.网关缓存:
在 Nginx 中,可以通过配置代理缓存来缓存接口的响应结果。以下是详细的步骤:
1.启用代理缓存:
在 Nginx 的配置文件中,开启代理缓存功能并定义一个缓存区域。
http {proxy_cache_path /path/to/cache levels=1:2 keys_zone=my_cache:10m max_size=10g inactive=60m use_temp_path=off;
}
-
/path/to/cache:指定缓存存储路径。 -
levels=1:2:定义缓存路径层级。 -
keys_zone=my_cache:10m:为缓存区域指定一个名称(my_cache)和分配的内存大小(10MB)。 -
max_size=10g:设置缓存区域的最大容量为 10GB。 -
inactive=60m:指定缓存项在 60 分钟内没有被访问时被认为是过期的。 -
use_temp_path=off:禁止使用临时路径。2.配置代理缓存:
在 Nginx 的配置文件中,为需要缓存的接口添加缓存配置。
server {location /api/department {proxy_cache my_cache;proxy_cache_valid 200 1d;proxy_pass http://backend_server;}
}
-
proxy_cache my_cache:指定使用前面定义的缓存区域(my_cache)进行缓存。 -
proxy_cache_valid 200 1d:设置缓存有效期为 1 天,对于状态码为 200 的响应进行缓存。 -
proxy_pass http://backend_server:指定反向代理的目标后端服务器。3.清除缓存:
如果需要手动清除缓存,可以使用 Nginx 的proxy_cache_purge模块,通过发送特定请求来清除缓存。
location /purge-cache {proxy_cache_purge my_cache "$scheme$request_method$host$request_uri";
}
proxy_cache_purge:启用proxy_cache_purge模块。my_cache:指定要清除的缓存区域。"$scheme$request_method$host$request_uri":指定要清除的缓存键值。
通过上述配置,Nginx 会在接收到请求时先查看缓存,如果缓存中存在对应的响应,则直接返回缓存的结果,减少对后端服务的请求。如果缓存中不存在或已过期,则会转发请求到后端服务,并将响应结果缓存起来,以供后续相同请求使用。
请注意,缓存接口需要根据具体的业务需求和接口特性进行配置。需要根据接口的频率、数据更新频率和缓存策略进行合理的调整。
对于动态生成的树形数据页面,也可以采用页面缓存技术,将页面内容缓存到 CDN 或其他缓存中,并设置合适的缓存过期时间。
9.调优小结
针对组织结构树的优化设计,我们可以在数据库层面、缓存层面和 NGINX 网关层面进行优化,以提高查询性能和系统的可伸缩性。
在数据库层面,我们可以采取以下优化设计:
- 使用适当的表结构和索引,优化组织结构树的存储和查询效率。
- 考虑采用合适的分库分表策略,将数据水平拆分,减少单表数据量。
- 针对组织结构树的查询,使用适当的查询语句和优化技巧,如递归查询、嵌套集模型等。
在缓存层面,我们可以采取以下优化设计:
- 使用 Redis 等缓存技术,将组织结构树的数据缓存在内存中,减少对数据库的访问次数。
- 针对频繁访问的组织结构树数据,设置合适的缓存过期时间和缓存策略。
- 使用合理的缓存命名规则和缓存键设计,确保缓存的准确性和一致性。
在 NGINX 网关层面,我们可以采取以下优化设计:
- 使用 Nginx 的压缩功能,减小响应数据的大小,提高网络传输效率。
- 使用 CDN 缓存静态资源,减轻网关和后端服务器的负载,加速资源传输。
- 配置代理缓存,将组织结构树接口的响应结果缓存起来,减少对后端服务的请求。
- 设置适当的负载均衡机制,分发请求到多个后端服务实例,提高系统的可扩展性和容错性。
综合上述优化设计,可以大大提升组织结构树接口的查询性能和系统的可伸缩性。通过数据库的优化,可以提高数据的存储和查询效率;通过缓存的优化,可以减少对数据库的访问次数;通过网关层面的优化,可以降低网络传输成本和后端服务的负载压力。这些综合的优化措施将显著改善系统的整体性能和用户体验。
5.BigKey 问题
1.什么是 BigKey?
在 Redis 中,BigKey 指的是占用大量内存空间的键值对。当一个键值对的数据量过大,超过 Redis 的配置限制或者内存容量时,就称之为 BigKey。
2.BigKey 导致的问题
BigKey 会导致以下问题:
- 内存占用过高:BigKey 占用大量内存空间,可能导致 Redis 服务器的内存资源紧张,影响其他操作和缓存数据的存储。
- 延迟和性能下降:由于读写大型 BigKey 的数据需要较长的时间,会导致读写操作的延迟增加,并且消耗更多的 CPU 资源和网络带宽,影响系统的整体性能。
- Redis 持久化和备份问题:BigKey 在进行持久化(如 RDB 快照或 AOF 日志)或备份时,会增加持久化和备份的时间和资源消耗。
3.解决方案
解决 BigKey 问题的一些优化方法包括:
- 数据拆分:将大型 BigKey 拆分成多个较小的键值对,根据数据的逻辑关联性和查询模式进行合理的拆分和分组。这样可以降低单个键值对的大小,减少内存占用。
- 分片存储:将数据分散存储在多个键中,使用合适的哈希函数或者分片算法,将数据均匀地分散到不同的键中,避免单个键值对过大。这样可以平衡数据的存储和访问压力。
- 数据压缩:对于可以压缩的数据类型(如字符串或 JSON 格式的数据),可以使用压缩算法(如 LZF、Snappy、Gzip 等)进行压缩,减少 BigKey 的内存占用。
- 数据分页和增量加载:对于查询结果过大的 BigKey,可以采用数据分页或者增量加载的方式,只加载部分数据或者按需加载,以降低单次查询的数据量和内存消耗。
- 避免无意义的数据存储:避免将无需持久化或频繁变更的数据存储为 BigKey,可以使用临时缓存或者其他数据存储方案。
通过合理的数据拆分、分片存储和压缩等优化方法,可以有效地解决 BigKey 问题,提高 Redis 的性能和资源利用率。
因为在根节点下的第一级优 10 个组织,这 10 个组织分别有不同的子孙节点,我们可以尝试将单个 key 先拆分成 10 个 key,每个 key 分别对应这 10 个组织及子节点数据。
public DepartmentDTO findAll() {DepartmentDTO root = new DepartmentDTO();root.setId(0L);// 从10个key里获取缓存数据,放入到根节点的children集合里for (int i = 0; i< 10; i++) {DepartmentDTO child = (DepartmentDTO) redisTemplate.opsForValue().get(DEPARTMENT_CACHE_KEY + i);// 没有缓存数据if (Objects.isNull(child)) {root.setChildren(new ArrayList<>());break;}root.getChildren().add(child);}if (root.getChildren().size() == 0) {// 查询数据库queryChildren2(root);}// 将数据按照1级部门存储到10个keyList<DepartmentDTO> children = root.getChildren();for (int i = 0 ; i < 10; i++) {redisTemplate.opsForValue().set(DEPARTMENT_CACHE_KEY + i, children.get(i), 1, TimeUnit.HOURS);}return root;
}
6.重复提交问题?
重复提交问题是指用户在某个操作或请求上多次点击提交按钮,从而导致重复执行同一操作或请求的情况。这可能会引发各种问题,例如重复订单、数据重复插入等。下面是一些解决重复提交问题的常见方法:
-
前端控制:
- 禁用提交按钮:在用户点击一次提交按钮后,禁用该按钮,防止用户连续点击。
- 显示加载状态:在提交后,显示一个加载指示器,让用户知道操作正在进行中,从而减少他们的不必要点击。
-
后端控制:
- 生成唯一标识符:在每次请求时,在后端生成一个唯一标识符(如 Token),将其包含在请求中。服务器在处理请求后,可以检查该标识符是否已被使用,从而防止重复提交。
- 请求限制:通过某种机制(例如 IP 地址、用户会话等)限制用户在特定时间内只能提交一次请求,从而防止频繁提交。
- 幂等操作:设计操作为幂等,即无论操作执行多少次,结果都是一致的。这样,就不会因为重复执行而产生问题。
-
时间戳和过期处理:
- 记录时间戳:在用户提交请求时,记录一个时间戳。后端在处理请求时,可以检查时间戳,如果距离上一次请求时间太短,则拒绝请求。
- 设置有效期:为每个操作设置一个有效期,在有效期内同一操作请求将被视为重复请求并被拒绝。
-
前后端协作:
- 双重确认:在用户提交后,弹出确认对话框,要求用户再次确认是否要执行操作,从而减少误操作的可能性。
- 提交完成页面跳转:在操作成功后,将用户重定向到一个新页面,这样刷新页面不会再次提交相同的请求。
-
防止重复提交的库和框架:
- 许多现代的 Web 框架和库提供了防止重复提交的解决方案,例如使用单次令牌(one-time token)、防止多次点击等机制。你可以查阅相关文档了解如何在你的技术栈中应用这些解决方案。
-
测试和监控:
- 在开发过程中进行测试,模拟快速点击、重复请求等情况,确保系统能够正确处理这些情况。
- 监控系统日志,查找重复提交问题的发生频率和原因,及时采取措施解决。
综合考虑以上方法,可以根据具体情况选择适合你的应用场景的解决方案,以减少或防止重复提交问题的发生。
7.接口幂等性设计?
接口的幂等性设计是指无论调用多少次,其产生的结果都是相同的,不会因为多次调用而引发不一致或重复的操作。在设计 API 接口时,考虑到幂等性非常重要,特别是在网络通信不稳定、客户端重试请求、系统故障等情况下。
以下是一些设计原则和方法来确保接口的幂等性:
-
使用唯一标识符:
- 在每个请求中使用
唯一标识符(例如请求 ID、随机生成的 UUID 等)。 - 在服务器端检查标识符,以确保重复请求不会重复执行操作。
- 在每个请求中使用
-
HTTP 方法的选择:
- 使用合适的 HTTP 方法:
GET、HEAD、OPTIONS是幂等的,而 POST、PUT、DELETE 则可能会改变资源状态,需要额外处理幂等性。
- 使用合适的 HTTP 方法:
-
Idempotency-Key 头部:
- 客户端可以在
请求头部添加一个自定义的 Idempotency-Key(幂等 key),用于标识请求的幂等性。 - 服务器端可以根据这个头部来检查重复请求。
- 客户端可以在
-
幂等性验证:
- 在服务器端,对于可能会引起状态变化的操作,
检查操作的影响,确保相同的请求不会产生不一致的结果。
- 在服务器端,对于可能会引起状态变化的操作,
-
状态检查和变更:
- 在处理请求之前,
检查资源的当前状态,然后再决定是否执行状态变更操作,以避免重复的变更。
- 在处理请求之前,
-
使用事务:
- 对于需要多个步骤的操作,
使用事务来确保操作的原子性,从而避免部分操作成功、部分操作失败的情况。
- 对于需要多个步骤的操作,
-
返回结果和响应码:
- 对于幂等请求,不管操作是否执行,
响应的结果应该一致。响应码可以根据操作是否成功来区分。
- 对于幂等请求,不管操作是否执行,
-
幂等性测试:
- 在开发过程中,编写测试用例来
模拟重复请求,确保接口的幂等性。
- 在开发过程中,编写测试用例来
-
数据验证和处理:
- 对于数据插入、更新等操作,使用
唯一约束或条件判断来防止重复数据插入。
- 对于数据插入、更新等操作,使用
-
日志和审计:
- 记录所有接口
请求和响应,包括请求参数、响应结果和处理时间,以便后续排查重复请求的问题。
- 记录所有接口
在设计幂等性时,需要考虑到具体的业务场景和操作特点,选择适合的方法和策略。不同的接口可能需要不同的处理方式来保证幂等性。
8.超卖解决方案
超卖是指在电子商务或库存管理系统中,同一商品被售出的数量超过了实际库存的数量,从而导致库存不一致的情况。这可能会给用户和商家带来困扰。以下是一些解决超卖问题的常见方案:
-
悲观锁:
- 在更新库存时,使用数据库的悲观锁机制,例如使用数据库事务的排他锁(SELECT … FOR UPDATE)。
- 在进行库存检查和更新操作之间,锁定对应的库存记录,确保其他事务无法同时操作,从而避免超卖。
-
乐观锁:
- 在更新库存时,使用乐观锁机制,例如在库存记录中添加版本号字段。
- 检查更新前的版本号和当前数据库中的版本号是否一致,如果一致则执行更新,否则放弃更新。
-
队列和异步处理:
- 将订单和库存更新操作放入消息队列中,然后使用消费者来处理订单并更新库存。
- 这可以避免多个请求同时访问库存,通过队列的方式进行顺序处理,减少超卖的可能性。
-
限制购买数量:
- 对用户进行限制,例如每次只能购买一个商品或限制购买数量不超过库存数量。
- 在前端和后端都进行验证,防止用户提交超过限制数量的请求。
-
并发控制和缓存:
- 使用分布式锁或缓存来控制并发访问,确保同一时刻只有一个请求能够进行库存更新。
- 当一个请求正在更新库存时,其他请求需要等待或返回错误信息。
-
预扣库存:
- 在用户下订单时,先将相应数量的库存进行预扣除,但不立即更新实际库存。
- 在订单支付完成后,再正式扣除库存。如果支付失败,释放预扣的库存。
-
事务和回滚:
- 使用数据库事务,将检查库存和更新库存操作放在同一个事务中。
- 如果库存不足或其他异常,可以回滚事务,确保库存和订单的一致性。
-
监控和报警:
- 设置监控机制,实时监控库存的变化和订单的处理情况。
- 当库存出现异常情况时,及时报警并进行处理。
不同的解决方案适用于不同的场景和需求,通常需要根据业务需求和系统架构来综合考虑选择哪些方案或者采用多种方案组合来解决超卖问题。
9.消息推送的设计?
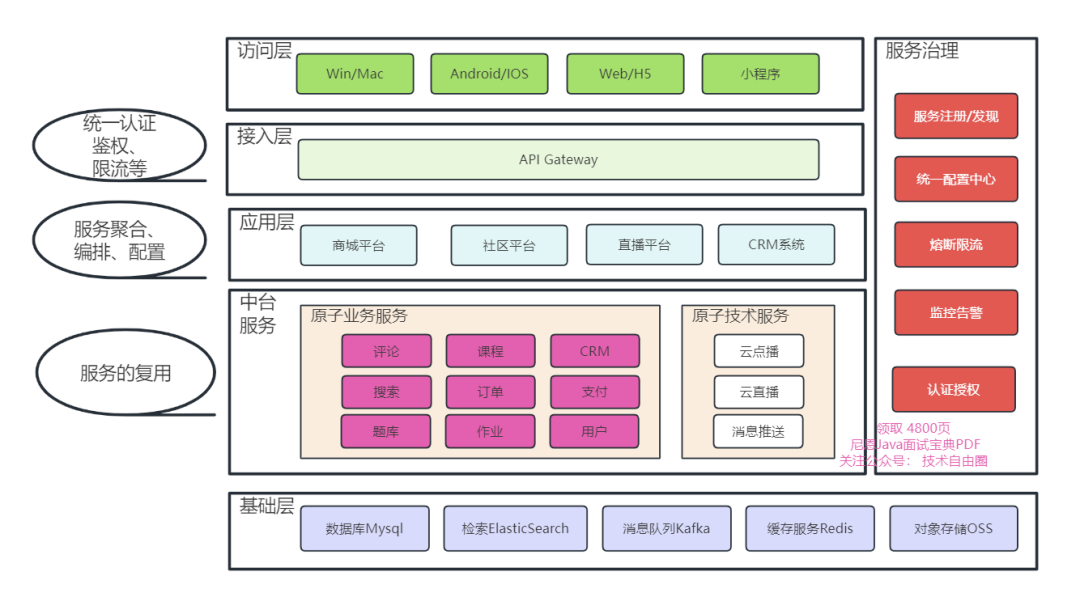
推送系统设计架构
- 通知客户端
- 通知服务
- 模板服务
- 消息分发服务
- 事件优先级队列(消息队列)
- 通用出站处理程序
- 通知适配器
- 通道供应商
- 用户选择服务
- 用户配置文件服务
- 分析服务
- 通知跟踪器
- 通知数据库:Mysql 数据库集群
10.多级缓存
多级缓存架构的注意事项:
- 由于本地缓存会占用 Java 进程的 JVM 内存空间,因此不适合存储大量数据,需要对缓存大小进行评估。
- 如果业务能够接受短时间内的数据不一致,那么本地缓存更适用于读取场景。
- 在缓存更新策略中,无论是主动更新还是被动更新,本地缓存都应设置有效期。
- 考虑设置定时任务来同步缓存,以防止极端情况下数据丢失。
- 在 RPC 调用中,需要避免本地缓存被污染,可以通过合理的缓存淘汰策略,来解决这个问题。
- 当应用重启时,本地缓存会失效,因此需要注意加载分布式缓存的时机。
- 通过发布/订阅解决数据一致性问题时,如果发布/订阅模式不持久化消息数据,如果消息丢失,本地缓存就会删除失败。所以,要解决发布订阅消息的高可用问题。
- 当本地缓存失效时,需要使用 synchronized 进行加锁,确保由一个线程加载 Redis 缓存,避免并发更新。
11.如何给接口限流?
接口限流是一种管理和控制访问速率的方法,旨在保护服务器免受过多请求的影响。以下是一些常见的接口限流方法和策略:
-
固定窗口限流: 在一个固定的时间窗口内,只允许一定数量的请求通过。例如,在每秒钟内只允许 100 个请求。一旦达到限制,后续的请求会被阻塞或延迟。
-
滑动窗口限流: 类似于固定窗口限流,但窗口是滑动的,可以更灵活地控制请求速率。可以通过限制一个窗口内的请求总数或平均速率来实现。
-
令牌桶限流: 令牌桶算法基于一个令牌桶,请求需要消耗令牌才能被处理。令牌以固定速率添加到桶中,如果桶中没有足够的令牌,请求将被延迟或拒绝。
-
漏桶限流: 漏桶算法类似于令牌桶,但请求以固定速率从“漏桶”中流出。如果请求到达时桶为空,请求将被延迟或拒绝。
-
动态限流: 基于服务器负载、流量情况等动态调整限流策略,以确保服务器不会超负荷。可以使用自动扩展、缩减限流速率等方式。
-
分布式限流: 适用于分布式系统的限流策略,可以通过共享限流状态、中心化控制、令牌传递等方式来实现全局限流。
-
熔断: 在服务出现故障或性能下降时,可以关闭接口,避免对下游服务造成更大影响,直到服务恢复正常。
-
负载均衡: 将流量分散到多个服务器上,以避免单一服务器负载过高。
要实现接口限流,你可以使用诸如限流库、反向代理(如 Nginx)、API 网关(如 Spring Cloud Gateway、Kong)等工具或技术。不同的技术和框架提供不同的限流实现方法,具体取决于你的技术栈和需求。
九.解决方案
1.数据迁移方案
数据迁移执行流程,大概有 10 个步骤:
- 环境准备:线上库配置完成
- 全量同步:数据迁移工具上新建 2 张表(积分表、明细表)的全量任务
- 增量同步:全量迁移完成后开启增量(自动回溯全量开始时间,消息多次消费会进行幂等)
- 数据校验:全量数据校验,查看数据是否一致
- 切流测试:改造代码预发测试(采集线上流量进行回放,多种 case 跑一下,切流开关等校验),没问题发布上线
- 二次校验:再次全量进行校验&订正(数据追平)
- 开启双写:打开双写(保证数据实时性)既写老库,又写新库
- 开启读灰度:低峰时段,进行灰度切流
userId%x,进行验证,逐步流量打开,持续观察 - 只写新库:写流量切到新库,只写新库,不写老库。完成数据迁移方案
- 迁移完成:系统稳定运行一段时间,迁移&双写代码下线,老库进行资源释放
2.64 亿的 url,如何去重?
处理 64 亿个 URL 并在只分配 1GB 内存的情况下进行去重是一个非常具有挑战性的任务。由于数据量巨大,传统的内存去重方法可能会受到内存限制,并且可能需要更复杂的策略来实现高效的去重。
以下是一些可能的方法和建议:
-
分批处理: 将数据分为多个较小的批次,每次只加载一批数据到内存中进行去重,然后将结果写回到数据库。这可以减少单次加载的内存压力。
-
哈希集合: 使用哈希集合(例如 Java 中的
HashSet)来存储已经出现过的 URL。由于内存有限,你可能需要考虑使用一些压缩技术或哈希函数来降低内存占用。注意,哈希集合可能会有一些冲突,需要额外的处理。 -
位图: 如果 URL 的范围有限,你可以使用位图(Bitmap)来表示 URL 是否存在。这可以显著减少内存占用,但仅适用于特定情况。
-
外部存储: 如果内存非常有限,你可以考虑使用外部存储,如硬盘或者分布式存储,来进行去重操作。这可能会涉及更多的复杂性和性能开销。
-
使用数据库功能: 一些数据库系统具有内置的去重功能,你可以探索你正在使用的数据库是否提供类似的功能。
-
采样和统计: 如果只需要大致估计去重后的 URL 数量,你可以考虑对数据进行采样,然后统计不同 URL 的出现次数,从而得出去重后的近似数量。
需要根据具体情况综合考虑选择合适的方法。请注意,处理如此大规模的数据和内存限制可能需要一定的技术深度和优化经验。最好在实际环境中进行实验和测试,以找到最适合你情况的解决方案。
3.什么是脑裂问题?
脑裂问题(Split-Brain Problem)是分布式系统中的一个严重的一致性问题。它发生在具有多个节点或副本的分布式系统中,当网络通信发生故障或延迟时,可能导致系统的不一致性和错误操作。脑裂问题的名字源自于类似于“大脑被劈开”的图像,其中分布式系统被分割成多个独立的部分。
脑裂问题的主要原因是分布式系统中节点之间的通信中断或延迟,导致不同节点之间无法及时同步数据和状态。这可能会导致以下问题:
-
数据不一致: 不同节点之间无法及时更新数据,导致不同节点上的数据不一致。例如,在数据库复制中,一个节点可能更新了数据,但由于网络故障,其他节点无法及时同步,从而导致数据不一致。
-
双重提交: 当节点之间通信故障后,可能会导致同一个操作被多次提交。例如,在分布式事务中,如果一个事务提交了,但由于通信问题,协调节点没有收到确认,那么协调节点可能会重试提交,从而导致双重提交。
-
资源竞争: 脑裂可能导致资源的竞争和冲突。例如,多个节点认为自己是主节点,同时操作相同的资源,导致资源冲突。
4.如何解决脑裂问题?
为了解决脑裂问题,分布式系统需要采取一些策略和机制:
-
心跳检测: 使用心跳检测来监测节点的健康状态。如果一个节点被认为不健康,可以将其从集群中隔离,以避免不一致性。
-
Quorum 和多数投票: 使用 Quorum 原则来决定是否执行某个操作。只有在多数节点同意的情况下,才能执行操作,这有助于防止双重提交和资源竞争。
-
选主机制: 使用选主(Leader Election)机制来确保在任何时候只有一个主节点对外提供服务,从而避免资源冲突和数据不一致。
-
超时和重试: 在通信发生故障时,使用合理的超时和重试机制,以避免因网络延迟导致的误判。
-
分区容错: 将分布式系统设计为分区容错,即在面对网络分区时能够保持一致性。这可以通过一致性算法如 Paxos、Raft 等来实现。
脑裂问题在分布式系统中是一个复杂且需要谨慎处理的问题。选择合适的一致性算法、网络配置和节点通信策略,以及实施适当的故障检测和恢复机制,都是减轻脑裂问题影响的关键。
5.什么是雪花算法?
雪花算法生成的 ID 由哪些部分组成?
- 符号位,占用 1 位。
- 时间戳,占用 41 位,可以支持 69 年的时间跨度。
- 机器 ID,占用 10 位。
- 序列号,占用 12 位。一毫秒可以生成 4095 个 ID。

6.雪花算法时钟回拨问题?
雪花算法(Snowflake Algorithm)是一种分布式唯一 ID 生成算法,通常用于分布式系统中生成全局唯一的 ID。该算法的核心思想是将一个 64 位的整数 ID 分成不同的部分,其中包括时间戳、机器 ID、数据中心 ID 和序列号等字段,以确保生成的 ID 在分布式环境中是唯一的。
问题的关键点是时钟回拨,这是指服务器的系统时间被调整回到了过去。时钟回拨可能会导致生成重复的 ID,因为雪花算法中的时间戳部分通常用来确保 ID 的唯一性。如果系统时间回拨到了之前已经生成过的时间戳,那么在同一毫秒内生成的 ID 可能会相同。
为了解决时钟回拨问题,可以考虑以下几种方法:
-
时钟同步: 确保服务器的时钟是
同步的,可以使用网络时间协议(NTP)等工具来同步系统时间,减小时钟回拨的可能性。 -
时钟漂移检测: 在生成 ID 时,
检测当前时间戳是否小于上一次生成的时间戳,如果是,则表示发生了时钟回拨,可以等待一段时间再生成 ID,或者采取其他措施来处理。 -
保留序列号: 在雪花算法中,通常有一部分位用来表示
序列号。当发生时钟回拨时,可以通过递增序列号来确保生成的 ID 不会重复。 -
使用更高精度的时间戳: 使用
更高精度的时间戳(例如毫秒级别或微秒级别)可以减小在同一时间戳下生成重复 ID 的概率。 -
记录时钟回拨事件: 如果检测到时钟回拨,可以记录事件并采取适当的处理策略,例如等待一段时间再生成 ID,或者生成一个特殊标识的 ID 来表示时钟回拨事件。
处理时钟回拨问题需要根据具体的应用场景和要求来选择合适的方法。不同的解决方案可以根据系统的可用性、性能要求和复杂性进行权衡。
7.关于语雀挂了思考?
- 故障原因简单来说就是新的运维升级工具 bug 带来的一系列影响。其实,究其根本原因还是高可用架构体系设计、运维以及项目规范,甚至是团队管理和制度上存在严币的问题需要去改进和完善。
- 这件事儿也给大家提了个醒,自己写的文档,记得还是在本地留存一份。
- 当场拔网线,模拟火灾报警,地震来袭,光纤挖断啥的,你以为这些是开玩笑的?
- 作为程序员,大家聊到这里的时候,一遍都会谈到高可用、容灾备份、两地三中心、异地多活、同城双活
觉得有用的话点个赞
👍🏻呗。
❤️❤️❤️本人水平有限,如有纰漏,欢迎各位大佬评论批评指正!😄😄😄💘💘💘如果觉得这篇文对你有帮助的话,也请给个点赞、收藏下吧,非常感谢!👍 👍 👍
🔥🔥🔥Stay Hungry Stay Foolish 道阻且长,行则将至,让我们一起加油吧!🌙🌙🌙