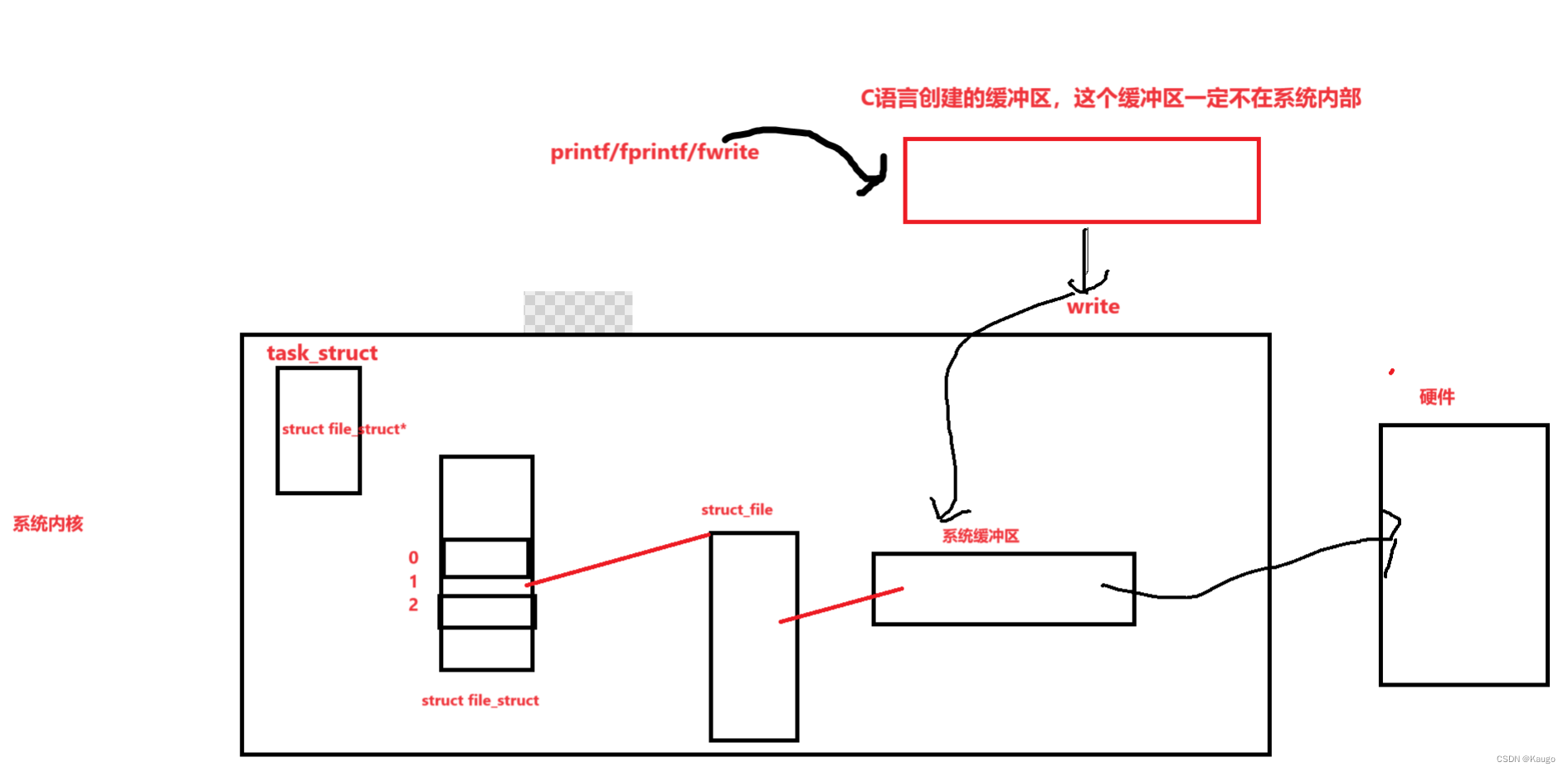
在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器
在本文中我们将介绍如何使HuggingFace的模型适应你的任务,在Pytorch中建立自定义模型头并将其连接到HF模型的主体,并端到端地训练系统。
1、HF模型头和模型体
这是典型的HF模型的样子:

为什么我需要单独使用模型头(Model Head)和模型体(Model Body)?
一些HF的模型针对下游任务(例如提问或文本分类)训练,并包含有关其权重培训的数据的知识。
有时,尤其是当我们手头的任务包含很少的数据或领域特定(例如医学或运动特定任务)时,我们可以在HUB上使用其他任务训练的模型(不一定与我们的任务相同的任务 手但属于相同领域,例如运动或药物),并利用一些验证的知识来提高我们模型在我们自己任务的性能表现。
- 一个非常简单的例子是,如果说我们有一个小数据集,比如分类某些财务报表是积极还是负面的。 但是,我们进入了HF,发现许多模型已经经过与金融相关的问答数据集的训练,那么 我们可以使用这些模型的某些层来改进自己的任务。
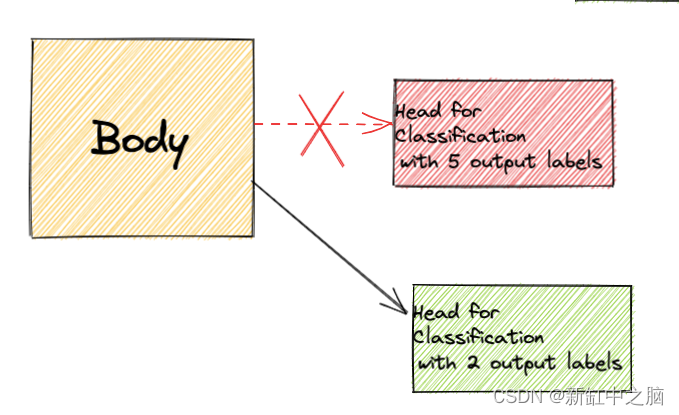
- 另一个简单的示例是,某个特定领域的模型经过巨大数据集的训练学会了将文本从中分为5个类别。 假设我们有类似的分类任务,在同一域中的一个完全不同的数据集,只想将数据分类为2个类别而不是5。 这时我们也可以复用模型主体,添加自己的模型头来增强我们自己任务的特定领域知识。
这就是我们要做的事情的示意图:

2、自定义HF模型头
我们的任务是简单的,从Kaggle上的这个数据集进行讽刺检测。
你可以在此处查看完整的代码。 为了时间的考虑,我没有在下面包括预处理和一些训练的详细信息,因此请确保查看整个代码的笔记本。
我将使用一个在大量推文上训练的模型,有5个分类输出不同的情感类型。我们将提取模型体,在pytorch中添加自定义层(2个标签,讽刺/不讽刺),并训练新的模型。
注意:你可以在此示例中使用任何模型(不一定是对分类训练的模型),因为我们只会使用该模型主体并拆除模型头。
这就是我们的工作流程:

我将跳过数据预处理步骤,然后直接跳到主类,但是你可以在本节开头的链接中查看整个代码。
3、令牌化和动态填充
使用如下代码将文本转化为令牌并进行动态填充:
checkpoint = "cardiffnlp/twitter-roberta-base-emotion"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
tokenizer.model_max_len=512def tokenize(batch):return tokenizer(batch["headline"], truncation=True,max_length=512)tokenized_dataset = data.map(tokenize, batched=True)
print(tokenized_dataset)tokenized_dataset.set_format("torch",columns=["input_ids", "attention_mask", "label"])
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)结果如下:
DatasetDict({train: Dataset({features: ['headline', 'label', 'input_ids', 'attention_mask'],num_rows: 22802})test: Dataset({features: ['headline', 'label', 'input_ids', 'attention_mask'],num_rows: 2851})valid: Dataset({features: ['headline', 'label', 'input_ids', 'attention_mask'],num_rows: 2850})
})4、提取模型体并添加我们自己的层
代码如下:
class CustomModel(nn.Module):def __init__(self,checkpoint,num_labels): super(CustomModel,self).__init__() self.num_labels = num_labels #Load Model with given checkpoint and extract its bodyself.model = model = AutoModel.from_pretrained(checkpoint,config=AutoConfig.from_pretrained(checkpoint, output_attentions=True,output_hidden_states=True))self.dropout = nn.Dropout(0.1) self.classifier = nn.Linear(768,num_labels) # load and initialize weightsdef forward(self, input_ids=None, attention_mask=None,labels=None):#Extract outputs from the bodyoutputs = self.model(input_ids=input_ids, attention_mask=attention_mask)#Add custom layerssequence_output = self.dropout(outputs[0]) #outputs[0]=last hidden statelogits = self.classifier(sequence_output[:,0,:].view(-1,768)) # calculate lossesloss = Noneif labels is not None:loss_fct = nn.CrossEntropyLoss()loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))return TokenClassifierOutput(loss=loss, logits=logits, hidden_states=outputs.hidden_states,attentions=outputs.attentions)如你所见,我们首先是继承Pytorch中的 nn.Module,使用AutoModel(来自transformers库)提取加载了指定检查点的模型主体。
请注意, forward() 方法返回 TokenClassifierOutput,从而确保我们输出的格式与HF预训练模型一致。
5、端到端训练新的模型
代码如下:
from tqdm.auto import tqdmprogress_bar_train = tqdm(range(num_training_steps))
progress_bar_eval = tqdm(range(num_epochs * len(eval_dataloader)))for epoch in range(num_epochs):model.train()for batch in train_dataloader:batch = {k: v.to(device) for k, v in batch.items()}outputs = model(**batch)loss = outputs.lossloss.backward()optimizer.step()lr_scheduler.step()optimizer.zero_grad()progress_bar_train.update(1)model.eval()for batch in eval_dataloader:batch = {k: v.to(device) for k, v in batch.items()}with torch.no_grad():outputs = model(**batch)logits = outputs.logitspredictions = torch.argmax(logits, dim=-1)metric.add_batch(predictions=predictions, references=batch["labels"])progress_bar_eval.update(1)print(metric.compute())model.eval()test_dataloader = DataLoader(tokenized_dataset["test"], batch_size=32, collate_fn=data_collator
)for batch in test_dataloader:batch = {k: v.to(device) for k, v in batch.items()}with torch.no_grad():outputs = model(**batch)logits = outputs.logitspredictions = torch.argmax(logits, dim=-1)metric.add_batch(predictions=predictions, references=batch["labels"])metric.compute()结果如下:
0%| | 0/2139 [00:00<?, ?it/s]0%| | 0/270 [00:00<?, ?it/s]
{'f1': 0.9335347432024169}
{'f1': 0.9360090874668686}
{'f1': 0.9274912756882513}如你所见,我们使用此方法实现了不错的性能。 请记住,该博客的目的不是分析此特定数据集的性能,而是要学习如何使用预训练的身体并添加自定义头。
6、结束语
在本文中,我们看到了如何在HF预训练模型上添加自定义层。
一些收获:
- 在我们拥有特定于域的数据集并希望利用在同一域(任务 - 努力的task-agnostic)上训练的模型以增强小型数据集中的性能的情况下,此技术特别有用。
- 我们可以选择接受过与自己任务不同的下游任务训练的模型,并且仍然使用该模型主体的知识。
- 如果你的数据集足够大且通用,那么这可能根本不需要,在这种情况下,你可以使用
AutoModeForSequenceCecrification或使用BERT解决的任何其他任务。 实际上,如果是这样,我强烈建议不要建立自己的模型头。
原文链接:HF自定义模型头 - BimAnt