一、说明
我们调查了来自复杂系统的想法,如群体智能、自组织和紧急行为,这些想法在机器学习中越来越受欢迎。人工神经网络正在影响我们的日常生活,从执行预测性任务(如推荐、面部识别和对象分类)到生成任务(如机器翻译和图像、声音、视频生成)。但是,随着所有这些进步,深度学习的惊人壮举需要大量复杂的工程工作。
 |
亚历克斯网。AlexNet 的神经网络架构(Krizhevsky 等人,2012 年),2012 年 ImageNet 竞赛的获胜者。
即使我们看一下 2012 年的早期 AlexNet,它在赢得 ImageNet 竞赛时就让深度学习声名鹊起,我们也可以看到其设计中涉及的谨慎的工程决策。现代网络通常更加复杂,需要跨越网络架构和精心训练方案的管道。为了产生这些惊人的结果,必须付出大量的汗水和劳动。
|
|

工程桥梁与新兴桥梁。左图:加拿大的联邦大桥。右图:军蚁架起一座桥梁。
我相信我们目前进行深度学习的方式就像工程一样。我认为我们构建神经网络系统的方式与构建桥梁和建筑物的方式相同。但是在自然系统中,涌现的概念起着很大的作用,我们看到由于自组织而出现的复杂设计,而这种设计通常对周围世界的变化很敏感和反应灵敏。自然系统适应并成为其环境的一部分。
“桥梁和建筑物的设计都是为了对环境漠不关心,承受波动,而不是适应它们。最好的桥梁是一座矗立在那里的桥梁,无论天气如何。
——安德鲁·皮克林,《控制论大脑》。
在过去的几年里,我注意到深度学习研究中的许多工作都使用了集体智慧中的一些想法,特别是新兴复杂系统领域。最近,Yujin Tang和我一起撰写了一篇名为《深度学习的集体智慧:关于该主题的最新进展的调查》的调查论文,在这篇文章中,我将总结我们论文中的关键主题。
二、历史背景
深度学习之所以走上正轨,可能只是历史上的一个偶然结果,而且它不一定是这样的。事实上,在神经网络发展的早期,从 1980 年代开始,许多小组,包括由传奇电气工程师 Leon Chuo 领导的小组,致力于研究更接近自然自适应系统的神经网络。他们开发了一种叫做细胞神经网络的东西,这是一种带有人工神经元网格的人工神经网络电路。
 |
细胞神经网络。细胞神经网络中的每个神经元都会接收来自邻居的信号,执行加权和运算,并应用非线性激活函数,就像我们今天所做的那样,并向邻居发送信号。这些网络与当今网络之间的区别在于,它们是使用模拟电路构建的,这意味着它们的工作方式大致相同,但在当时也比数字电路快得多。此外,每个电池的接线(每个电池的“参数”)完全相同。(来源: 蔡讲座)
值得注意的是,即使在 1980 年代后期,他们也已经证明这些网络可以产生惊人的结果,例如对象提取。这些模拟网络在纳秒内工作,这是我们几十年后才能在数字电路中匹配的。它们可以被编程为做一些重要的事情,比如选择像素图像中指向上方的所有对象,并擦除所有其他对象。几十年后,我们才能够通过深度学习完成这些任务:
|
|

使用细胞神经网络检测所有指向上方的物体。左:输入像素图像。右:输出像素图像。
在过去的几年里,我们注意到深度学习研究中的许多工作,这些工作从涌现的复杂系统中探索了与这些细胞神经网络相似的想法,这促使我们写了一份调查。问题在于,复杂系统是一个巨大的话题,包括研究实际蜜蜂和蚁群行为的主题,我们将把我们的讨论限制在专注于机器学习的几个领域:
- 图像处理和生成模型
- 深度强化学习
- 多智能体学习
- 元学习(“Learning-to-learn”))
三、图像生成
我们将首先讨论使用集体智慧生成图像的想法。一个很酷的例子是人类的集体智慧:Reddit r/Place 实验。在这个社区实验中,Reddit 设置了一个 1000x1000 像素的画布,因此 reddit 用户必须共同创建一个百万像素的图像。但有趣的是 Reddit 施加的限制:每个用户每 5 分钟只能绘制一个像素:
|
|

Reddit r/Place 实验:在几分钟内观看几天的活动。
这个实验持续了一周,让数百万reddit用户可以画出他们想要的任何东西。由于每个用户的时间限制,为了画出有意义的东西,用户必须合作,并最终在论坛上协调一些策略,以捍卫他们的设计,攻击其他设计,甚至结成联盟。这确实是人类集体智慧创造力的一个例子。
早期的算法还以集体方式在像素网格上计算设计。这种算法的一个例子是康威的《生命游戏》中举例的元胞自动机,其中网格上每个像素的状态都是根据一个函数计算的,该函数依赖于上一个时间步中邻居的状态,并且基于简单的规则,可以出现复杂的模式:
|
|

康威的生命游戏。
最近的一项工作,神经细胞自动机(Mordvintsev et al., 2020),试图扩展 CA 的概念,但用神经网络代替简单的规则,所以从某种意义上说,它真的很类似于我之前讨论的 1980 年代的细胞神经网络。但在这项工作中,他们将神经 CA 应用于图像生成,就像在 Reddit r/Place 示例中一样,在每个时间步长,将根据单个神经网络函数的输出随机选择和更新一个像素,该函数的输入只是像素的近邻值。
|
|

用于图像生成的神经细胞自动机。
们表明,神经 CA 可以被训练为基于稀疏随机采样规则和几乎为空的初始画布输出任何特定的给定设计。以下是 3 个神经 CA 生成 3 个设计的一些示例。这种方法的显着之处在于,当我们在图像中看到一些损坏时,该算法会尝试以自己的方式自动重新生成损坏的部分。
神经细胞自动机(Neural Cellular Automata)重新生成损坏的图像。
神经 CA 还可以以集体方式执行预测任务。例如,它们可以应用于对MNIST数字进行分类,但这里的区别在于,每个像素必须根据自己的像素以及来自其近邻的预测来产生自己的预测,因此它自己的预测也会影响其邻居的预测,并随着时间的推移改变他们的观点,就像在民主社会中一样。随着时间的流逝,通常会在像素集合中达成一些共识,但有时,我们可以看到有趣的效果,例如如果数字以一种奇怪的方式书写,则在数字的不同区域会有不同的预测稳定状态。
自分类 MNIST 数字。经过训练以识别 MNIST 数字的神经细胞自动机(Randazzo 等人,2020 年)也可作为交互式 Web 演示使用。每个单元格只允许查看单个像素的内容并与其邻居进行通信。随着时间的流逝,将就哪个数字是最有可能的像素形成共识,但有趣的是,根据进行预测的像素的位置,可能会导致分歧。
神经 CA 并不局限于生成像素。它们还可以生成体素和 3D 形状。最近的工作甚至使用神经CA在Minecraft中生成设计,这有点像体素。它们可以生成建筑物和树木之类的东西,但最有趣的是,由于Minecraft中的某些组件是主动的而不是被动的,因此它们也可以生成具有行为的功能性机器。
|
|

神经 CA 也被应用于 Minecraft 实体的再生。在2021年的《Sudhakaran》这部作品中,作者的配方不仅使Minecraft建筑物、树木的再生成为可能,而且还使游戏中的简单功能机器(例如蠕虫状生物)在切成两半时甚至可以再生为两种不同的生物。
在这里,他们表明,当其中一台功能机器被切成两半时,每一半都可以在形态发生上自我再生,最终形成两台功能机器。

形态发生。除了再生之外,Minecraft 中的神经 CA 系统还能够再生简单功能机器的部分(例如游戏中的虚拟生物)。他们展示了一种形态发生生物,在《我的世界》中被切成两半时会长成 2 种不同的生物。
四、深度强化学习
深度学习中的另一个热门领域是使用强化学习来训练神经网络,以完成运动控制等任务。以下是这些 Mujoco Humanoid 基准测试环境及其最先进解决方案的几个示例:

最先进的Mujoco人形机器人。您可能不喜欢它,但这就是峰值性能的样子。
通常发生的事情是,所有输入的观察状态(在类人机器人的情况下,我们有 376 个观察)都被输入到一个深度神经网络中,即“策略”,该网络将输出控制类人机器人执行器所需的 17 个动作,使其向前移动。通常,这些策略网络往往会过度拟合训练环境,因此您最终会得到仅适用于此精确设计和仿真环境的解决方案。
我们最近看到一些有趣的工作,着眼于使用集体控制器方法解决这些问题。特别是,在 Huang 等人,2020 年,他们没有让一个策略网络承担所有输入并输出所有操作,而是在这里,他们为代理中的每个执行器使用单个共享策略,有效地将代理分解为由四肢连接的代理集合:
|
|

传统的RL方法为具有固定形态的特定机器人训练特定策略。但最近的工作,如Huang等人2020年展示的工作,试图训练一个负责控制机器人单个部分的模块化神经网络。因此,每个机器人的全局策略都是这些相同的模块化神经网络协调的结果,这是从局部交互中产生的。这个系统可以推广到各种不同的骨骼结构,从漏斗到四足动物,甚至到一些看不见的形态。
这些策略可以与邻居进行双向通信,因此随着时间的推移,全局策略可以从本地交互中产生。他们不仅为一个代理设计训练这个单一的策略,而且它必须在训练集中的数十个设计中工作,所以在这里,这些代理中的每一个都由管理每个执行器的相同策略控制:

控制每个执行器的相同神经网络必须在所有这些设计中工作。
他们表明,这种类型的集体系统具有一些零样本泛化能力,不仅可以控制具有不同肢体长度和质量的不同设计变化的智能体,还可以控制训练集中没有的新颖设计,并且还可以应对看不见的挑战:

那么,为什么要依赖固定设计呢?另一项工作,Pathak等人,2019年着眼于让每个肢体都找出一种自我组装的方法,并学习一种设计来执行平衡和运动等任务:

自组装肢体。自组织还使RL环境中的系统能够针对给定任务自行配置自己的设计。在 Pathak 等人,2019 年,作者探索了这种动态和模块化代理,并表明它们不仅可以推广到看不见的环境,还可以推广到由其他模块组成的看不见的形态。
他们表明,这种方法可以推广到各种情况,即使你的肢体数量是系统训练的两倍或一半——这在传统的深度强化学习中根本不可能实现。即使是使用传统深度强化学习训练的系统也可以工作,但自组装解决方案始终被证明对风等看不见的挑战更加强大,或者在运动的情况下,可以处理障碍和楼梯等新型地形:

这种类型的集体策略制定也可以应用于基于图像的 RL 任务。在Yujin Tang和我最近在NeurIPS上发表的一篇论文中,我们研究了将视频馈送的每个补丁输入相同的感觉神经元单元,这些感觉神经元必须弄清楚自己的输入通道的上下文,然后使用注意力机制进行自组织进行通信,以共同为智能体输出运动命令。这样,即使屏幕上的补丁全部被打乱,代理仍然可以工作:
 |
感官替代。利用自组织和注意力的特性,我们的论文 Tang 和 Ha,2021 年研究了将他们的观察视为任意排序、可变长度的感觉输入列表的 RL 代理。在这里,他们将视觉任务(如CarRacing)中的输入划分为一个由小块组成的2D网格,并重新排列它们的顺序。系统中的每个感觉神经元都会接收到特定像素块的流,并且通过协调,必须完成手头的任务。该代理使用在训练期间未看到的新背景(它只看到绿草背景)。
这项工作的灵感来自感官替代的想法,其中大脑的不同部分可以被重新训练以处理不同的感官模式,使我们能够使我们的感官适应关键的信息源。
|
|

神经科学家Paul Bach-y-rita(1934-2006)被誉为“感官替代之父”。
这种方法也适用于非视觉任务。当我们将这种方法应用于运动任务时,就像这个蚂蚁代理一样,我们可以非常频繁地打乱 28 个输入的顺序,我们的智能体将快速调整到动态观察空间:
 |
适应感觉替换的排列不变强化学习代理。蚂蚁的 28 个观察结果的顺序每 200 个时间步长随机洗牌一次。与标准策略不同,我们的策略不受突然置换的输入的影响。
我们可以让代理玩一个 Puzzle Pong 游戏,其中补丁不断重新洗牌,我们展示了系统也可以处理部分信息,比如只有 70% 的补丁,这些补丁都是洗牌的:

五、多智能体学习
早期的强化学习示例主要是将单个智能体分解为较小的智能体集合。但是我们从复杂系统中了解到的是,出现通常比 10 或 20 个智能体大得多。也许我们需要数千个或更多个体代理的集合来有意义地相互作用,才能出现复杂的“超级有机体”。
几年前,有一篇论文研究了利用硬件加速器(如GPU)来实现多智能体强化学习的显著扩展。在这项名为MAgent的工作中(Zheng et al., 2018),他们提出了一个框架,可以让多达一百万个智能体(尽管是简单的智能体)参与各种网格世界的多智能体环境,此外,他们可以让一个智能体群体以集体自博的方式对抗另一个智能体群体。
 |
MAgent(Zheng et al., 2018)是一组环境,网格世界中的大量像素代理在战斗或其他竞争场景中进行交互。与大多数专注于使用单个代理或只有几个代理的 RL 研究的平台不同,它们的目标是支持扩展到数百万个代理的 RL 研究。
深度学习带来的硬件革命可以让我们利用硬件,并利用它们来训练真正的大规模集体行为。在其中一些实验中,他们观察到捕食者-猎物循环,包围战术从真正的大规模多智能体强化学习中出现。这些宏观层面的集体智慧可能不会从传统的小规模多智能体环境中出现:
|
|

我想指出的是,这项工作是从 2018 年开始的,从那时起,硬件加速进度只会呈指数级增长。NVIDIA 去年最近的一个演示展示了一个物理引擎,该引擎现在可以处理数千个代理在逼真的物理模拟中运行,这与简单的网格世界环境不同。我相信,在未来,我们可以看到使用这些新技术对涌现行为进行非常有趣的研究。
 |
GPU 硬件的最新进展可以对数千个机器人模型进行逼真的 3D 模拟,例如 Rudin 等人 2021 年在此图中显示的模型。这些进步为人工代理的大规模3D模拟打开了大门,这些智能体可以相互交互并共同开发智能行为。
六、元学习
计算能力的提高不会止步于模拟。最后,我将讨论如何将集体行为应用于元学习。我们可以将人工神经网络视为神经元和突触的集合,每个神经元和突触都可以建模为单个智能体,并且这些智能体都在一个系统内相互作用,其中学习能力是一种涌现属性。
目前,我们的人工神经网络概念只是具有非线性激活函数的节点之间的权重矩阵。但是通过额外的计算,我们也可以探索非常有趣的方向,在那里我们可以模拟神经网络的广义版本,其中也许每个“神经元”都被实现为一个相同的递归神经网络(原则上可以计算任何东西)。我记得有几篇神经科学论文探讨了这个主题,请参阅神经科学家马克·汉弗莱斯(Mark Humphries)的优秀博客文章。
|
|

每个“神经元”都是一个人工神经网络。“如果我们认为大脑是一台计算机,因为它就像一个神经网络,那么现在我们必须承认单个神经元也是计算机。它们全部 170 亿个都在你的皮层中;也许你大脑里有860亿个。
不过,最近我们看到了一些非常雄心勃勃的工作,而不是神经元,将突触建模为循环神经网络。这是因为当我们看一个标准神经网络是如何训练的时,我们通过网络的正向传递,将网络的输入正向传播到输出,然后我们使用反向传播算法将误差信号从输出层“反向传播”回输入层, 使用梯度来调整权重,因此原则上,RNN 突触也可以学习反向传播规则之类的东西,或者更好的东西。

每个突触都是一个循环神经网络。Sandler 等人(2021 年)和 Kirsch 和 Schmidhuber(2020 年)最近的工作试图推广公认的人工神经网络概念,其中每个神经元可以保持多个状态而不是标量值,并且每个突触双向运行以促进学习和推理。在该图中,(Kirsch 等人,2021 年)使用相同的递归神经网络 (RNN)(具有不同的内部隐藏状态)对每个突触进行建模,并表明可以通过简单地向前运行 RNN 来训练网络,而无需使用反向传播。
因此,与其依赖这种前向和后向传播,不如使用循环神经网络(通用计算机)对神经网络的每个突触进行建模,以学习如何最好地向前和向后传播信号,或学习如何学习。每个RNN的“隐藏状态”基本上会以一种高度可塑的方式定义“权重”。
最近的工作,Sandler 等人,2021 年和 Kirsch 和 Schmidhuber,2020 年,表明这些方法是反向传播的推广。他们甚至可以通过实验训练这些元学习网络,完美地复制反向传播操作,并执行随机梯度下降。但更重要的是,它们可以进化出学习规则,这些规则可以比随机梯度下降甚至ADAM更有效地学习。
在接下来的实验中,Kirsch 和 Schmidhuber,2020 年训练了这种类型的元学习系统,称为变量共享元学习器,蓝线,以仅使用 MNIST 数据集学习学习规则,其中这里的学习规则优于反向 SGD 和 Adam 基线,这是意料之中的,因为学习到的学习规则已微调为 MNIST 数据集。但是,当他们在新的数据集(如Fashion-MNIST)上测试学习规则时,他们看到了类似的性能提升:
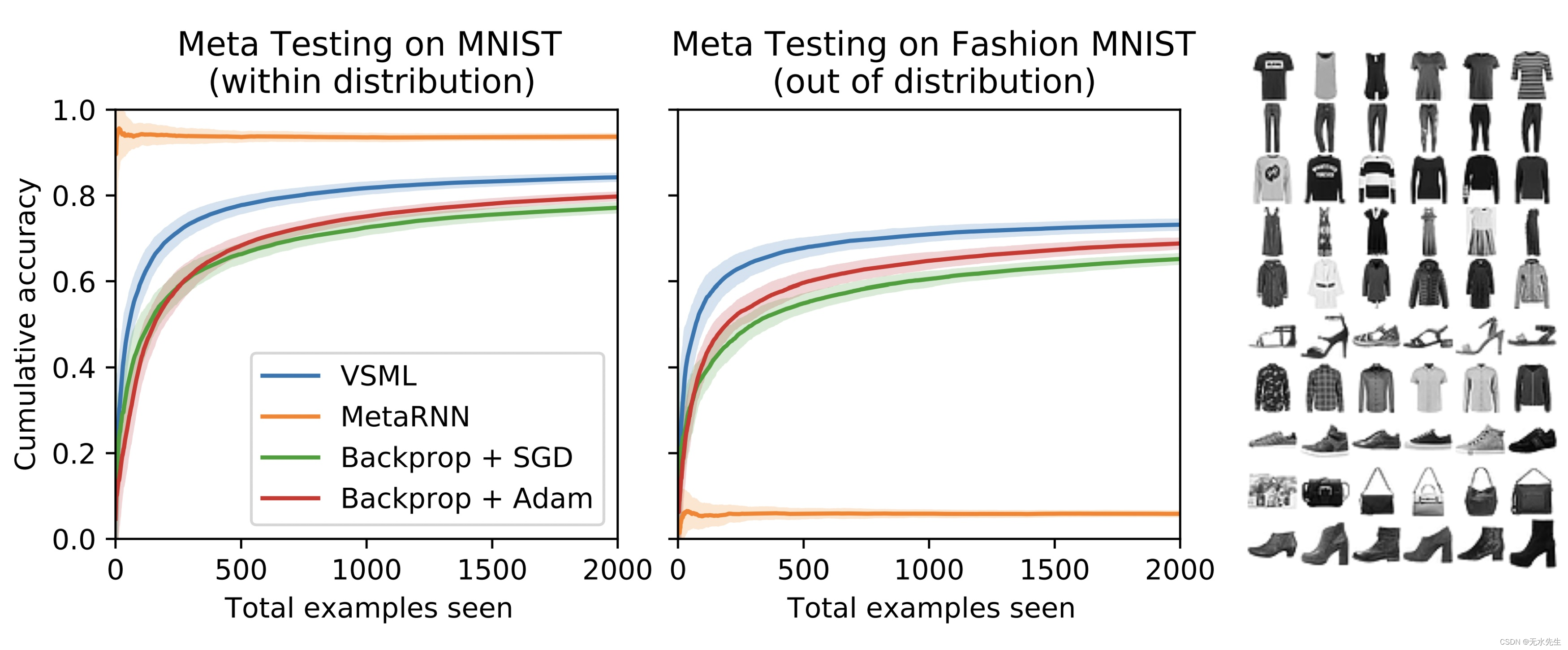
这些工作仍处于早期阶段,但我认为将神经网络建模为一组真正相同的神经元或突触,而不是固定的唯一权重,是一个非常有前途的方向,它将真正改变元学习的子领域。
七、总结
神经网络系统非常复杂。我们可能永远无法真正理解它们在简单的理想化系统中是如何工作的,这些系统可以用相对简单的物理定律来解释(和预测)。我相信深度学习研究可以从神经网络系统中受益:它们的构建、训练和部署,作为复杂的系统。我希望这篇博文是对复杂系统中的几个想法的有用调查,这些想法使神经网络系统更加健壮并适应环境的变化。
如果您有兴趣内容,请查看我们发表在《集体智慧》上的论文。