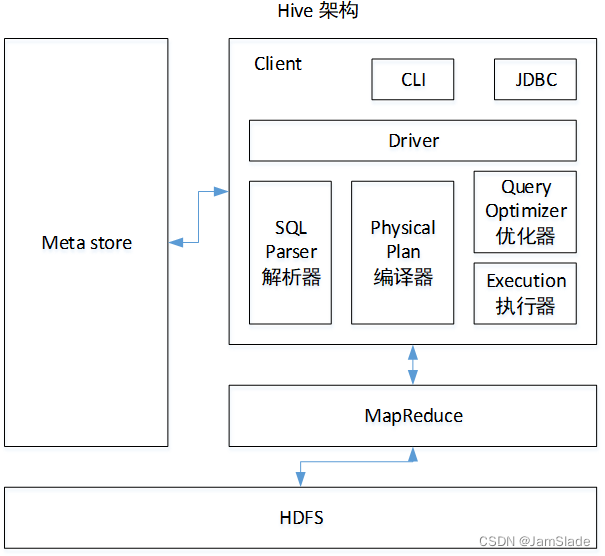
上一篇当中,使用pytorch搭建了一个squeezenet,效果还行。但是偶然间发现了一个稍微改动的版本,拿来测试一下发现效果会更好,大概网络结构还是没有变,还是如下的第二个版本:

具体看网络结构代码:
import torch
import torch.nn as nnclass Fire(nn.Module):def __init__(self, in_channel, out_channel, squzee_channel):super().__init__()self.squeeze = nn.Sequential(nn.Conv2d(in_channel, squzee_channel, 1),nn.BatchNorm2d(squzee_channel),nn.ReLU(inplace=True))self.expand_1x1 = nn.Sequential(nn.Conv2d(squzee_channel, int(out_channel / 2), 1),nn.BatchNorm2d(int(out_channel / 2)),nn.ReLU(inplace=True))self.expand_3x3 = nn.Sequential(nn.Conv2d(squzee_channel, int(out_channel / 2), 3, padding=1),nn.BatchNorm2d(int(out_channel / 2)),nn.ReLU(inplace=True))def forward(self, x):x = self.squeeze(x)x = torch.cat([self.expand_1x1(x),self.expand_3x3(x)], 1)return xclass SqueezeNet(nn.Module):"""mobile net with simple bypass"""def __init__(self, class_num=100):super().__init__()self.stem = nn.Sequential(nn.Conv2d(3, 96, 3, padding=1),nn.BatchNorm2d(96),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2))self.fire2 = Fire(96, 128, 16)self.fire3 = Fire(128, 128, 16)self.fire4 = Fire(128, 256, 32)self.fire5 = Fire(256, 256, 32)self.fire6 = Fire(256, 384, 48)self.fire7 = Fire(384, 384, 48)self.fire8 = Fire(384, 512, 64)self.fire9 = Fire(512, 512, 64)self.conv10 = nn.Conv2d(512, class_num, 1)self.avg = nn.AdaptiveAvgPool2d(1)self.maxpool = nn.MaxPool2d(2, 2)def forward(self, x):x = self.stem(x)f2 = self.fire2(x)f3 = self.fire3(f2) + f2f4 = self.fire4(f3)f4 = self.maxpool(f4)f5 = self.fire5(f4) + f4f6 = self.fire6(f5)f7 = self.fire7(f6) + f6f8 = self.fire8(f7)f8 = self.maxpool(f8)f9 = self.fire9(f8)c10 = self.conv10(f9)x = self.avg(c10)# x = x.view(x.size(0), -1)x = torch.flatten(x, start_dim=1)return xdef squeezenet(class_num=100):return SqueezeNet(class_num=class_num)
最大的变化就是在卷积层和relu激活层之间加了个bn层,包括所有的fire结构内。其余就是卷积和池化的kernel_size或stride的微调,包括最后去掉了dropout,以及最后部分的网络结构也稍作调整:

将这个网络结构与上一个的网络结构训练同一训练集,得到的模型测试同一测试集,发现这个模型的准确率会比上一个高几个点。而且上一个模型训练容易不稳定,训练到一半直接梯度爆炸了,需要不断调参也比较麻烦,这个模型lr直接0.1或0.01都能训练很好,所以个人更推荐这个网络模型。
下一篇编辑此网络结构的caffe版本。