🚀个人主页:为梦而生~ 关注我一起学习吧!
💡专栏:机器学习 欢迎订阅!后面的内容会越来越有意思~
💡往期推荐:【机器学习基础】机器学习入门(1)
💡本期内容:再次大致介绍一下机器学习
文章目录
- 分类和回归
- 来一个小测验
- 监督学习和无监督学习
这篇文章来说一下机器学习具体可以做哪些工作
分类和回归
机器学习任务大致分为分类和回归,两者的概念和区别如下:
- 分类问题:输出的是物体所属的类别。例如,我们可以根据天气历史数据,将天气分为晴天、阴天和雨天三类,然后根据今天的天气情况预测明天及以后几天的天气情况。
- 回归问题:输出的是物体的值,这个值是连续的。例如,根据过去的天气温度数据,我们可以预测未来的天气温度。每一个时刻,我们都能预测出一个温度值。
分类和回归的主要区别在于输出结果的不同。分类问题的输出是离散的,而回归问题的输出是连续的。
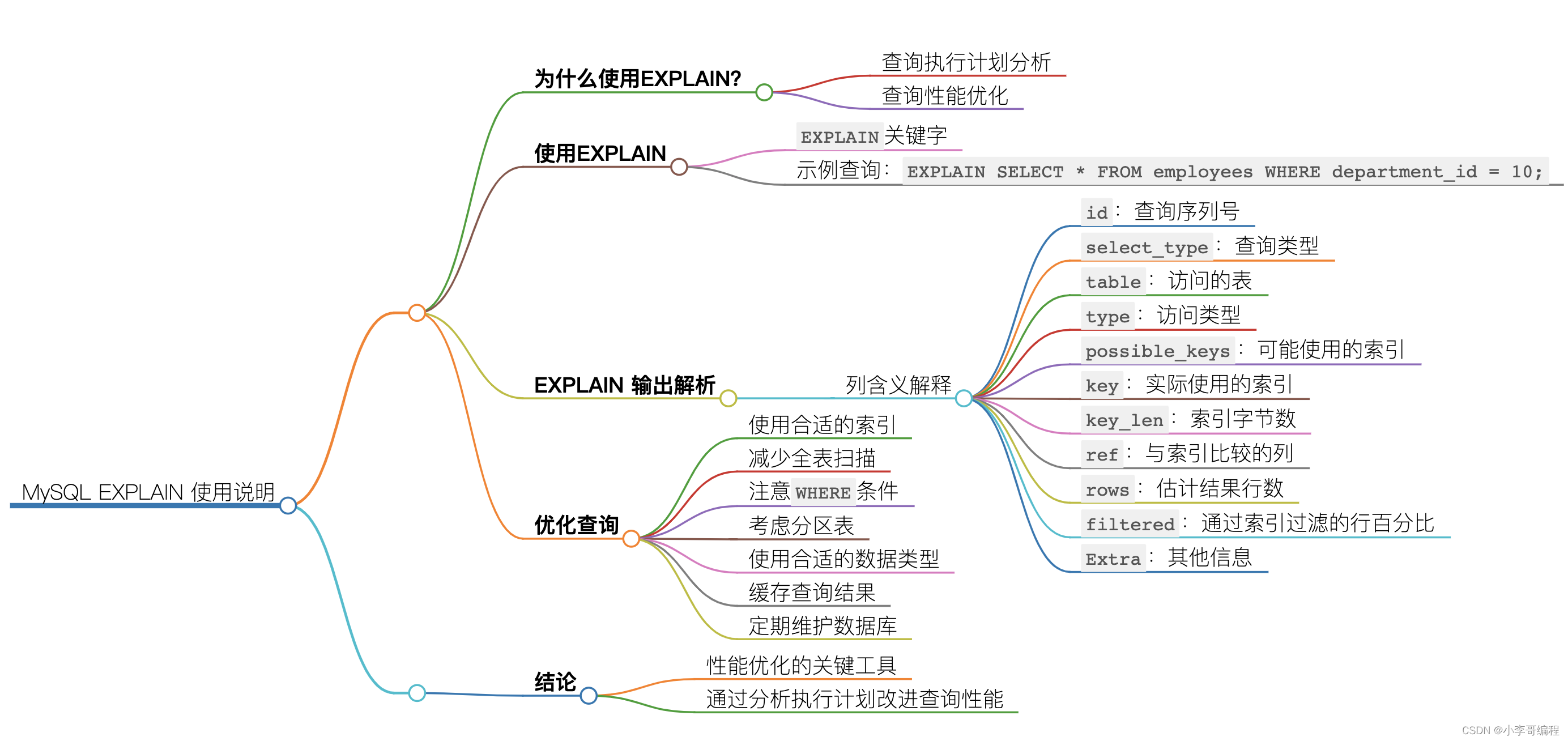
(最经典的例子)房屋价格预测(回归)
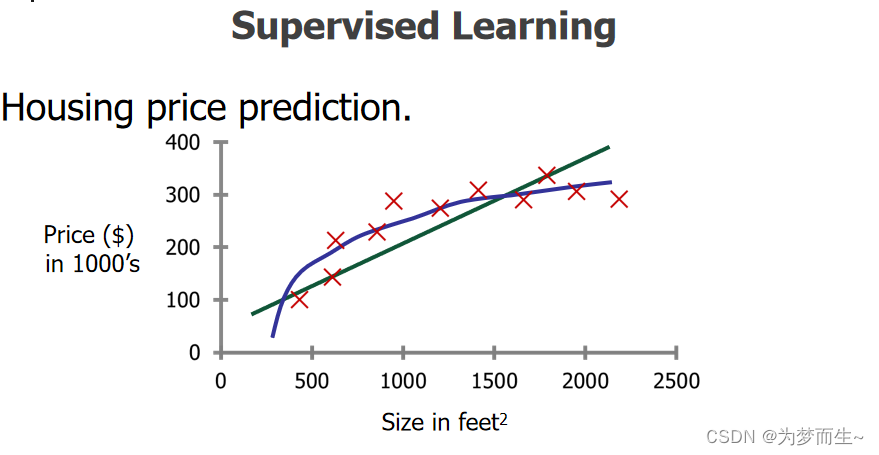
分析乳腺癌是恶行还是良性的(分类)
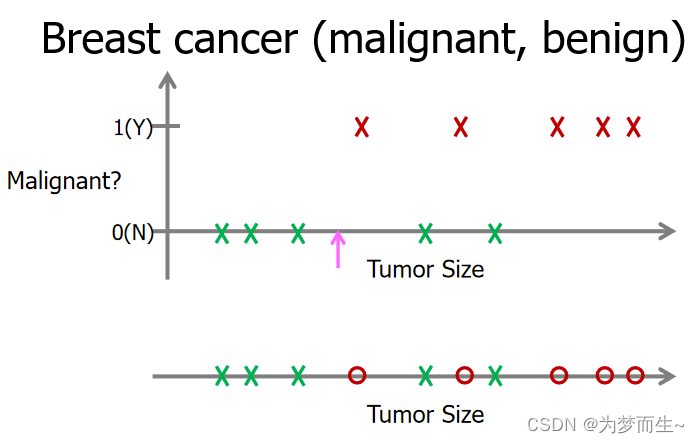
二维分类
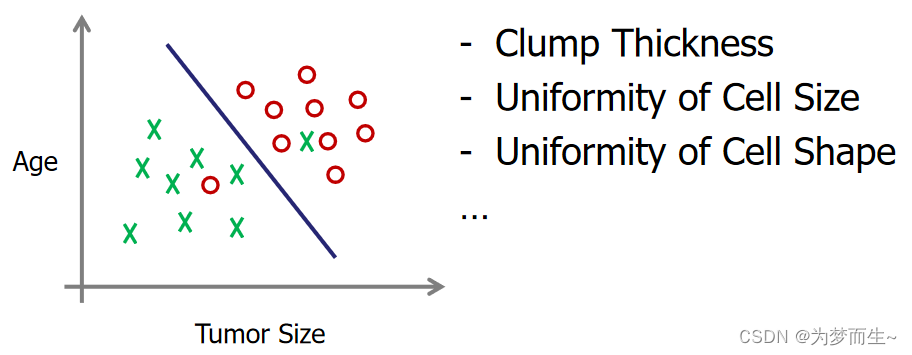
对于这种线性不可分的我们如何处理呢?
这里可以利用SVM等方法,后面会讲到~
来一个小测验
You’re running a company, and you want to develop learning algorithms to address each of two problems.
- Problem 1: You have a large inventory of identical items. You want to predict how many of these items will sell over the next 3 months.
- Problem 2: You’d like software to examine individual customer accounts, and for each account decide if it has been hacked/compromised.
Should you treat these as classification or as regression problems?
- Treat both as classification problems.
- Treat problem 1 as a classification problem, problem 2 as a regression problem.
- Treat problem 1 as a regression problem, problem 2 as a classification problem.
- Treat both as regression problems.
监督学习和无监督学习
机器学习中的监督学习(Supervised Learning)和无监督学习(Unsupervised Learning)是两种基本的学习方法。
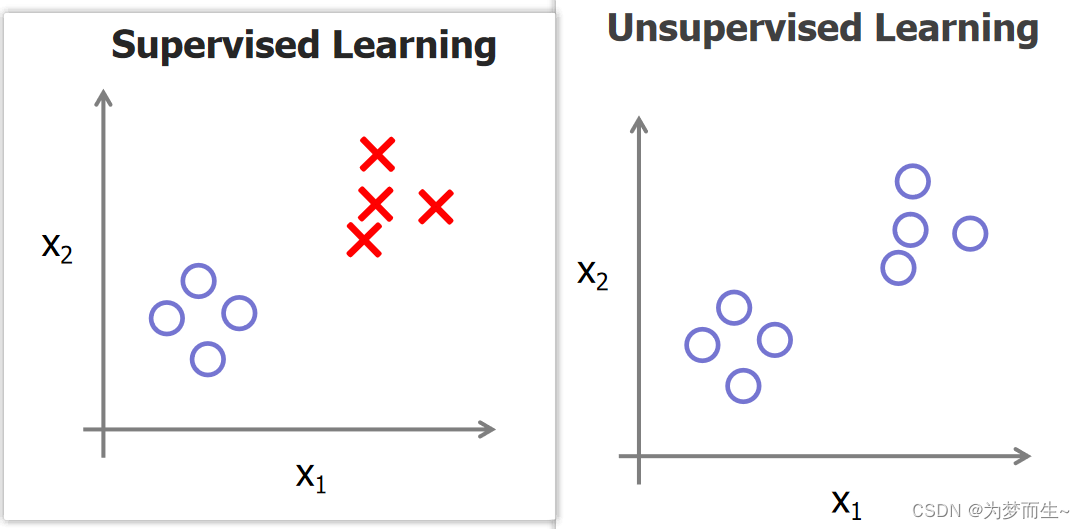
- 监督学习:利用训练集数据对其进行训练得到相应的正确对应关系,从而测试集数据在得到的对应关系下进行运算得到相应的正确结果。在监督学习中,对于数据集的每个样本,我们用算法预测并得出正确答案。监督学习可分为回归问题和分类问题。回归问题预测连续值的输出,分类问题预测离散值的输出。
- 无监督学习:数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。无监督学习的数据集没有标签或具有相同的标签,算法自动对数据集处理分类。
总的来说,监督学习和无监督学习的主要区别在于是否利用标签进行训练和测试。
机器学习是从人工智能中产生的一个重要学科分支,是实现智能化的关键。