目录
- 萝卜选坑
- 选择ChatGLM-6B的理由
- 选择硬件方案
- 购买GPU云服务器
- 充值
- 购买
- 配置环境
- 登录服务器
- 安装显卡驱动
- 安装CUDA
- 安装Python
- 部署ChatGLM-6B
- 下载项目程序包
- 安装Pytorch
- 安装依赖包
- 检查Pytorch是否为GPU版本
- 运行网页版Demo
- 保存镜像
萝卜选坑
生成式AI已经火了好几个月了,各种模型层出不穷,一直想自己搓一个玩玩,但又碰到日常选择性困难,不知道往哪个坑里跳更合适。难点如下:
- 模型太多,一个都不认识,感觉各个都是无底洞,如何挑选一个?
- 听说玩AI要显卡,而我只有集显笔记本,搞这个要花多少钱?
- 搞的AI是否具有可持续性,还是一锤子买卖?
选择ChatGLM-6B的理由
-
国产,ChatGLM出自于清华系,当前最大的模型为130B,有以下优点:

-
130B的ChatGLM综合性能略高于ChatGPT3,而ChatGPT3以上版本都不开源。
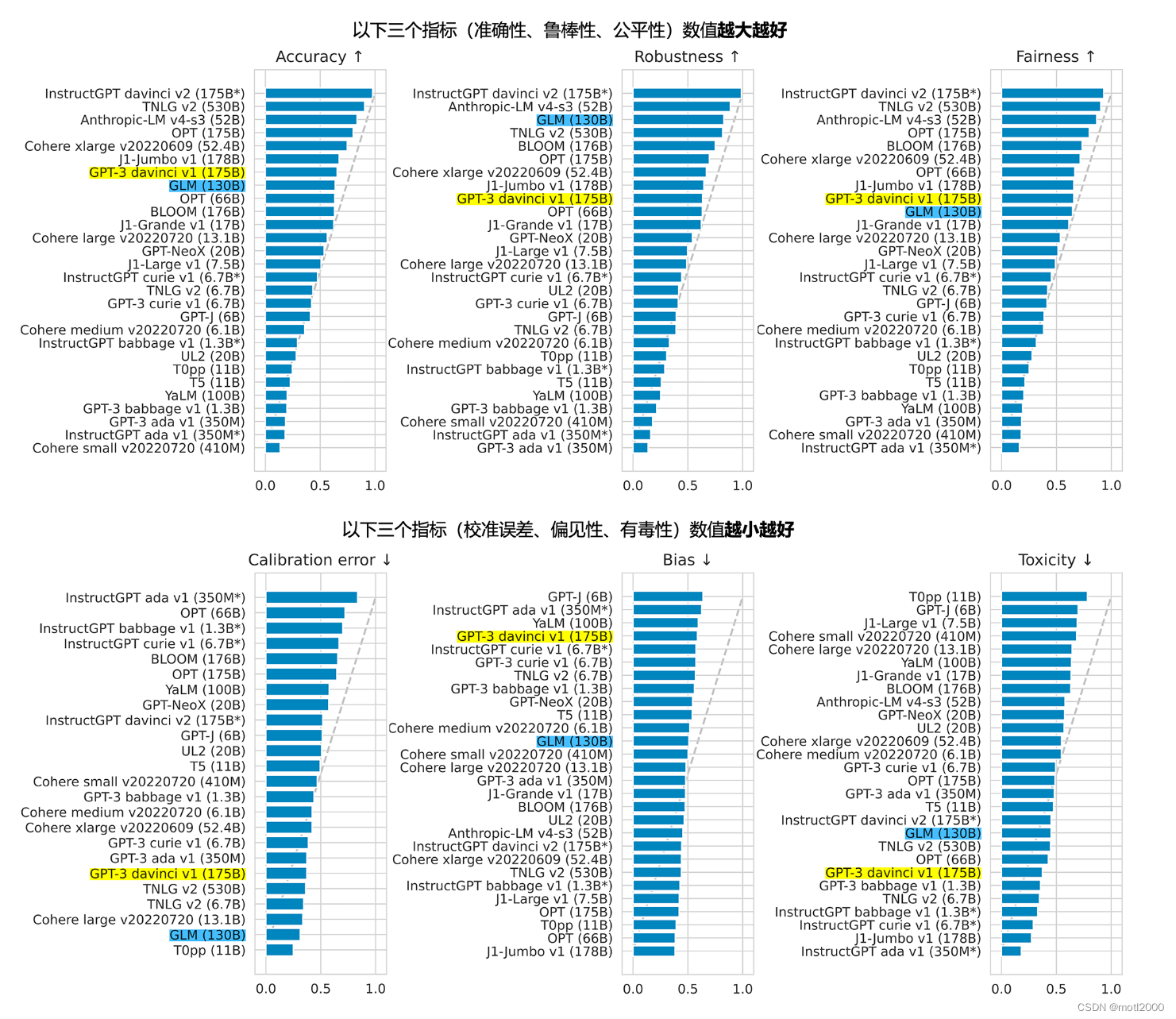
-
有适合单机部署的6B开源版本。这种硬件要求下,一张16G显存的显卡就可以顺滑的跑起来。
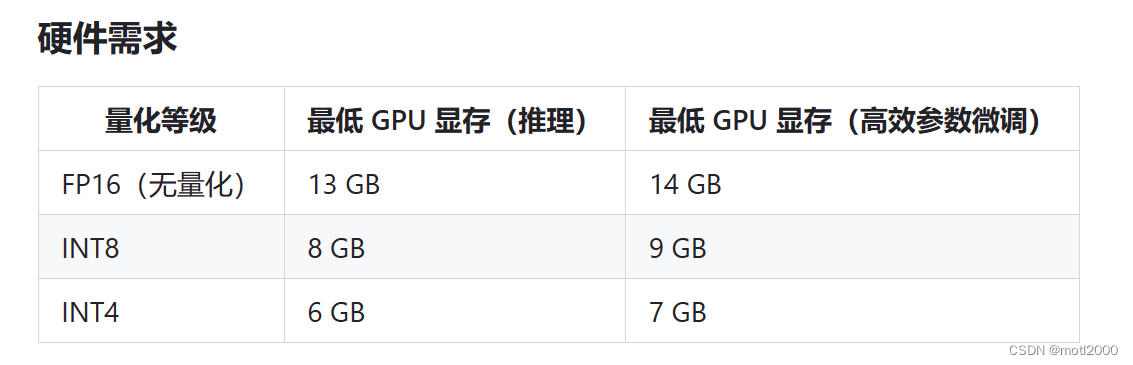
-
已有一定的生态环境,未来前景不错。https://github.com/THUDM/ChatGLM-6B

选择硬件方案
ChatGLM支持GPU和CPU模式,但听说CPU下速度很慢,就没有什么可玩性。所以还是需要搞一个合适的GPU环境。
一张16G显存显卡起码在1万上下,个人无论是搭台式机还是采用扩展坞,这入门成本都不低。如果资源可以一直得到充分利用,这投资还算划算,如果只是随便试一下的一次性买卖,那这投入就是打了水漂。
现在腾讯云提供适合运算的GPU云服务器,价钱也挺便宜,非常适合入门玩票。
购买GPU云服务器
登录腾讯云,https://cloud.tencent.com/
首先需要有腾讯云账号,没有的话按要求注册。
充值
如题,此部署方案每小时不到2元RMB,但由于创建GPU服务器后会需要先冻结8块多,所以充10元足够用几小时了。
购买
- 进入购买页
- 选择“竞价实例”

- 选择离你近的地区
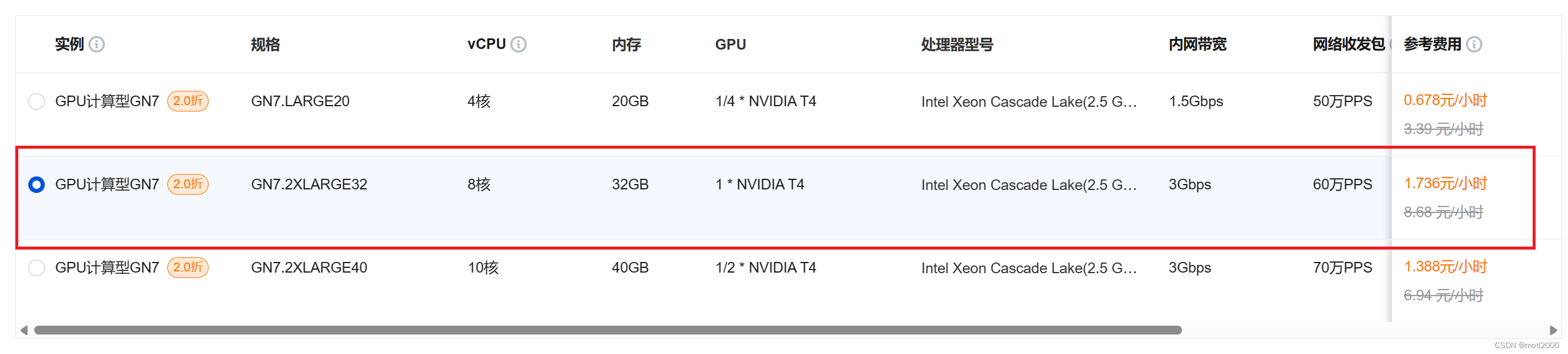
- 选择机型,如果你选择的地区没有此机型,就换一个地区。选择这个机型的原因是:支持windows,我不熟悉Linux。如果熟悉Linux的可以选择其他机型,成本更低。
- 选择操作系统,这里选择Windows。并选择Windows Server2002 64位中文版的镜像。如果是其他的操作系统,有些支持自动安装GPU驱动,或镜像中自带驱动及其他环境。Windows版本需要自己安装GPU和CUDA驱动。

- 设置存储,有两个方案
单盘模式,一个C盘,75G。为什么是75G?1. 安装运行环境需要较大的空间,50G不够用(本人亲身体验过的尴尬,装一半说空间不足) 。 2. 因为腾讯支持80G免费快照存储,保存快照就不用每次要使用时在此重新安装环境,下文会详细说明。
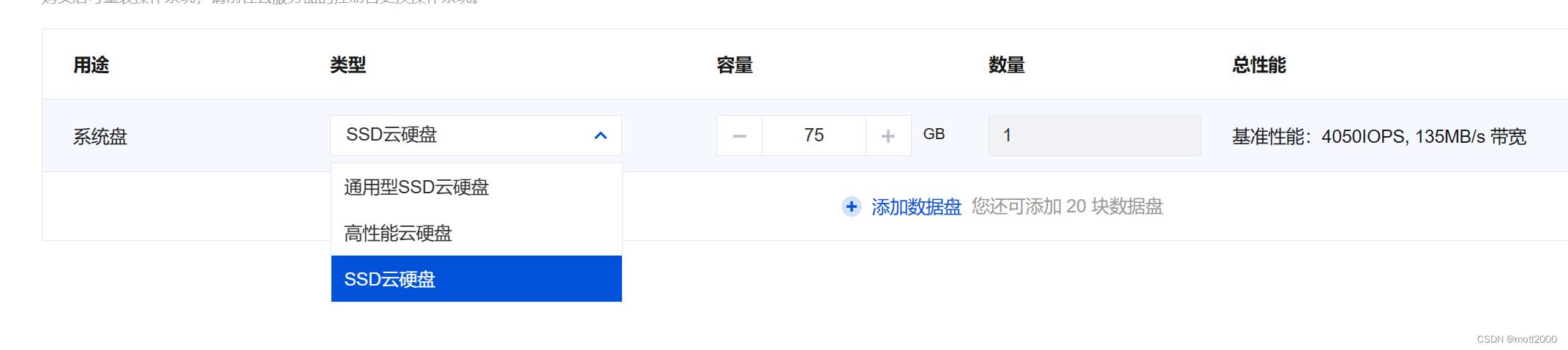
多盘模式,一个C盘,50G。一个数据盘,25G。原因也是如上,这个方案的优点是数据可以独立于系统盘挂载。还有一个原因是本人一开始选的50G系统盘不够用了,哈哈。
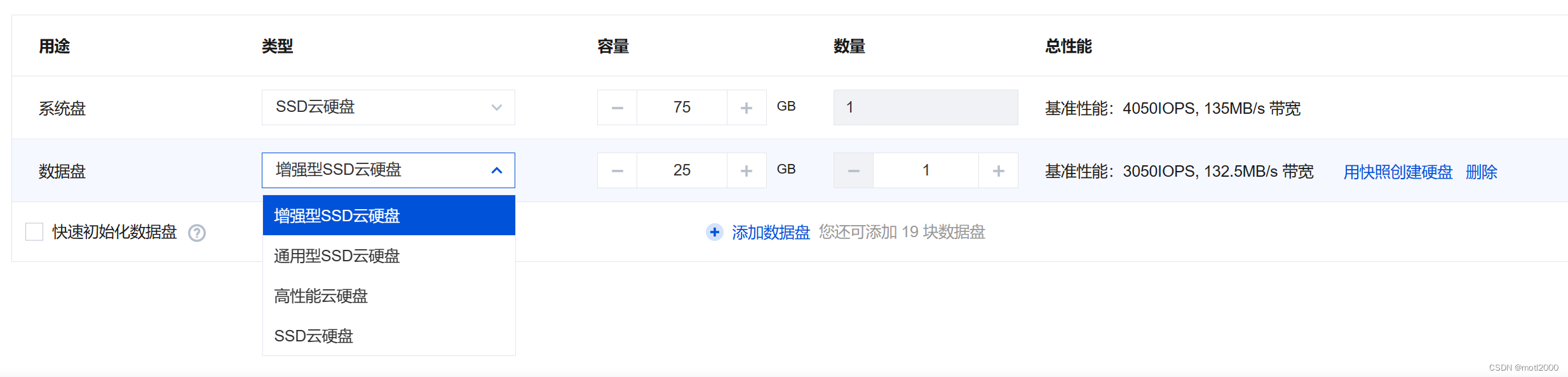
- 价格,选择任何云盘类型,配置价格也没有超过2元,这里可以自由选择,一般玩票差异不大。

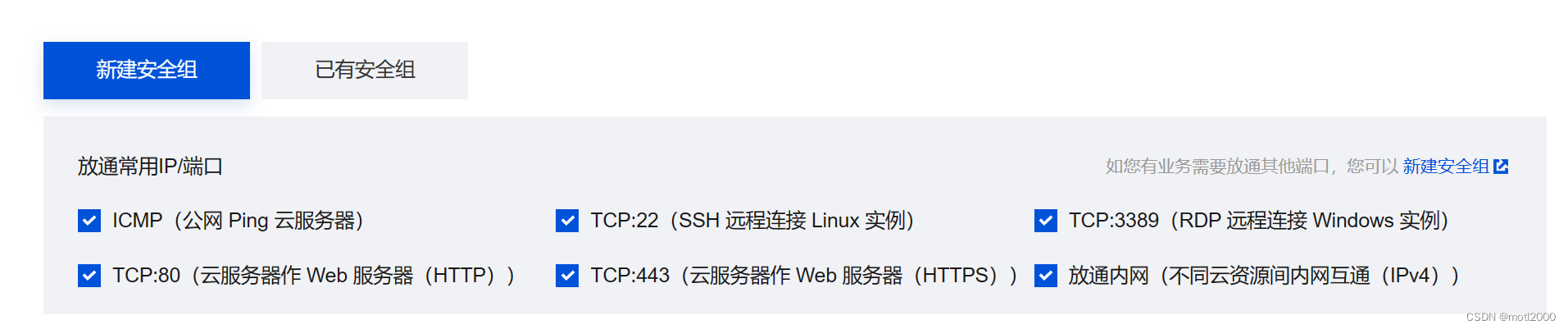
- 安全组,注意要打开3389,否则不能连接远程桌面。如果购机完成后,还是无法连接远程桌面,可以使用腾讯云提供的检查功能,然后在检查结果中开启端口。
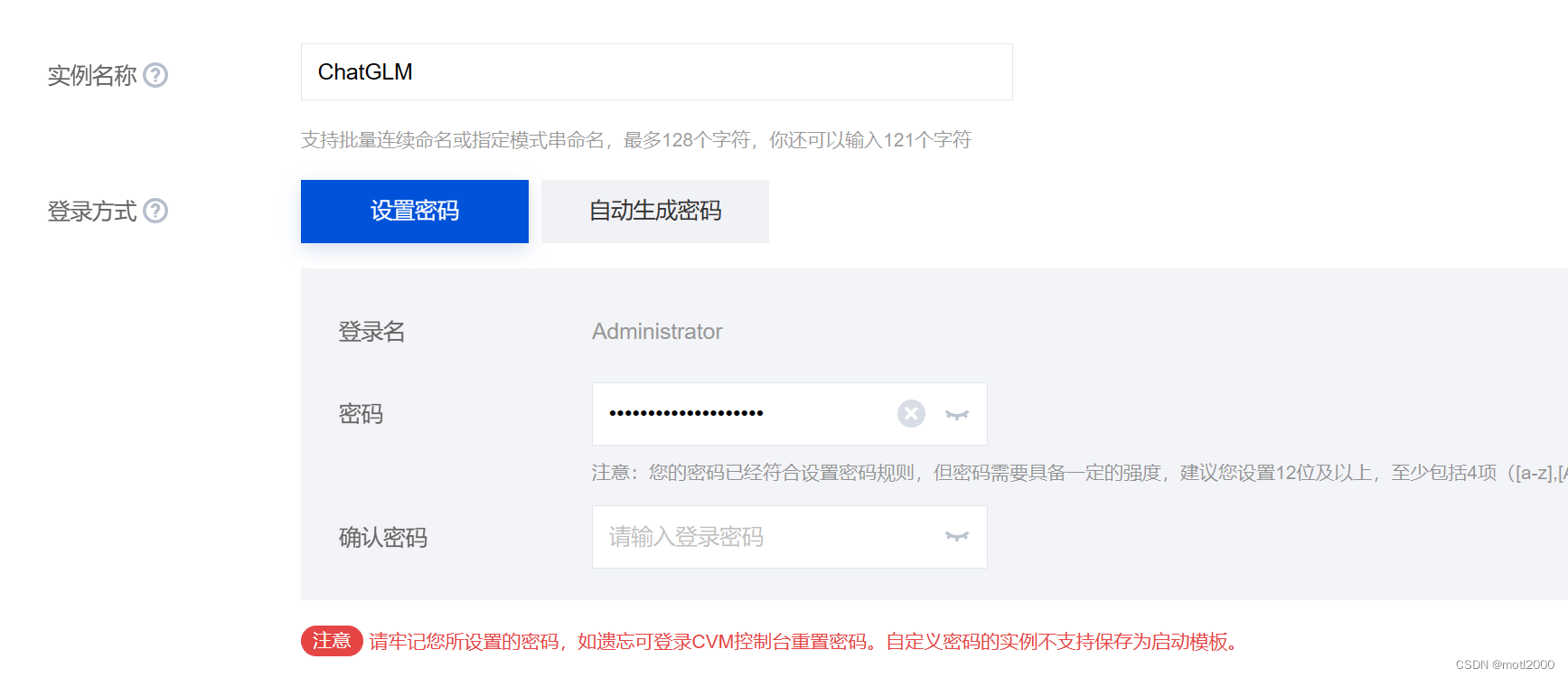
- 最后,给服务器起个名字,并设置管理员密码,这也是远程登录的密码。
- 最终价格,就是前面的配置费用,和网络单价。初始化环境时需要下载几十G的软件和包等。

配置环境
登录服务器
- 可以通过本地电脑远程链接GPU云服务器。服务器IP显示在实例列表中。
- 也可通过服务器列表中的“操作”远程连接服务器。
- 如果无法连接服务器,使用“自动检查”功能基本都可以排除。
安装显卡驱动
此服务器使用的是NVIDIA Tesla T4,16G显存。Window服务器需要手动安装显卡驱动。
如何安装可以在客服对话框里提问。
进入Windows驱动安装,按照说明步骤按照。
我选择的是这个:
安装CUDA
需要ChatGLM支持GPU模式的话,就必须按照CUDA。
如何安装可以在客服对话框里提问,如上。
我下载的是这个版本。
安装Python
-
Python安装,从官网下载(https://www.python.org/downloads/),我下载的是3.11
-
安装后如果pip命令提示不存在,使用以下命令安装,如果pip命令存在,就跳过此步。
py -m ensurepip --upgrade
- 修改pip安装包下载地址,因为默认是从国外下载,速度很慢。
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
pip config set install.trusted-host mirrors.aliyun.com
部署ChatGLM-6B
下载项目程序包
- 从GitHub下载项目程序包,https://github.com/THUDM/ChatGLM-6B
- 下载后解压到本地目录,如D:\ChatGLM\ChatGLM-6B-main
- 下载模型包chatglm,https://huggingface.co/THUDM/chatglm-6b/tree/main
- huggingface里不能打包下载,只能一个个下载(因为没有找到打包下载的地方),下载到D:\ChatGLM\ChatGLM-6B-main\chatglm-6b。
- 8个模型文件(1G以上的那8个)不用在huggingface里下载,从这里下载:https://cloud.tsinghua.edu.cn/d/fb9f16d6dc8f482596c2/
安装Pytorch
在项目文件的requirements.txt里是有Pytorch的,但是自动安装时安装的是CPU的版本,就无法使用GPU,这里我搞了很久,也可能是因为我对这方面还不熟悉,前面有些步骤不正确导致的。
我手动安装了CUDA版本的Pytorch,在Pytorch官网生成安装命令,https://pytorch.org/get-started/locally/

执行生成的命令就可以安装Pytorch了。
安装依赖包
在项目目录中执行:
pip install -r requirements.txt
检查Pytorch是否为GPU版本
在python中运行
>>> import torch
>>> torch.cuda.is_available()
True
返回True说明现在为GPU版本
运行网页版Demo
- 修改模型路径,编辑web_demo.py,修改路径为模型包保存的目录
#model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
model = AutoModel.from_pretrained("D:\ChatGPT\ChatGLM-6B-main\chatglm-6b", trust_remote_code=True).half().cuda()
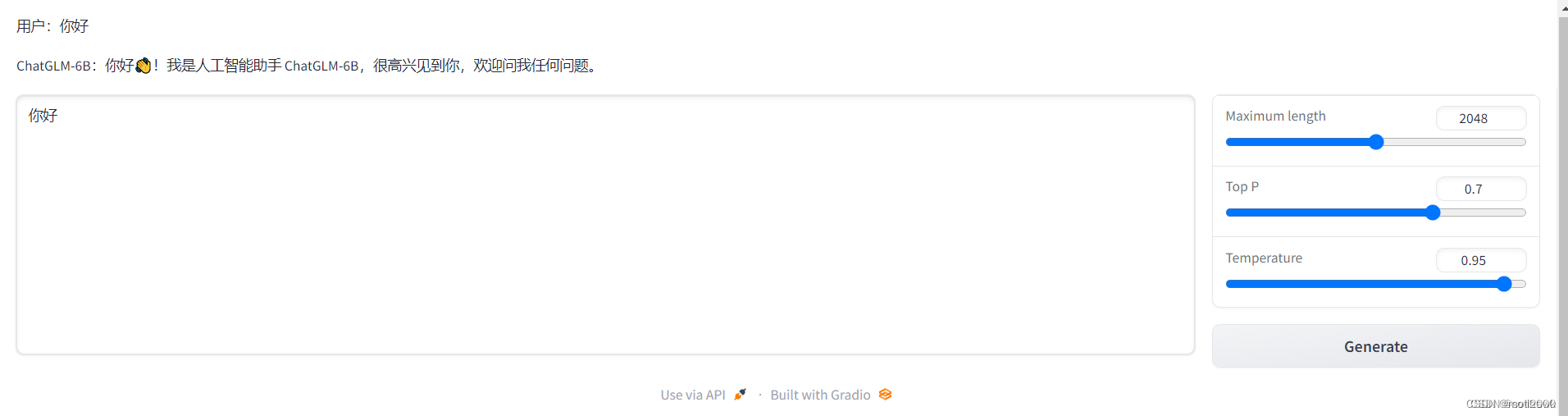
- 执行如下命令,运行网页版本的demo,如下
python web_demo.py
保存镜像
这个GPU云服务器的方案是按时间计费的,服务器空闲时间也是计费的,即使关机也不会停止计费。如要停止计费,必须将服务器和云盘都销毁。一旦销毁后,下次还想再使用ChatGLM就只能重复以上繁琐的步骤,至少需要2个小时。
因此,我们可以利用腾讯提供的80G免费快照空间。
当不再需要运行ChatGLM时,可以将当前的服务器和云盘保存为镜像和快照,然后销毁相应资源。
当需要再次使用时,只须在购买设置配置时选择保存的镜像和快照,就可以立刻恢复上次保存的内容。
既省钱又方便,赞!