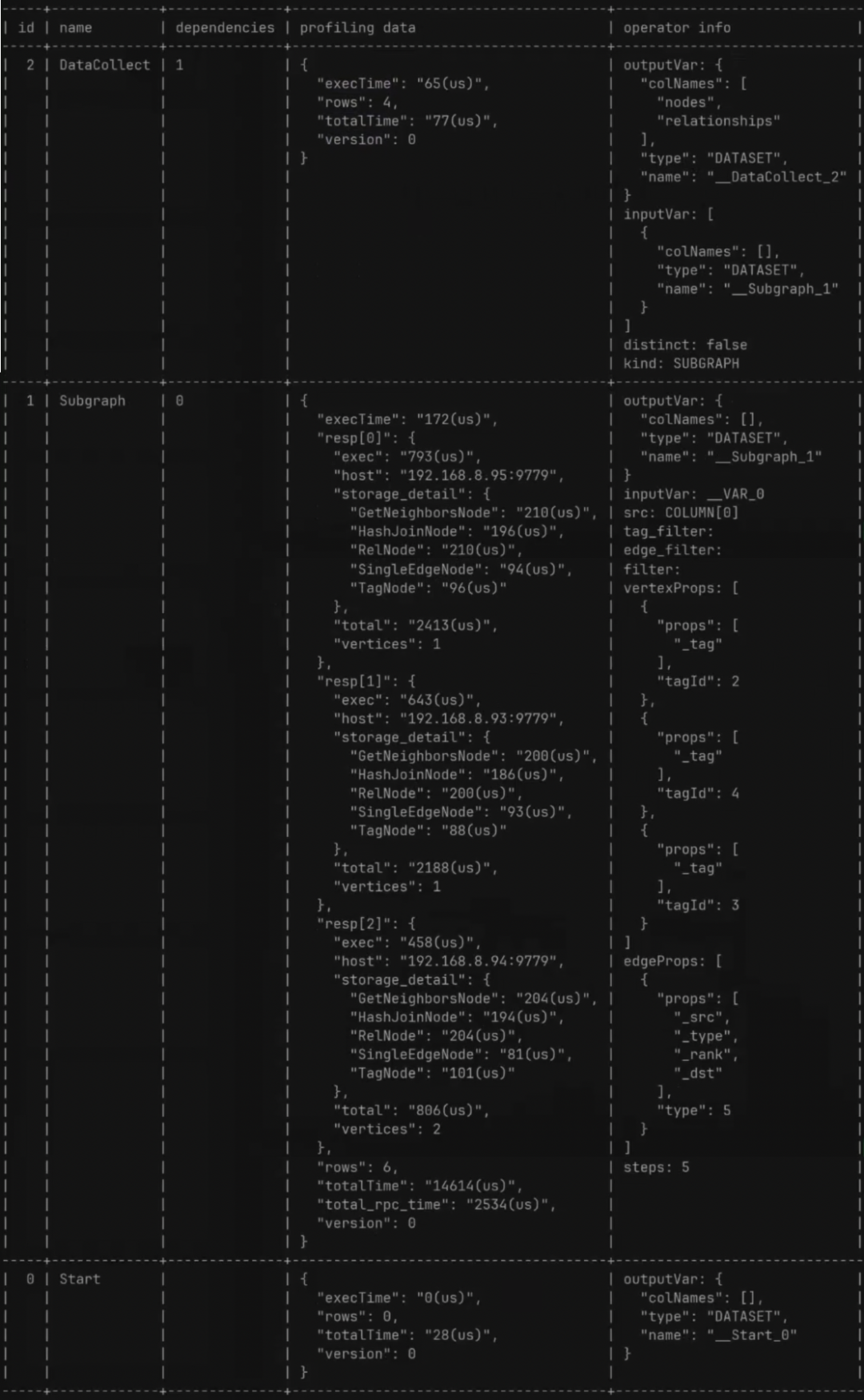
一般而言cpu异常往往还是比较好定位的。原因包括业务逻辑问题(死循环)、频繁gc以及上下文切换过多。而最常见的往往是业务逻辑(或者框架逻辑)导致的,可以使用jstack来分析对应的堆栈情况。
使用jstack排查占用率问题
当使用jstack排查占用率问题时,可以按照以下步骤进行:
- 首先,使用top命令找到占用率较高的进程,并记录其PID。
- 接着,使用以下命令来查看该进程中占用CPU较高的线程:
top -H -p <pid>该命令将显示进程中各个线程的CPU使用率,以及线程的ID(TID)。
3. 根据线程ID(TID)获取nid,可以使用以下命令:
printf '%x\n' <tid>这将把TID转换为16进制格式的nid。
4. 然后,通过以下命令来查看该线程的堆栈信息:
jstack <pid> | grep 'nid' -C5 --color
该命令将显示包含nid的堆栈信息。注意,这里使用了grep命令来过滤输出结果,只显示包含nid的部分。-C5表示在匹配项前后各显示5行上下文信息,--color则用于在输出中添加颜色标记。
5. 除了逐个查看线程的堆栈信息外,还可以对整个jstack文件进行分析。可以使用以下命令来统计各个状态的线程数量:
cat jstack.log | grep "java.lang.Thread.State" | sort -nr | uniq -c该命令将输出各个线程状态的数量,例如RUNNABLE、BLOCKED、WAITING、TIMED_WAITING等。如果WAITING或TIMED_WAITING的数量较多,那么可能存在一些问题。
通过以上步骤,我们可以使用jstack来定位占用率较高的问题,并进一步分析问题原因。
频繁GC问题
通过使用jstat工具的-gc选项,我们可以观察GC的分代变化情况,以便确定GC是否过于频繁。具体来说,我们可以使用以下命令来观察进程的GC情况:
jstat -gc <pid> 1000在上述命令中,<pid>是目标Java进程的PID,而1000表示采样间隔(以毫秒为单位)。通过这个命令,我们可以获取关于Survivor区、Eden区、老年代(Old Generation)、元数据区(Metaspace)的容量和使用量信息,以及关于Young GC和Full GC的耗时和次数以及总耗时信息。

具体来说,以下是一些关键指标的含义:
- S0C/S1C和S0U/S1U:这两个指标分别表示Survivor 0区和Survivor 1区的容量和已使用的容量。如果这些值接近或达到其最大值,则可能需要进行GC。
- EC/EU:这两个指标分别表示Eden区的当前容量和已使用的容量。如果这些值接近或达到其最大值,则可能需要进行GC。
- OC/OU:这两个指标分别表示老年代的当前容量和已使用的容量。如果这些值接近或达到其最大值,则可能需要进行GC。
- MC/MU:这两个指标分别表示元数据区的当前容量和已使用的容量。如果这些值接近或达到其最大值,则可能需要进行GC。
- YGC/YGT:这两个指标分别表示Young GC的次数和所花费的总时间。如果这些值较高,则可能表明应用程序存在过多的短期对象引用,需要优化。
- FGC/FGCT:这两个指标分别表示Full GC的次数和所花费的总时间。如果这些值较高,则可能表明应用程序存在过多的长期对象引用,需要优化。
- GCT:这个指标表示应用程序进行GC的总时间。如果这个值较高,则可能表明应用程序需要进行优化以减少GC的开销。
通过观察这些指标,我们可以更好地了解Java进程的内存使用情况和垃圾回收情况。如果发现GC过于频繁或存在其他问题,我们可以进一步分析并采取相应的优化措施。
频繁上下文切换
上下文切换会消耗CPU的时间,并导致进程真正运行的时间缩短,从而成为系统性能下降的一个因素。过多的上下文切换可能会使得CPU花费过多的时间用于保存和恢复寄存器、内核栈以及虚拟内存等数据,从而影响系统的响应速度和吞吐量。
vmstat是一个非常有用的系统性能分析工具,它可以提供关于系统内存、CPU活动、分页和上下文切换等信息。
在使用vmstat查看上下文切换情况时,可以显示以下统计信息:

- "cs"(上下文切换):显示系统每秒上下文切换的次数。自愿上下文切换(voluntary context switches)和非自愿上下文切换(non voluntary context switches)都会被计算在内。
- "in"(中断):显示系统每秒中断的次数。这些中断可能来自硬件设备、网络或其他原因。
- "r"(运行或可运行):显示正在运行或等待CPU的进程数。这个统计信息可以提供关于系统负载的总体视图。
- "b"(阻塞):显示处于不可中断睡眠状态的进程数。这些进程通常是在等待某些资源(如I/O操作)可用。
需要注意的是,vmstat命令的具体选项和输出可能会因操作系统和版本而有所不同。在使用vmstat时,建议查阅相关文档或使用"man vmstat"命令来获取特定系统上vmstat的详细使用说明和输出解释。
vmstat是给出整个系统总体的上下文切换情况,要想查看每个进程的详细情况就需要使用pidstat,加上-w选项就可以查看进程上下文切换的情况 pidstat -w pid命令,cswch和nvcswch表示自愿及非自愿切换。

cswch(voluntary context switches):表示每秒自愿上下文切换的次数nvcswch(non voluntary context switches):表示每秒非自愿上下文切换的次数
- 自愿上下文切换:进程无法获取所需的资源,导致的上下文切换,例如IO、内存等资源不足时,就会发生自愿上下文切换
- 非自愿上下文切换:进程由于时间片已到等时间,被系统强制调度,进而发生的上下文切换,例如大量的进程都在争抢CPU时,就容易发生非自愿上下文切换
系统上下文切换的次数为多少时是不正常的呢?
系统上下文切换的次数是否正常,取决于系统本身的CPU性能。一般来说,如果系统的上下文切换次数比较稳定,在数百到一万以内,都应该算是正常的。然而,当上下文切换次数超过一万次,或者切换次数出现数量级的增长时,就可能已经出现了性能问题。
具体遇到问题的时候,需要根据变化的上下文切换类型,再做具体分析。例如:自愿上下文切换变多了,说明进程都在等待资源,有可能发生了I/O等其他问题;非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢CPU,说明CPU的确成了瓶颈;中断次数变多了,说明CPU被中断处理程序占用,还需要通过查看/proc/interrupts文件来分析具体的中断类型。
https://www.toutiao.com/article/7294434753896792576/?app=news_article×tamp=1699856724&use_new_style=1&req_id=2023111314252400148FBCC5B1CF0D3913&group_id=7294434753896792576&wxshare_count=1&tt_from=weixin&utm_source=weixin&utm_medium=toutiao_android&utm_campaign=client_share&share_token=ecfddbaf-50a8-45ce-a206-1bbae14913a4&source=m_redirect&wid=1699856992481