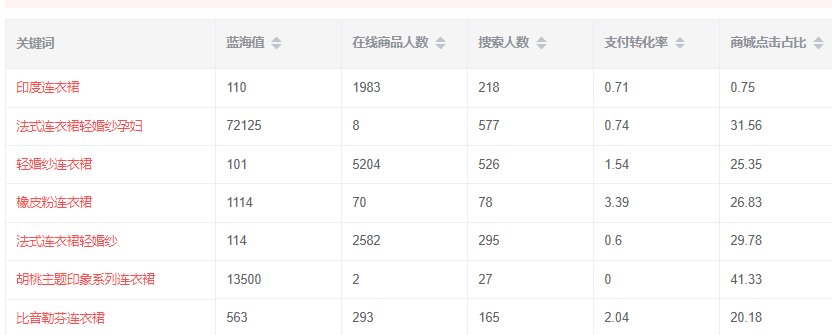
目录
一、引言
二、Rust爬虫框架介绍
三、爬虫代码实现
1、创建Scrapy项目
2、创建Spider
3、定义Item对象
4、修改settings.py文件
5、运行爬虫程序
四、图片抓取与存储
五、优化爬虫性能
六、注意事项
总结
一、引言
网络爬虫是一种自动化的网页访问工具,可以按照预设的规则自动抓取互联网上的信息。Rust是一种高性能的系统编程语言,具有强大的并发处理能力和内存管理功能。使用Rust编写爬虫代码可以充分利用其高效的并发性能和内存管理功能,提高数据采集的效率和质量。本文将介绍如何使用Rust编写爬虫代码来抓取精美的图片,并通过实际案例进行详细说明。

二、Rust爬虫框架介绍
在Rust中,有很多流行的爬虫框架可供选择,如Scrapy、Reqwest、getrequests等。其中,Scrapy是一个功能强大的Web爬虫框架,支持异步操作和多线程,可以方便地抓取网页内容并解析出所需的数据。Reqwest是一个基于异步IO的HTTP客户端库,具有简单易用的API和高效的性能。getrequests是一个基于异步IO的HTTP库,具有简单易用的API和广泛的支持。
三、爬虫代码实现
下面是一个使用Scrapy框架实现爬取图片的示例代码:
1、创建Scrapy项目
首先,我们需要安装Scrapy框架,创建一个新的Scrapy项目。在终端中执行以下命令:
$ cargo install scrapy
$ scrapy startproject myproject2、创建Spider
在Scrapy项目中,我们需要创建一个Spider来定义爬取规则和数据处理方式。在myproject文件夹中创建一个新的Spider文件,命名为myspider.py。在myspider.py文件中,我们需要定义以下内容:
导入所需的模块和库
定义Spider类,继承自scrapy.spider.Spider类
在Spider类中定义start_requests()方法,生成初始请求并返回Request对象列表
在Spider类中定义parse()方法,解析响应内容并返回Item对象或Request对象列表
3、定义Item对象
在Scrapy项目中,我们需要定义一个Item对象来存储抓取的数据。在myproject文件夹中创建一个新的Item文件,命名为myitem.py。在myitem.py文件中,我们需要定义以下内容:
导入所需的模块和库
定义MyItem类,继承自scrapy.item.Item类
在MyItem类中定义所需的字段,如url、title、description等
4、修改settings.py文件
在Scrapy项目的settings.py文件中,我们需要配置一些参数来控制爬虫的运行方式。我们需要修改以下参数:
设置DOWNLOAD_DELAY参数为适当的延迟时间,以避免被目标网站封禁
设置CONCURRENT_REQUESTS参数为适当的并发请求数,以控制爬虫的并发处理能力
设置DOWNLOADER_MIDDLEWARES参数来添加自定义的中间件,如代理、重试等
5、运行爬虫程序
在终端中进入Scrapy项目的根目录,执行以下命令来运行爬虫程序:
$ scrapy crawl myspider -o myitem.json -t json
四、图片抓取与存储
在爬虫代码中,我们可以使用XPath或CSS选择器来定位和提取网页中的图片链接。以下是一个示例代码片段,演示如何使用XPath定位图片链接:
import scrapy class MySpider(scrapy.Spider): name = 'myspider' start_urls = ['http://example.com'] def parse(self, response): # 使用XPath定位图片链接 image_links = response.xpath('//img[@class="image"]/@src').getall() # 处理图片链接,存储图片或下载图片 for link in image_links: # 这里可以存储图片链接或下载图片,具体取决于你的需求 self.log(f"Found image link: {link}")在上述代码中,我们使用XPath定位了包含class="image"属性的img元素的src属性,以提取图片链接。然后,在循环中处理每个图片链接,可以根据需要存储到数据库、下载到本地或执行其他操作。
五、优化爬虫性能
为了提高爬虫的性能和效率,可以采取以下措施:
使用并发处理:Rust提供了强大的并发处理能力,可以使用多线程或多进程来并发访问不同的网页,加快数据采集速度。
使用异步IO:Rust的异步IO库tokio和async-std可以显著提高网络请求的响应速度,减少等待时间。
使用代理:如果目标网站对IP地址有限制,可以使用代理来隐藏真实的IP地址,提高访问成功率。
避免重复访问:在爬虫代码中加入去重机制,避免重复访问相同的网页,提高效率。
异常处理:在爬虫代码中加入适当的异常处理机制,避免因为错误导致程序崩溃或停止。
数据清洗:在数据处理阶段,对数据进行清洗和过滤,去除无效或低质量的数据。
结果存储:将抓取到的数据存储到数据库或其他存储介质中,方便后续分析和利用。
分布式爬虫:将爬虫程序分布到多个节点上运行,提高数据采集速度和效率。
负载均衡:通过负载均衡技术将请求分配给多个服务器或节点,避免单个节点负载过高或被目标网站封禁。
定期维护:定期对爬虫程序进行维护和更新,修复漏洞和错误,保持程序的稳定性和可用性。
六、注意事项
在使用爬虫抓取数据时,需要注意以下几点:
遵守法律法规:遵守相关法律法规和网站的使用条款,不得进行非法或违规的数据采集和使用。
尊重隐私:在抓取数据时,要尊重用户的隐私权,不得采集和利用用户的个人信息。
避免对目标网站造成影响:在抓取数据时,要避免对目标网站的性能和稳定性造成影响,如不要过于频繁地访问或大量下载文件。
处理异常情况:在抓取数据时,要预料到可能出现的异常情况,如网络中断、服务器宕机等,并制定相应的处理策略,避免程序崩溃或数据丢失。
数据清洗和过滤:在数据处理阶段,要对数据进行清洗和过滤,去除无效或低质量的数据,保证数据的准确性和完整性。
定期备份数据:在抓取数据时,要定期备份数据,避免数据丢失或损坏。
避免被目标网站封禁:在抓取数据时,要遵守目标网站的使用规则,避免被目标网站封禁或限制访问。
尊重他人的劳动成果:在使用爬虫抓取数据时,要尊重他人的劳动成果,不得盗用他人的数据或研究成果。
总结
在使用爬虫抓取数据时,要遵守相关法律法规和道德规范,尊重他人的劳动成果和隐私权,不得进行非法或违规的数据采集和使用。同时,要注意程序的稳定性和可用性,保证数据的准确性和完整性。