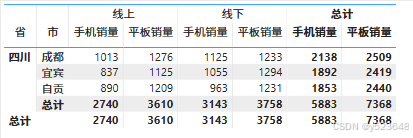
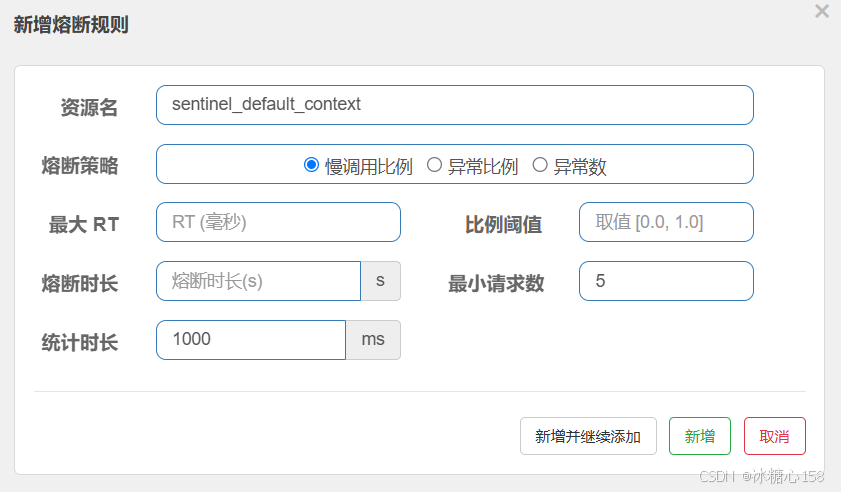
1. 定义与原理
监督学习依赖于标记数据(即每个输入样本都对应已知的输出标签),模型通过分析这些数据中的规律,建立从输入特征到目标标签的映射函数。例如,在垃圾邮件检测中,输入是邮件内容,输出是“垃圾”或“非垃圾”标签。这种“监督”来源于训练过程中标签对模型的指导,即通过损失函数衡量预测与真实标签的差异,并通过优化算法(如梯度下降)调整模型参数以最小化误差。
2. 主要类型
监督学习可分为两类:
- 分类(Classification) :预测离散的类别标签,例如判断图像是否为猫(二分类)或识别手写数字(多分类)。常用算法包括逻辑回归、支持向量机(SVM)、决策树等。
- 回归(Regression) :预测连续值,如房价或气温。典型算法有线性回归、随机森林回归等。
3. 工作流程
监督学习的实施通常包括以下步骤:
- 数据收集与预处理:清洗数据、处理缺失值、归一化等,以提高数据质量。
- 模型选择:根据问题类型(分类或回归)选择合适的算法。
- 训练与优化:通过训练数据调整模型参数,使用交叉验证防止过拟合,并通过超参数调优提升性能。
- 评估与部署:用测试数据评估模型泛化能力,最终部署到实际场景中。
4. 常见算法
- 分类算法:逻辑回归、K最近邻(KNN)、朴素贝叶斯、神经网络。
- 回归算法:线性回归、高斯过程回归、支持向量回归(SVR)。
- 集成方法:随机森林、梯度提升树(如XGBoost),通过组合多个弱模型提升性能。
5. 应用领域
监督学习广泛应用于:
- 图像识别(如人脸识别)。
- 自然语言处理(如情感分析、机器翻译)。
- 金融领域(如风险评估、股票预测)。
- 医疗诊断(如疾病预测)。
- 推荐系统(如电商商品推荐)。
6. 挑战与限制
- 数据依赖:需要大量高质量标记数据,而数据标注成本高。
- 过拟合与欠拟合:模型可能在训练数据上表现过好(过拟合)或无法捕捉规律(欠拟合)。
- 数据不平衡:某些类别样本过少可能导致模型偏向多数类。
- 特征工程:人工设计有效特征耗时且需要专业知识。
7.监督学习过程示例