了解 HashMap 源码吗?
参考文章:https://juejin.cn/post/6844903682664824845
https://blog.51cto.com/u_15344989/3655921
以下均为 jdk1.8 的 HashMap 讲解
首先,HashMap 的底层结构了解吗?
底层结构为:数组 + 链表 + 红黑树
什么时候链表会转换为红黑树呢?
当一个位置上哈希冲突过多时,会导致数组中该位置上的链表太长,链表的查询时间复杂度是O(N),即查询代价随着链表长度线性增长,那么在 HashMap 中就通过 TREEIFY_THRESHOLD=8 来控制链表的长度,当链表的长度大于 8 时并且数组长度大于 64 时,就将链表转换为红黑树
这里在冲突插入链表时,使用的是尾插法,会顺着链表进行判断,当遍历到链表最后一个节点时,并判断链表长度是否需要转为红黑树,之后再通过尾插法,插入在最后一个节点的后边
扩展:jdk8 之前是头插法,但是 jdk8 改为了尾插法,这是为什么呢?为什么 jdk8 之前要采用头插法呢?
jdk1.7 使用头插法的一种说法是,利用到了缓存的时间局部性,即最近访问过的数据,下次大概率还会进行访问,因此把刚刚访问的数据放在链表头,可以减少查询链表的次数
jdk1.7 中的头插法是存在问题的,在并发的情况下,插入元素导致扩容,在扩容时,会改变链表中元素原本的顺序,因此会导致
链表成环的问题那么 jdk8 之后改为了尾插法,保留了元素的插入顺序,在并发情况下就不会导致链表成环了,但是 HashMap 本来就不是线程安全的,如果需要保证线程安全,使用 ConcurrentHashMap 就好了!
如何计算插入节点在数组中需要存储的下标呢?
计算下标是先计算出 key 的 hash 值,在将 hash 值对数组长度进行取模,拿到在数组中存放的位置
计算 hash 值代码如下:
(h = key.hashCode()) ^ (h >>> 16)
首先拿到 key 的 hashCode,将 hashCode 和 h >>> 16 进行异或运算,此时计算出来 key 的哈希值 hash,这里计算 哈希值 时,因为在计算数组中的下标时,会让 hash 值对数组长度取模,一般数组长度不会太大,导致 hash 值的高 16 位参与不到运算,因此让 hashCode 在与 hashCode >>> 16 进行异或操作,让 hashCode 的高 16 位也可以参与到下标的计算中去,这样计算出的下标更不容易冲突
这里面试官问了 hashCode 一定是 32 位吗?当时没反应过来,其实一定是 32 位的,因为 hashCode 是 int 类型,这里说的 32 位其实是二进制中是 32 位,int 类型是 4B = 32bit
那么在数组中的下标为:hash & (n-1) 也就是让 hash 值对数组长度进行取模,从而拿到在数组中的下标。(这里 hash & (n-1) == hash % n,hash 值和 n-1 进行与操作其实就是使用二进制运算进行取模)
这里举个取模运算的例子:
比如数组长度为 8,计算出来的 hash 值为 19,那么
19 & (8 - 1) = 10011 & 00111(二进制) = 00011(二进制) = 3
19 % 8 = 3
HashMap 中如何进行扩容的呢?
当 HashMap 中的元素个数超过数组长度 * loadFactor(负载因子)时,就会进行数组扩容,负载因子默认为 0.75,数组大小默认为 16,因此默认是 HashMap 中的元素个数超过 (16 * 0.75 = 12) 时,就会将数组的大小扩展为原来的一倍,即 32,之后再重新计算数组的下标,这异步操作是比较耗费性能的,所以如果可以预知 HashMap 中元素的个数,可以提前设置容量,避免频繁的扩容
在 HashMap 扩容时,即在 resize() 方法中,如果数组中某个位置上的链表有多个元素,那么我们如果对整条链表上的元素都重新计算下标是非常耗时的操作,因此在 HashMap 中进行了优化,HashMap 每次扩容都是原来容量的 2 倍,那么一条链表上的数据在扩容之后,这一条链表上的数据要么在原来位置上,要么在原来位置+原来数组长度上,这样就不需要再对这一条链表上的元素重新计算下标了,下边来解释一下为什么这一条链表扩容后的位置只可能是这两种情况:
因为每一次扩容都是容量翻倍,在下标计算中 (n-1) & hash 值,n 每次扩容都会增大一倍,那么 (n-1) 在高位就会多一个 1,比如(可能写的有些啰嗦,主要是这一段用文字不太好描述,耐心看一下就可以看懂):
假如说我们插入一个
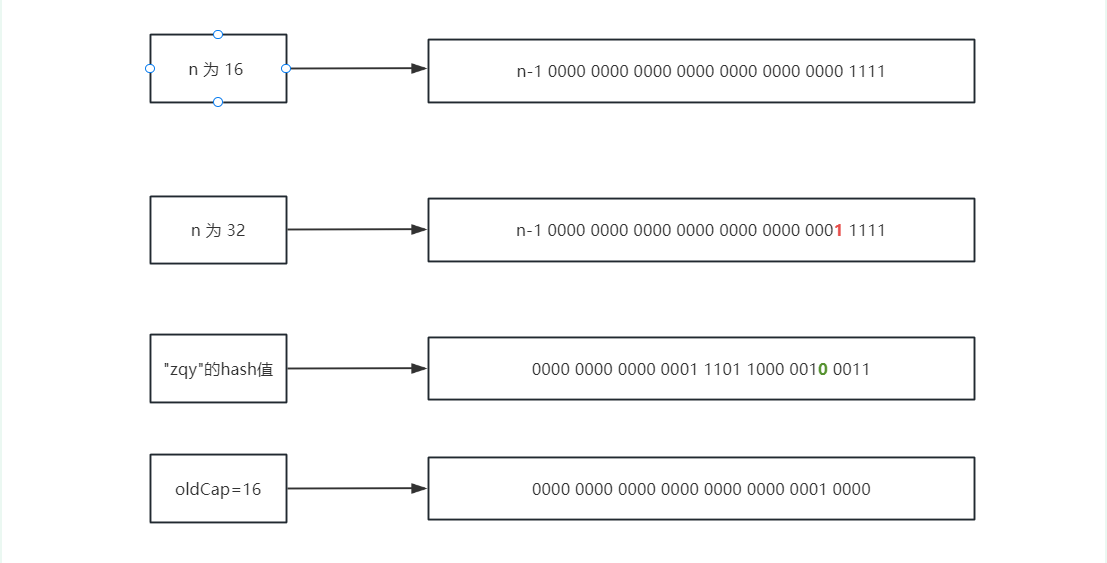
key="zqy"时,从 16 扩容为 32 ,我们来看一下扩容前后的如何计算下标:
- n 为 16 时,n-1 只有 4 个 1
- n 为 32 时,n-1 有 5 个 1,在高位多出来了一个 1
下标的计算公式为
(n-1)&hash,n 每次都是扩容1倍,也就是 n-1 的二进制中会在高位多一个 1,那么如果hash 值在多出来的 1 这一位上为 1,那么下标计算之后就比原下标多了一个 oldCap,如果hash 值在多出来的 1 这一位上为 0,那么就不会对下标计算有影响,新下标还是等于原下标那么怎么判断在多出来的这一个 1 的位置上,hash 值是否为 1 呢?只需要让
hash & oldCap即可,对上图来说,在扩容之后,当 n 为 32 时, n-1 中会多出来标位红色的1,那么需要判断的就是"zqy"的 hash 值中绿色的位置那一位是否为1(通过hash&oldCap来判断),如果为1,新下标=原下标+oldCap;如果为 0,新下标=原下标
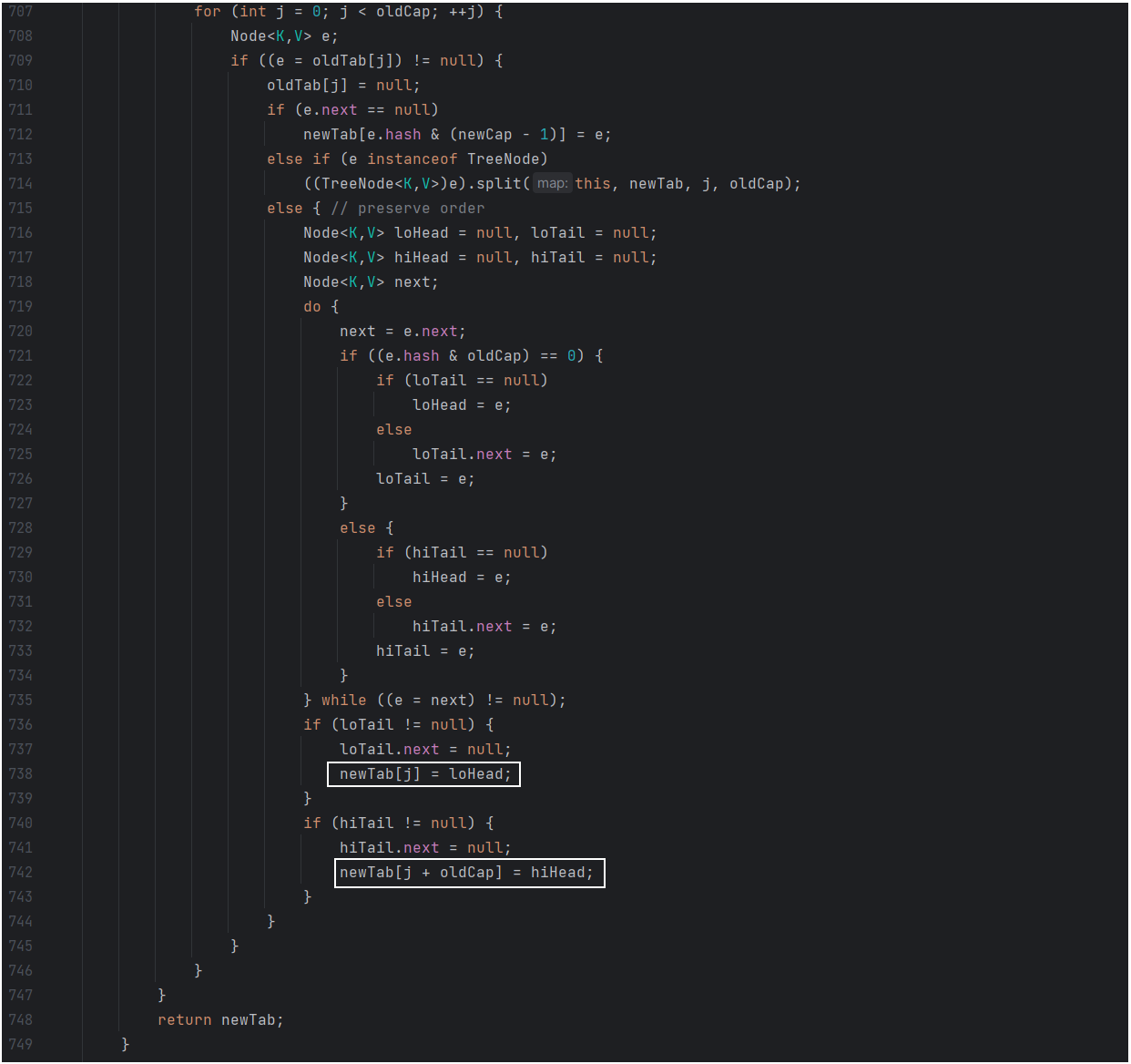
上边说的源码位置如下图,下边为 resize() 方法中的部分代码,优化位置在 738 和 742 行,在 715 行开始的 else 语句中,针对的就是原数组的位置上的链表有多个元素,在 721 行判断,如果 hash & oldCap 是 0 的话,表示该链表上的元素的新下标为原下标;如果是 1,表示新下标=原下标+原数组长度
HashMap 在链表长度达到 8 之后一定会转为红黑树吗?如何转为红黑树呢?
HashMap 会在数组长度大于 64 并且链表长度大于 8 才会将链表转为红黑树
在下边这个转成红黑树的方法中,757 行就判断了 tab.length 也就是数组的长度,如果小于 64,就进行扩容,不会将链表转成红黑树
如果需要转换成红黑树,就进入到 759 行的 if 判断,先将链表的第一个节点赋值为 e,之后将 e 转为 TreeNode,并且将转换后的树节点给串成一个新的链表,hd 为链表头,tl 为链表尾,当将链表所有节点转为 TreeNode 之后,在 771 行使用转换后的双向链表替代原来位置上的单链表,之后再 772 行调用 treeify() ,该方法就是将链表中的元素一个一个插入到树中

HashMap不是线程安全的,那么举一个不安全的例子吧?
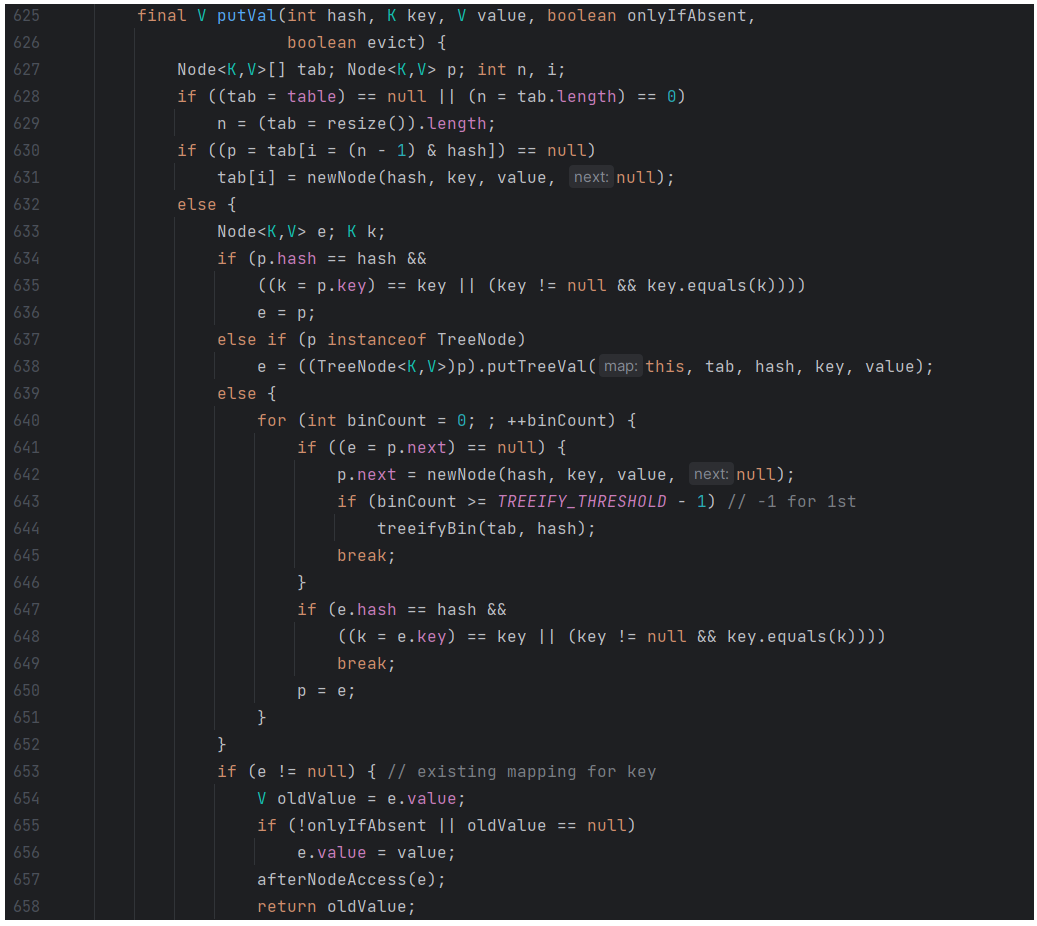
我们可以来分析一下,在多线程情况下,那么一般是多个线程修改同一个 HashMap 所导致的线程不安全,那么也就是 put() 操作中,会造成线程不安全了,那么我们看下边 putVal() 方法,来分析一下在哪里会造成线程不安全:
假如初始时,HashMap 为空,此时线程 A 进到 630 行的 if 判断,为 true,当线程 A 准备执行 631 行时,此时线程 B 进入在 630 行 if 判断发现也为 true,于是也进来了,在 631 行插入了节点,此时线程 B 执行完毕,线程 A 继续执行 631 行,就会出现线程 A 插入节点将线程 B 插入的节点覆盖的情况