目录
一、搭建环境:
1.1 下载软件上传到linux目录/data/soft下
1.2 把所有软件解压到/data/es-cluster
二、单节点(多节点同理)集群部署elasticsearch
2.1 创建es用户
2.2 准备节点通讯证书
2.3 配置elasticsearch,编辑/data/es-cluster/elasticsearch-7.9.0-node1/config/elasticsearch.yml文件
2.4 在每一台集群机器上修改linux读写配置
2.5 使用ik分词器
编辑2.6 启动es服务
2.7 es加密访问(只需要一个节点执行即可,es会把密码创建到.security索引下)
2.8 测试访问,请求xxx.xxx.xxx.xxx:9201/_cat/nodes,需要输入密码(elastic账号为超管),输入密码,显示节点信息说明成功。
三、安装kibana控制台
四、安装canal服务端(canal-deployer-1.1.5)(单机)
4.1 mysql开启binlog,并创建canal从节点账号
4.2 修改canal服务端(canal-deployer-1.1.5)配置
五、安装canal客户端(canal-adapter-1.1.5)
5.1 修改配置/conf/application .yml ,按如下配置即可,主要是修改canal-server配置、数据源配置和客户端适配器配置:
5.2 添加配置文件canal-adapter/conf/es7/canal_xxx_01_index.yml,用于配置MySQL中的表与Elasticsearch中索引的映射关系
5.3 客户端启动druid依赖冲突解决
5.4 启动
5.5 查看日志
六、 canal-admin安装(可以选择性安装)
6.1 创建canal-admin需要使用的数据库canal_manager,创建SQL脚本为/mydata/canal-admin/conf/canal_manager.sql,会创建如下表;
6.2 修改配置文件conf/application.yml,按如下配置即可,主要是修改数据源配置和canal-admin的管理账号配置,注意需要用一个有读写权限的数据库账号,比如管理账号root:root;
6.3 接下来对之前搭建的canal-server的conf/canal_local.properties文件进行配置,主要是修改canal-admin的配置,修改完成后使用sh bin/startup.sh local重启canal-server
七、 全量同步
7.1 方法一
7.2 全量同步方法二(推荐)
查询所有订阅同步的canal instance或MQ topic
数据同步开关状态
手动ETL
一、搭建环境:
jdk 8
mysql 8
centos 7.8
canal.adapter-1.1.5
canal.admin-1.1.5
canal.deployer-1.1.5
elasticsearch-7.9.0
kibana-7.9.0
elasticsearch-analysis-ik-7.9.0
1.1 下载软件上传到linux目录/data/soft下
1.2 把所有软件解压到/data/es-cluster
## tar.gz解压命令
tar -zxvf /data/soft/xxx.tar.gz -C /data/es-cluster
## unzip解压命令
unzip /data/soft/xxx.zip /data/es-cluster 解压后如下:(elasticsearch-7.9.0-node1跟elasticsearch-7.9.0-node2配置不一样,后边会说到,node2由node1解压后复制而来)
二、单节点(多节点同理)集群部署elasticsearch
2.1 创建es用户
因为安全问题,Elasticsearch 不允许 root 用户直接运行,所以要在每个节点中创建新用
户,在 root 用户中创建新用户:
useradd es-cluster #新增 es-cluster 用户
passwd es-cluster #为 es-cluster 用户设置密码
userdel -r es-cluster #如果错了,可以删除再加
chown -R es-cluster:es-cluster /data/es-cluster #文件夹所有者2.2 准备节点通讯证书
- 生成ca证书:
## 切换到/data/es-cluster/elasticsearch-7.9.0-node1/bin,执行下边的命令,生成的压缩包在/data/es-cluster/elasticsearch-7.9.0-node1下:
./elasticsearch-certutil ca --pem --out ca.zip --days 365000 -s
## 查看证书有效期:
openssl x509 -in ca.crt -noout -dates- 到/data/es-cluster/elasticsearch-7.9.0-node1下解压ca.zip:
unzip ca.zip- 使用解压出来的ca.key、ca.crt生成cert证书,并解压:
./elasticsearch-certutil cert --ca-cert ca/ca.crt --ca-key ca/ca.key --pem --name za-test --out za-test.zip --days 365000 -s
## 解压za-test.zip
unzip za-test.zip- 将证书拷贝到目录/data/es-cluster/elasticsearch-7.9.0-node1/config/certs,没有certs目录自己建一个:
cp ca/* za-test/* config/certs- 将/data/es-cluster/elasticsearch-7.9.0-node1/config/certs文件夹拷贝到集群所有机器
2.3 配置elasticsearch,编辑/data/es-cluster/elasticsearch-7.9.0-node1/config/elasticsearch.yml文件
#集群名称
cluster.name: cluster-es
#节点名称,每个节点的名称不能重复
node.name: node-1
#ip 地址,每个节点的地址不能重复(填localhost访问不了)
network.host: xxx.xxx.xxx.xxx
#是不是有资格主节点
node.master: true
node.data: true
http.port: 9201
transport.tcp.port: 9301
# head 插件需要这打开这两个配置
http.cors.allow-origin: "*"
http.cors.enabled: true
http.max_content_length: 200mb
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 master.(子节点不需要配置)
cluster.initial_master_nodes: ["node-1"]
#es7.x 之后新增的配置,节点发现(localhost节点没法找到主节点,无法加入集群),因为我是单节点,所以ip是一样的,端口不一样。如果是多节点,端口可以都是9301.
discovery.seed_hosts: ["xxx.xxx.xxx.xxx:9301","xxx.xxx.xxx.xxx:9302"]
gateway.recover_after_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
#集群内同时启动的数据任务个数,默认是 2 个
cluster.routing.allocation.cluster_concurrent_rebalance: 16
#添加或删除节点及负载均衡时并发恢复的线程个数,默认 4 个
cluster.routing.allocation.node_concurrent_recoveries: 16
#初始化数据恢复时,并发恢复线程的个数,默认 4 个
cluster.routing.allocation.node_initial_primaries_recoveries: 16
#索引自動創建。这里限制需不需要自动创建索引。因为我自己的索引都是canal开头,所以我使用-canal*,不让es自己创建索引。根据自己的实际来配置。除了-canal*根据自己的实际配置,其他都是必须的。
action.auto_create_index: +first*,-canal_*,+.watches*,+.triggered_watches,+.watcher-history-*,+.kibana*,+.ilm*,+.tasks*,+.apm*
#配置密碼
xpack.security.enabled: true
#xpack.license.self_generated.type: basic
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.key: certs/za-test.key
xpack.security.transport.ssl.certificate: certs/za-test.crt
xpack.security.transport.ssl.certificate_authorities: certs/ca.crt编辑/data/es-cluster/elasticsearch-7.9.0-node2/config/elasticsearch.yml文件:
#集群名称
cluster.name: cluster-es
#节点名称,每个节点的名称不能重复
node.name: node-1
#ip 地址,每个节点的地址不能重复(填localhost访问不了)
network.host: xxx.xxx.xxx.xxx
#是不是有资格主节点
node.master: true
node.data: true
## 如果是多节点集群,端口可以不用修改默认9201即可
http.port: 9202
## 如果是多节点集群,端口可以不用修改默认9301即可
transport.tcp.port: 9302
# head 插件需要这打开这两个配置
http.cors.allow-origin: "*"
http.cors.enabled: true
http.max_content_length: 200mb
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 master.(子节点不需要配置)
#cluster.initial_master_nodes: ["node-1"]
#es7.x 之后新增的配置,节点发现(localhost节点没法找到主节点,无法加入集群),因为我是单节点,所以ip是一样的,端口不一样。如果是多节点,端口可以都是9301.
discovery.seed_hosts: ["xxx.xxx.xxx.xxx:9301","xxx.xxx.xxx.xxx:9302"]
gateway.recover_after_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
#集群内同时启动的数据任务个数,默认是 2 个
cluster.routing.allocation.cluster_concurrent_rebalance: 16
#添加或删除节点及负载均衡时并发恢复的线程个数,默认 4 个
cluster.routing.allocation.node_concurrent_recoveries: 16
#初始化数据恢复时,并发恢复线程的个数,默认 4 个
cluster.routing.allocation.node_initial_primaries_recoveries: 16
#索引自動創建,这里限制需不需要自动创建索引。因为我自己的索引都是canal开头,所以我使用-canal*,不让es自己创建索引。除了-canal*根据自己的实际配置,其他都是必须的。
action.auto_create_index: +first*,-canal_*,+.watches*,+.triggered_watches,+.watcher-history-*,+.kibana*,+.ilm*,+.tasks*,+.apm*
#配置密碼
xpack.security.enabled: true
#xpack.license.self_generated.type: basic
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.key: certs/za-test.key
xpack.security.transport.ssl.certificate: certs/za-test.crt
xpack.security.transport.ssl.certificate_authorities: certs/ca.crt2.4 在每一台集群机器上修改linux读写配置
- 修改/etc/security/limits.conf
# 注:* 带表 Linux 所有用户名称
* soft nofile 65535
* hard nofile 65535
或者(指定用户)
es-cluster soft nofile 65535
es-cluster hard nofile 65535- 修改/etc/security/limits.d/20-nproc.conf
es-cluster soft nofile 65536
es-cluster hard nofile 65536
* hard nproc 4096- 修改/etc/sysctl.conf
# 在文件中增加下面内容
vm.max_map_count=655360- 重新加载配置
sysctl -p 2.5 使用ik分词器
解压/data/soft/elasticsearch-analysis-ik-7.9.0.zip到每一台集群机器/data/es-cluster/elasticsearch-7.9.0-nodexx/plugins下。
如果某些内容需要自定义分词效果,可以进行以下操作:
进入 es plugins 文件夹下的 ik 文件夹,进入 config 目录,创建 custom.dic文件,比如我要`弗雷尔卓德`不分词,就把`弗雷尔卓德`写到custom.dic里边,使用回车换行,区分。同时打开 IKAnalyzer.cfg.xml 文件,将新建的 custom.dic 配置其中:

2.6 启动es服务
首次启动es,先给文件赋值权限,使用root账户执行:
chown -R es-cluster:es-cluster /data/es-cluster #文件夹所有者切换es-cluster用户:
su es-cluster执行命令依次启动每个集群es:
#启动
bin/elasticsearch
#后台启动
bin/elasticsearch -d注意:首次启动,因为没有log文件,报错,暂停,切换root执行chown -R es-cluster:es-cluster /data/soft/es-cluster,再切换回es用户启动即可。
2.7 es加密访问(只需要一个节点执行即可,es会把密码创建到.security索引下)
切换到es bin目录执行命令,并输入密码即可:
./elasticsearch-setup-passwords interactive需要配置密码的内置用户有:
## es内置用户
Changed password for user [apm_system]
Changed password for user [kibana_system]
Changed password for user [kibana]
Changed password for user [logstash_system]
Changed password for user [beats_system]
Changed password for user [remote_monitoring_user]
Changed password for user [elastic]
2.8 测试访问,请求xxx.xxx.xxx.xxx:9201/_cat/nodes,需要输入密码(elastic账号为超管),输入密码,显示节点信息说明成功。
三、安装kibana控制台
- 修改解压出来的kibana文件 /data/es-cluster/kibana-7.9.0/config/kibana.yml文件:
# 默认端口
server.port: 5601
#允许远程访问的地址配置,默认为本机,如果需要把 Kibana 服务给远程主机访问,只需要在这个配置中填写远程的那台
#主机的 ip 地址,那如果希望所有的远程主机都能访问,那就填写 0.0.0.0
server.host: "0.0.0.0"# ES 服务器的地址
elasticsearch.hosts: ["http://xxx.xxx.xx1:9201","http://xxx.xxx.xx2:9201"]
# 索引名
kibana.index: ".kibana"
# 支持中文
i18n.locale: "zh-CN"## 配置es与kibana通讯账密
# 该参数意思为任意长度为32以上的字符串
elasticsearch.username: "kibana_system"
## 上边es设置的kibana_system的密码
elasticsearch.password: "xxxx"# must be a positive integer.
elasticsearch.requestTimeout: 50000
# Time in milliseconds for Elasticsearch to wait for responses from shards. Set to 0 to disable.
elasticsearch.shardTimeout: 30000
# Time in milliseconds to wait for Elasticsearch at Kibana startup before retrying.
elasticsearch.startupTimeout: 5000## 日志输出
# Enables you to specify a file where Kibana stores log output.
logging.dest: ./kibana.log
# Set the value of this setting to true to suppress all logging output.
logging.silent: false
# Set the value of this setting to true to suppress all logging output other than error messages.
logging.quiet: false
# Set the value of this setting to true to log all events, including system usage information
# and all requests.
logging.verbose: false
- 启动kibana:
## kibana启动:
./bin/kibana &
## kibana指定配置文件启动:
nohup /bin/kibana -c /config/kibana.yml > /dev/null 2>&1 &访问xxx.xxx.xxx.xxx:5601输入账号密码即可访问。
四、安装canal服务端(canal-deployer-1.1.5)(单机)
4.1 mysql开启binlog,并创建canal从节点账号
-
mysql需要开启binlog,以及设置日志格式
[mysqld]
## 设置server_id,同一局域网中需要唯一
server_id=101
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能
log-bin=mall-mysql-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=row
## 二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=30
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
- 配置完成后需要重新启动MySQL,重启成功后通过如下命令查看binlog是否启用.
show variables like '%log_bin%';
show variables like 'binlog_format%'; - 创建从库账号(后边需要使用)
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;4.2 修改canal服务端(canal-deployer-1.1.5)配置
- 修改配置/conf/canal.properties,除了ip和port外,其他配置可不改动。
#canal的server地址:127.0.0.1
canal.ip = xxx.xxx.xxx.aaa
#canal端口,用于客户端监听
canal.port = 11111- 修改配置/conf/example/instance.properties
#被同步的mysql地址
canal.instance.master.address=xxx.xxx.xxx.bbb:3306
#数据库从库权限账号(需要提前准备)
canal.instance.dbUsername=canal
#数据库从库权限账号的密码
canal.instance.dbPassword=canal
#数据库连接编码
canal.instance.connectionCharset = UTF-8
#需要订阅binlog的表过滤正则表达式
#canal.instance.filter.regex=.*\\..* # 訂閲所有库所有表
# 配置需要同步的表,xxx_db表示数据库名,xxx_01等表示具体的表
canal.instance.filter.regex=xxx_db.xxx_01,xxx_db.xxx_02,xxx_db.xxx_03不配置这几个,canal会使用`show master status`命令获取最新的提交位置(如果想读取binlog历史,可以通过show binary logs获取到你需要同步的起始文件,并查看起始位置的position已经timestamp。除了这样读取历史,还可以执行canal提供的etl同步表历史数据,这个在下边有说):
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=
- 启动: bin目录下 ./startup.sh
- 查看日志:/logs/canal/canal.log
- 查看实例日志/logs/example/example.log(example可以是默认的,可以自己改名)
- 可能的问题: caching_sha2_password Auth failed
原因: 使用mysql版本为8.0,而创建用户时默认的密码加密方式为caching_sha2_password,所以修改为 mysql_native_password
ALTER USER 'canal'@'%' IDENTIFIED WITH mysql_native_password BY '密码'; #更新一下用户密码
FLUSH PRIVILEGES; #刷新权限五、安装canal客户端(canal-adapter-1.1.5)
5.1 修改配置/conf/application .yml ,按如下配置即可,主要是修改canal-server配置、数据源配置和客户端适配器配置:
server:port: 9401
spring:jackson:date-format: yyyy-MM-dd HH:mm:sstime-zone: GMT+8default-property-inclusion: non_null
canal.conf:mode: tcp # 客户端的模式,可选tcp kafka rocketMQ
# flatMessage: true # 扁平message开关, 是否以json字符串形式投递数据, 仅在kafka/rocketMQ模式下有效
# zookeeperHosts: # 对应集群模式下的zk地址syncBatchSize: 1000 # 每次同步的批数量retries: 0 # 重试次数, -1为无限重试timeout: 120000 # 同步超时时间, 单位毫秒accessKey:secretKey:consumerProperties:# canal tcp consumercanal.tcp.server.host: xxx.xxx.xxx.aaa:11111 #设置canal-server的地址canal.tcp.zookeeper.hosts:canal.tcp.batch.size: 500canal.tcp.username:canal.tcp.password:srcDataSources: # 源数据库配置defaultDS:url: jdbc:mysql://xxx.xxx.xxx.bbb:3306/xxx_db?useUnicode=trueusername: canalpassword: canalmaxActive: 10 #额外增加这一行,默认的连接数只有3,会导致全量同步出现异常,导致全量同步数据缺失,最好改大一点canalAdapters: # 适配器列表- instance: example # canal实例名或者MQ topic名groups: # 分组列表- groupId: g1 # 分组id, 如果是MQ模式将用到该值outerAdapters:- name: logger # 日志打印适配器# 配置目标数据源#key: esKey- name: es7 # ES同步适配器key: eskeyhosts: http://xxx.xxx.xxx.xxx1:9201,http://xxx.xxx.xxx.xxx2:9202 # ES连接地址,逗号分隔。properties:mode: rest # 模式可选transport(9300) 或者 rest(9200)security.auth: elastic:xxxxxx # only used for rest modecluster.name: cluster-es # ES集群名称5.2 添加配置文件canal-adapter/conf/es7/canal_xxx_01_index.yml,用于配置MySQL中的表与Elasticsearch中索引的映射关系
注意:如果这里写了映射关系,但是索引里的mapping没有写,数据无法同步
dataSourceKey: defaultDS # 源数据源的key, 对应上面配置的srcDataSources中的值
outerAdapterKey: eskey # 与上述application.yml中配置的outerAdapters.key一致
destination: example # 默认为example,与application.yml中配置的instance保持一致
groupId: g1 # 对应MQ模式下的groupId, 只会同步对应groupId的数据
esMapping:_index: canal_xxx_01_index # es 的索引名称_type: _doc_id: id # es 的_id, 如果不配置该项必须配置下面的pk项_id则会由es自动分配sql: "SELECTp.id AS id,p.title,p.sub_title,p.price,p.picFROMxxx_01 p" # sql映射etlCondition: "where a.c_time>={}" #etl的条件参数commitBatch: 3000 # 提交批大小5.3 客户端启动druid依赖冲突解决
1、https://github.com/alibaba/canal/tree/canal-1.1.5
到github下载源码。解压修改client-adapter/escore/pom.xml:
<dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><!--add by whx 20220112--><scope>provided</scope></dependency>2、编译,将client-adapter/es7x/target/client-adapter.es7x-1.1.5-jar-with-dependencies.jar上传到服务器,替换adataper/plugin下的同名jar文件。
3、给文件赋值权限:chmod 777 /data/es-cluster/canal-adapter-1.1.5/plugin/client-adapter.es7x-1.1.5-jar-with-dependencies.jar
4、重启客户端。5.4 启动
sh bin/startup.sh5.5 查看日志
tail -f logs/adapter/adapter.log六、 canal-admin安装(可以选择性安装)
6.1 创建canal-admin需要使用的数据库canal_manager,创建SQL脚本为/mydata/canal-admin/conf/canal_manager.sql,会创建如下表;

6.2 修改配置文件conf/application.yml,按如下配置即可,主要是修改数据源配置和canal-admin的管理账号配置,注意需要用一个有读写权限的数据库账号,比如管理账号root:root;
server:port: 9402
spring:jackson:date-format: yyyy-MM-dd HH:mm:sstime-zone: GMT+8spring.datasource:address: 127.0.0.1:3306database: canal_managerusername: rootpassword: rootdriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=falsehikari:maximum-pool-size: 30minimum-idle: 1canal:adminUser: adminadminPasswd: admin6.3 接下来对之前搭建的canal-server的conf/canal_local.properties文件进行配置,主要是修改canal-admin的配置,修改完成后使用sh bin/startup.sh local重启canal-server
# register ip
canal.register.ip =# canal admin config
canal.admin.manager = 127.0.0.1:9401
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = admin
# admin auto register
canal.admin.register.auto = true
canal.admin.register.cluster = 七、 全量同步
7.1 方法一
查看mysql中的binlog文件
show binary logs;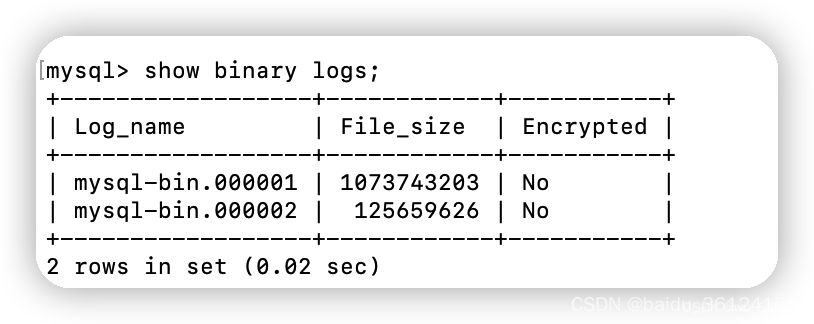 在conf/example/instance.properties中修改
在conf/example/instance.properties中修改
# 全量同步
# 第一个binlog文件
canal.instance.master.journal.name=mysql-bin.000001
canal.instance.master.position=0
#2019-01-01 00:00:00 上一次更新的时间 时间戳形式
canal.instance.master.timestamp=1546272000000如果之前同步过,想要重新做全量同步,那么需要删除conf/example/meta.dat文件,这个文件会记录上次同步的时间和binlog位置
rm -rf ./conf/example/meta.dat7.2 全量同步方法二(推荐)
查询所有订阅同步的canal instance或MQ topic
## 访问canal-adapter,elastic 是es管理员账号,回车,输入密码即可看到:
curl -u elastic http://xxx.xxx.xxx.xxx:9401/destinations数据同步开关状态
curl -u elastic http://xxx.xxx.xxx.xxx:9401/syncSwitch/example手动ETL
## 开始请求接口同步,es7为adapter实例配置的name,eskey为adapter配置的key,canal_xxx_01_index.yml为es7文件下,需要同步的文件。回车输入elastic 的密码等待同步即可:
curl -u elastic http://10.252.194.1:9401/etl/es7/eskey/canal_xxx_01_index.yml -X POST不删除索引,直接删除索引下的所有数据:
## 打开kibana控制台,输入这个查询
POST -u username xxx.xxx.xxx.xxx:9201/索引名/_delete_by_query请求体:
{"query": {"match_all": {}}
}注释:
其中 my_index是索引名称