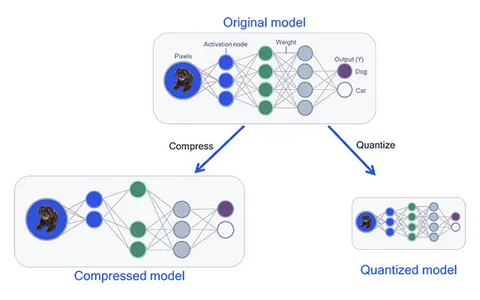
在不断发展的人工智能领域,生成式AI无疑已成为创新的基石。 这些先进的模型,无论是用于创作艺术、生成文本还是增强医学成像,都以产生非常逼真和创造性的输出而闻名。 然而,生成式AI的力量是有代价的—模型大小和计算要求。 随着生成式AI模型的复杂性和规模不断增长,它们需要更多的计算资源和存储空间。 这可能是一个重大障碍,特别是在边缘设备或资源受限的环境上部署这些模型时。 这就是具有模型量化功能的生成式 AI 发挥作用的地方,它提供了一种在不牺牲质量的情况下缩小这些庞大模型的方法。
在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器
1、模型量化简介
简而言之,模型量化(Model Quantization)会降低模型参数数值的精度。 在深度学习模型中,神经网络通常采用高精度浮点值(例如 32 位或 64 位)来表示权重和激活。 模型量化将这些值转换为较低精度的表示形式(例如 8 位整数),同时保留模型的功能。
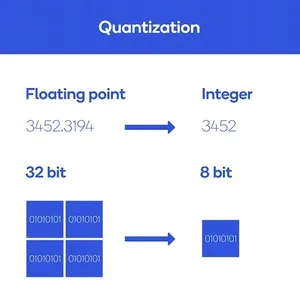
模型量化在生成式AI中的好处包括:
- 减少内存占用:模型量化最明显的好处是内存使用量的显着减少。 较小的模型尺寸使得在边缘设备、移动应用程序和内存容量有限的环境中部署生成式AI变得可行。
- 更快的推理:由于数据大小减少,量化模型运行速度更快。 这种速度的提高对于视频处理、自然语言理解或自动驾驶汽车等实时应用至关重要。
- 能源效率:缩小模型大小有助于提高能源效率,使得在电池供电设备或在能源消耗令人担忧的环境中运行生成式AI模型变得可行。
- 降低成本:较小的模型占用空间会降低存储和带宽要求,从而为开发人员和最终用户节省成本。
尽管有其优势,生成式AI中的模型量化也面临着一些挑战:
- 量化感知训练:准备量化模型通常需要重新训练。 量化感知训练旨在最大限度地减少量化过程中模型质量的损失。
- 最佳精度选择:选择正确的量化精度至关重要。 精度太低可能会导致显着的质量损失,而精度太高可能无法充分减小模型大小。
- 微调和校准:量化后,模型可能需要微调和校准以保持其性能并确保它们在新的精度约束下有效运行。
一些生成式AI模型量化的应用示例如下:
- 设备上的艺术生成:通过量化缩小生成式 AI 模型,艺术家可以创建设备上的艺术生成工具,使它们更易于访问和便携地进行创意工作。
- 边缘设备上的医疗保健成像:可以部署量化模型以进行实时医学图像增强,从而实现更快、更高效的诊断。
- 移动终端文本生成:移动应用程序可以提供文本生成服务,减少延迟和资源使用,从而增强用户体验。
2、生成式AI模型量化的代码优化
将模型量化纳入生成式 AI 可以通过 TensorFlow 和 PyTorch 等流行的深度学习框架来实现。 TensorFlow Lite 的量化感知训练(quantization-aware training)和 PyTorch 的动态量化(dynamic quantization)等工具和技术提供了在项目中实现量化的简单方法。
2.1 TensorFlow Lite 量化
TensorFlow 提供了用于模型量化的工具包,特别适合设备上部署。 以下代码片段演示了使用 TensorFlow Lite 量化 TensorFlow 模型:
import tensorflow as tf# Load your saved model
converter = tf.lite.TFLiteConverter.from_saved_model("your_model_directory")
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
open("quantized_model.tflite", "wb").write(tflite_model)在此代码中,我们首先导入 TensorFlow 库, `tf.lite.TFLiteConverter `用于从模型目录加载保存的模型,将优化设置为 tf.lite.Optimize.DEFAULT 以启用默认量化,最后,我们转换模型并将其保存为量化的 TensorFlow Lite 模型。
2.2 PyTorch 动态量化
PyTorch 提供动态量化,允许你在推理过程中量化模型。 下面是 PyTorch 动态量化的代码片段:
import torch
from torch.quantization import quantize_dynamic
model = YourPyTorchModel()
model.qconfig = torch.quantization.get_default_qconfig('fbgemm')
quantized_model = quantize_dynamic(model, qconfig_spec={torch.nn.Linear}, dtype=torch.qint8)在此代码中,我们首先导入必要的库,然后通过 YourPyTorchModel()创建PyTorch 模型,将量化配置 (qconfig) 设置为适合模型的默认配置,最后使用 quantize_dynamic 来量化模型,得到量化模型 quantized_model。
3、比较数据:量化模型 vs. 非量化模型
内存占用:
- 非量化:3.2 GB 内存。
- 量化:模型大小减少 65%,内存使用量为 1.1 GB。 内存消耗减少了 66%。
推理速度和效率:
- 非量化:每次推理 38 毫秒,消耗 3.5 焦耳。
- 量化:每次推理速度加快 22 毫秒(提高 42%),能耗降低 2.2 焦耳(节能 37%)。
输出质量:
- 非量化:视觉质量(1-10 分值为 8.7)、文本连贯性(1-10 分值为 9.2)。
- 量化:视觉质量略有下降(7.9,下降 9%),同时保持文本连贯性(9.1,下降 1%)。
推理速度与模型质量:
- 非量化:25 FPS,质量得分 (Q1) 为 8.7。
- 量化:以 38 FPS 进行更快的推理(提高 52%),质量得分(第二季度)为 7.9(降低 9%)。
比较数据强调了量化的资源效率优势以及现实应用中输出质量的权衡。
4、生成式AI模型量化的最佳实践
虽然模型量化为在资源有限的环境中部署生成式 AI 模型提供了多种好处,但遵循最佳实践以确保量化工作取得成功至关重要。 以下是一些关键建议:
- 量化感知训练:从量化感知训练开始,这是一个微调模型以降低精度的过程。 这有助于最大限度地减少量化期间模型质量的损失。 在精度降低和模型性能之间保持平衡至关重要。
- 精度选择:仔细选择正确的量化精度。 评估模型尺寸减小和潜在质量损失之间的权衡。 你可能需要尝试不同的精度级别才能找到最佳折衷方案。
- 校准:量化后,进行校准,以确保量化模型在新的精度约束下有效运行。 校准有助于调整模型的行为以与所需的输出保持一致。
- 测试和验证:彻底测试和验证你的量化模型。 这包括评估其在现实世界数据上的性能、测量推理速度以及将生成的输出的质量与原始模型进行比较。
- 监控和微调:持续监控量化模型在生产中的性能。 如有必要,可以对模型进行微调,以随着时间的推移保持或提高其质量。 这个迭代过程确保量化模型保持有效。
- 文档和版本控制:记录量化过程并保留模型版本、校准数据和性能指标的详细记录。 该文档有助于跟踪量化模型的演变,并在出现问题时简化调试。
- 优化推理管道:关注整个推理管道,而不仅仅是模型本身。 优化输入预处理、后处理和其他组件,以最大限度地提高整个系统的效率。
5、结束语
在生成式AI领域,模型量化是应对模型大小、内存消耗和计算需求挑战的强大解决方案。 通过降低数值精度,同时保持模型质量,量化使生成式 AI 模型能够将其覆盖范围扩展到资源受限的环境。 随着研究人员和开发人员不断微调量化过程,我们预计生成式AI将部署在从移动设备到边缘计算等更加多样化和创新的应用程序中。 在此过程中,关键是在模型大小和模型质量之间找到适当的平衡,释放生成式AI的真正潜力。
原文链接:生成式AI模型量化 - BimAnt









![[开源]基于 AI 大语言模型 API 实现的 AI 助手全套开源解决方案](https://img-blog.csdnimg.cn/img_convert/76188c5e190503861b883f61284b150c.png)