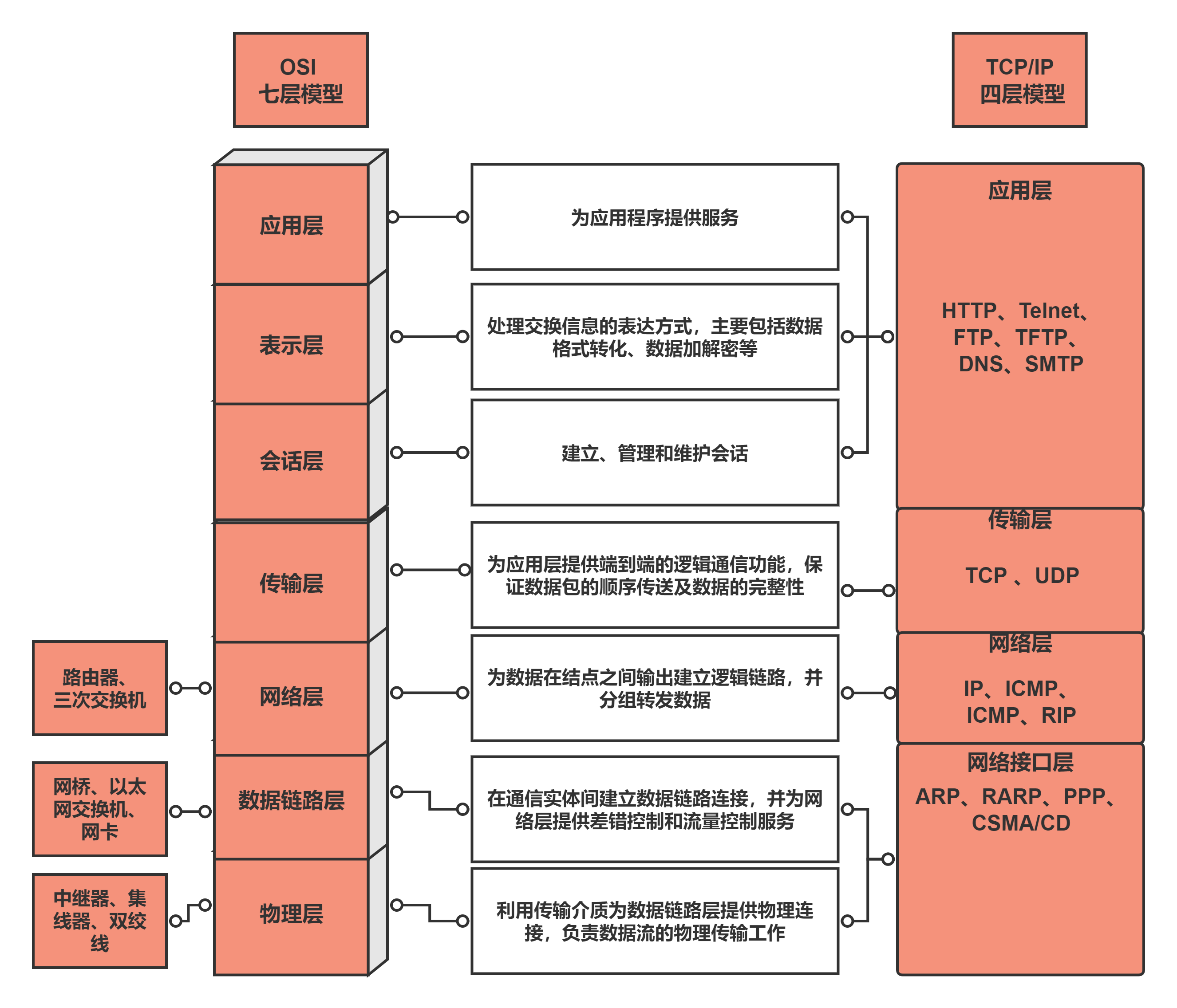
数据库的三范式(Normalization)是关系数据库设计中的基本理论原则,旨在减少数据冗余和提高数据库的数据组织结构。三范式通过将数据分解为更小的表,并通过关系建立连接,使得数据库设计更加灵活、规范和容易维护。在这篇文章中,我们将详细讲解数据库的三范式及其重要性。
第一范式(1NF)
第一范式要求数据库中的每个表必须是原子性的,即表中的每一列都包含不可再分的原子数据,而不是包含多个值或数组。
例如,考虑以下不符合第一范式的表
| StudentID | Courses |
|---|---|
| 1 | Math, English, Physics |
| 2 | Chemistry, Biology |
在这个例子中,Courses 列包含多个课程,违反了原子性的要求。符合第一范式的表应该是:
| StudentID | Course |
|---|---|
| 1 | Math |
| 1 | English |
| 1 | Physics |
| 2 | Chemistry |
| 2 | Biology |
第二范式(2NF)
第二范式要求数据库表中的每列都必须完全依赖于表中的主键,而不是依赖于部分主键。
考虑以下表
| OrderID | Product | Price |
|---|---|---|
| 1 | Laptop | $800 |
| 1 | Printer | $150 |
| 2 | Laptop | $850 |
在这个例子中,Price 列依赖于部分主键 OrderID,因为相同的产品在不同的订单中价格可能不同。为了符合第二范式,我们可以将表拆分为两个表:
| OrderID | Product |
|---|---|
| 1 | Laptop |
| 1 | Printer |
| 2 | Laptop |
| Product | Price |
| ----------- | -------- |
| Laptop | $800 |
| Printer | $150 |
| Laptop | $850 |
第三范式(3NF)
第三范式要求数据库表中的每一列都直接依赖于主键,而不是依赖于其他非主键列。
考虑以下表
| StudentID | Course | Professor | ProfessorEmail |
|---|---|---|---|
| 1 | Math | Dr. Smith | smith@example.com |
| 1 | English | Dr. Johnson | johnson@example.com |
| 2 | Chemistry | Dr. White | white@example.com |
在这个例子中,ProfessorEmail 列依赖于 Professor 列,而不是直接依赖于主键 StudentID 和 Course。为了符合第三范式,我们可以将表拆分为两个表:
| StudentID | Course | Professor |
|---|---|---|
| 1 | Math | Dr. Smith |
| 1 | English | Dr. Johnson |
| 2 | Chemistry | Dr. White |
| Professor | ProfessorEmail |
|---|---|
| Dr. Smith | smith@example.com |
| Dr. Johnson | johnson@example.com |
| Dr. White | white@example.com |
通过这样的拆分,我们确保了每一列都直接依赖于主键,避免了数据冗余和更新异常。
三范式的重要性
数据一致性: 三范式的应用有助于维护数据库中的数据一致性。通过减少冗余和依赖关系,确保了数据的准确性和更新的一致性。
减少数据冗余: 消除冗余数据是三范式的一个主要目标。冗余数据不仅占用存储空间,还容易导致数据不一致。
提高查询性能: 数据库的三范式设计有助于提高查询性能。由于数据存储在更小的表中,查询通常更加迅速和高效。
简化数据维护: 三范式设计使得数据维护更加简单。由于数据分解到更小的表中,对数据的修改更加容易,减少了更新异常的发生。
增加灵活性: 三范式设计使得数据库更加灵活。新的数据关系可以通过简单的建立外键来实现,而无需修改原有表的结构。
总体而言,数据库的三范式是关系数据库设计的基石,它通过规范化数据结构,提高了数据库的灵活性、一致性和性能。在设计数据库时,合理应用三范式原则有助于建立高效、可维护的数据库系统。