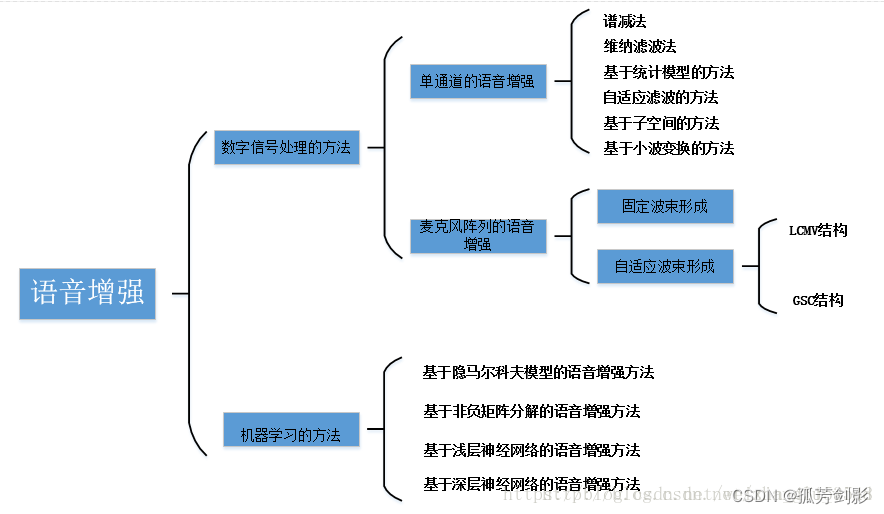
- ControlNet: TL;DR
- Control Type
- StableDiffusionControlNetPipeline
- 1. Canny ControlNet
- 1.1 模型与数据加载
- 1.2 模型推理
- 1.3 DreamBooth微调
- 2. Pose ControlNet
- 2.1 数据和模型加载
- 2.2 模型推理
ControlNet: TL;DR
ControlNet 是在 Lvmin Zhang 和 Maneesh Agrawala 的 Adding Conditional Control to Text-to-Image Diffusion Models 中引入的。 它引入了一个框架,允许支持各种空间环境,这些环境可以作为Diffusion模型(如 Stable Diffusion)的Additional conditionings。
训练 ControlNet 由以下步骤组成:(每一种新的condition都需要重新训练一个新的 ControlNet 权重副本)
-
复制 Diffusion 模型的预训练参数,例如 Stable Diffusion 的Latent UNet(称为“
trainable copy”),同时单独维护原始的预训练参数(“locked copy”): locked 的参数副本可以保留从大型数据集中学到的大量先验知识,而 trainable 参数副本则用于学习特定于任务的方面。 -
参数的 trainable 和 locked 副本通过“
zero convolution”层连接,这些层作为 ControlNet 框架的一部分进行了优化,从0 逐步增长参数值,确保开始时没有随机的噪音会干扰finetuning。这是一种训练技巧,用于在训练新condition时保留冻结模型已经学习的语义。
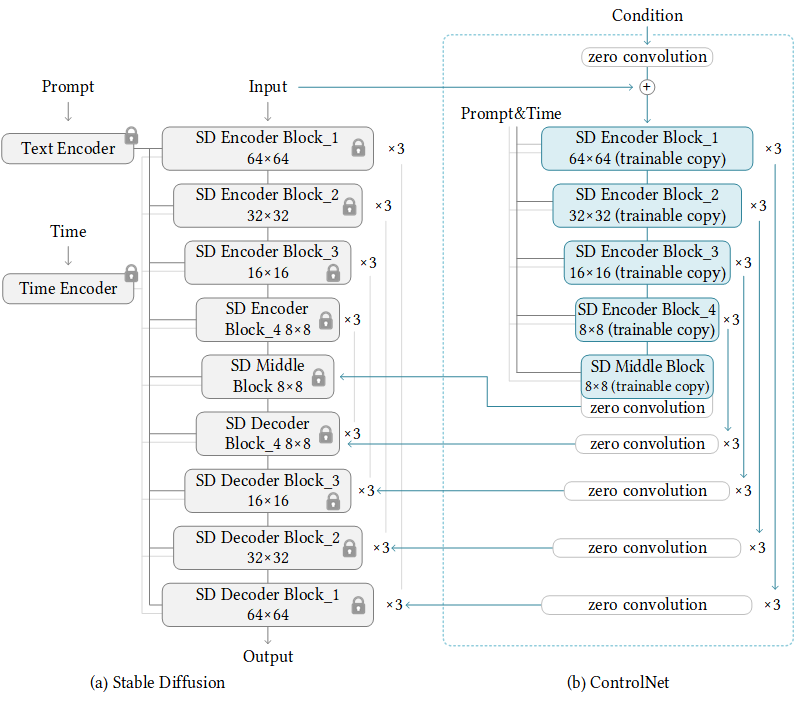
推理时,需要Pre-trained的扩散模型权重和Finetune过的 ControlNet 权重。与仅使用原始 Stable Diffusion 模型相比,将 Stable Diffusion v1-5 与 ControlNet 检查点一起使用需要大约 7 亿个参数,这使得 ControlNet 在推理时需要的内存成本更高。在使用不同的condition时,只需切换 ControlNet 参数。这使得在一个应用程序中部署多个 ControlNet 权重变得相当简单。
Control Type
8种:Canny、Depth、Openpose、Normal、Seg、Scribble、Mlsd、Hed
-
边缘线Canny:
controlnet='lllyasviel/sd-controlnet-canny',黑色背景上有白边的单色图像。

-
深度图Depth:
lllyasviel/sd-controlnet-depth,灰度图像,黑色表示深部区域,白色表示浅层区域。
-
骨骼图像Opse:
controlnet='fusing/stable-diffusion-v1-5-controlnet-openpose'或lllyasviel/sd-controlnet-openpose
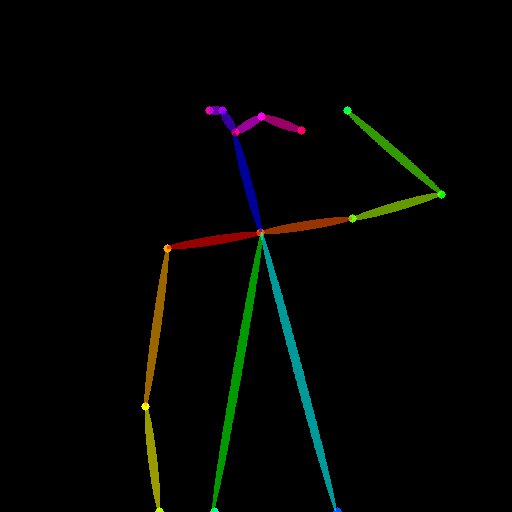
-
软边缘线HED:
lllyasviel/sd-controlnet-hed,在黑色背景上具有白色柔和边缘的单色图像。

- 法线贴图Normal Map:
lllyasviel/sd-controlnet-normal

- M-LSD 线:
lllyasviel/sd-controlnet-mlsd,仅由黑色背景上的白色直线组成的单色图像。

- 语义分割seg:
lllyasviel/sd-controlnet-seg

- 人类涂鸦scribble:
lllyasviel/sd-controlnet-scribble

StableDiffusionControlNetPipeline
StableDiffusionControlNetPipeline像其他 diffuser pipeline 一样,可以从huggingface加载预训练权重。
在命令行安装必要的库:
# diffusers依赖
pip install -q diffusers==0.14.0 transformers xformers git+https://github.com/huggingface/accelerate.git
# 处理不同condition的依赖
pip install -q opencv-contrib-python
pip install -q controlnet_aux
1. Canny ControlNet
1.1 模型与数据加载
加载图像
from diffusers import StableDiffusionControlNetPipeline
from diffusers.utils import load_imageimage = load_image("https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
)
image

调用cv2的Canny算法提取edge图像作为condition
import cv2
from PIL import Image
import numpy as npimage = np.array(image)low_threshold = 100
high_threshold = 200image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
canny_image

用torch.dtype=torch.float16半精度(half-precision)加载SD(runwaylml/stable-diffusion-v1-5)和ControlNet-Cnney(lllyasviel/sd-controlnet-canny),实现更快的 Inference。controlnet='lllyasviel/sd-controlnet-canny'
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
import torch# 分布加载StableDiffusion和ControlNet 组成 StableDiffusionControlNetPipeline
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)
使用当前最快的Noise Scheduler UniPCMultistepScheduler,减少Inference steps from 50 to 20
from diffusers import UniPCMultistepSchedulerpipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
使用pipe的enable_model_cpu_offload函数实现GPU的自动加载管理,无需手动to("cuda"):因为在推理过程中,模型(如SD)需要多个按顺序运行的模型组件。 在使用 ControlNet 进行 Stable Diffusion 的情况下,我们首先使用 CLIP 文本编码器,然后是 unet 和 controlnet,然后是 VAE 解码器,最后运行safechecker。 大多数组件在推理过程中只运行一次,因此不需要一直占用 GPU 内存。通过启用智能的enable_model_cpu_offload,我们确保 每个组件只在需要时加载到 GPU 中,这样我们就可以显着节省内存消耗。
pipe.enable_model_cpu_offload()
利用 FlashAttention/xformers 注意力层加速(如果没有配置xformers就跳过)
pipe.enable_xformers_memory_efficient_attention()
1.2 模型推理
分别测试加和不加prompt后缀的生成结果:
- prompt 的文本提示应该尽可能地清晰、具体、简洁地描述想要生成的图像,避免模糊、冗长、矛盾的表述。文本提示可以从主体描述、环境氛围、艺术类别、艺术风格、材质、构图、视角、光照、色调等等方面来解构,也可以使用表情符号、角色名、场景名等来增加表现力。
- prompt 的后缀参数可以影响图像生成的质量、分辨率等。不同参数之间要用,隔开。
normal_image = pipe(["Trump"],canny_image,negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"],generator=generator[0],num_inference_steps=20,
)

# positive prompt后缀
good_image = pipe(["Trump, best quality, extremely detailed"],canny_image,negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"],generator=generator[0],num_inference_steps=20,
)

1.3 DreamBooth微调
还可以用DreamBooth来 fine-tune ControlNet模型 :加载StableDiffusionPipeline(在Mr Potato Head人物subject上DreamBooth微调过的StableDiffusion)和ControlNet(前面一模一样的canny的controlnet)组成StableDiffusionControlNetPipeline

model_id = "sd-dreambooth-library/mr-potato-head"
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(model_id, # StableDiffusionPipeline的model_idcontrolnet=controlnet, # ControlNetModel实例torch_dtype=torch.float16,
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
pipe.enable_xformers_memory_efficient_attention() # 如果没有装xformers注释掉即可
推理
generator = torch.manual_seed(2)
prompt = "a photo of sks mr potato head, best quality, extremely detailed"
output = pipe(prompt,canny_image,negative_prompt="monochrome, lowres, bad anatomy, worst quality, low quality",generator=generator,num_inference_steps=20,
)

2. Pose ControlNet
2.1 数据和模型加载
加载瑜伽数据
urls = "yoga1.jpeg", "yoga2.jpeg", "yoga3.jpeg", "yoga4.jpeg"
imgs = [load_image("https://hf.co/datasets/YiYiXu/controlnet-testing/resolve/main/" + url)for url in urls
]image_grid(imgs, 2, 2)

调用controlnet_aux的OpenposeDetector提取图片中的pose
from controlnet_aux import OpenposeDetectormodel = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")poses = [model(img) for img in imgs]
image_grid(poses, 2, 2)
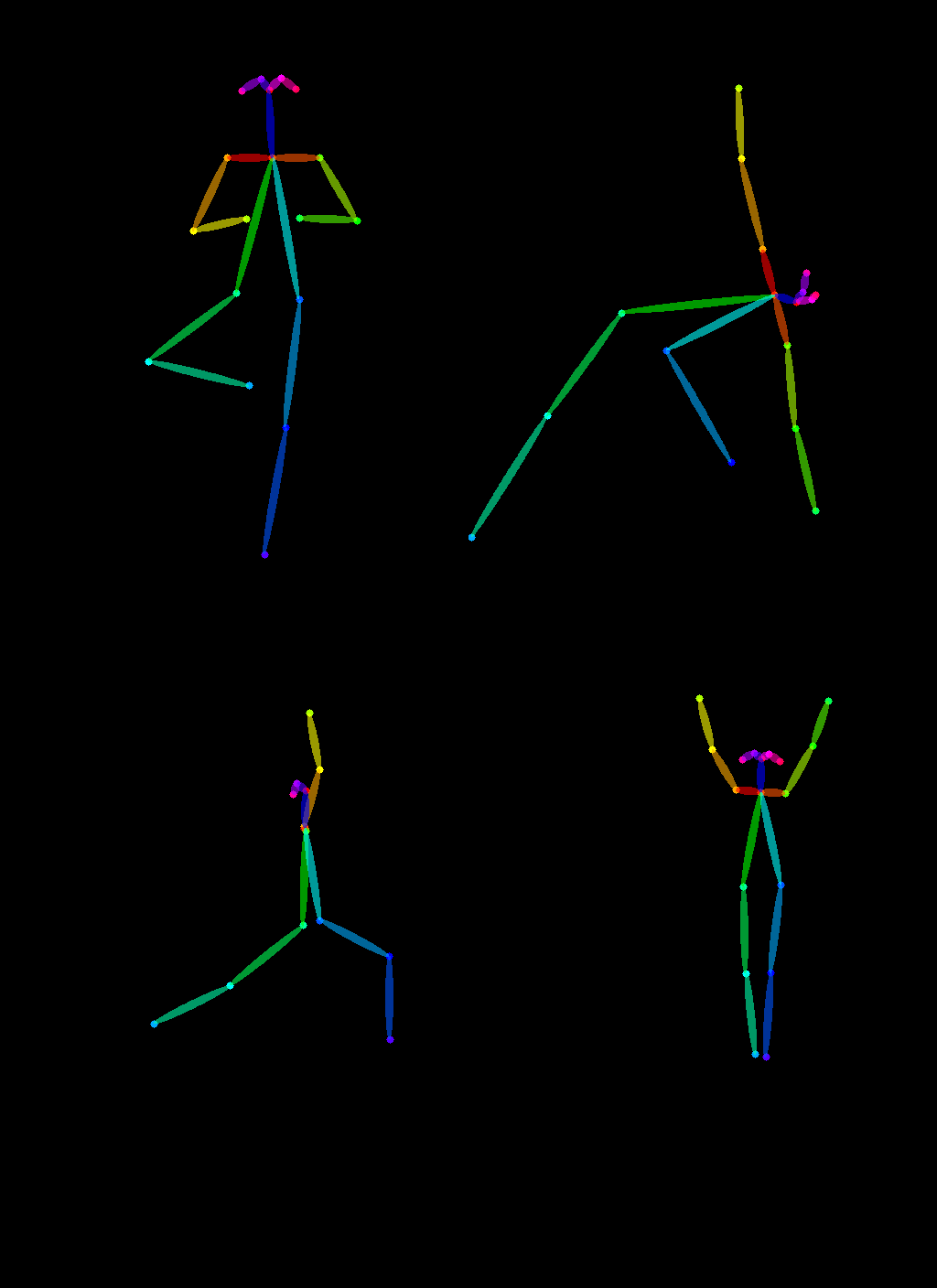
加载StableDiffusionControlNetPipeline,controlnet ='fusing/stable-diffusion-v1-5-controlnet-openpose'
controlnet = ControlNetModel.from_pretrained("fusing/stable-diffusion-v1-5-controlnet-openpose", torch_dtype=torch.float16
)model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionControlNetPipeline.from_pretrained(model_id,controlnet=controlnet,torch_dtype=torch.float16,
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
pipe.enable_xformers_memory_efficient_attention() # 如果没有装xformers注释掉即可
2.2 模型推理
generator = [torch.Generator(device="cpu").manual_seed(2) for i in range(4)]
prompt = "super-hero character, best quality, extremely detailed"
output = pipe([prompt] * 4,poses,negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"] * 4,generator=generator,num_inference_steps=20,
)
image_grid(output.images, 2, 2)