文章目录
- 简介
- Nested Loops
- Merge Join
- Hash Join
- 总结
- 参考文献
简介
多表之间基础的关联算法一共有三种:
- Hash Join
- Nested Loops
- Merge Join
还有很多基于这三种基础算法的变体,以Nested Loops为例,就有用于in和exist的半连接(Nested Loops Semi)算法,以及用于not in和not exists的反连接(Nested Loops Anti)算法等等。这里就不展开介绍了,有兴趣可以再专门搜搜。
Nested Loops
中文名叫嵌套循环,这种连接方式可以简单的用下图来展示:
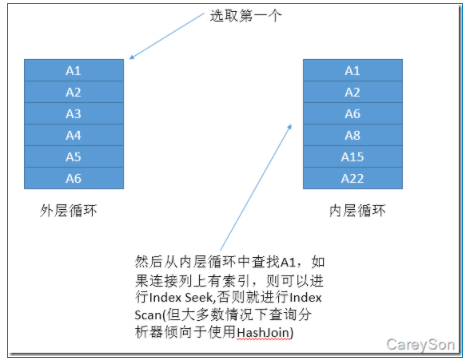
上图来自参考文献2.
如果内表中的连接列有索引的话,内表就可以做index scan(索引扫描),否则的话,内表就只能做tab scan(全表扫描)了。
假设我们有一个外表outer, 一个内表inner,连接列c,嵌套循环实际上就是:
for i in outer:for j in inner:if i.c = i.c:# do something
这就是利用嵌套查询来做连接的全过程。
如果inner表的c列有索引,那内层循环就很快了,直接走index scan即可,如果没有,那就只能tab scan扫描全表了。如果没有索引的话,outer表有多少行记录,inner表就要 全表扫描多少次。(所以内层没有索引的话是很恐怖的)
至于外层outer表有没有索引,就无所谓了,反正他总是要做tab scan,取出每一行来跟inner表比较的。
有个小问题,嵌套循环中,如果连接条件使用了不等值连接,那内表还能走索引吗?
不等式!=会导致索引失效,使用函数会导致失效,但范围查询一般不会使索引失效,如<、>=之类的。(注意是一般情况, 如果优化器认为通过索引扫描的行记录数超过全表的10%~30%,那么它可能会自动变成全表扫描,放弃走索引 )
Merge Join
也称合并连接。
merge join实际上就是把两个有序队列(存在索引,或者无索引但是有序)进行连接,需要两端都要有序,所以不像Nested Join一样不断的循环内部的表。另外,Merge Join需要表连接条件中至少有一个等式,查询分析器才会去选择Merge Join。
merge join的过程可以用下面几个图来解释(同样来自参考文献2):
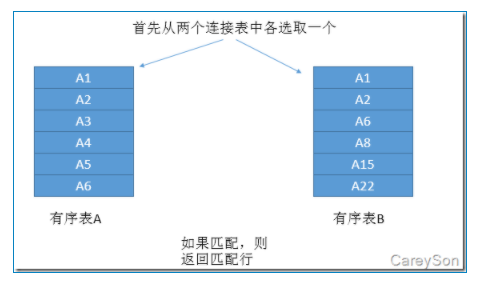
首先从两个表中各选取一行,比较,如果匹配,则返回匹配行;如果不匹配,则有较小值的表+1行,可认为是拥有较小值的表,指针后移一位。
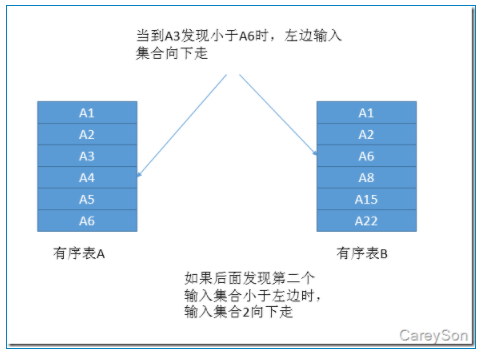
但是如果当前两表并不是有序表(但存在索引),你需要显式的sort之后才能merge join的话,那么使用hash join是效率更高的选择。但也并不绝对,如果查询中已经存在了order by、group by、distinct等,那可能会导致查询分析器不得不进行显式排序,既然已经显式sort了,那查询分析器大概率会对sort之后的结果做merge join。
merge join 对不等值连接(除!=、like外)有更好的支持效率。
但是上面的这张图只能说明等式连接下的merge join的执行过程,那不等式连接下的merge join呢?
据说是这样的:
- 根据谓词条件访问A表,对A表的结果集按照连接列进行排序,形成R1;
- 根据谓词条件访问B表,对B表的结果集按照连接列进行排序,形成R2;
- 将R1和R2放入PGA(即SQL内存区);(
这也是传说中的,sort merge join的两表只需要做一次扫描的原因,扫一次就写入内存) - R1中取出第一条记录去R2进行匹配,然后取第二条、第三条,直到匹配完R1中的所有记录。由于R1和R2都在内存中,所以这个匹配过程也是在PGA中进行的。
可以发现,这个过程实际上跟嵌套循环很像,但是有个很显著的特点,merge join中内表是排过序的,这意味着,相比嵌套循环,merge join能高效的处理不等值连接。
通常情况下,sort merge join并不适合OLTP的系统, 原因是对于OLTP来讲,排序是极其昂贵的操作。
Hash Join
哈希连接。
哈希连接在针对大量、无序的数据时,性能均要优于Merge Join和Nested Join。对于连接列没有索引的情况,查询分析器会优先使用Hash Join。所以哈希连接是做大数据集连接时的常用方式。Hash Join只支持等值连接。
哈希连接分为两个阶段:生成和探测阶段。
生成阶段,选择其中一个表(一般是量比较小的表)作为输入源,将其每一行都经过散列函数的计算,放入不同的Hash Bucket中。其中用到的Hash Function和Hash Bucket据说是黑盒的。另外,Hash Bucket中的数据无序。
这一阶段可以参照下图:
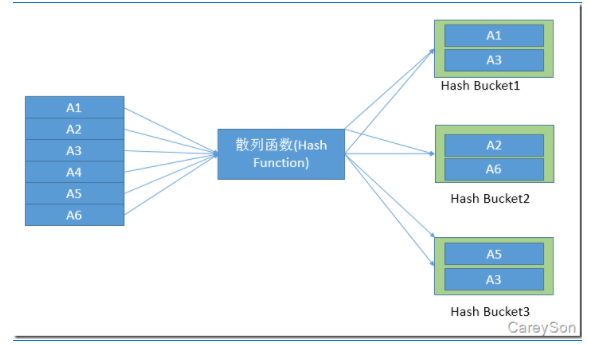
探测阶段,对于另一个表,同样针对每一行做散列函数计算,确定其应在的Hash Bucket,然后用这一行跟这个Hash Bucket中的每一行做匹配,匹配成功则返回对应的行。
探测阶段里,用到的表不需要放入内存,只需要把生成阶段里的小表放入内存即可。
由于Hash Join涉及散列函数计算,所以对CPU的消耗会很大,另外其输出的结果也是无序的。如果内存吃紧的话,还会涉及Grace哈希匹配和递归哈希匹配,可能会用到TempDB从而吃掉大量的IO(如果Hash表太大,无法一次构造在内存里,则会分成若干个partition,写入磁盘,所以使用时会多很多的IO)。有兴趣可以自行查找看看。
hash join 如何处理不等式连接问题?
hash join不支持不等值连接,即<>、<、>等,以及like。
事实上,我感觉也是,分成桶也没办法做范围查询之类的。
总结
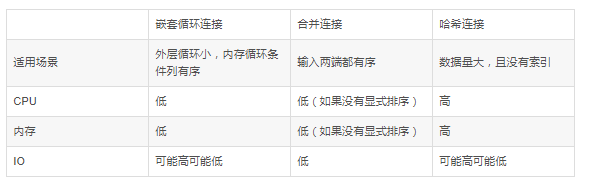
出自参考文献2;
需要提一句的是,在MySQL8.0.18发布之前的很长一段时间里,Mysql的连接算法只有一个嵌套循环的变体,被人广为诟病。直到Mysql8.0.18发布后,Mysql才可以使用Hash Join了。
一般来讲,有索引的情况下会优先使用嵌套,没索引的等值连接则优先使用哈希连接。
参考文献
- 多表连接的三种方式详解 hash join、merge join、 nested loop
- 表的连接方式:NESTED LOOP、HASH JOIN、MERGE JOIN(修改) 写的非常好,推荐看看
- 表连接三剑客(嵌套循环连接,哈希连接,排序合并连接)
- 实现一个基于嵌套循环策略的两表连接算法_MySQL新特性之哈希连接





![【C++入门到精通】新的类功能 | 可变参数模板 C++11 [ C++入门 ]](https://img-blog.csdnimg.cn/011f2608bc4748f4b7dcf007f881967f.png)