最近腾讯的混元大模型内测,我有幸申请到了一个名额。
身为一个程序员,我想大家最关注的一定是该模型的代码和类代码能力,因为这直接关系到这个模型能帮我们解决多少问题,节约多少时间,提高多少效率。
对此,我针对工作中可能会用到的几个点进行了详细的体验。
先说结论:腾讯混元模型在代码生成能力和回答代码类问题的准确性方面和我之前体验过的ChatGPT3.5没有显著区别.
因此我认为,腾讯混元在未来可以作为一个泛用工具来帮助国内程序员提高效率。
以下几个方面是我们工作中可能常常需要去搜索,去提效提速的店点,我结合了工作中的实例来具体体验了以下腾讯混元模型。
1.模块代码的生成功能
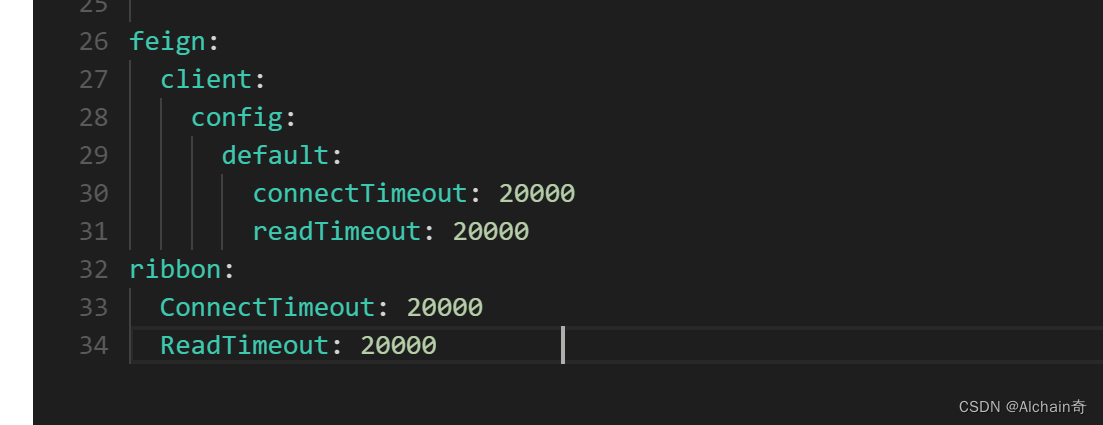
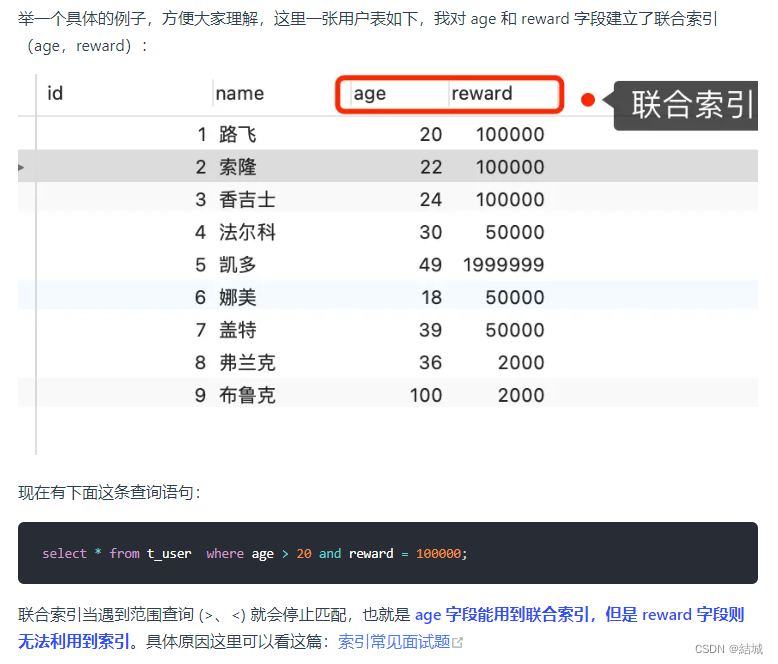
举一个经典的例子:java连接MySQL数据库
像这样的模块一般在自动化框架里会是Utils下的一个基础方法,在腾讯混元模型输入相应的关键字会得到如下的结果 :
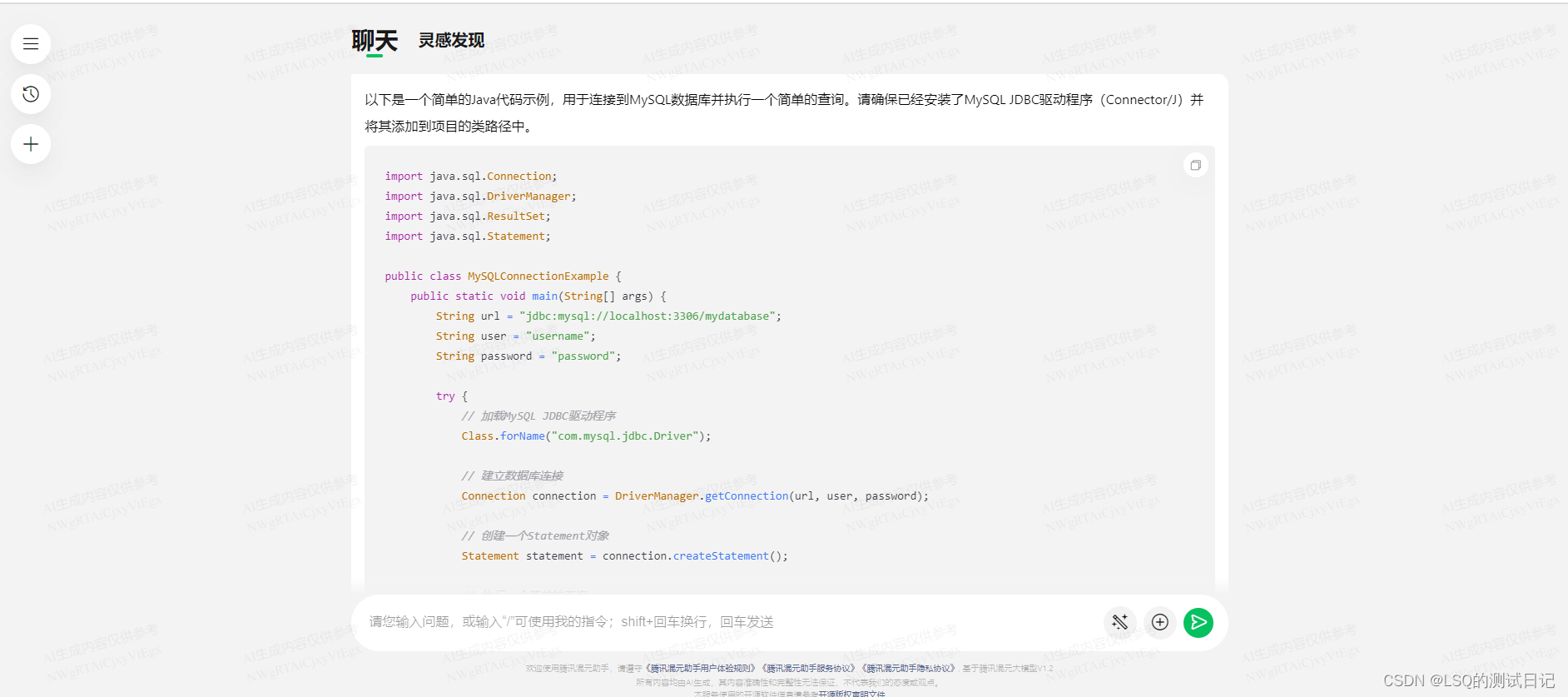
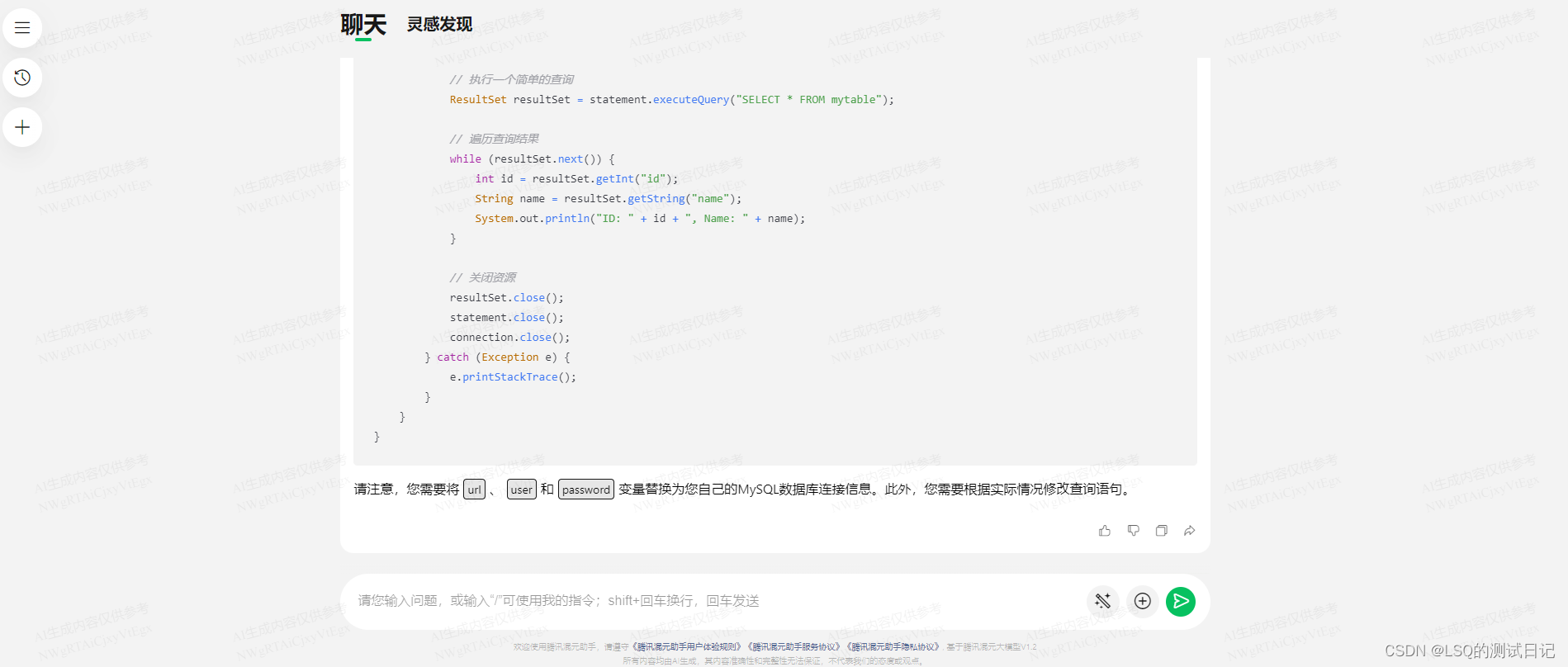
得到的是一段非常标准而典型的代码,你可以用这段基础的代码试着运行并调试,尝试连接数据库。
当然了,在实际工作中我们不会这么写,通常需要做点其他操作。
比如我们需要对这段基础代码进行额外封装,根据业务需求封装成不同的函数。
或者需要把url,用户名,密码等敏感数据放到配置文件里,看情况是否需要加密,在调用函数需要相关数据时进行读配置操作。
等等诸如此类。
再举个例子:java连接redis

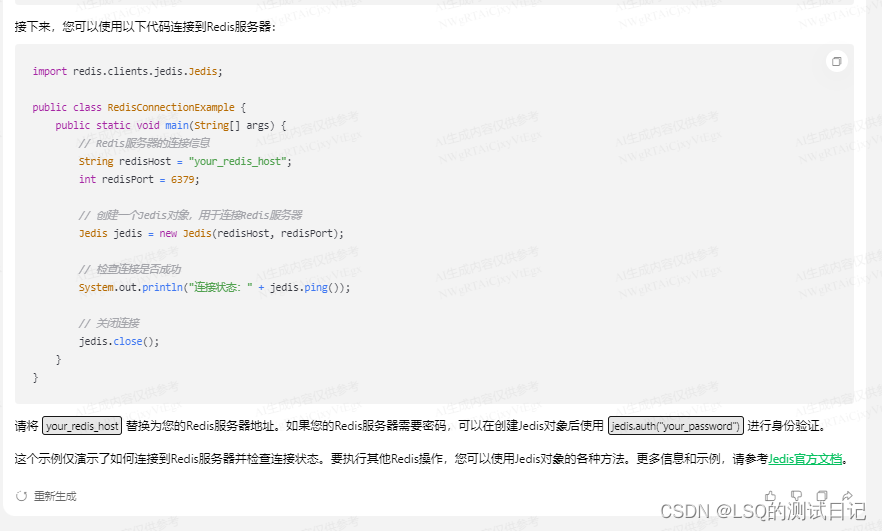
与上面一个 例子类似,这边额外点名了需要在maven中 添加相应的依赖,并附上了Jedis的官方 文档链接,可以说是相当贴心了。
简单总结:
以上的两个例子都是举的java的例子 ,实际上python等其他语言也都类似。
我们在使用腾讯混元模型生成代码时,通常得到的都是一些基础的代码 ,当然,这些代码都是正确的。
在实际工作过程中 ,我们可以拿生成的代码先进行简单的连接调试,随后根据需求自行改进和额外封装 。
因此,对于第一点模块代码的生成功能,我的使用感受是第一点:可以快速生成最基本的调试代码,其次可以过滤掉传统搜索引擎很多无效的信息。
个人认为,在项目或者框架的启动阶段格外实用。
2.报错信息的实时查询及可能错误原因汇总
一个最典型的coding场景,相信99%的软件从业者都经历过:
拿着键盘一顿敲,最后一跑,发现编辑器报错了。仔细排查两遍,没找到程序中的错误,而报错说实话之前也没见过。
然后当然是拿着这段报错信息去网上搜索了。
又或者框架或者微服务跑着跑着就报错了,肯定得拿日志里的报错信息去网上查一查了。
这边我结合了工作中实际遇到的一个情况。
前段时间我们的项目经历了切环境,由于项目还没正式上线 ,总的来说影响不算大 。
项目到了新的云 上 ,我发现我们的自动化 框架没法连到数据库上了。
在换云之前,我们肯定已经经过了简单的调试 ,用账号密码是可以在堡垒机上访问数据库的,但将账号密码和新的url替换到自动化框架中,自动化框架无法连接到数据库。
报错如下:
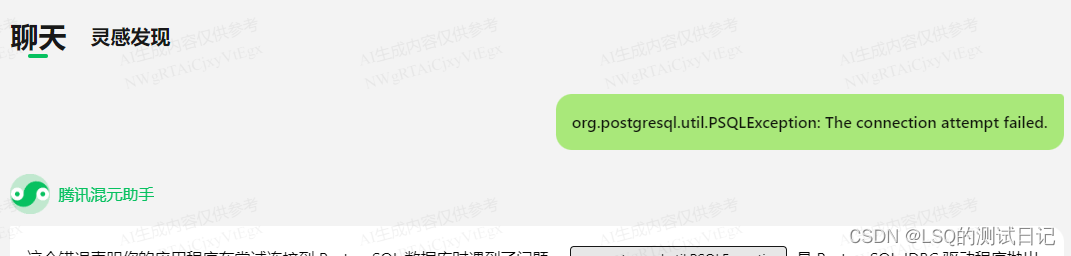
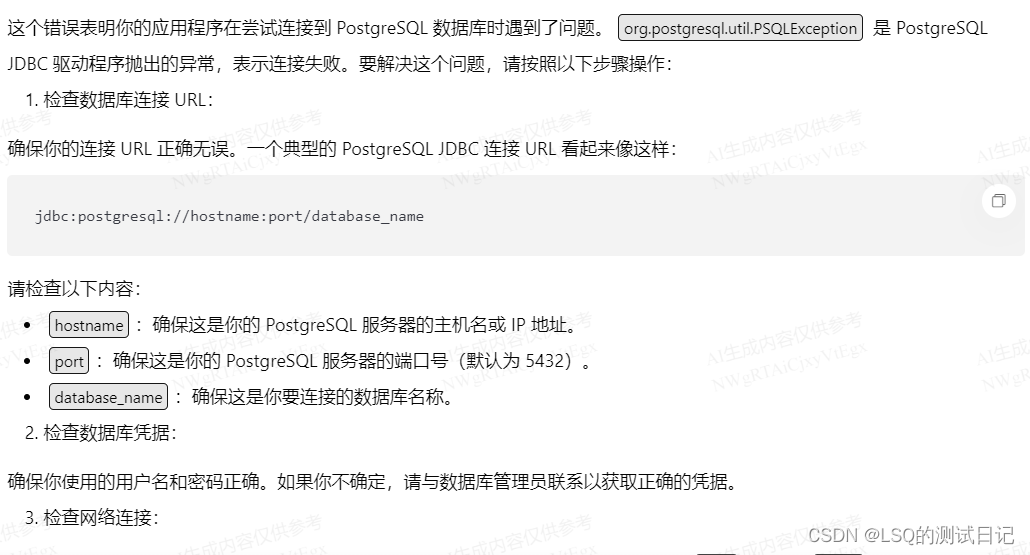
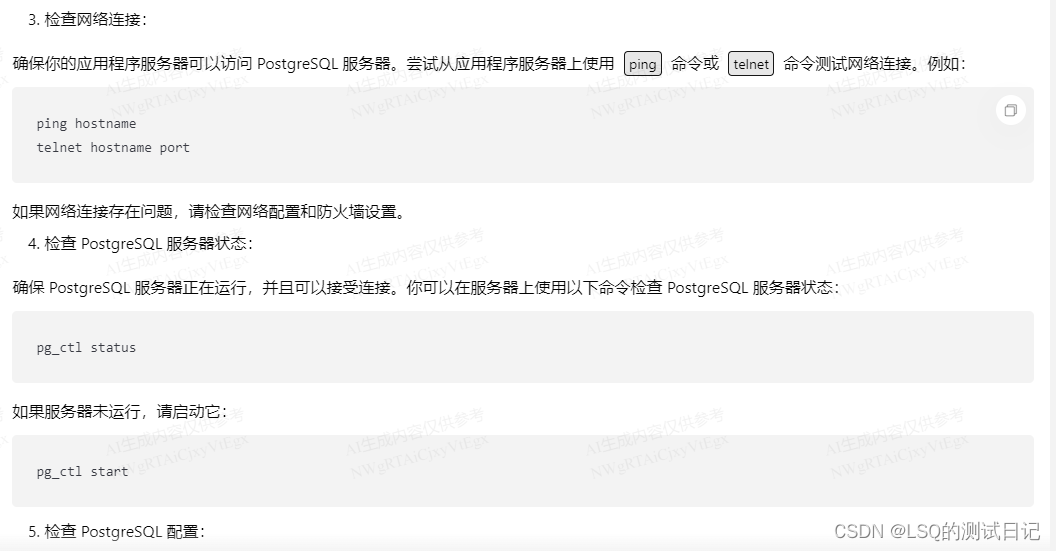

这边我根据实际情况一一排查,首先数据库的基本信息和服务状态是对的。
那么可能的原因就是云上的一些设置,比如限制外网访问,设置了防火墙等等。
最终问题由devops团队解决,的确是配置问题。
简单总结:
在报错信息上腾讯混元模型可以做到对所有可能情况的汇总,帮助使用者一一排查。
个人认为这个功能可以极大的帮助 程序员过滤无效信息,因为对于报错信息查询来说,传统搜索引擎和部分技术网站的内容重叠性实在是太高了。
3.代码的逻辑解读
有没有一种可能,你入职了一家新公司,接手了一个 新项目。前任给你留下的是一座屎山,甚至于连一行注释都没有。
于是你不得不一个文件一个文件的解读,每个文件都有数百上千行代码。
腾讯混元模型可以根据函数名,变量名以及代码行间的逻辑进行一个基本的解读。
当然 ,变量名 /函数名取的实在太差或者代码中函数调用部分都可能会导致一定的解读偏差,不过帮助程序员快速全方面的掌握代码的基本逻辑还是可以的。
在不涉及敏感信息的前提下,我可以截取公司框架中的部分简单逻辑进行尝试。
首先是一个自动化测试用例的语句描述部分,这是个退出登录接口的自动化例子:
简单 来说分三步:
- 给出的测试账号先登录
- 该账号调用退出登录接口
- 验证退出登录的结果/token是否失效 等

我们看看腾讯混元模型的解读:
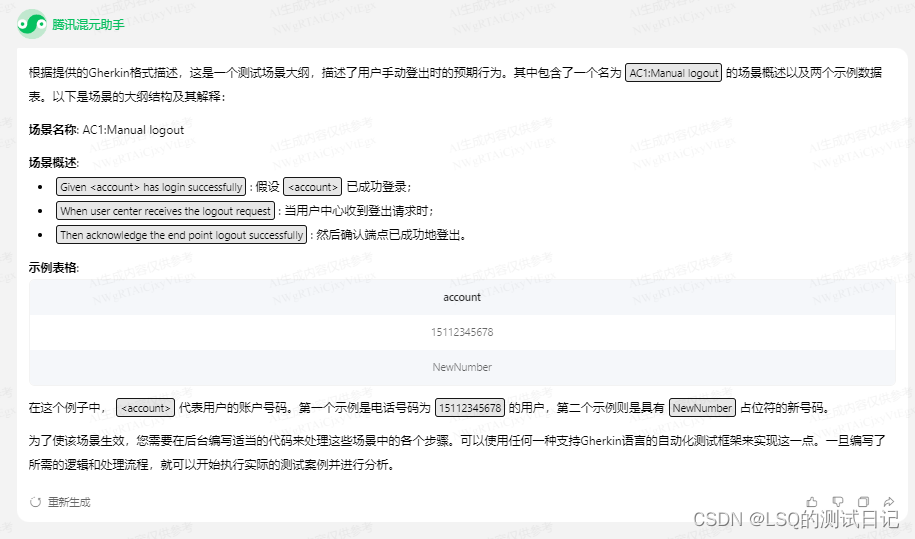
完全正确。
我们再拿一段Java代码来尝试:


除了第三步略微有点出入,应该是验证短信验证码并完成登录操作,其他的解析完全正确。当然,这边只是调用了 一个函数 ,想完全解读清楚还是有点难度的。
另外一点,最后对函数的总结做的也相当不错。
简单总结:
个人认为产品对于代码的解析做的已经相当成熟了,而且准确性保守估计能到 90%以上。
这个功能我觉得在帮助程序员快速掌握项目代码或者同事之间团结合作,熟悉彼此的代码这两个方面提效很大。
4.生成逻辑代码
这部分老生常谈了,我觉得目前想要使用腾讯混元模型在日常真实的工作中帮助程序员来生成逻辑代码还是有点困难的。
一是描述费劲和时间成本,我觉得对于一个手熟并且社交PTSD的程序员来说,让他用中文把逻辑描述清楚的这点功夫,他可能早就已经把代码写好了。
二是实现的代码可能有一定偏差。
三是风格问题,将提供的代码放到已有的代码框架中可能要费点功夫。
不过腾讯混元模型还是具备一定的逻辑处理能力的,这边进行一个简单的尝试。

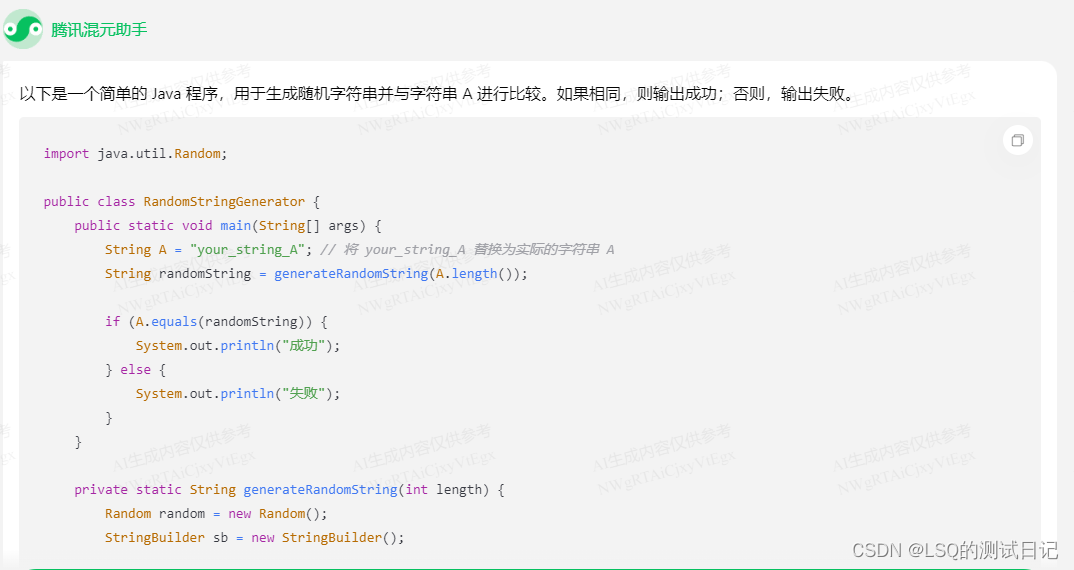

简单总结:
还是可以处理一定的逻辑并生成代码的,不过可能确实很难应用到工作中,这边就没举实际例子。
整体感受
其实,自从ChatGPT问世以来 ,程序员的提效真的很明显了 。以我自己为例,身边的同事人手一个 ChatGPT,代码提交速度比之前快乐了很多,也更卷了。
不过,今年以来 ,时常能听到同事说他的ChatGPT又被封了,或者用的是国内代理的套皮版ChatGPT,时不时的就又不能用了。
因此,我觉得在使用体验和功能没有明显差距的情况下,腾讯混元模型或许是国内程序员不错的一个 选择。