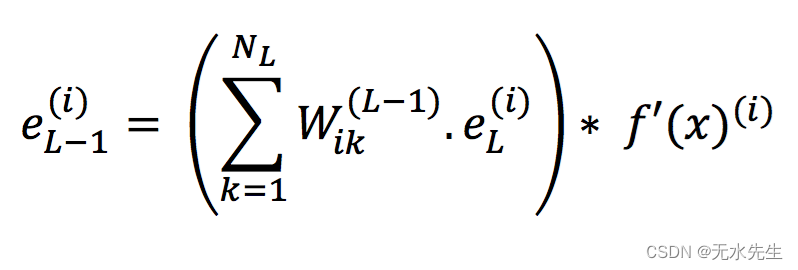文章目录
机器学习专栏
介绍
基本思想
使用代码
深度探索
优点
估计概率
训练算法
CART成本函数
实例数与不纯度
正则化
在鸢尾花数据集上训练决策树
机器学习专栏
机器学习_Nowl的博客-CSDN博客
介绍
作用:分类
原理:构建一个二叉树,逐级条件判断筛选
基本思想
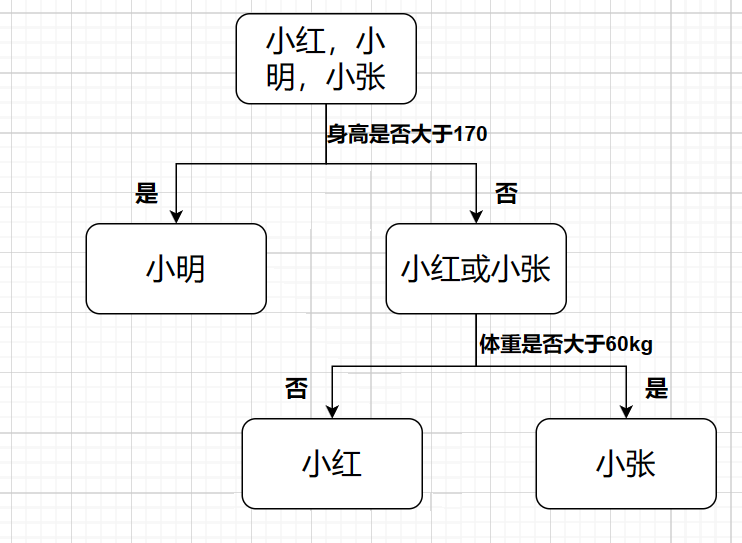
假如有小明,小红和小张三个人,我们知道他们的身高体重,要通过身高体重来判断是哪个人,决策树算法会构建一个二叉树,逐级判断,如下
使用代码
from sklearn.tree import DecisionTreeClassifiertree_clf = DecisionTreeClassifier(max_depth=2)
tree_clf.fit(X, y)max_depth参数设置的是决策树的深度,上图的深度是2,它代表决策的次数
深度探索
优点
我们来看决策树的过程:每到一个节点进行一次询问,然后将数据集分向其他的节点,这样的特性决定了数据不需要经过特征缩放的处理
估计概率
决策树模型可以输出每个类的概率
这意味着我们可以使用predict_proba方法,这将输出每个类的概率
model = DecisionTreeClassifier(max_depth=2)
model.fit(x, y)model.predict_proba(x)训练算法
决策树的训练算法被称为CART算法,它的目标是选择一个特征(k)和阈值(t)(在最开始的例子中,身高体重是特征,170和60kg是阈值),CART算法会通过成本函数不断优化,选择每个节点合适的特征和阈值
CART成本函数
m为实例数
G为不纯度
下标left和right分别代表该节点的左右子树
实例数与不纯度
实例数就是被分到某节点实例数量,在最开始的例子中,根节点的左实例数会这样记录:1个小明,0个小红,0个小张,右实例数会记为0个小明,1个小红,1个小张
不纯度代表着节点中类的混合程度,在最开始的例子中左节点只有一类,不纯度就为0,而右节点有两类,不纯度就较高,决策树算法中往往采用基尼不纯度来判定
它的公式为
为第k类的实例数
为总实例数
正则化
为了防止过拟合,我们当然要进行正则化,决策树的正则化通过控制参数max_depth来决定,越大则越可能过拟合
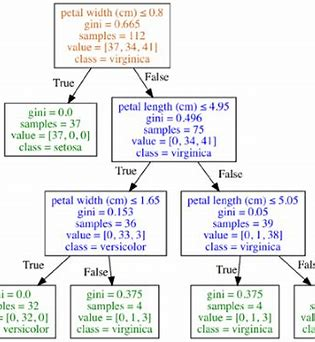
在鸢尾花数据集上训练决策树
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifieriris = load_iris()
X = iris.data[:, 2:] # petal length and width
y = iris.targettree_clf = DecisionTreeClassifier(max_depth=3)
tree_clf.fit(X, y)当我们用上面代码训练模型时(使用花瓣长和宽做特征,决策树深度设为3),可能得到如下模型图