好多内容直接看书确实很难坚持,就比如这个卷积,书上的一大堆公式和图表直接把人劝退,我觉得一般的学习流程应该是自顶向下,先整体后局部,先把握大概再推敲细节的,上来就事无巨细地展示对初学者来说很痛苦。
所以我先把我学习的结果通俗总结一下,卷积是将输入结合其他的节点进行一定处理,从而得到想要的结果,卷积操作多用于图像中,可以实现图像的平滑,特征的提取等。
卷积
数学上表达为积分公式(积分号)f(x)g(n-x)dx
其中f表示为输入,g表示为输出,可以结合问题理解该式的物理意义:
一个人一直进食,其进食数量的曲线就可以表示为f,与此同时也在一直消化食物,且消化速度只按比例,表示为g;问任意时间t胃部食物数量。
一个时刻进食剩余为f(x)g(n-x)//x时刻的进食量乘经过n-x时间的消化率,故在t时刻胃部食物剩余量为上式的积分,f与g的对应关系如下图:
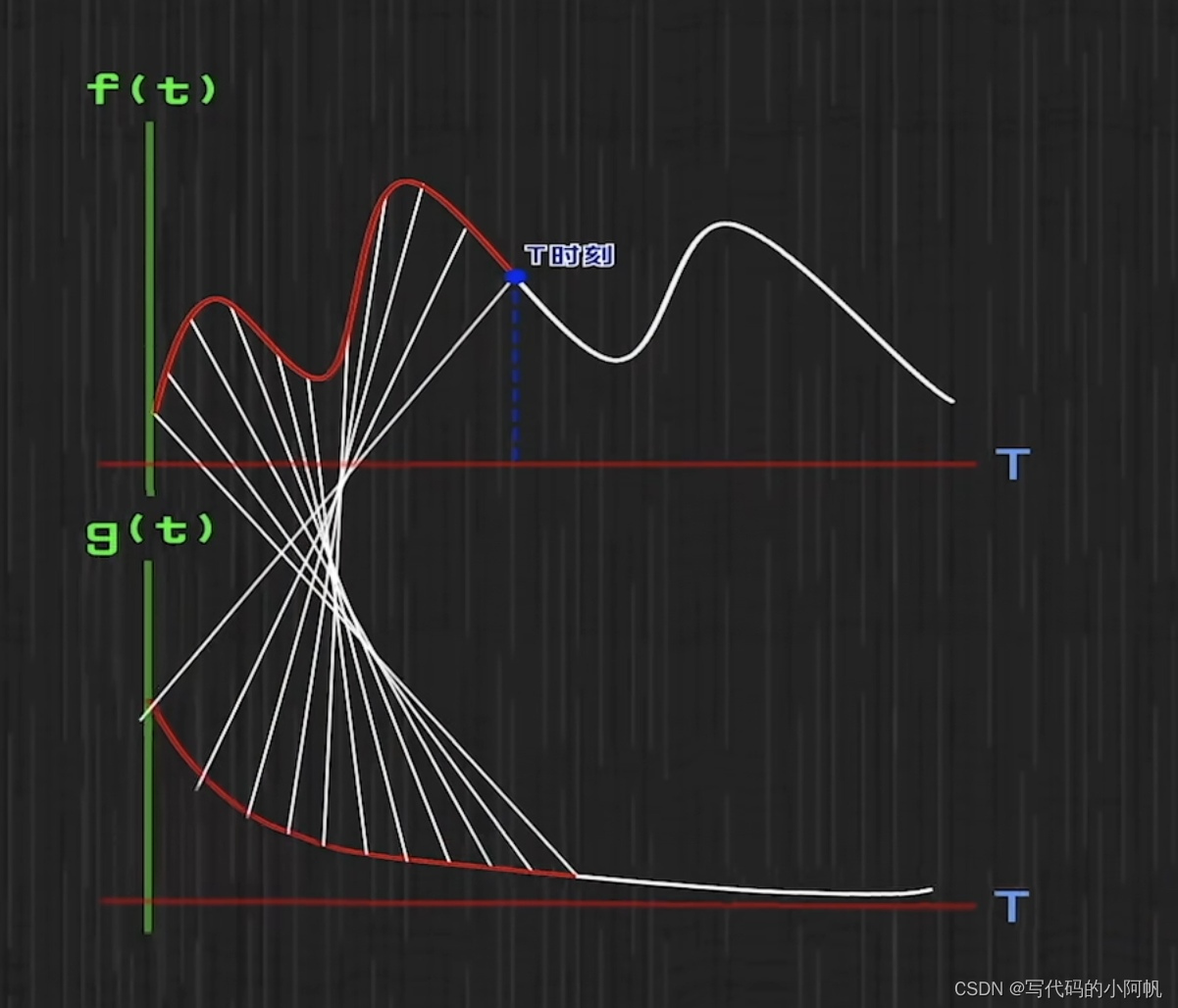
卷积的卷应该体现在g的反转上
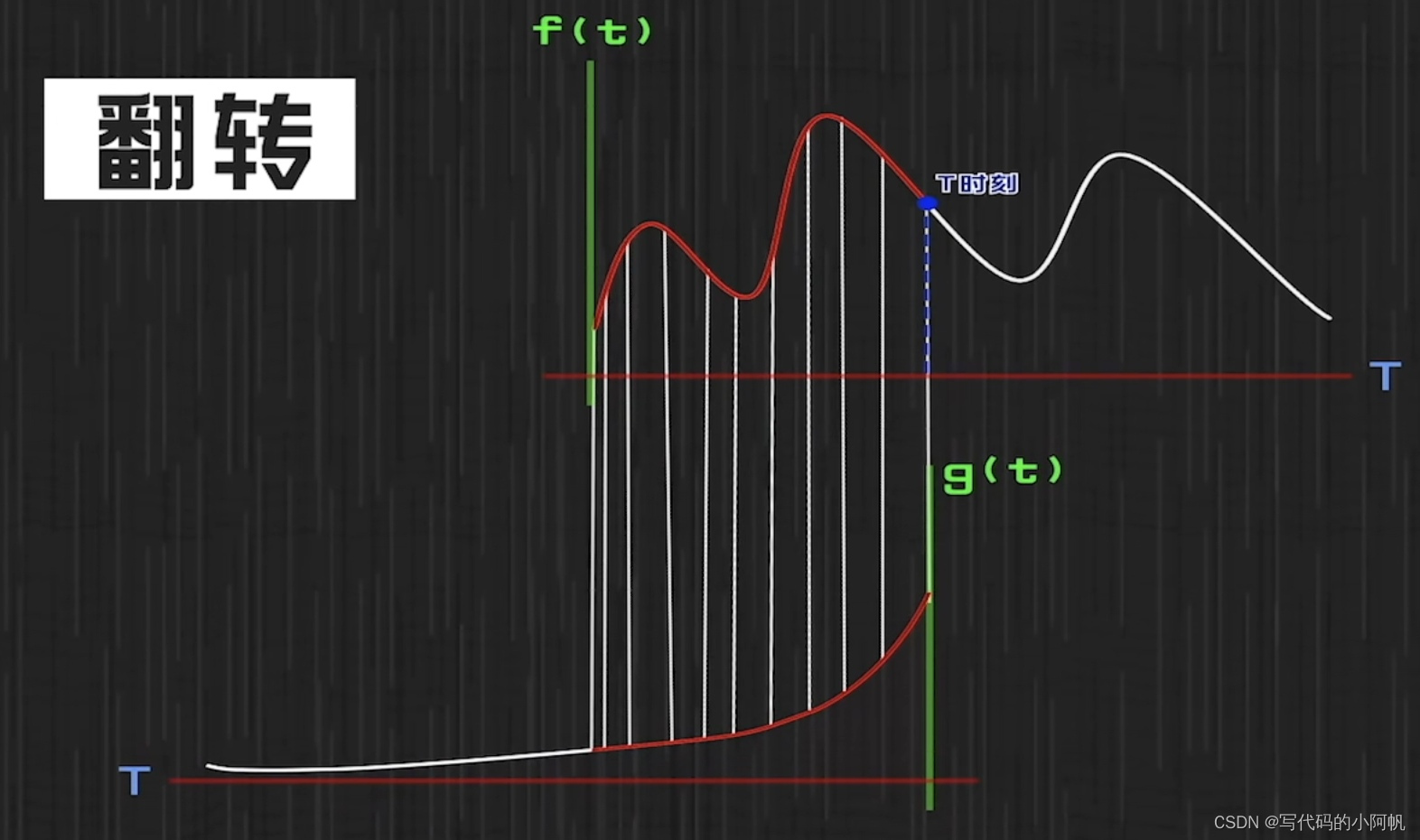
即,卷积可以用于一个输入不稳定但输出稳定的系统求任意时刻的存量。
图像卷积操作
卷积在实践中的应用主要是用于识别图像内容,在识别之前需要先对图像进行卷积操作,但该操作步骤与上面提到的不同;图像卷积操作是用3×3矩阵与图像进行先乘再加,图像经过处理会缩小一圈,外部直接赋0,过程展示如下:
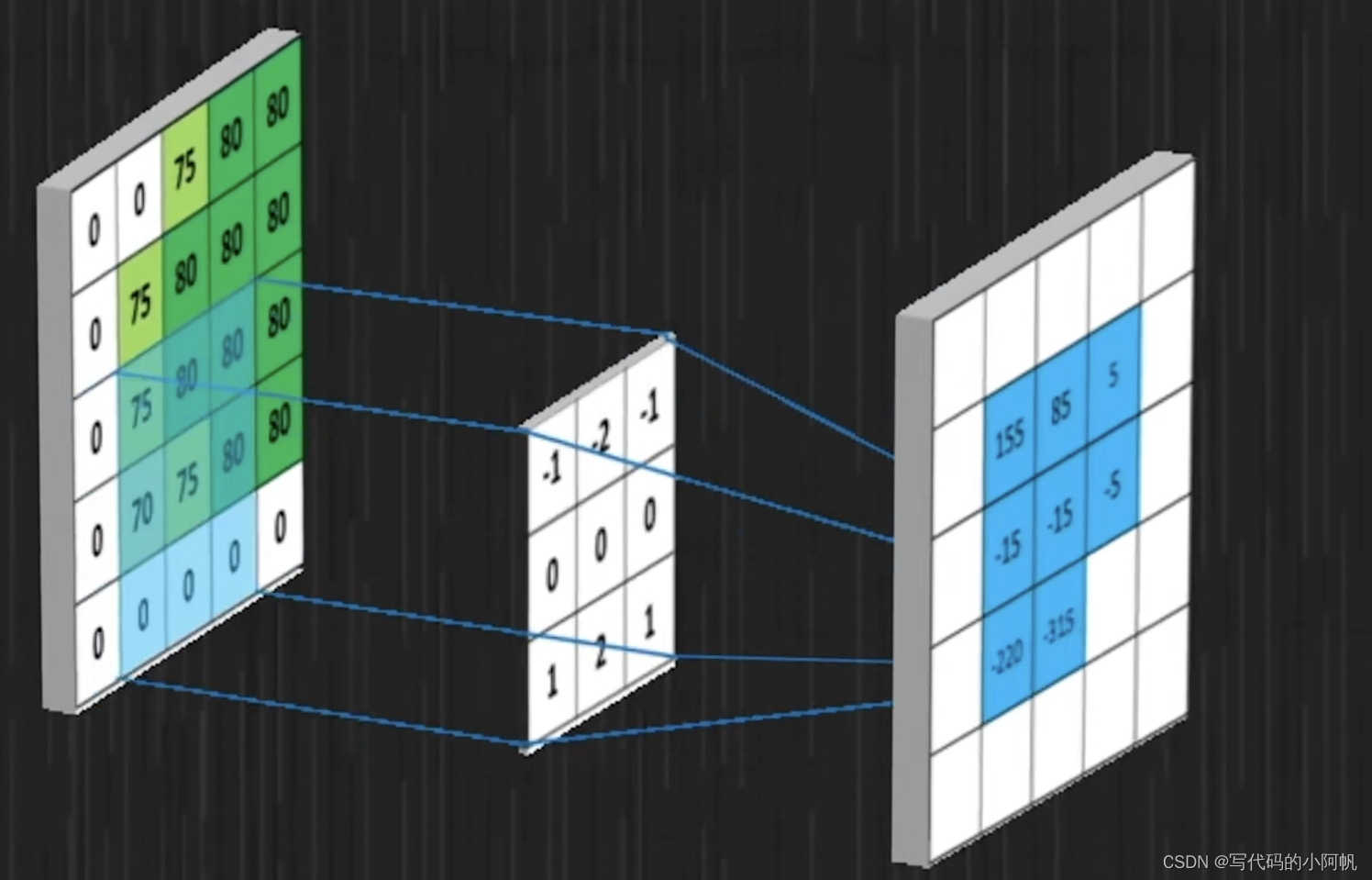
该矩阵称为卷积核,该步骤的作用是将一个像素点与其他的像素点通过卷积核关联起来。
比如每个元素均为1/9也就是平滑卷积核,使用平滑卷积核卷积后的图像会使图像整体更平滑,因为他缩小了像素直接的差距,用平均数来代替。
卷积的另一个作用
通过这个例子我们看出卷积不知用于系统的求存量,在图像中也能通过卷积核时相邻像素点产生关联,此时的f是像素点,卷积核是g,即周围的像素点共同影响当前像素点,而g决定具体如何影响。
图像识别
本来这部分应该叫卷积神经网络的,但是一想神经网络没讲到,只是单单写了最前的一步,还是该叫图像识别吧。
现在的图像验证码们人眼看来识别很简单,但是为什么能防住计算机呢?就是因为他们难以从图像中识别出物体,但随着人工智能的发展,图像识别对计算机来说也是洒洒水了。
图像识别原理
计算机不能像人一样感性推断出图像内容,它们识别物体主要是依赖特征值,比如A上的“尖或者三角”、Z的两个大折线、老虎头上的“王”字等等,甚至目前的人脸识别也是如此,计算机通过特征识别出我们的五官后,对我们的眼距,鼻梁等特征再进行对比从而判断身份。
说着很简单,但每次判断都不简单,不同的字符和事物可能有不同的和相同的特征,这时又该如何是好呢?我看过一篇论文,里面说到每个特征对应一个“特征鬼”,当特征被满足时,该“特征鬼”就会尖叫,又有最上层的决策系统看哪个事物的“鬼”叫的最响来作出判断。
卷积操作提取特征
说白了还是利用卷积核进行操作,只是卷积核的取值发生了变化,比如:
1 1 1
0 0 0
-1 -1 -1
作为卷积核,就只提取水平上的特征值,此时卷积核称为水平/垂直过滤器,起到过滤图片保存特征的作用,同理
1 -1 -1
-1 1 -1
-1 -1 1
可以判断图像是否为一条对角线,等等,从而生成特征矩阵交由后续算法判断。
图像识别卷积总结
实质还是卷积和也就是g的选取,如果g选的合适,就可以把对我们有用的特征保存下来。
总结
归根到底就是f×g,通过对g不同形式不同值的选取,在多角度多维度上筛选f,得到我们想要角度的特征值,再加上求和加权平均消除误差。也难怪人工智能喜欢用,这一个方法就能提取出一个特征值发一篇文章,基于人工智能的······研究,其实就是用个CNN跑出一组数据处理一下,找找关系,下个结论。
讲到这我又要喷人工智能了,在我目前来看,我们对自己意识的研究和脑科学尚不充足完备的情况下,所谓人工智能根本名不副实,现在已有的这些模型不过是基于大数据的统计分类的机器而已。