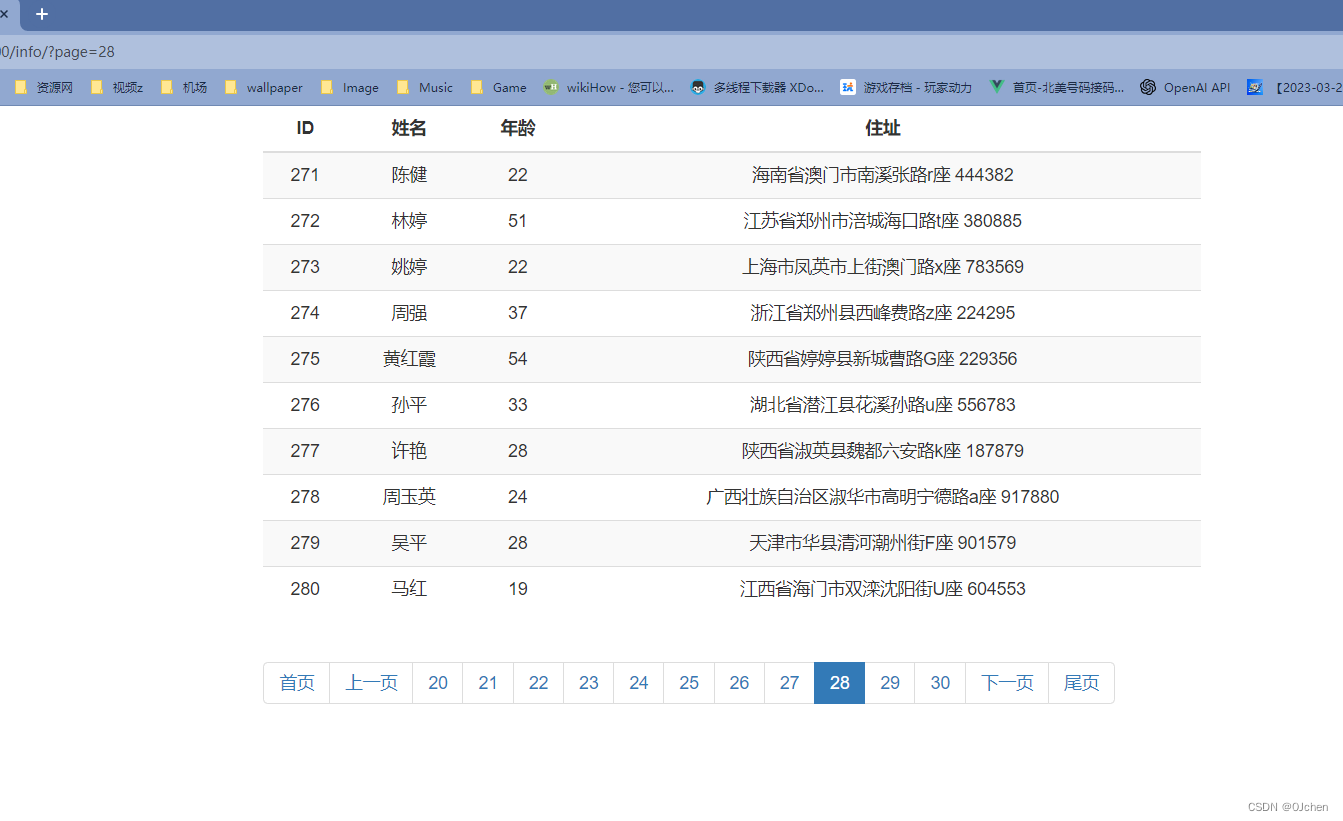
博主原文链接:https://www.yourmetaverse.cn/nlp/504/

PyTorch中并行训练的几种方式
在深度学习的世界里,随着模型变得越来越复杂,训练时间也随之增长。为了加快训练速度,利用并行计算变得至关重要。PyTorch作为一个流行的深度学习框架,提供了多种并行训练的方法。本文将介绍几种常用的并行训练方式,包括数据并行(Data Parallelism)、模型并行(Model Parallelism)、分布式数据并行(Distributed Data Parallelism)以及混合并行(Hybrid Parallelism)。
1. 数据并行(Data Parallelism)
数据并行是最简单直接的并行训练方法。它通过将训练数据分割成多个小批次,然后在多个GPU上并行处理这些批次来实现加速。PyTorch通过torch.nn.DataParallel来实现数据并行。
优点:
- 易于实现和使用。
- 适合小到中等规模的模型。
缺点:
- 随着GPU数量的增加,由于GPU之间需要同步,可能会遇到通信瓶颈。
2. 模型并行(Model Parallelism)
模型并行是另一种并行训练方法,它将模型的不同部分放在不同的计算设备上。例如,将一个大型神经网络的不同层分别放在不同的GPU上。
优点:
- 适用于大模型,尤其是单个模型无法放入单个GPU内存的情况。
缺点:
- 实现复杂。
- 需要精心设计以减少设备间的通信。
3. 分布式数据并行(Distributed Data Parallelism)
分布式数据并行(DDP)是一种更高级的并行方法,它不仅在多个GPU上分配数据,还在多台机器之间分配工作。PyTorch通过torch.nn.parallel.DistributedDataParallel实现DDP。
优点:
- 可以在多台机器上并行处理,进一步提高了训练效率。
- 减少了GPU间的通信开销。
缺点:
- 设置比较复杂。
- 对网络和数据加载方式有额外的要求。
4. 混合并行(Hybrid Parallelism)
混合并行结合了数据并行和模型并行的优点。它在不同的GPU上既分配模型的不同部分,也分配不同的数据。
优点:
- 最大化了资源利用率。
- 适用于极大规模的模型和数据集。
缺点:
- 实现难度最大。
- 需要更多的调优和优化。