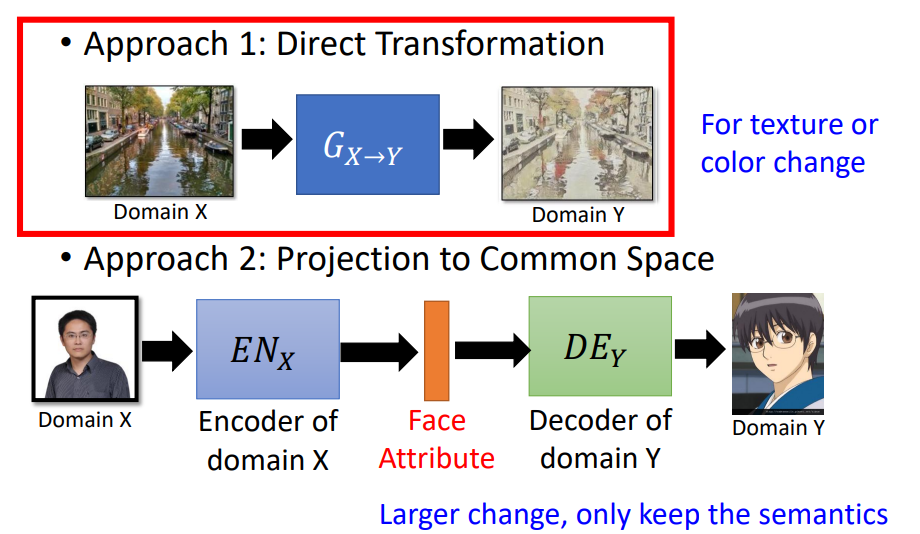
Unsupervised Condition GAN主要有两种做法:
- Direct Transformation
直接输入domain X图片,经过Generator后生成对应的domain Y的图像。这种转化input和output不能够差太多。通常只能实现较小的转化,比如改变颜色等。
- Projection to Common Space
先学习一个X domain的encoder,把特征抽出来;然后输入Y domain的decoder,生成对应的图片。
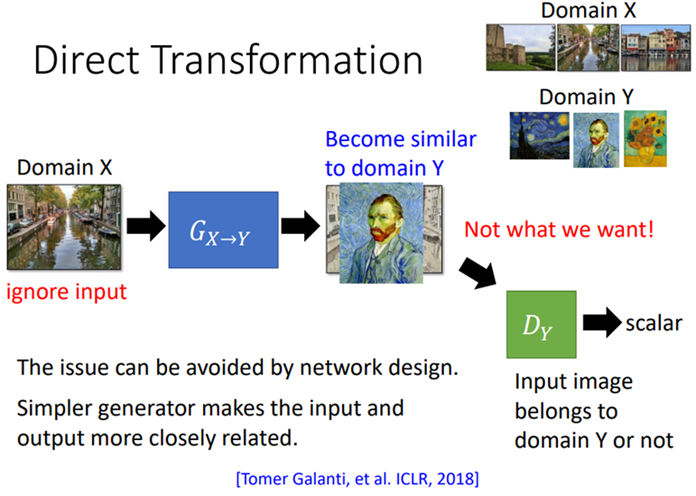
Direct Transformation
训练一个G,它能够将X domain的图片转换为 Y domain的图片。现在有一堆X domain的数据,一堆Y domain的数据,但是合起来的pair没有。因此需要训练一个Y domain的discriminator,鉴别一张图片是不是Y domain 的图片。存在的一个问题就是generator输出的图像可能和输入无关。有三种方法可以解决此问题。
直接无视(generator shallow)
在generator 比较shallow的情况下,输入和输出会特别像,这时候就不需要额外的处理。
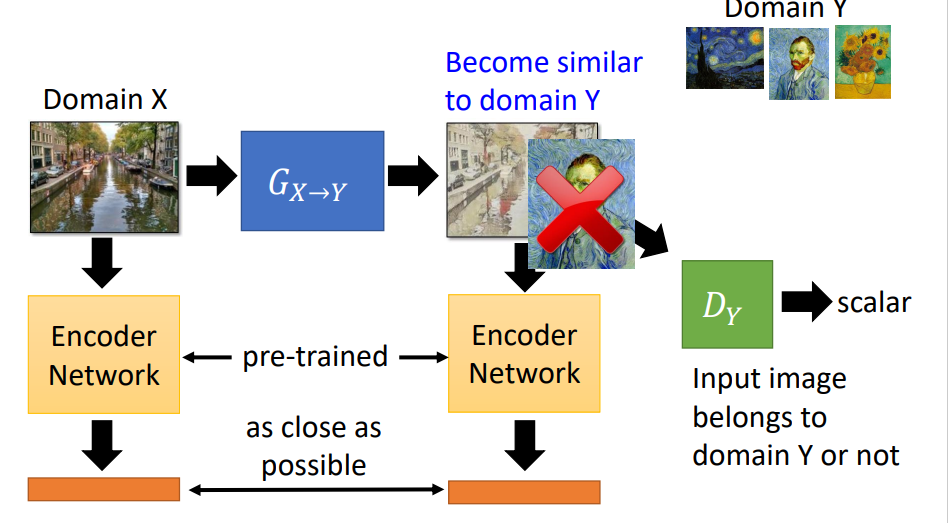
利用预训练网络
用一个已训练好的网络,把generator的输入和输出转换成两个embedding vector;在训练的时候,让这两个embedding的vector尽可能的相似。
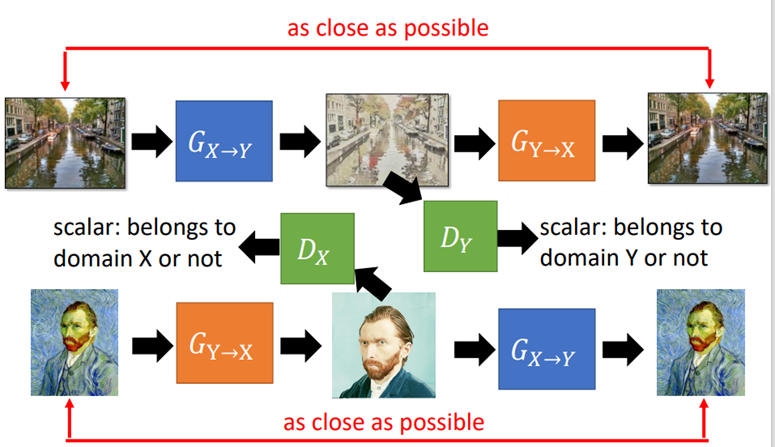
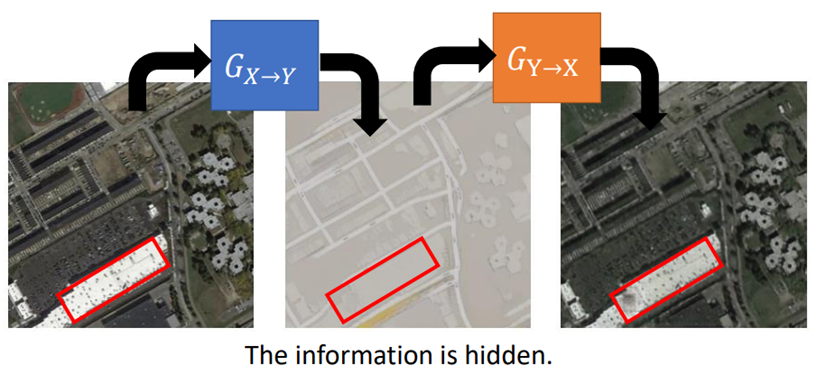
Cycle GAN
在训练一个X domain到Y domain的generator的同时,训练一个Y domain到X domain的generator;目标就是输入图像和两次转换之后的图像越接近越好。
训练一个Y domain到X domain同样的结构,就构成双向结构。
Cycle GAN存在的问题:cycle GAN会把输入的有些部分隐藏起来,然后再output的时候再呈现出来。
StarGAN
StarGAN主要用于多个domain之间的转换。具体做法如下:
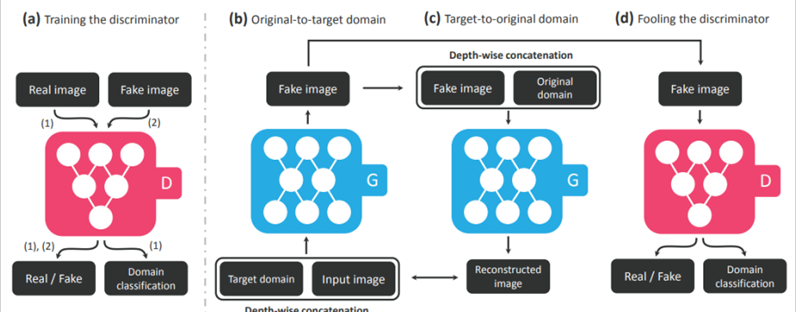
- 训练一个discriminator:鉴别图片的真假;判断这张图片属于哪个domain;
- 训练一个generator,输入是一张图片以及目标domain,输出目标domain的图片;
- 将生成的图片以及原始图片的domain输入给同一个generator,输出一张新的图片,新的图片和2中输入的图片越接近越好;
- Discriminator要做两件事:鉴别2中输出图片的真假;判断这张图片是否属于目标domain。
下面是实际的例子。

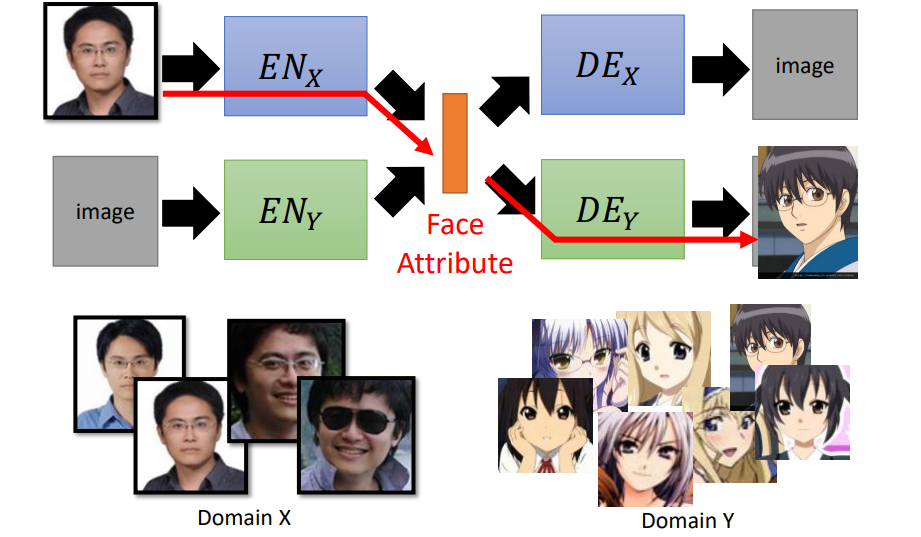
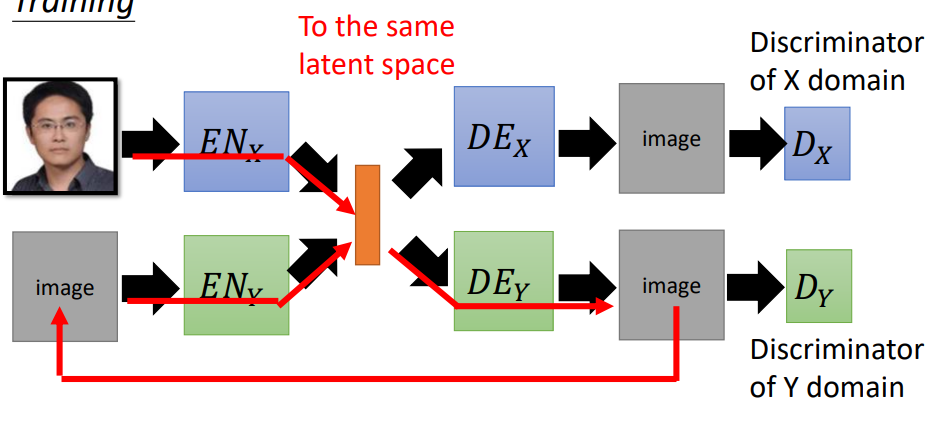
Projection to Common Space
训练目标:真人图片输入到ENx ,可以提取出真人的特征,然后经过二次元的DEx 得到对应的二次元图片;同理二次元图片经过特征提取,能够产生真人的图片。
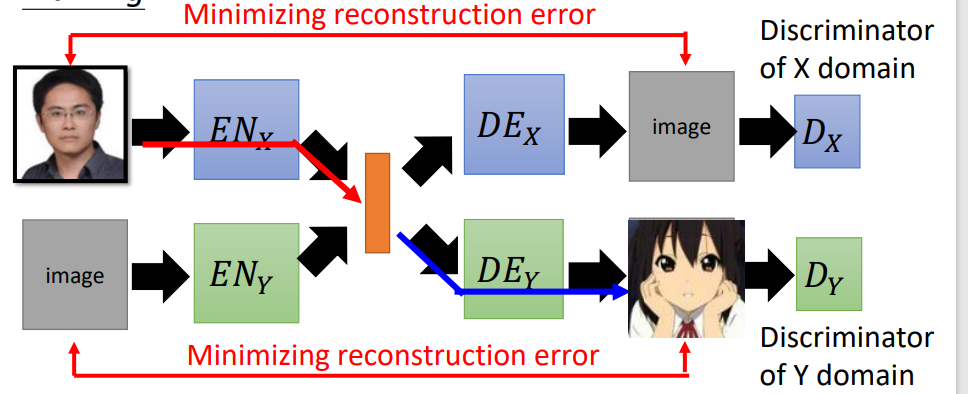
一种训练方法就是:分别训练两个auto-encoder生成真人照片和二次元照片。但是两个auto-encoder是分开训练的,两者之间没有关联,所以在latent space中每个维度的表示属性可能是不一样的。
可以使用以下方法解决关联问题:
共享参数
让不同domain的decoder的最后几个hidden layer和encoder的最前面几个hidden layer的参数共用;通过共享参数,将不同domain的image压缩到同一个latent space,即同样的dimension 表示同样的属性。

增加判别网络
用一个discriminator来判断特征vector是来自于X domain的image还是来自于Y domain的image。两个encoder就是要骗过这个discriminator。当discriminator无法判别的时候,说明两者被encode到同一个空间。

Cycle Consistency
将一张image经过X encoder变成code;再经过Y decoder还原成image;然后再输入到Y encoder,再通过X decoder把它还原成image;然后希望input和output越接近越好。

semantic consistency
让原始图片通过 X encoder 输出 code,再让这个 code 通过Y decoder和 Y的encoder生成另一个 code,最后让着两个code越接近越好。这种技术常用于 DTN 和 SGAN 。
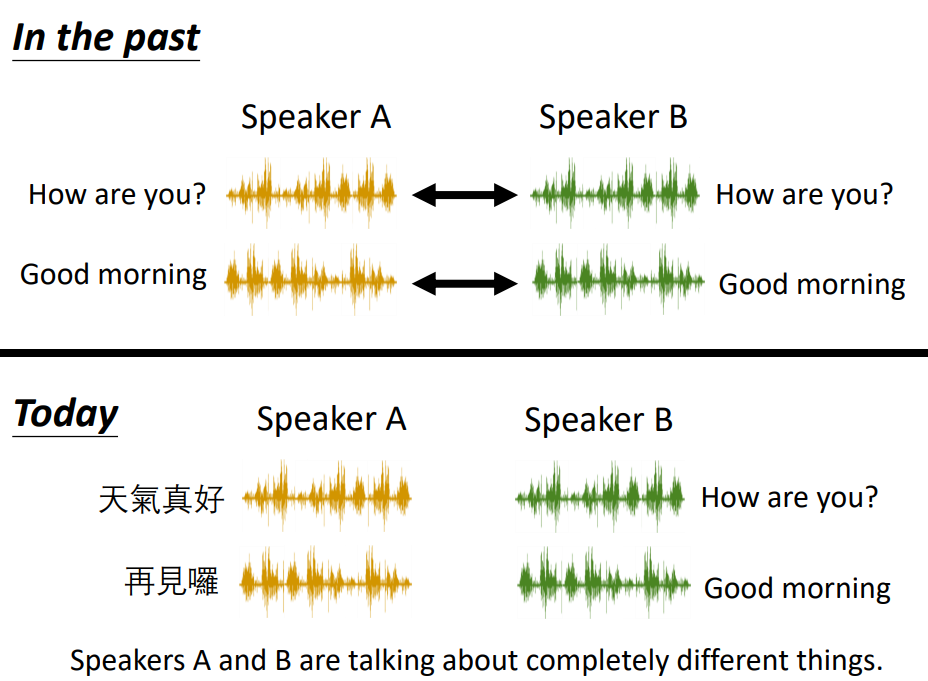
- Voice Conversion(声音转换)
过去,用的监督学习的方法,要有一堆对应的声音;现在只要收集两组声音,不用讲一样的内容就可以进行训练。








![CNVD-2023-12632:泛微E-cology9 browserjsp SQL注入漏洞复现 [附POC]](https://img-blog.csdnimg.cn/6b6152d8d9634b3e9e29f8fdddf0f804.png)