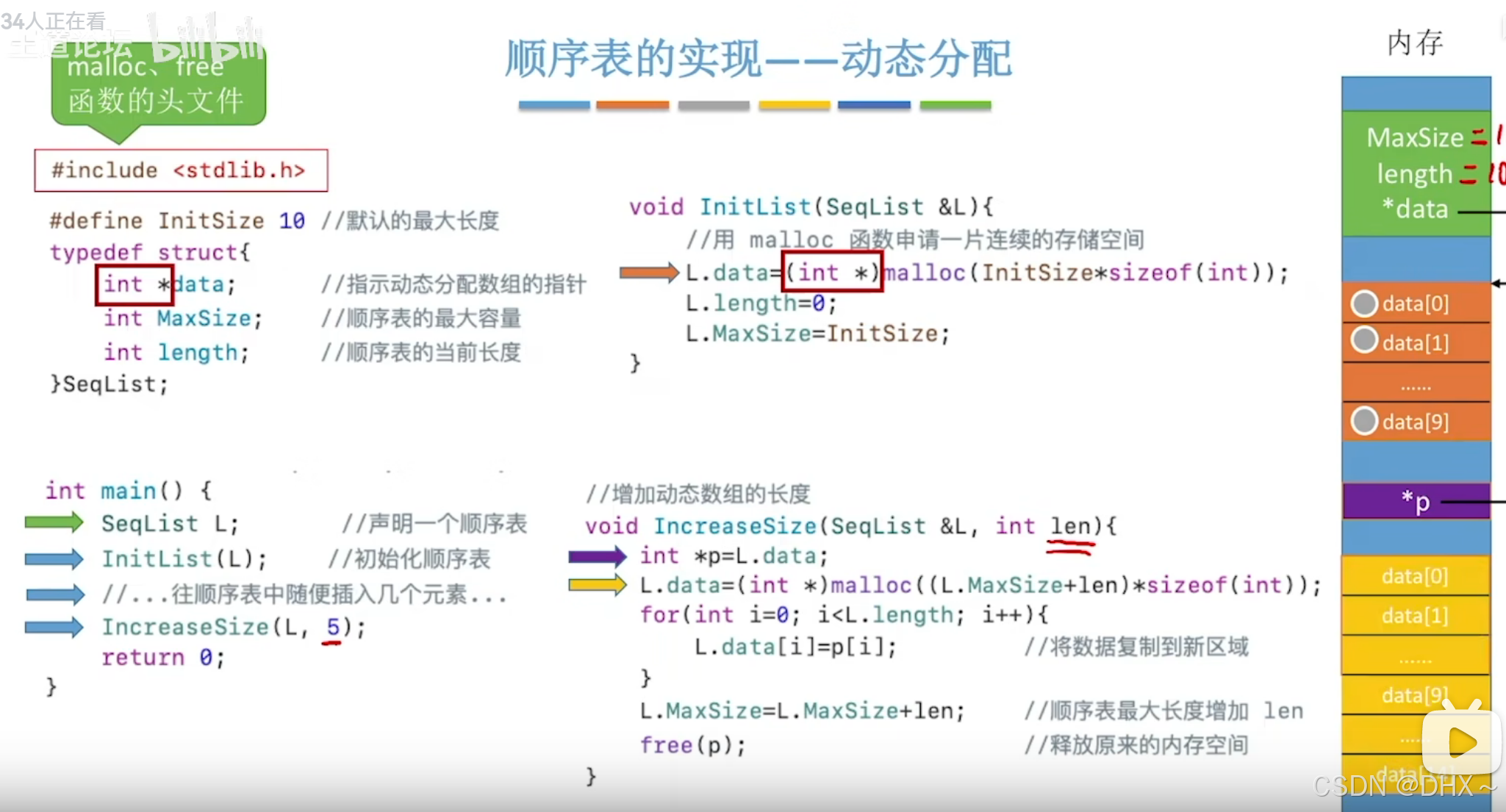
25考研分数马上要出了。
目前,多所大学已经陆续给出了分数查分时间,综合往年情况来看,每年的查分时间一般集中在2月底。
等待出成绩的日子,学子们的心情是万分焦急,小编用最近爆火的“活人感”十足的DeepSeek帮大家预测一下25考研的分数线。
一起来看看吧~

影响国家线的关键因素
1)报考人数
-
2023年考研报名人数为474万(首次下降),2024年回升至438万(官方未公布,网传数据存疑)。若2025年报考人数继续波动,可能影响竞争激烈程度。
-
就业压力若持续,考研仍会是重要选择,但“逆向考研”(双非院校热度上升)可能缓解部分热门专业的分数线压力。
2)招生计划
-
专硕扩招:教育部明确到2025年将专硕招生扩大到总规模的2/3,可能导致部分专硕专业国家线小幅下降(如电子信息、机械等工科专硕)。
-
学硕缩招:部分高校缩减学术型硕士名额,可能推高学硕分数线(如文学、教育学等热门文科专业)。
3)试题难度与考生水平
-
公共课(政治、英语、数学)难度波动直接影响单科线。例如,2023年数学难度较高导致工科国家线下降。
-
考生备考日趋精细化,高分段竞争可能加剧(尤其经管类、计算机等热门专业)。
4)政策导向
-
国家鼓励理工科人才培养,可能通过扩招或专项计划稳定相关专业分数线(如材料、能源等)。
-
部分冷门专业(如农学、哲学)可能通过政策倾斜保持较低分数线。
2025年国家线预测(分学科大类)
| 学科门类 | 2024年国家线(A区) | 2025年趋势预测 | 原因分析 |
| 哲学 | 323(↑9分) | 持平或微降 | 报考人数稳定,招生计划有限,分数线波动较小。 |
| 经济学 | 346(↑8分) | 持平或微涨 | 经管类热度高,竞争激烈,但专硕扩招可能分流压力。 |
| 法学 | 340(↑5分) | 持平 | 法律硕士(非法学)持续热门,但招生规模扩大可能平衡分数线。 |
| 教育学 | 350(↓1分) | 微涨 | 教师编制竞争加剧,跨考生增多,可能推高分数线。 |
| 文学 | 365(持平) | 高位持平 | 传统高分学科,招生名额少,分数线难以下降。 |
| 工学 | 273(↓10分) | 小幅波动(±5分) | 专硕扩招+理工科政策支持,但数学难度波动可能影响单科线。 |
| 理学 | 279(↓8分) | 持平或微涨 | 基础学科报考稳定,实验类学科可能受扩招影响。 |
| 医学 | 304(↑9分) | 微涨 | 医学专硕竞争激烈,且临床类招生门槛较高。 |
| 管理学 | 347(↑4分) | 持平 | MBA/MPA等非全日制项目扩招,可能缓冲全日制分数线上涨压力。 |
根据deepseek给出的预测,25考研大部分专业的分数线是略微上涨的。
当然,不论是上涨还是下降,deepseek给出的国家线通常都是基于当期考研的大环境进行分析和调整,仅供参考,目的是为我们后续计划提前做准备。
那么应该怎么准备呢?
高分学子(超过国家线30分及以上)
准备复试,并提前联系导师,了解导师的研究方向
→重点方向:
-
复习院校的重点,报考院校导师的重点研究方向;
-
准备个人简历、英文自我介绍,提前联系英语口语和专业课知识,有项目、实习、比赛经验的要重点突出;
-
专业课的基础和复试院校要求的专业课内容持续学习,如有上机操作的也需要提前准备。
中等分数(超过国家线20分)
好好准备复试,争取在复试中逆袭;若需要调剂,提前查询调剂信息,联系导师。
→重点方向:
-
系统复习专业课,查漏补缺,尤其是薄弱环节;
-
模拟面试,提升表达能力和应变能力;
-
准备个人简历、英语自我介绍和常见专业课问题回答,如果有项目、实习经验可以重点突出。
一般考生(刚过国家线0-15分)
认真准备复试,多关注调剂信息,可以访问学校官方微信公众号、官网等,加群联系往届学姐学长进行推荐。
→重点方向:
-
关注调剂信息,尽早联系有调剂名额的院校;
-
稳扎稳打准备复试,确保复试不出错;
-
准备个人简历、英语自我介绍和常见专业课问题回答。
国家线只是初试的初步筛选,复试表现同样重要,复试一定不要掉以轻心。
最后想跟大家说,无论考研成功还是失败,不要因为一时失败而慌乱、气馁。
乾坤未定,你我皆为黑马!
当然,之前也给大家预测过,25届考研预计268万人考研失败。

万一上不了岸,我们能做什么?
1)考研二战
如果心有不甘,年纪尚轻,也可以和家里人商量一下二战。
第二次考研相比第一次,经验更丰富,也可以迅速找到自己的不足,加强弥补。
但二战需要克服更巨大的心理和经济上的压力。
2)转战留学:
和考研相比,出国留学没那么卷,而且国外大部分研究生的学制通常是1-2年,相比国内的3年更快毕业。即便部分海外硕士被调侃为“水硕”,但按照世界排名来看,留学是一个不错的选择。
当然,留学更适合第二语言能力强,家境较为殷实的同学。比如,英国硕士留学一年的费用大概在25-35W人民币,加上前期的语言考试、作品集、留学中介费等,是一笔不小的费用。
3)找工作:
如果考研结果不如预期,提前找工作可以为你积累工作经验,增加就业竞争力。
对于GIS专业的同学来说,直接就业,薪资竞争力最大、性价比最高的还是GIS开发岗。在新中地,每年也有很多考研没上岸的同学,转行做WebGIS开发,继而成功就业的。
考研失利,转GIS开发上岸:月薪12K
该同学22年地信专业毕业,毕业后奋力二战,因为太卷,没能上岸,之后在同学的介绍下来新中地学GIS开发,顺利进入某上市企业(军工)从事GIS开发工作,薪资12K各项补助年终奖。


00后考研失利转GIS开发,斩获11K offer
该同学22年毕业,考研失败后加入了新中地GIS开发特训营,结业后就收到某大型上市企业的录用。在北京某上市公司从事GIS开发,薪资11K*14薪。

如果没有确定自己职业规划方向的,可以趁这段时间思考自己的职业兴趣和发展方向,寻找与之匹配的工作机会。
也可以利用这段时间提升自己的专业技能,例如GIS开发技能和项目经验。
来源:DeepSeek预测25考研分数线