网络爬虫是什么?
网络爬虫就是:请求网站并提取数据的自动化程序
网络爬虫能做什么?
网络爬虫被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。
网络爬虫还被用于爬取各个网站的数据,进行分析、预测
近几年来,大量的企业和个人开始使用网络爬虫采集互联网的公开数据,进行数据分析,进一步达到商业目的。
利用网络爬虫能从网上爬取什么数据?
可以好不吹嘘的说,平时从浏览器浏览的所有数据都能被爬取下来。
网络爬虫是否合法?
上面说到了爬虫可以爬取任何数据,那么,爬取数据这种行为是否合法?
目前关于爬取数据的法律还在建立和完善中,如果爬取的数据属于个人使用或者科研范畴,基本不存在什么问题;一旦要用于商业用途就得注意了,有可能会违法。互联网界对于网络爬虫也建立了一定的道德规范(Robots协议)来约束。
这里具体看下Robots协议
Robots协议规定各个搜索引擎哪些页面可以抓取,哪些页面不能抓取,Robots协议虽然没有被写入法律,但是每一个爬虫都应该遵守这项协议。
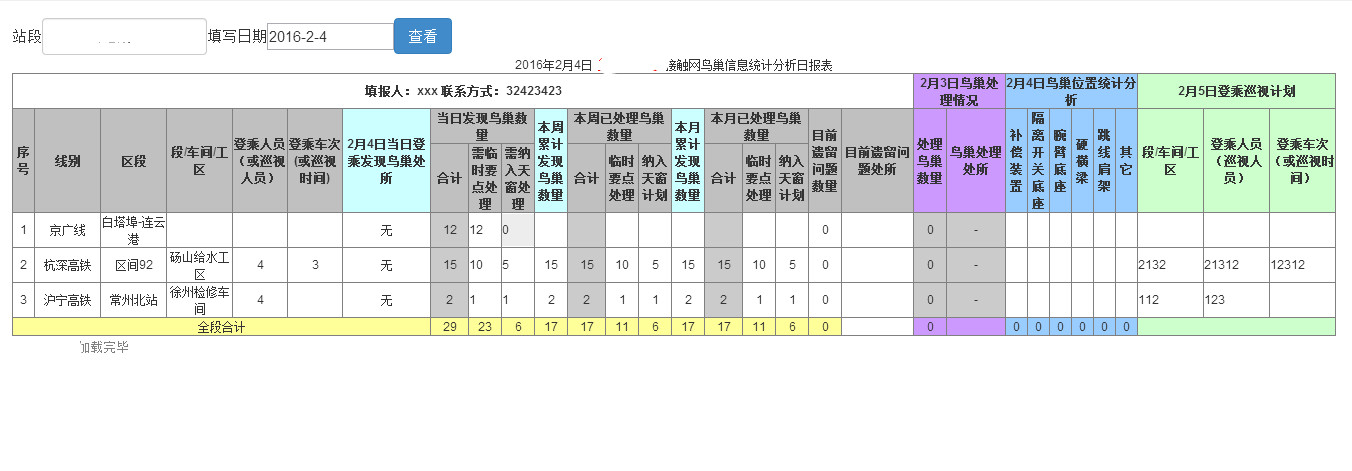
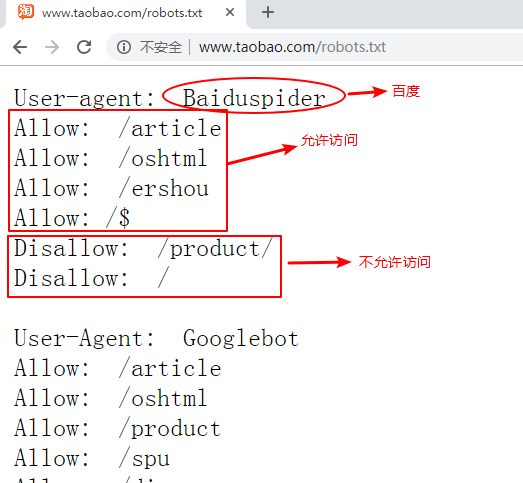
下面是淘宝网的robots协议:
进群:960410445 即可获取源码哦!
从图中我们就可以发现淘宝网对百度的爬虫引擎做出了规定,然而百度也会遵守这些规定,不信你可以试试从百度是找不到淘宝里的商品信息的。
python爬虫的基本流程
Python爬虫的基本流程非常简单,主要可以分为三部分:(1)获取网页;(2)解析网页(提取数据);(3)存储数据。

简单的介绍下这三部分:
- 获取网页 就是给一个网址发送请求,该网址会返回整个网页的数据。类似于在浏览器中输入网址并按回车键,然后可以看到网站的整个页面。
- 解析网页 就是从整个网页的数据中提取想要的数据。
- 存储数据 顾名思义就是把数据存储下来,我们可以存储在文本中,也可以存储到数据库中。
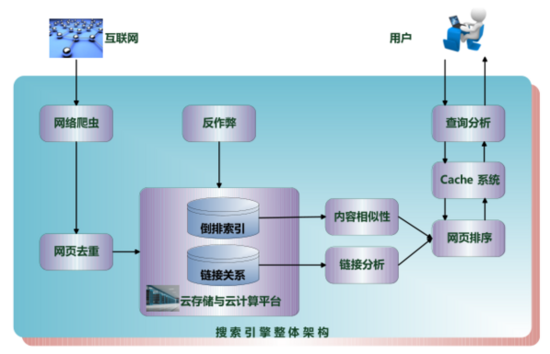
基础爬虫的框架以及详细的运行流程
基础爬虫框架主要包括五大模块,分别是 爬虫调度器、URL管理器、HTML下载器、HTML解析器、数据存储器 。这五大模块之间的关系如下图所示:
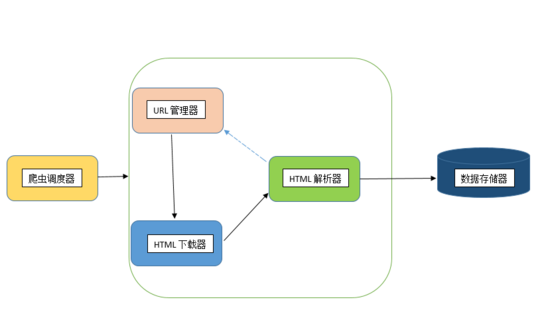
下来我们来分析这五大模块之间的功能:
- 爬虫调度器主要负责统筹其他四个模块的协调工作。
- URL管理器负责管理URL链接,维护已经爬取的URL集合和未爬取的URL集合, 提供获取新URL链接的接口。
- HTML下载器用于从URL管理器中获取未爬取的URL链接并下载HTML网页。
- HTML解析器用于从HTML下载器中获取已经下载的HTML网页,并从中解析出新 的URL链接交给URL管理器,解析出有效数据交给数据存储器。
- 数据存储器用于将HTML解析器解析出来的数据通过文件或者数据库的形式存储起来。
详细的运行流程如下图所示:

关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门Python是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习等习教程。带你从零基础系统性的学好Python!
零基础Python学习资源介绍
👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取哈)

👉Python必备开发工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉100道Python练习题👈
检查学习结果。
👉面试刷题👈


这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】