文章目录
- 摘要
- 引言
- 相关工作
- 任务定义
- 构造RECCON数据集
- 情绪原因的类型
- 实验
- 任务1:Causal Span Extraction
- 模型
- 任务2:Causal Emotion Entailment
- 模型
- 面临的挑战
摘要
识别文本中情绪背后的原因是NLP中一个未被探索的研究领域。这个领域的发展具有着改善情感模型可解释性和性能的潜力。由于说话者之间的动态交互性,对话中的话语级情绪原因识别极具挑战性。为此,我们引入对话中的情绪原因识别任务,并提出一个该任务的数据集RECCON,此外,我们根据原因的来源定义了不同的原因类型,并且在RECCON中的两个子任务:1)Causal Span Extranction 和 2)Causal Emoiton Entailment上建立了较强的基于transformer的基线。数据集地址为: https://github.com/declare-lab/RECCON.
引言
情感理解是AI中的一个关键部分,而语言经常暗示了一个人的情感。因此,考虑到情感识别在意见挖掘,推荐系统,医疗和其它领域的广泛应用,情感识别在NLP中受到了广泛关注。
文本或视频中的情感探测和分类方面已经有了很大的进展,然而到目前为止,关于情绪的进一步推理,比如理解一个说话者情绪的背后原因仍然很少被探索。
在这篇论文中,我们关注的是对话中的情绪原因识别。特别地,我们会在对话上下文中寻找能够触发目标话语中的情绪的events, situations, opinions or experiences。除了上述提及的事件,原因也可以是一个说话者对另一个说话者所关心事件的对应反应(人际交往之间的情绪影响)。
我们引入了对话中的情绪原因识别任务,这个原因可能出现在当前话语或者历史话语中。
所做贡献如下所示:
- 我们提出了一个新的任务,并深入发掘了这个任务中的很多特性,而且定义了情绪原因的类型。
- 我们为这个任务构造了一个数据集RECCON。
- 我们提出了两个极具挑战性的子任务和对应的基线。
相关工作
主要是文本中的情感识别以及文本中的情绪原因识别(ECE和ECPE),而且在数据集中标注了多个片段来充分表示原因,同时提供了负样本:不包含原因片段的上下文。
作者在这块提到了数据集标注中遇到的挑战,包括:对话中的情绪并不总是显示的;对话非正式,很多原因是隐式的,需要推理;原因很可能距离目标华语非常远,识别它需要复杂的推理和指代消解。
任务定义
目标话语Ut、对话历史H(Ut)、原因片段集合CS(U)、utterane-causal span(UCS) pair即话语-原因片段对,S属于CS(U)。
该任务的目标是识别出给定文本中的所有的UCS对。如果这个对中的S属于CS(U),那么这个对就是positive example,如果不属于,那么这个对就是negative example。
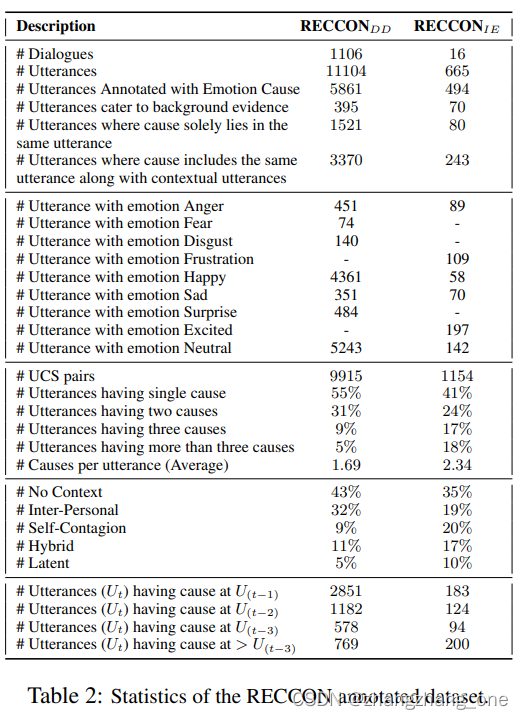
构造RECCON数据集
考虑数据集:IEMOCAP和DailyDialog,两个数据集都有话语级的情感标签。
IEMOCAP是两人对话数据集,使用6个情感标签:happy,sad,netural,anger,excited,frustrated。数据集中的每个对话超过50个话语。
DailyDialog是一个覆盖日常生活话题的人类自然对话数据集,使用7个情感标签:anger,disgust,fear,happy,netural,sad,surprise。但是这个数据集超过83%都是中性标签,所以我们随机选择至少有4个非中性话语的对话。数据集中的每个对话平均8个话语。
标注者要求抽取原因片段,如果原因是隐式的,那么标注者将认为的原因写下来。每个话语由两个标注者标注。标注分成两个阶段,阶段1通过majority voting来决定哪个话语是原因话语,阶段2进行span-level的标注,我们会选择片段的并集作为最终原因片段,如果两个片段不重合,那么引入第三个标注者来决定最终的片段。
计算卡帕和宏F1来说明标注结果。
情绪原因的类型
根据原因的来源不同,观察到5种主要的类型:
- No Context:原因显示地出现在目标话语当中。
- Inter-personal Emotional Influence:原因出现在另一个说话者话语中,两种子类型:一种是另一个说话者提到地事件或概念;另一种是受到另一个说话者对于某些事件或场景地情绪影响。
- Self-Contagion:自我情绪的传染,很多情况下,说话者会保持之前对话轮次的情绪。
- Hybrid:第二种类型和第三种类型联合引发了情绪。
- Unmentioned Latent Cause:目标话语及其对话历史中找不到显示的原因。
实验
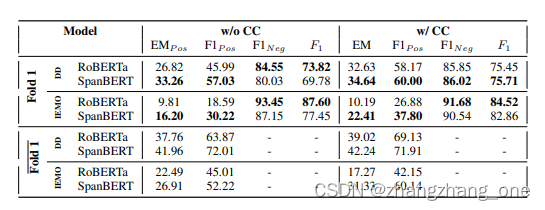
任务1:Causal Span Extraction
任务1旨在识别目标话语的情绪原因片段。在我们的实验设置中,我们将该任务形式化为机器阅读理解任务,并提出两种片段抽取设置:带有上下文;不带上下文。
- With Conversational Context:我们将构造实例(Context,Question,Answer),其中目标话语的对话历史中的所有话语拼接作为Context;

CS(Ut)中的Span作为Answer。 - Without Conversational Context:此时Context只有Ui。
模型
- RoBERTa Base:我们使用roberta-base和一个作用与隐藏层状态上的线性层用于计算开始和结束的位置。
- SpanBERT Fine-tuned on SQuAD:我们使用在SQuAD 2.0上微调的SpanBERT base模型作为第二个基线模型。
评价指标有EMpos、F1pos、F1neg、F1。
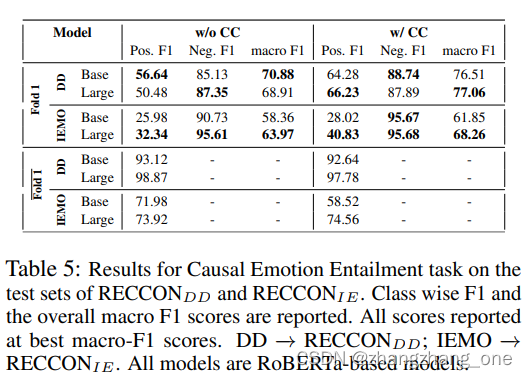
任务2:Causal Emotion Entailment
任务2旨在识别出对话历史中触发目标话语情绪的原因话语。跟任务1的两种设置相同:带有上下文和不带上下文。
- With Conversationnal Context:我们将这个问题看作一个三元做分类问题,三元组为(Ut,Ui,H(Ut)),如果Ui是原因话语,那么三元组分类为positive,否则为negative。
- Without Conversational Context:二元句子对分类任务,(Ut,Ui)被分类为positive如果Ui为原因话语,否则为negative。
模型
- Roberta Base/Large
评价指标为Pos.F1、Neg.F1、macro F1。
面临的挑战
- 片段的数量:能够充分抽取出触发情绪的原因片段的集合是一个主要的挑战,这些片段应该能够形成一个逻辑推理。
- 情绪的动态性:理解对话中的情绪动态性对于原因识别很重要,我们可以观察到很多对话中的原因是由另一个说话者谈到的事件或概念引起,或者是自我的一个影响。并且我们也可以看到它有时距离目标话语很多轮次远,因此还需要具有建模长期信息的能力。而且在标注中发现,情感信息非常重要。
- 常识知识:常识知识在抽取情绪原因中发挥着重要作用,尤其当情绪原因是隐式的。
- 复杂的共指消解:对话中的指代关系经常隐式。
- 对话的非正式性和复杂的特性使得抽取出的原因并非最exact,而是perceived cause。