31.PDR模型与访问控制的主要区别(A)
A、PDR把对象看作一个整体
B、PDR作为系统保护的第一道防线
C、PDR采用定性评估与定量评估相结合
D、PDR的关键因素是人
32.信息安全中PDR模型的关键因素是(A)
A、人
B、技术
C、模型
D、客体
33.计算机网络最早出现在哪个年代(B)
A、20世纪50年代
B、20世纪60年代
C、20世纪80年代
D、20世纪90年代
34.最早研究计算机网络的目的是什么?( C )
A、直接的个人通信;
B、共享硬盘空间、打印机等设备;
C、共享计算资源;
D、大量的数据交换。
35.最早的计算机网络与传统的通信网络最大的区别是什么?(B)
A、计算机网络带宽和速度大大提高。
B、计算机网络采用了分组交换技术。
C、计算机网络采用了电路交换技术
D、计算机网络的可靠性大大提高。
36.关于80年代Mirros 蠕虫危害的描述,哪句话是错误的?(B)
A、该蠕虫利用Unix系统上的漏洞传播
B、窃取用户的机密信息,破坏计算机数据文件
C、占用了大量的计算机处理器的时间,导致拒绝服务
D、大量的流量堵塞了网络,导致网络瘫痪
37.以下关于DOS攻击的描述,哪句话是正确的?( C )
A、不需要侵入受攻击的系统
B、以窃取目标系统上的机密信息为目的
C、导致目标系统无法处理正常用户的请求
D、如果目标系统没有漏洞,远程攻击就不可能成功
38.许多黑客攻击都是利用软件实现中的缓冲区溢出的漏洞,对于这一威胁,最可靠的解决方案是什么?( C )
A、安装防火墙
B、安装入侵检测系统
C、给系统安装最新的补丁
D、安装防病毒软件
39.下面哪个功能属于操作系统中的安全功能 ( C )
A、控制用户的作业排序和运行
B、实现主机和外设的并行处理以及异常情况的处理
C、保护系统程序和作业,禁止不合要求的对程序和数据的访问
D、对计算机用户访问系统和资源的情况进行记录
40.下面哪个功能属于操作系统中的日志记录功能(D)
A、控制用户的作业排序和运行
B、以合理的方式处理错误事件,而不至于影响其他程序的正常运行
C、保护系统程序和作业,禁止不合要求的对程序和数据的访问
D、对计算机用户访问系统和资源的情况进行记录
42.Windows NT提供的分布式安全环境又被称为(A)
A、域(Domain)
B、工作组
C、对等网
D、安全网
43.下面哪一个情景属于身份验证(Authentication)过程(A)
A、用户依照系统提示输入用户名和口令
B、用户在网络上共享了自己编写的一份Office文档,并设定哪些用户可以阅读,哪些用户可以修改
C、用户使用加密软件对自己编写的Office文档进行加密,以阻止其他人得到这份拷贝后看到文档中的内容
D、某个人尝试登录到你的计算机中,但是口令输入的不对,系统提示口令错误,并将这次失败的登录过程纪录在系统日志中
44.下面哪一个情景属于授权(Authorization)(B)
A、用户依照系统提示输入用户名和口令
B、用户在网络上共享了自己编写的一份Office文档,并设定哪些用户可以阅读,哪些用户可以修改
C、用户使用加密软件对自己编写的Office文档进行加密,以阻止其他人得到这份拷贝后看到文档中的内容(D、某个人尝试登录到你的计算机中,但是口令输入的不对,系统提示口令错误,并将这次失败的登录过程纪录在系统日志中
45.下面哪一个情景属于审计(Audit)(D)
A、用户依照系统提示输入用户名和口令
B、用户在网络上共享了自己编写的一份Office文档,并设定哪些用户可以阅读,哪些用户可以修改
C、用户使用加密软件对自己编写的Office文档进行加密,以阻止其他人得到这份拷贝后看到文档中的内容
D、某个人尝试登录到你的计算机中,但是口令输入的不对,系统提示口令错误,并将这次失败的登录过程纪录在系统日志中
46.以网络为本的知识文明人们所关心的主要安全是( C )
A、人身安全
B、社会安全
C、信息安全
47.第一次出现"HACKER"这个词是在(B)
A、BELL实验室
B、麻省理工AI实验室
C、AT&T实验室
48.可能给系统造成影响或者破坏的人包括(A)
A、所有网络与信息系统使用者
B、只有黑客
C、只有跨客
49.黑客的主要攻击手段包括(A)
A、社会工程攻击、蛮力攻击和技术攻击
B、人类工程攻击、武力攻击及技术攻击
C、社会工程攻击、系统攻击及技术攻击
50.从统计的情况看,造成危害最大的黑客攻击是( C )
A、漏洞攻击
B、蠕虫攻击
C、病毒攻击
51.第一个计算机病毒出现在(B)
A、40年代
B、70 年代
C、90年代
52.口令攻击的主要目的是(B)
A、获取口令破坏系统
B、获取口令进入系统
C、仅获取口令没有用途
53.通过口令使用习惯调查发现有大约___%的人使用的口令长度低于5个字符的(B)
A、50.5
B、51. 5
C、52.5
54.通常一个三个字符的口令破解需要(B)
A、18毫秒
B、18 秒
C、18分
55.黑色星期四是指(A)
A、1998年11月3日星期四
B、1999年6月24日星期四
C、2000年4月13日星期四
56.大家所认为的对Internet安全技术进行研究是从_______时候开始的( C )
A、Internet 诞生
B、第一个计算机病毒出现
C、黑色星期四
57.计算机紧急应急小组的简称是(A)
A、CERT
B、FIRST
C、SANA
58.邮件炸弹攻击主要是(B)
A、破坏被攻击者邮件服务器
B、添满被攻击者邮箱
C、破坏被攻击者邮件客户端
59.逻辑炸弹通常是通过(B)
A、必须远程控制启动执行,实施破坏
B、指定条件或外来触发启动执行,实施破坏
C、通过管理员控制启动执行,实施破坏
60.1996年上海某寻呼台发生的逻辑炸弹事件,造事者被判"情节轻微,无罪释放"是因为( C )
A、证据不足
B、没有造成破坏
C、法律不健全
网络安全学习路线
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。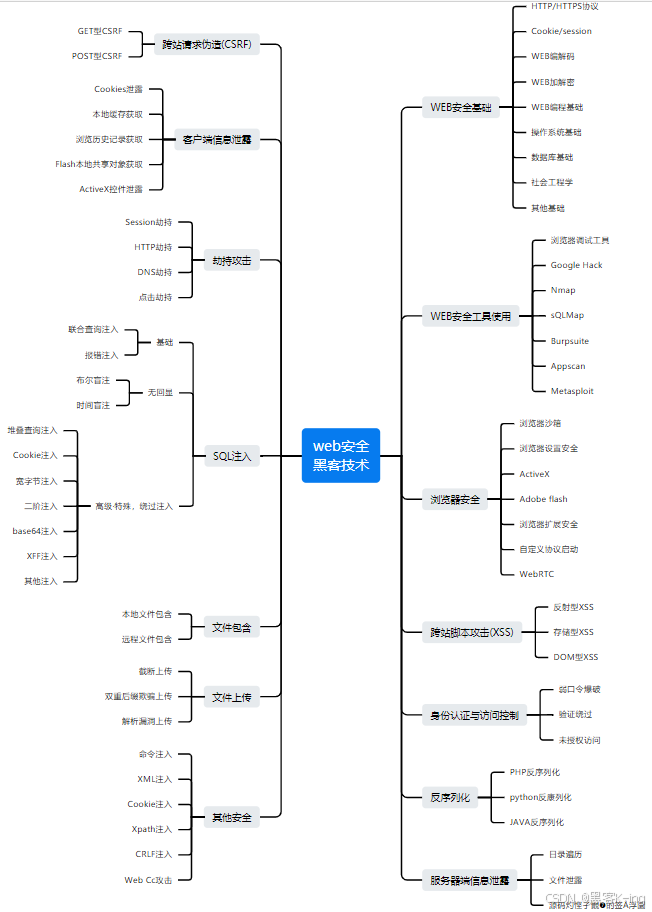
同时每个成长路线对应的板块都有配套的视频提供:
网络安全产业就像一个江湖,各色人等聚集。相对于欧美国家基础扎实(懂加密、会防护、能挖洞、擅工程)的众多名门正派,我国的人才更多的属于旁门左道(很多白帽子可能会不服气),因此在未来的人才培养和建设上,需要调整结构,鼓励更多的人去做“正向”的、结合“业务”与“数据”、“自动化”的“体系、建设”,才能解人才之渴,真正的为社会全面互联网化提供安全保障。
特别声明:
此教程为纯技术分享!本教程的目的决不是为那些怀有不良动机的人提供及技术支持!也不承担因为技术被滥用所产生的连带责任!本教程的目的在于最大限度地唤醒大家对网络安全的重视,并采取相应的安全措施,从而减少由网络安全而带来的经济损失