ElasticSearch客户端操作
ElasticSearch
版本:7.8 学习视频:尚硅谷
笔记:https://zgtsky.top/
实际开发中,主要有三种方式可以作为elasticsearch服务的客户端:
-
第一种,使用elasticsearch提供的Restful接口直接访问
-
第二种,elasticsearch-head插件
-
第三种,使用elasticsearch提供的API进行访问
ElasticSearch的接口语法

Elasticsearch提供了基于JSON的完整查询DSL(Domain Specific Language领域特定语言)来定义查询。将查询DSL视为查询的AST(抽象语法树),它由两种子句组成:
- 叶子查询子句:
叶查询子句中寻找一个特定的值在某一特定领域,如 match,term或 range查询。这些查询可以自己使用。
- 复合查询子句
复合查询子句包装其他叶查询或复合查询,并用于以逻辑方式组合多个查询(例如 bool或dis_max查询),或更改其行为(例如 constant_score查询)。
我们在使用ElasticSearch的时候,避免不了使用DSL语句去查询,就像使用关系型数据库的时候要学会SQL语法一样。如果我们学习好了DSL语法的使用,那么在日后使用和使用Java Client调用时候也会变得非常简单。
Postman
操作索引 index

创建索引
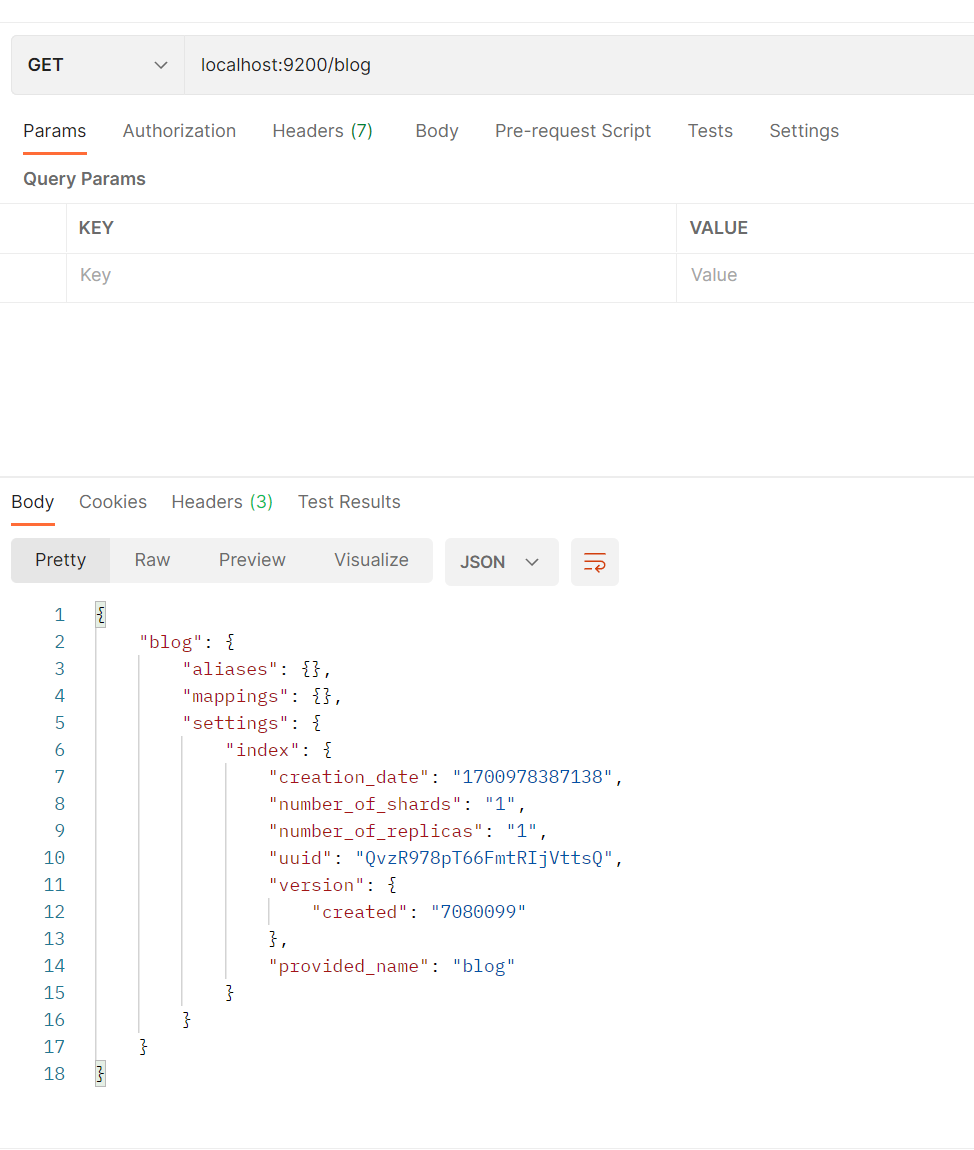
请求url:put localhost:9200/blog
发送请求,响应数据

elasticsearch-head查看:请求localhost:9200

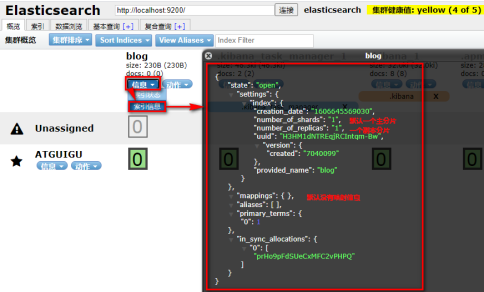
如果重复创建索引,会报错:

查看索引
get localhost:9200/log
删除索引
delete localhost:9200/blog
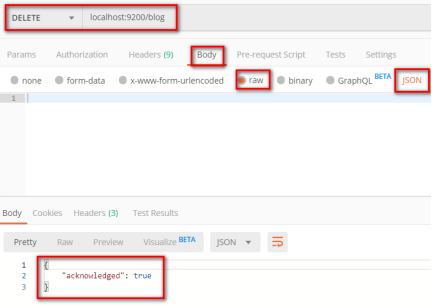
关闭索引
post localhost:9200/blog/_close


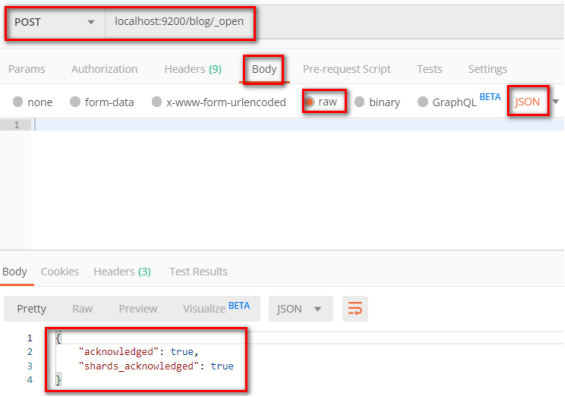
打开索引
post localhost:9200/blog/_open

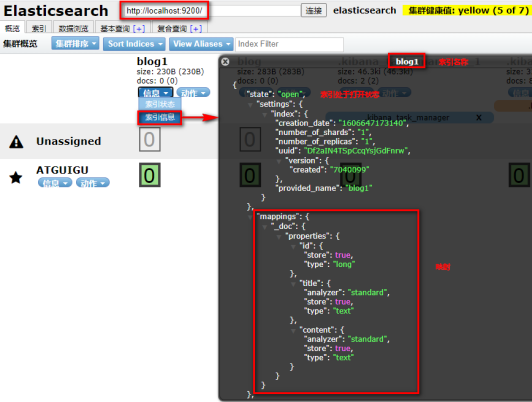
创建索引index并且进行映射mapping
请求url :PUT localhost:9200/blog1请求体:{"mappings": {"properties": {"id": {"type": "long","store": true,"index":true},"title": {"type": "text","store": true,"index":true,"analyzer":"standard"},"content": {"type": "text","store": true,"index":true,"analyzer":"standard"}}}
}
注意:
key需要使用双引号,不可以省略
mappings、properties等都是关键字,区分大小写
mapping中的字段类型一旦设置,禁止直接修改,因为 lucene实现的倒排索引生成后不允许修改,应该重新建立新的索引,然后做reindex操作。
如果没有mapping所有text类型属性默认都使用standard分词器。所以如果希望使用IK分词就必须配置自定义mapping。
store含义:默认false。当某个数据字段很大,我们可以指定其它字段store为true,这样就不用从_source中取数据。 store 的意思是,是否在 _source 之外在独立存储一份。当你索引数据的时候, elasticsearch 会保存一份源文档到 _source ,如果文档的某一字段设置了 store 为 true,这时候会在 _source 存储之外再为这个字段独立进行存储,这么做的目的主要是针对内容比较多的字段,放到 _source 返回的话,因为_source 是把所有字段保存为一份文档,命中后读取只需要一次IO,包含内容特别多的字段会很占带宽影响性能,通常我们也不需要完整的内容返回(可能只关心摘要),这时候就没必要放到 _source 里一起返回了(当然也可以在查询时指定返回字段)。
index含义:默认值是true。es默认大多数及常用数据字段类型就是索引的,这也是es职责之所在,但是有时会有部分字段只是做存储,不做检索,这也会提高es性能。

elasticsearch-head查看:
kibana
操作索引和映射
# 创建索引
PUT person
# 查询索引
GET person
# 删除索引
DELETE person# 查询映射
GET person/_mapping# 添加映射
PUT person/_mapping
{"properties":{"name":{"type":"keyword"},"age":{"type":"integer"}}
}
# ------------------------------------------------
# 创建索引并添加映射
PUT person
{"mappings": {"properties": {"name":{"type": "keyword"},"age":{"type":"integer"}}}
}
# 索引库中添加字段
PUT person/_mapping
{"properties":{"address":{"type":"text"}}
}
# 判断索引是否存在
HEAD person
打开kibana,在此操作。前提是elasticsearch也在开着。


操作文档document
• 添加文档
• 查询文档
• 修改文档
• 删除文档
• 判断文档是否存在
# 查询索引
GET person# 添加文档,指定id
PUT person/_doc/1
{"name":"张三","age":20,"address":"深圳宝安区"
}# 查询文档
GET person/_doc/1# 添加文档,不指定id,自动生成id
POST person/_doc/
{"name":"李四","age":20,"address":"深圳南山区"
}
# 查询文档
GET person/_doc/u8b2QHUBCR3n8iTZ8-Vk# 添加文档,不指定id,自动生成id
POST person/_doc
{"name":"李四","age":20,"address":"深圳南山区"
}
# 查询文档
GET person/_doc/u8b2QHUBCR3n8iTZ8-Vk# 查询所有文档
GET person/_search# 删除文档
DELETE person/_doc/1# 修改文档 根据id,id存在就是修改,id不指定报405请求方式不支持,使用POST方式
PUT person/_doc/2
{"name":"硅谷","age":20,"address":"深圳福田保税区"
}
#如果我们只需要判断文档是否存在,而不是查询文档内容,那么可以这样:
HEAD shangguigu/_doc/1001
#存在返回:200 - OK
#不存在返回:404 – Not Found
注意:
put:id存在是修改(以现在提供字段为全部字段),id不存在是添加
post:id存在是添加,id不存在自动生成id,
查询全部
GET person/_search
GET person/_search
{"query": {"match_all": {}}
}
全文查询-match查询
全文查询会分析查询条件,先将查询条件进行分词,然后查询,求并集
# match 先会对查询的字符串进行分词,在查询,求并集
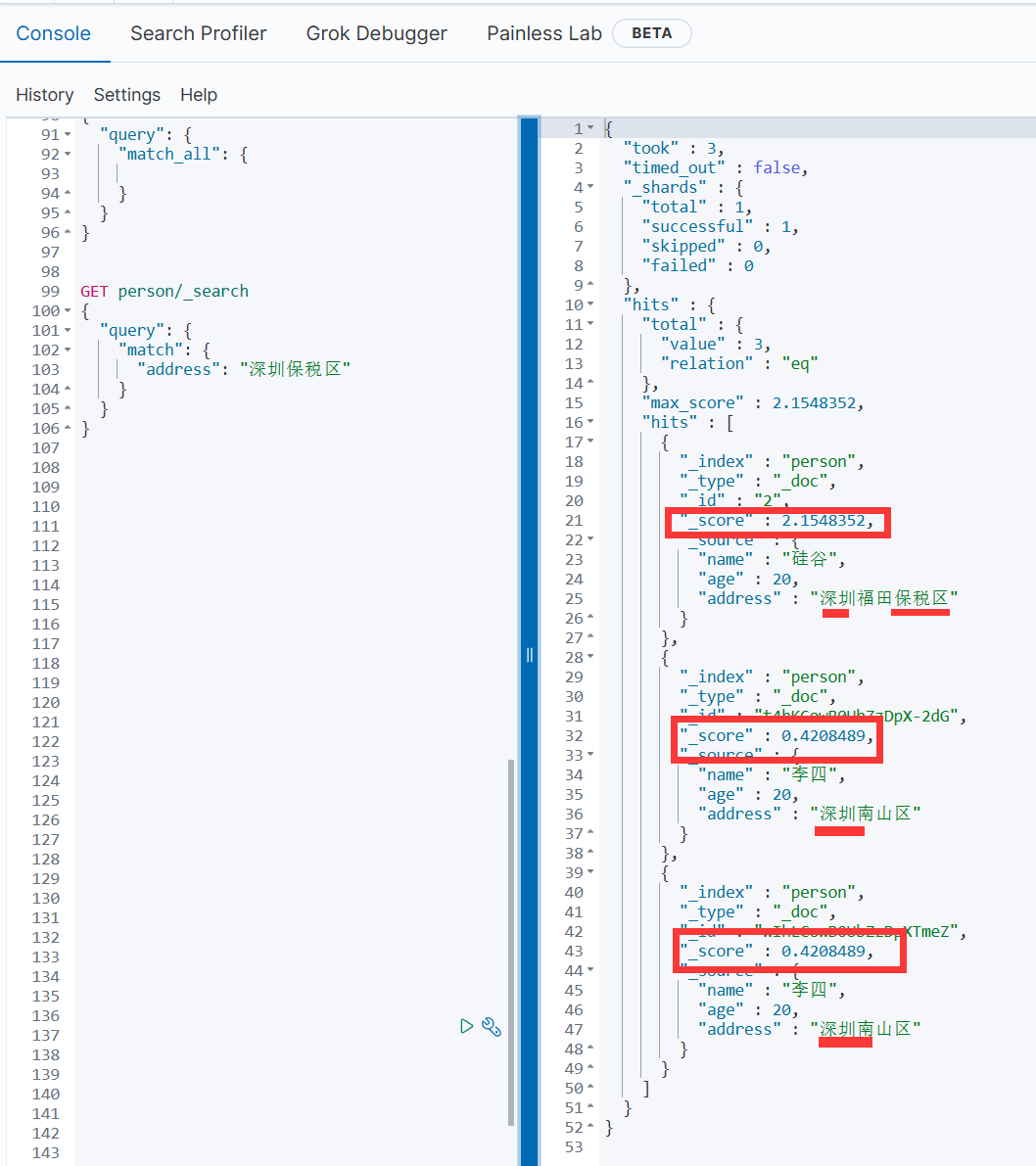
GET person/_search
{"query": {"match": {"address": "深圳保税区"}}
}
结果按照得分进行排序
查询文档-term查询
词条查询不会分析查询条件,只有当词条和查询字符串完全匹配时才匹配搜索。term主要用于精确匹配哪些值,比如数字,日期,布尔值或 not_analyzed 的字符串(未经分析的文本数据类型)
# 查询所有数据
GET person/_search# 查询 带某词条的数据
GET person/_search
{"query": {"term": {"address": {"value": "深圳南山区"}}}
}
这个结果与使用的分词器有关。根据address字段,建立倒排索引时,需要对其分词,产生多个词条,而词条集合中没有"深圳南山区"的词条,故而查询不到数据。

大家可以查询“深”或“南山区”或“深圳”试试。
这里之前没有指定ik分词器,所以中文都是一个一个的,此处用 深 可以查出。

注意:
默认情况下,hits.total.value是不确切的命中计数,当hits.total.relation的值是eq时,hits.total.value的值是准确计数。
当hits.total.relation的值是gte时,hits.total.value的值是不准确的。
hits.hits 是存储搜索结果的实际数组(默认为前10个文档)
terms查询
terms 跟 term 有点类似,但 terms 允许指定多个匹配条件。 如果某个字段指定了多个值,那么文档需要一起去做匹配:
POST person/_search
{"query" : {"terms" : { "age" : [20,21]}}
}
exists 查询
exists 查询可以用于查找文档中是否包含指定字段或没有某个字段,类似于SQL语句中的 IS_NULL 条件
# "exists": 必须包含
POST person/_search
{"query": {"exists": { "field": "name"}}
}
range查询
range 过滤允许我们按照指定范围查找一批数据:
范围操作符包含:
gt :: 大于
gte :: 大于等于
lt :: 小于
lte :: 小于等于
POST person/_search
{"query": {"range": {"age": {"gte": 20,"lte": 22}}}
}
复合查询(bool)
复合查询就是多条件查询
GET 索引名/类型名/_search
{"query": {"bool": {"must": [ #数组中的多个条件必须同时满足{"range": {"字段名": {"lt": 条件}}}],"must_not":[ #数组中的多个条件必须都不满足{"match": {"字段名": "条件"}},{"range": {"字段名": {"gte": "搜索条件"}}}],"should": [# 数组中的多个条件有任意一个满足即可。{"match": {"字段名": "条件"}},{"range": {"字段名": {"gte": "搜索条件"}}}]}}
}
bool 可以用来合并多个过滤条件查询结果的布尔逻辑,它包含这如下几个操作符:
· must : 多个查询条件的完全匹配,相当于 and,有评分。
· filter: 多个查询条件的完全匹配,相当于 and,无评分。
· must_not ::多个查询条件的相反匹配,相当于 not。
· should : 至少有一个查询条件匹配, 相当于 or。
多添加数据,方便展示
PUT person/_doc/1001
{"id":"1001","name":"张三","age":20,"sex":"男"
}
PUT person/_doc/1002
{"id":"1002","name":"李四","age":25,"sex":"女"
}PUT person/_doc/1003
{"id":"1003","name":"王五","age":30,"sex":"女"
}PUT person/_doc/1004
{"id":"1004","name":"赵六","age":30,"sex":"男"
}GET person/_search
复合查询示例:
GET shangguigu/_search
{"query": {"bool": {"must": [{"range": {"age": {"gte": 25,"lte": 33}}},{"term": {"sex": {"value": "女"}}}],"must_not": [{"match": {"name": "王五"}}],"should": [{"exists": {"field": "address"}}]}}
}
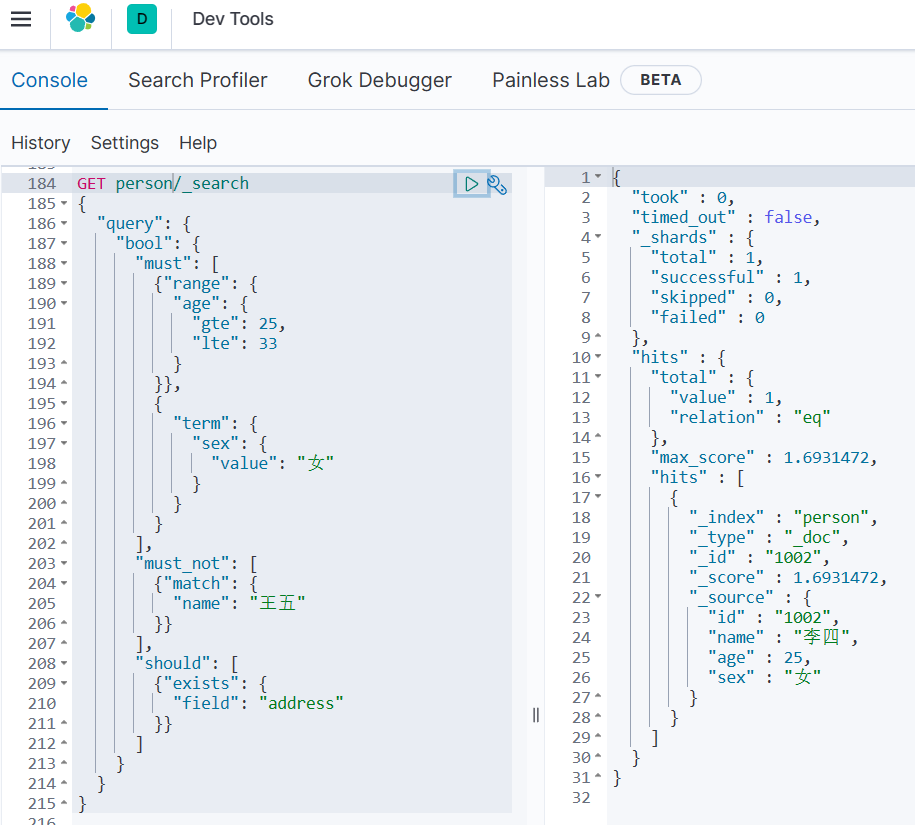
高亮显示
在浏览器搜索时,我们搜索的关键词汇,在给出的搜索列表里对应的词汇会高亮。
GET person/_search
{"query":{"match":{"name": "张三 李四"}},"highlight": {"fields": {"name": {}}}
}
扩展:可以自定义高亮的样式:
“pre_tags”: “”,
“post_tags”: “”

自定义样式
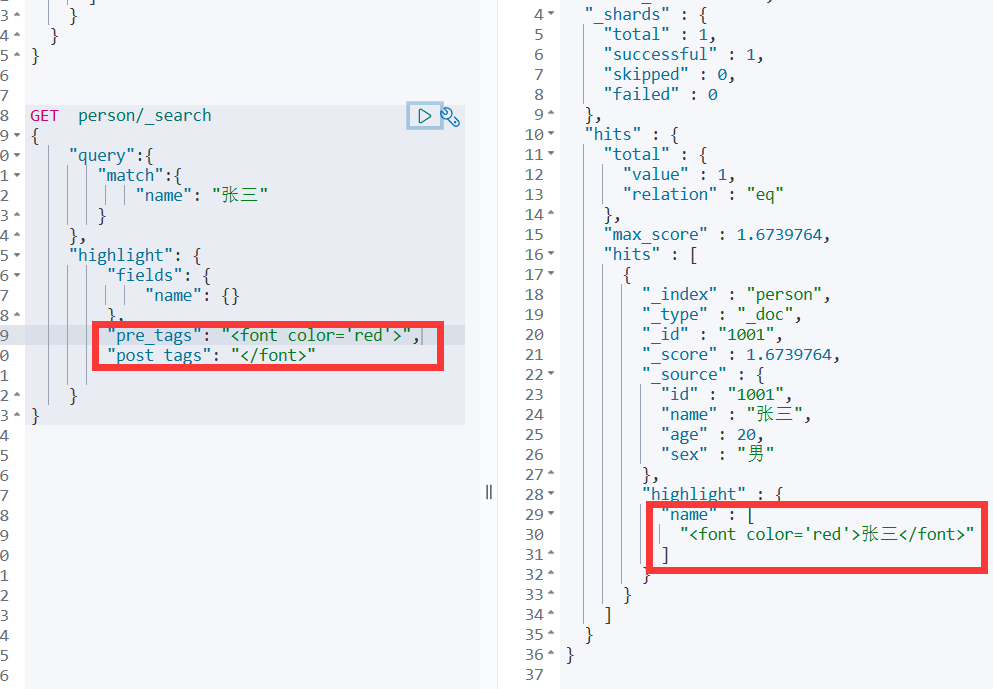
指定响应字段
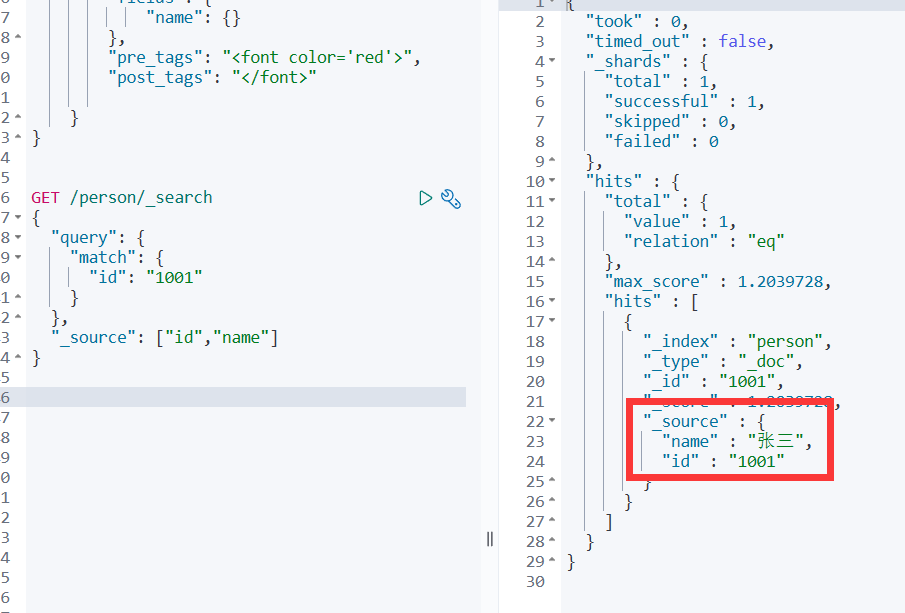
在响应的数据中,如果我们不需要全部的字段,可以指定某些需要的字段进行返回
GET person/_doc/1001?_source=id,name等价于GET /person/_search
{"query": {"match": {"id": "1001"}},"_source": ["id","name"]
}
聚合
在Elasticsearch中,支持聚合操作,类似SQL中的group by操作。
注意:
"all_ages"名称是任意的。
GET person/_search
{"aggs": {"all_ages": {"terms": {"field": "age"}}}
}

如果聚合查询报错:在es中,text类型的字段使用一种叫做fielddata的查询时内存数据结构。当字段被排序,聚合或者通过脚本访问时这种数据结构会被创建。它是通过从磁盘读取每个段的整个反向索引来构建的,然后存存储在java的堆内存中。fileddata默认是不开启的。Fielddata可能会消耗大量的堆空间,尤其是在加载高基数文本字段时。一旦fielddata已加载到堆中,它将在该段的生命周期内保留。此外,加载fielddata是一个昂贵的过程,可能会导致用户遇到延迟命中。这就是默认情况下禁用fielddata的原因。如果尝试对文本字段进行排序,聚合或脚本访问,将看到以下异常:
修改后的语句:
{"aggs": {"all_ages": {"terms": {"field": "age.keyword"}}} }

批量操作
有些情况下可以通过批量操作以减少网络请求。如:批量查询、批量插入数据。
- 批量查询
POST person/_doc/_mget
{"ids" : [ "1001", "1003" ]
}

如果,某一条数据不存在,不影响整体响应,需要通过found的值进行判断是否查询到数据。
1006 不存在
{"ids" : [ "1001", "1006" ]
}

- _bulk操作
在Elasticsearch中,支持批量的插入、修改、删除操作,都是通过_bulk的api完成的。
请求格式如下:(请求格式不同寻常)
不要有多余的空行
{ action: { metadata }}\n
{ request body }\n
{ action: { metadata }}\n
{ request body }\n
...
批量插入:
POST _bulk
{"create":{"_index":"person","_id":2001}}
{"id":2001,"name":"name1","age": 20,"sex": "男"}
{"create":{"_index":"person","_id":2002}}
{"id":2002,"name":"name2","age": 20,"sex": "男"}
{"create":{"_index":"person","_id":2003}}
{"id":2003,"name":"name3","age": 20,"sex": "男"}
批量删除:
由于delete没有请求体,所以,action的下一行直接就是下一个action。
POST _bulk
{"delete":{"_index":"atguigu","_id":2001}}
{"delete":{"_index":"atguigu","_id":2002}}
{"delete":{"_index":"atguigu","_id":2003}}
分页
和SQL使用 LIMIT 关键字返回只有一页的结果一样,Elasticsearch接受 from 和 size 参数:
插入数据:
size: 结果数,默认10
from: 跳过开始的结果数,默认0
POST person/_bulk
{"index":{"_index":"person"}}
{"name":"张三","age": 20,"mail": "111@qq.com","hobby":"羽毛球、乒乓球、足球"}
{"index":{"_index":"person"}}
{"name":"李四","age": 21,"mail": "222@qq.com","hobby":"羽毛球、乒乓球、足球、篮球"}
{"index":{"_index":"person"}}
{"name":"王五","age": 22,"mail": "333@qq.com","hobby":"羽毛球、篮球、游泳、听音乐"}
{"index":{"_index":"person"}}
{"name":"赵六","age": 23,"mail": "444@qq.com","hobby":"跑步、游泳"}
{"index":{"_index":"person"}}
{"name":"孙七","age": 24,"mail": "555@qq.com","hobby":"听音乐、看电影"}
测试分页:
POST person/_search
{"query" : {"match" : { "hobby" : "音乐 羽毛球"}},"from": 0,"size": 2
}
注意事项:批量操作中index和create区别
- index 和 create 都会检查 _version 版本号。
- index 插入时分两种情况:
- 没有指定 _version,那对于已有的doc,_version会递增,并对文档覆盖。
- 指定_version,如果与已有的文档 _version 不相等,则插入失败;如果相等则覆盖,_version递增。
- create 插入时对于已有的文档,不会创建新文档,即插入失败,会抛出一个已经存在的异常。
通过查询字符串搜索数据
ElasticSearch除了提供DSL查询语法之外,还提供了query string search。
query string search:search的参数都是类似http请求头中的字符串参数提供搜索条件的。GET [/index_name/]_search[?parameter_name=parameter_value&…]
query DSL:请求参数以JSON形式提供,是在请求体传递的。在Elasticsearch中,请求体的字符集默认为UTF-8。
# 查询名字等于张三的用户
GET person/_search?q=name:张三
# 查询所有字段中带张三的用户
GET person/_search?q=张三

如果你想每页显示5个结果,页码从1到3,那请求如下:
GET person/_search?size=5
GET person/_search?size=5&from=5
GET person/_search?size=5&from=10
排序:
GET person/_search?size=1&from=2
GET person/_search?sort=age:desc
GET person/_search?size=5&sort=age:desc
重建索引
随着业务需求的变更,索引的结构可能发生改变。
ElasticSearch的索引一旦创建,只允许添加字段,不允许改变字段。因为改变字段,需要重建倒排索引,影响内部缓存结构,性能太低。
那么此时,就需要重建一个新的索引,并将原有索引的数据导入到新索引中。
原索引库 :student_index_v1
新索引库 :student_index_v2
# 新建student_index_v1索引,索引名称必须全部小写
PUT student_index_v1
{"mappings": {"properties": {"birthday":{"type": "date"}}}
}
# 查询索引
GET student_index_v1
# 添加数据
PUT student_index_v1/_doc/1
{"birthday":"2020-11-11"
}
# 查询数据
GET student_index_v1/_search
# 随着业务的变更,换种数据类型进行添加数据,程序会直接报错
PUT student_index_v1/_doc/1
{"birthday":"2020年11月11号"
}
# 业务变更,需要改变birthday数据类型为text
# 1:创建新的索引 student_index_v2
# 2:将student_index_v1 数据拷贝到 student_index_v2# 创建新的索引
PUT student_index_v2
{"mappings": {"properties": {"birthday":{"type": "text"}}}
}DELETE student_index_v2
# 2:将student_index_v1 数据拷贝到 student_index_v2
POST _reindex
{"source": {"index": "student_index_v1"},"dest": {"index": "student_index_v2"}
}
# 查询新索引库数据
GET student_index_v2/_search
# 在新的索引库里面添加数据
PUT student_index_v2/_doc/2
{"birthday":"2020年11月13号"
}
ElasticSearch集群搭建
相关概念
单节点故障问题
-
单台服务器,往往都有最大的负载能力,超过这个阈值,服务器性能就会大大降低甚至不可用。单点的elasticsearch也是一样,那单点的es服务器存在哪些可能出现的问题呢?
-
单台机器存储容量有限
-
单服务器容易出现单点故障,无法实现高可用
-
单服务的并发处理能力有限
-
所以,为了应对这些问题,我们需要对elasticsearch搭建集群
- 集群中节点数量没有限制,大于等于2个节点就可以看做是集群了。一般出于高性能及高可用方面来考虑集群中节点数量都是3个以上。
集群的相关概念
**1)**集群 cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来
加入这个集群。
2) 节点 node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。
一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于
ElasticSearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地
形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
分片和复制 shards&replicas
一个索引可以存储超出单个节点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,ElasticSearch提供了将索引划分
成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片很重要,主要有两方面的原因:
1)允许你水平分割/扩展你的内容容量。
2)允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由ElasticSearch管理的,对于作为用户的你来说,这些都是透明的。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,ElasticSearch允许你创建分片的一份或多
份拷贝,这些拷贝叫做复制分片( 副本)。
复制之所以重要,有两个主要原因: 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上
并行运行。
总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指
定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是存储数据后不能改变分片的数量。
默认情况下:
Elasticsearch6.x中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。
Elasticsearch7.x中的每个索引被分片1个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有1个主分片和另外1个复制分片(1个完全拷贝),这样的话每个索引总共就有2个分片。
集群搭建
- 准备三台elasticsearch服务器
创建elasticsearch-cluster文件夹,在内部复制三个elasticsearch服务
-
修改每台服务器配置
修改elasticsearch-cluster\node*\config\elasticsearch.yml配置文件
node1节点:按照(新)的来,discovery.zen.ping.unicast.hosts这个参数用discovery.seed_hosts替换
#节点1的配置信息:
#集群名称,保证唯一
cluster.name: my-elasticsearch#默认为true。设置为false禁用磁盘分配决定器。
cluster.routing.allocation.disk.threshold_enabled: false
#节点名称,必须不一样
node.name: node-1
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9201
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9301
#设置集群自动发现机器ip集合
#discovery.zen.ping.unicast.hosts: [“127.0.0.1:9301”,“127.0.0.1:9302”,“127.0.0.1:9303”]#(新)# es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
# es7之后,不需要上面discovery.zen.ping.unicast.hosts这个参数,用discovery.seed_hosts替换
# discovery.zen.ping.unicast.hosts: [“10.19.1.9:9200”,“10.19.1.10:9200”,“10.19.1.11:9200”]
discovery.seed_hosts: [“127.0.0.1:9301”,“127.0.0.1:9302”,“127.0.0.1:9303”]
# es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: [“node-1”]
node2节点:
#节点2的配置信息:
#集群名称,保证唯一
cluster.name: my-elasticsearch#默认为true。设置为false禁用磁盘分配决定器。
cluster.routing.allocation.disk.threshold_enabled: false
#节点名称,必须不一样
node.name: node-2
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9202
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9302
#设置集群自动发现机器ip集合
#discovery.zen.ping.unicast.hosts: [“127.0.0.1:9301”,“127.0.0.1:9302”,“127.0.0.1:9303”]#(新)
# es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
# es7之后,不需要上面discovery.zen.ping.unicast.hosts这个参数,用discovery.seed_hosts替换
# discovery.zen.ping.unicast.hosts: [“10.19.1.9:9200”,“10.19.1.10:9200”,“10.19.1.11:9200”]
discovery.seed_hosts: [“127.0.0.1:9301”,“127.0.0.1:9302”,“127.0.0.1:9303”]
# es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: [“node-1”]
node3节点:
#节点3的配置信息:
#集群名称,保证唯一
cluster.name: my-elasticsearch#默认为true。设置为false禁用磁盘分配决定器。
cluster.routing.allocation.disk.threshold_enabled: false
#节点名称,必须不一样
node.name: node-3
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9203
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9303
#设置集群自动发现机器ip集合
#discovery.zen.ping.unicast.hosts: [“127.0.0.1:9301”,“127.0.0.1:9302”,“127.0.0.1:9303”]#(新)
# es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
# es7之后,不需要上面discovery.zen.ping.unicast.hosts这个参数,用discovery.seed_hosts替换
# discovery.zen.ping.unicast.hosts: [“10.19.1.9:9200”,“10.19.1.10:9200”,“10.19.1.11:9200”]
discovery.seed_hosts: [“127.0.0.1:9301”,“127.0.0.1:9302”,“127.0.0.1:9303”]
# es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: [“node-1”]
-
启动各个节点服务器
先清理掉之前数据:删除elasticsearch-cluster\node*\data目录下的nodes目录 这个目录很有必要删除,没删除时,集群不成功,elasticsearch head插口看不到集群
在各个节点安装ik分词器
双击elasticsearch-cluster\node*\bin\elasticsearch.bat
启动节点1:
启动节点2:
启动节点3:

集群测试
- 使用elasticsearch-head查看集群情况
地址栏通过http://localhost:9201/,http://localhost:9202/,http://localhost:9203分别查看集群中节点情况。
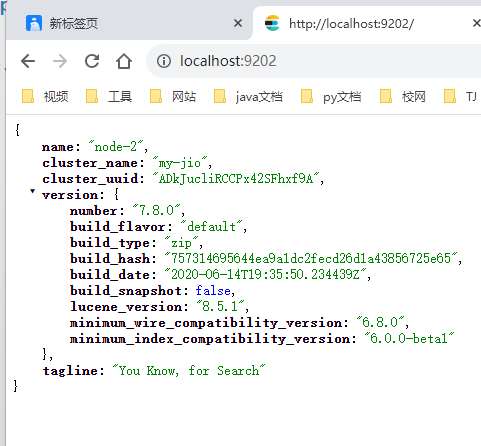
浏览器elasticsearch head插件中通过http://localhost:9201/,http://localhost:9202/,http://localhost:9203分别访问集群。可以看到3个节点,一切正常(绿色)。没有任何索引。
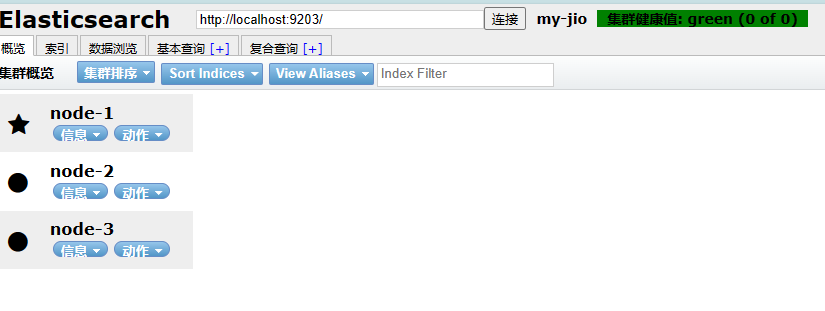
- 安装kibana连接集群
修改kibana的conf/kibana.yml中配置
#elasticsearch.hosts: [“http://localhost:9200”]
elasticsearch.hosts: [“http://localhost:9201”,“http://localhost:9202”,“http://localhost:9203”]
双击bin/kibana.bat确定kibana。
再次通过浏览器elasticsearch head插件访问集群

- 集群测试
创建索引及映射
# 请求方法:PUT
PUT /shopping
{"settings": {},"mappings": {"properties": {"title":{"type": "text","analyzer": "ik_max_word"},"subtitle":{"type": "text","analyzer": "ik_max_word"},"images":{"type": "keyword","index": false},"price":{"type": "float","index": true}}}
}
添加文档
POST /shopping/_doc/1
{"title":"小米手机","images":"http://www.gulixueyuan.com/xm.jpg","price":3999.00
}
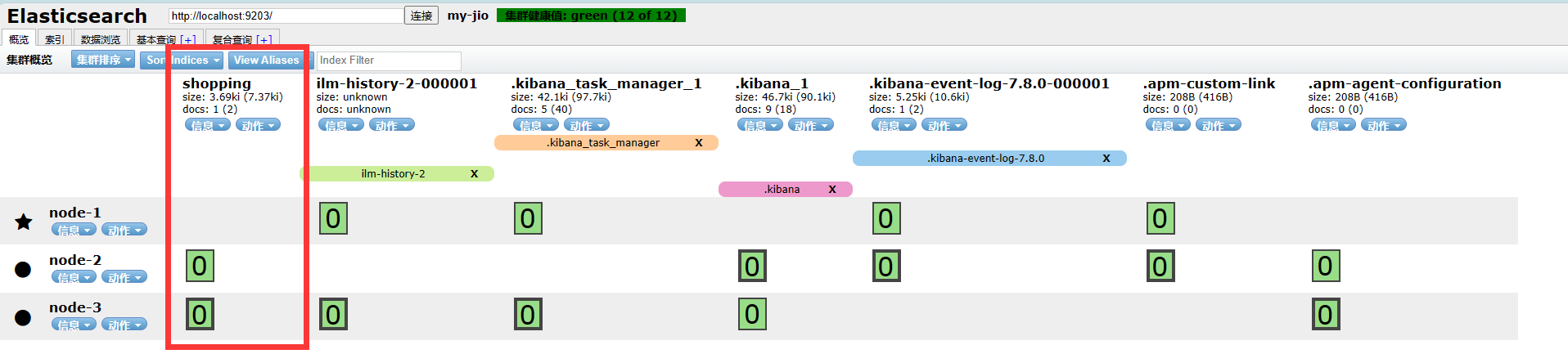
- 再次使用elasticsearch-head查看集群情况
GET _cluster/health
{
“cluster_name” : “my-jio”,
“status” : “green”,
“timed_out” : false,
“number_of_nodes” : 3,
“number_of_data_nodes” : 3,
“active_primary_shards” : 7,
“active_shards” : 14,
“relocating_shards” : 0,
“initializing_shards” : 0,
“unassigned_shards” : 0,
“delayed_unassigned_shards” : 0,
“number_of_pending_tasks” : 0,
“number_of_in_flight_fetch” : 0,
“task_max_waiting_in_queue_millis” : 0,
“active_shards_percent_as_number” : 100.0
}
- Elasticsearch-head查看:
服务器运行状态:
Green
所有的主分片和副本分片都已分配。你的集群是 100% 可用的。
yellow
所有的主分片已经分片了,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依然是完整的。不过,你的高可用性在某种程度上被弱化。如果 更多的 分片消失,你就会丢数据了。把 yellow 想象成一个需要及时调查的警告。
red
至少一个主分片(以及它的全部副本)都在缺失中。这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。