- List item
文章目录
- ⭐️写在前面的话⭐️
- 📌What is it?
- 分类
- 网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫(General Purpose Web Crawler)、聚焦网络爬虫(Focused Web Crawler)、增量式网络爬虫(Incremental Web Crawler)、深层网络爬虫(Deep Web Crawler)。 实际的网络爬虫系统通常是几种爬虫技术相结合实现的 。
- 1.通用网络爬虫(General Purpose Web Crawler)
- 2.聚焦网络爬虫(Focused Crawler)
- 3.增量式网络爬虫(Incremental Web Crawler)
- 4.深层网络爬虫(Deep Web Crawler)
- 简单的工作流程
- 🌈Why learn it?
- 🧲Who does it?
- 🎈When to use it? And Where to use it?
- **01 数据的采集途径**
- **1. 个人数据**
- **2. 公开数据**
- **3. 违反 Robots 协议**
- **02 数据的采集行为**
- **1. 高并发压力**
- **2. 影响正常业务**
- **03 数据的使用目的**
- **1. 超出约定的使用**
- **2. 出售个人信息**
- **3. 不正当商业行为**
- **04 「爬虫法」即将出台**
- 💊How to use it?==(重点)==
- 1、Java基础知识
- 2、HTTP协议基础与网络抓包
- HTTP协议
- URL
- 报文
- HTTP请求方法
- HTTP状态码
- HTTP信息头
- 协议结构
- 关于HTTP消息头
- 常用的`HTTP`请求头
- 常用的`HTTP`响应头
- HTTP请求及响应的例子
- 协议格式详解
- URL结构
- Request讲解
- (1).请求行
- (2).请求头部
- (3).空行
- (4).请求数据
- Reponse讲解
- (1).状态行
- (2).响应头
- (3).空行
- (4).响应体
- HTTP响应正文
- HTML
- XML
- JSON
- 网络抓包
- 3、网页内容获取
- 1.Jsoup的使用
- **快速入门**
- **直接载入 url**
- **通过文件加载文档**
- **通过字符串加载文档**
- **具体应用**
- **从 HTML 获取标题信息**
- **从 HTML 获取元信息**
- **从 HTML 获取头部信息**
- **从 HTML 获取内容信息**
- **从 HTML 获取页面所有超链接**
- **从 HTML 获取页面所有图片**
- **从 HTML 获取指定标签的内容**
- **从 HTML 获取指定标签ID的内容**
- **从 HTML 获取指定标签 class 的内容**
- **从 HTML 获取指定标签属性的内容**
- **从 HTML 获取页面元素中任意内容**
- **消除不信任的HTML(以防止XSS)**
- **小结**
- **参考**
- **请求URL**
- **设置头信息**
- 🔑How far you can do?
⭐️写在前面的话⭐️
📒博客主页: 程序员好冰
🎉欢迎 【点赞👍 关注🔎 收藏⭐️ 留言📝】
📌本文由 程序员好冰 原创,CSDN 首发!
📆入站时间: 🌴2022 年 07 月 13 日🌴
✉️ 是非不入松风耳,花落花开只读书。
💭推荐书籍:📚《Java编程思想》,📚《Java 核心技术卷》
💬参考在线编程网站:🌐牛客网🌐力扣
🍭 作者水平很有限,如果发现错误,一定要及时告知作者哦!感谢感谢!🍭
📌What is it?
是什么?目的是什么?做什么工作?
一种按照指定规则,自动抓取或下载网络资源的计算机程序或自动化脚本。
网络爬虫是一种从互联网抓取数据信息的自动化程序。如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛(程序),沿着网络抓取自己的猎物(数据)。
=爬虫可以在抓取过程中进行各种异常处理、错误重试等操作,确保爬取持续高效地运行。它分为通用爬虫和专用爬虫。通用爬虫是捜索引擎抓取系统的重要组成部分,主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份;专用爬虫主要为某一类特定的人群提供服务,爬取的目标网页定位在与主题相关的页面中,节省大量的服务器资源和带宽资源。比如要获取某一垂直领域的数据或有明确的检索需求,此时就需要过滤掉一些无用的信息。
分类
网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫(General Purpose Web Crawler)、聚焦网络爬虫(Focused Web Crawler)、增量式网络爬虫(Incremental Web Crawler)、深层网络爬虫(Deep Web Crawler)。 实际的网络爬虫系统通常是几种爬虫技术相结合实现的 。
1.通用网络爬虫(General Purpose Web Crawler)
爬取目标资源在全互联网中,爬取目标数据巨大。对爬取性能要求非常高。应用于大型搜索引擎中,有非常高的应用价值。
通用网络爬虫的基本构成:初始URL集合,URL队列,页面爬行模块,页面分析模块,页面数据库,链接过滤模块等构成。
通用网络爬虫的爬行策略:主要有深度优先爬行策略和广度优先爬行策略。
2.聚焦网络爬虫(Focused Crawler)
将爬取目标定位在与主题相关的页面中
主要应用在对特定信息的爬取中,主要为某一类特定的人群提供服务
聚焦网络爬虫的基本构成:初始URL,URL队列,页面爬行模块,页面分析模块,页面数据库,连接过滤模块,内容评价模块,链接评价模块等构成
聚焦网络爬虫的爬行策略:
基于内容评价的爬行策略
基于链接评价的爬行策略
基于增强学习的爬行策略
基于语境图的爬行策略
关于聚焦网络爬虫具体的爬行策略
3.增量式网络爬虫(Incremental Web Crawler)
增量式更新指的是在更新的时候只更新改变的地方,而未改变的地方则不更新
只爬取内容发生变化的网页或者新产生的网页,
一定程度上能保证所爬取的网页,尽可能是新网页
4.深层网络爬虫(Deep Web Crawler)
表层网页:不需要提交表单,使用静态的链接就能够到达的静态网页
深层网页:隐藏在表单后面,不能通过静态链接直接获得,是需要提交一定的关键词之后才能够获取得到的网页。
深层网络爬虫最重要的部分即为表单填写部分
深层网络爬虫的基本构成:URL列表,LVS列表(LVS指的是标签/数值集合,即填充表单的数据源)爬行控制器,解析器,LVS控制器,表单分析器,表单处理器,响应分析器等
深层网络爬虫表单填写有两种类型:
基于领域知识的表单填写(建立一个填写表单的关键词库,在需要的时候,根据语义分析选择对应的关键词进行填写)
基于网页结构分析的表单填写(一般是领域只是有限的情况下使用,这种方式会根据网页结构进行分析,并自动的进行表单填写)
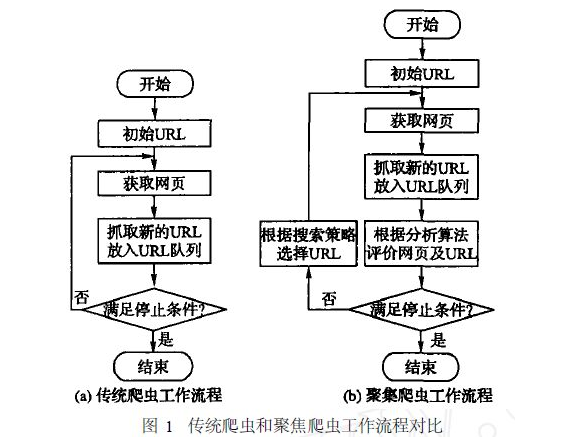
简单的工作流程
🌈Why learn it?
为什么要做?可不可以不做?有没有替代方案?
我们已经初步认识了网络爬虫,但是为什么要学习网络爬虫呢?要知道,只有清晰地知道我们的学习目的,才能够更好地学习这一项知识,所以在这一节中,我们将会为大家分析一下学习网络爬虫的原因。
当然,不同的人学习爬虫,可能目的有所不同,在此,我们总结了4种常见的学习爬虫的原因。
1) 学习爬虫,可以私人订制一个搜索引擎,并且可以对搜索引擎的数据采集工作原理进行更深层次地理解。
有的朋友希望能够深层次地了解搜索引擎的爬虫工作原理,或者希望自己能够开发出款私人搜索引擎,那么此时,学习爬虫是非常有必要的。简单来说,我们学会了爬虫编写之后,就可以利用爬虫自动地采集互联网中的信息,采集回来后进行相应的存储或处理,在需要检索某些信息的时候,只需在采集回来的信息中进行检索,即实现了私人的搜索引擎。当然,信息怎么爬取、怎么存储、怎么进行分词、怎么进行相关性计算等,都是需要我们进行设计的,爬虫技术主要解决信息爬取的问题。
2)大数据时代,要进行数据分析,首先要有数据源,而学习爬虫,可以让我们获取更多的数据源,并且这些数据源可以按我们的目的进行采集,去掉很多无关数据。
在进行大数据分析或者进行数据挖掘的时候,数据源可以从某些提供数据统计的网站获得,也可以从某些文献或内部资料中获得,但是这些获得数据的方式,有时很难满足我们对数据的需求,而手动从互联网中去寻找这些数据,则耗费的精力过大。此时就可以利用爬虫技术,自动地从互联网中获取我们感兴趣的数据内容,并将这些数据内容爬取回来,作为我们的数据源,从而进行更深层次的数据分析,并获得更多有价值的信息。
3)对于很多SEO从业者来说,学习爬虫,可以更深层次地理解搜索引擎爬虫的工作原理,从而可以更好地进行搜索引擎优化既然是搜索引擎优化,那么就必须要对搜索引擎的工作原理非常清楚,同时也需要掌握搜索引擎爬虫的工作原理,这样在进行搜索引擎优化时,才能知己知彼,百战不殆。
4)从就业的角度来说,爬虫工程师目前来说属于紧缺人才,并且薪资待遇普遍较高所以,深层次地掌握这门技术,对于就业来说,是非常有利的。
有些朋友学习爬虫可能为了就业或者跳槽。从这个角度来说,爬虫工程师方向是不错的选择之一,因为目前爬虫工程师的需求越来越大,而能够胜任这方面岗位的人员较少,所以属于一个比较紧缺的职业方向,并且随着大数据时代的来临,爬虫技术的应用将越来越广泛,在未来会拥有很好的发展空间。上海尚学堂Python培训有专门的Python网络爬虫课程,重点学习Python网络爬虫,就是针对的是爬虫工程师职位,详情可以点击查看Python培训课程。
技多不压身
🧲Who does it?
谁?由谁来做?选择哪种语言?哪些工具比较好?
Python、Java、网络请求工具HttpClient、JSON解析工具Fastjson、数据库操作工具QueryRunner、Maven仓库
🎈When to use it? And Where to use it?
何处?在哪里做?
何时?什么时间做?什么时机最适宜?使用的一些避讳,禁忌。
从海量数据中获取自己感兴趣的数据
爬虫作为一种计算机技术,具有技术中立性,爬虫技术在法律上从来没有被禁止。爬虫的发展历史可以追溯到 20 年前,搜索引擎、聚合导航、数据分析、人工智能等业务,都需要基于爬虫技术。
但是爬虫作为获取数据的技术手段之一,由于部分数据存在敏感性,如果不能甄别哪些数据是可以爬取,哪些会触及红线,可能下一位上新闻的主角就是你。
如何界定爬虫的合法性,目前没有明文规定,但我通过翻阅大量文章、事件、分享、司法案例,我总结出界定的三个关键点:采集途径、采集行为、使用目的。
01 数据的采集途径
通过什么途径爬取数据,这个是最需要重视的一点。总体来说,未公开、未经许可、且带有敏感信息的数据,不管是通过什么渠道获得,都是一种不合法的行为。
所以在采集这类比较敏感的数据时,最好先查询下相关法律法规,特别是用户个人信息、其他商业平台的信息 等这类信息,寻找一条合适的途径。
1. 个人数据
采集和分析个人信息数据,应该是当下所有互联网都会做的一件事,但是大部分个人数据都是非公开的,想获得必须通过合法途径,可参见『网络安全法』第四十一条:
网络运营者收集、使用个人信息,应当遵循合法、正当、必要的原则,公开收集、使用规则,明示收集、使用信息的目的、方式和范围,并经被收集者同意……
也就是必须在提前告知收集的方式、范围、目的,并经过用户授权或同意后,才能采集使用,也就是我们常见的各种网站与 App 的用户协议中关于信息收集的部分。
相关反面案例:
8月20日,澎湃新闻从绍兴市越城区公安分局获悉,该局日前侦破一起特大流量劫持案,涉案的新三板挂牌公司北京瑞智华胜科技股份有限公司,涉嫌非法窃取用户个人信息30亿条,涉及百度、腾讯、阿里、京东等全国96家互联网公司产品,目前警方已从该公司及其关联公司抓获6名犯罪嫌疑人。 …… 北京瑞智华胜公司及其关联公司在与正规运营商合作中,会加入一些非法软件用于清洗流量、获取用户的 cookie。
▲节选自 澎湃新闻:『新三板挂牌公司涉窃取30亿条个人信息,非法牟利超千万元』[1]
2. 公开数据
从合法公开渠道,并且不明显违背个人信息主体意愿,都没有什么问题。但如果通过破解、侵入等“黑客”手段来获取数据,那也有相关法律等着你:
刑法第二百八十五条第三款规定的“专门用于侵入、非法控制计算机信息系统的程序、工具”: (一)具有避开或者突破计算机信息系统安全保护措施,未经授权或者超越授权获取计算机信息系统数据的功能的; ……
3. 违反 Robots 协议
虽然 Robots 协议没有法规强制遵守,但 Robots 协议作为行业约定,在遵循之下会给你带来合法支持。
因为 Robots 协议具有指导意义,如果注明 Disallow 就说明是平台明显要保护的页面数据,想爬取之前应该仔细考虑一下。
02 数据的采集行为
使用技术手段应该懂得克制,一些容易对服务器和业务造成干扰甚至破坏的行为,应当充分衡量其承受能力,毕竟不是每家都是 BAT 级。
1. 高并发压力
做技术经常专注于优化,爬虫开发也是如此,想尽各种办法增加并发数、请求效率,但高并发带来的近乎 DDOS 的请求,如果对对方服务器造成压力,影响了对方正常业务,那就应该警惕了。
如果一旦导致严重后果,后果参见:
《刑法》第二百八十六条还规定,违反国家规定,对计算机信息系统功能进行删除、修改、增加、干扰,造成计算机信息系统不能正常运行,后果严重的,构成犯罪。
所以请爬取的时候,即使没有反爬限制,也不要肆无忌惮地开启高并发,掂量一下对方服务器的实力。
2. 影响正常业务
除了高并发请求,还有一些影响业务的情况,常见的比如抢单,会影响正常用户的体验。
03 数据的使用目的
数据使用目的同样是一大关键,就算你通过合法途径采集的数据,如果对数据没有正确的使用,同样会存在不合法的行为。
1. 超出约定的使用
一种情况是公开收集的数据,但没有遵循之前告知的使用目的,比如用户协议上说只是分析用户行为,帮助提高产品体验,结果变成了出售用户画像数据。
还有一种情况,是有知识产权、著作权的作品,可能会允许你下载或引用,但明显标注了使用范围,比如不能转载、不能用于商业行为等,更不能去盗用,这些都是有法律明文保护,所以要注意使用。
其他情况就不列举了。
2. 出售个人信息
关于出售个人信息,千万不要做,是法律特别指出禁止的,参见:
根据《最高人民法院 最高人民检察院关于办理侵犯公民个人信息刑事案件适用法律若干问题的解释》第五条规定,对“情节严重”的解释: (1)非法获取、出售或者提供行踪轨迹信息、通信内容、征信信息、财产信息五十条以上的; (2)非法获取、出售或者提供住宿信息、通信记录、健康生理信息、交易信息等其他可能影响人身、财产安全的公民个人信息五百条以上的; (3)非法获取、出售或者提供第三项、第四项规定以外的公民个人信息五千条以上的便构成“侵犯公民个人信息罪”所要求的“情节严重”。 此外,未经被收集者同意,即使是将合法收集的公民个人信息向他人提供的,也属于刑法第二百五十三条之一规定的“提供公民个人信息”,可能构成犯罪。
3. 不正当商业行为
如果将竞品公司的数据,作为自己公司的商业目的,这就可能存在构成不正当商业竞争,或者是违反知识产权保护。
这种情况在目前涉及爬虫的商业诉讼案中比较常见,两年前比较知名的案件,“车来了” App 抓取其竞品 “酷米客” 的公交车数据,并展示在自己的产品上:
虽然公交车作为公共交通工具,其实时运行路线、运行时间等信息仅系客观事实,但当此类信息经过人工收集、分析、编辑、整合并配合GPS精确定位,作为公交信息查询软件的后台数据后,此类信息便具有了实用性并能够为权利人带来现实或潜在、当下或将来的经济利益,已经具备无形财产的属性。元光公司利用网络爬虫技术大量获取并且无偿使用谷米公司“酷米客”软件的实时公交信息数据的行为,实为一种“不劳而获”、“食人而肥”的行为,构成不正当竞争。
▲节选自『深圳市中级人民法院(2017)粤03民初822号民事判决书』
04 「爬虫法」即将出台
好消息是,相关办法已经在路上了。
5 月 28 日零点,国家互联网信息办公室发布了《数据安全管理办法》征求意见稿。
我也查阅了这份意见稿,里面对数据的获取、存储、传输、使用等都做了一些规定,包括关于爬虫行为的若干规定(还在征求阶段,因此后续可能会有变化)。
比如,第二章第十六条:
网络运营者采取自动化手段访问收集网站数据,不得妨碍网站正常运行;此类行为严重影响网站运行,如自动化访问收集流量超过网站日均流量三分之一,网站要求停止自动化访问收集时,应当停止。
第三章第二十七条:
网络运营者向他人提供个人信息前,应当评估可能带来的安全风险,并征得个人信息主体同意。下列情况除外: (一)从合法公开渠道收集且不明显违背个人信息主体意愿; (二)个人信息主体主动公开; (三)经过匿名化处理; (四)执法机关依法履行职责所必需; (五)维护国家安全、社会公共利益、个人信息主体生命安全所必需。
▲节选自『数据安全管理办法(征求意见稿)』[2]





💊How to use it?(重点)
怎么做?如何提高效率?如何实施?方法是什么?
1、Java基础知识
-
JDK安装
-
IDEA下载
-
基本数据类型
-
数组
-
条件判断与循环
-
集合
- List和Set集合
- Map集合
- Queue集合
-
对象与类
-
String类
-
日期和时间处理
-
正则表达式
-
Maven工程的创建
-
log4j的使用
2、HTTP协议基础与网络抓包
HTTP协议
URL
报文
HTTP请求方法
虽然 HTTP/1.1 里规定了八种请求方法,但只有前四个是比较常用的,所以我们先来看一下这四个方法。
GET/HEAD
GET 方法应该是 HTTP 协议里最知名的请求方法了,也应该是用的最多的,自 0.9 版出现并一直被保留至今,是名副其实的“元老”。
它的含义是请求从服务器获取资源,这个资源既可以是静态的文本、页面、图片、视频,也可以是由 PHP、Java 动态生成的页面或者其他格式的数据。
GET 方法虽然基本动作比较简单,但搭配 URI 和其他头字段就能实现对资源更精细的操作。
例如,在 URI 后使用“#”,就可以在获取页面后直接定位到某个标签所在的位置;使用 If-Modified-Since 字段就变成了“有条件的请求”,仅当资源被修改时才会执行获取动作;使用 Range 字段就是“范围请求”,只获取资源的一部分数据。
HEAD 方法与 GET 方法类似,也是请求从服务器获取资源,服务器的处理机制也是一样的,但服务器不会返回请求的实体数据,只会传回响应头,也就是资源的“元信息”。
HEAD 方法可以看做是 GET 方法的一个“简化版”或者“轻量版”。因为它的响应头与 GET 完全相同,所以可以用在很多并不真正需要资源的场合,避免传输 body 数据的浪费。
比如,想要检查一个文件是否存在,只要发个 HEAD 请求就可以了,没有必要用 GET 把整个文件都取下来。再比如,要检查文件是否有最新版本,同样也应该用 HEAD,服务器会在响应头里把文件的修改时间传回来。
POST/PUT
GET 和 HEAD 方法是从服务器获取数据,而 POST 和 PUT 方法则是相反操作,向 URI 指定的资源提交数据,数据就放在报文的 body 里。
POST 也是一个经常用到的请求方法,使用频率应该是仅次于 GET,应用的场景也非常多,只要向服务器发送数据,用的大多数都是 POST。
比如,你上论坛灌水,敲了一堆字后点击“发帖”按钮,浏览器就执行了一次 POST 请求,把你的文字放进报文的 body 里,然后拼好 POST 请求头,通过 TCP 协议发给服务器。
又比如,你上购物网站,看到了一件心仪的商品,点击“加入购物车”,这时也会有 POST 请求,浏览器会把商品 ID 发给服务器,服务器再把 ID 写入你的购物车相关的数据库记录。
PUT 的作用与 POST 类似,也可以向服务器提交数据,但与 POST 存在微妙的不同,通常 POST 表示的是“新建”“create”的含义,而 PUT 则是“修改”“update”的含义。
在实际应用中,PUT 用到的比较少。而且,因为它与 POST 的语义、功能太过近似,有的服务器甚至就直接禁止使用 PUT 方法,只用 POST 方法上传数据。
其他方法
其他方法讲完了 GET/HEAD/POST/PUT,还剩下四个标准请求方法,它们属于比较“冷僻”的方法,应用的不是很多。
DELETE 方法指示服务器删除资源,因为这个动作危险性太大,所以通常服务器不会执行真正的删除操作,而是对资源做一个删除标记。当然,更多的时候服务器就直接不处理 DELETE 请求。
CONNECT 是一个比较特殊的方法,要求服务器为客户端和另一台远程服务器建立一条特殊的连接隧道,这时 Web 服务器在中间充当了代理的角色。
OPTIONS 方法要求服务器列出可对资源实行的操作方法,在响应头的 Allow 字段里返回。它的功能很有限,用处也不大,有的服务器(例如 Nginx)干脆就没有实现对它的支持。
TRACE 方法多用于对 HTTP 链路的测试或诊断,可以显示出请求 - 响应的传输路径。它的本意是好的,但存在漏洞,会泄漏网站的信息,所以 Web 服务器通常也是禁止使用。
扩展方法
虽然 HTTP/1.1 里规定了八种请求方法,但它并没有限制我们只能用这八种方法,这也体现了 HTTP 协议良好的扩展性,我们可以任意添加请求动作,只要请求方和响应方都能理解就行。
HTTP状态码
HTTP状态码负责表示客户端HTTP请求的返回结果、标记服务器的处理是否正常、通知出现的错误工作等。借助状态码,用户可以知道服务器端是正常处理了请求,还是出现了错误。
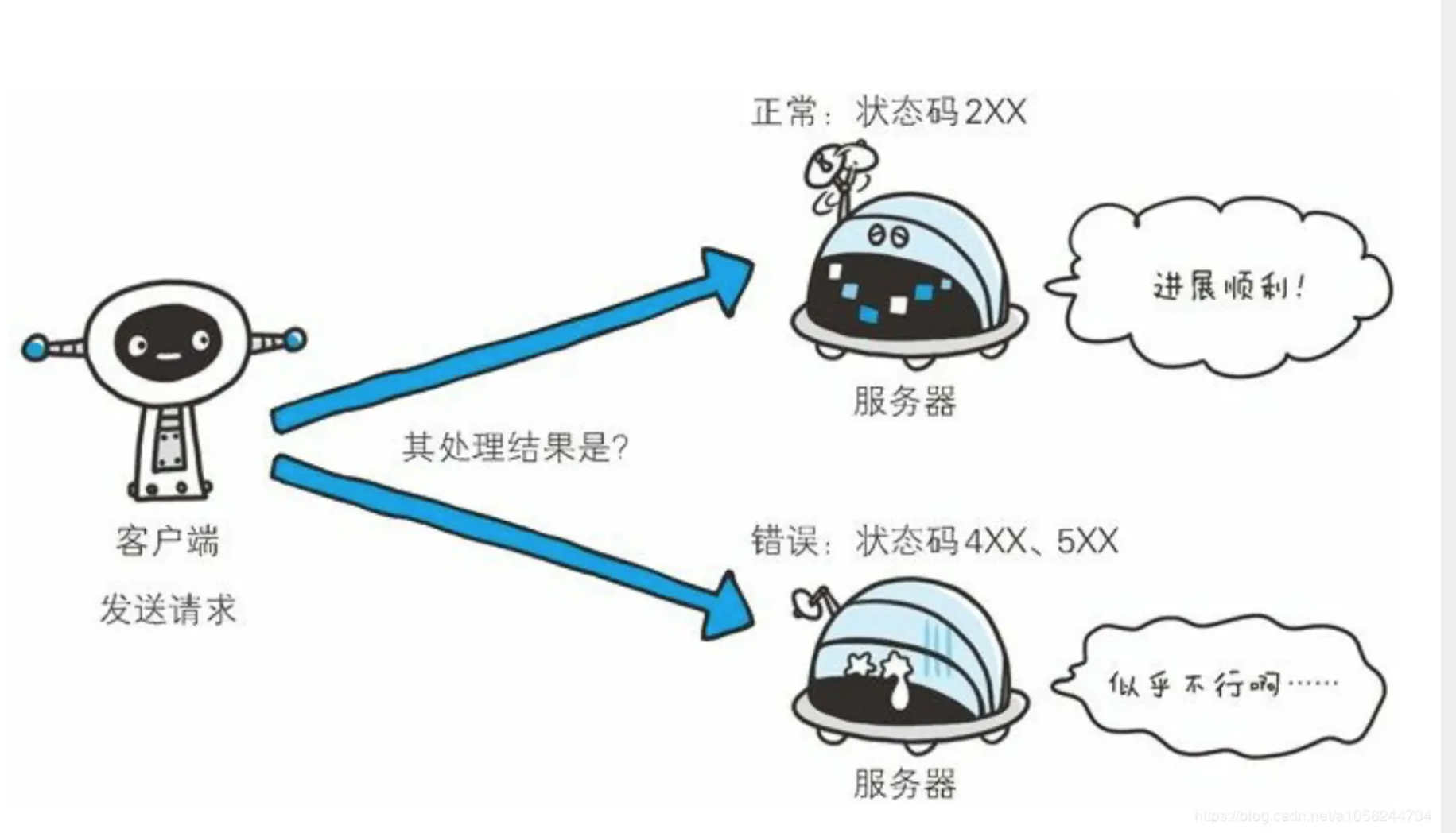
图源:《图解HTTP》(上野 宣 著)
状态码如200 OK,由3位数字和原因短语组成。数字中的第一位指定了响应类别,后两位无分类。相应类别由以下五种:
| 状态码 | 类别 | 描述 |
|---|---|---|
| 1xx | Informational(信息状态码) | 接受请求正在处理 |
| 2xx | Success(成功状态码) | 请求正常处理完毕 |
| 3xx | Redirection(重定向状态码) | 需要附加操作已完成请求 |
| 4xx | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5xx | Server Error(服务器错误状态码) | 服务器处理请求出错 |
HTTP的状态码总数达60余种,但是常用的大概只有14种。接下来,我们就介绍一下这些具有代表性的14个状态码。
- 14种常用的HTTP状态码列表
| 状态码 | 状态码英文名称 | 中文描述 |
|---|---|---|
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 204 | No Content | 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 |
| 206 | Partial Content | 是对资源某一部分的请求,服务器成功处理了部分GET请求,响应报文中包含由Content-Range指定范围的实体内容。 |
| 301 | Moved Permanently | 永久性重定向。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时性重定向。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 303 | See Other | 查看其它地址。与302类似。使用GET请求查看 |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向,会按照浏览器标准,不会从POST变成GET。 |
| 400 | Bad Request | 客户端请求报文中存在语法错误,服务器无法理解。浏览器会像200 OK一样对待该状态吗 |
| 401 | Unauthorized | 请求要求用户的身份认证,通过HTTP认证(BASIC认证,DIGEST认证)的认证信息,若之前已进行过一次请求,则表示用户认证失败 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面。也可以在服务器拒绝请求且不想说明理由时使用 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求,也可能是web应用存在bug或某些临时故障 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
- 不常用的HTTP状态码列表
| 状态码 | 状态码英文名称 | 中文描述 |
|---|---|---|
| 201 | Created | 已创建。成功请求并创建了新的资源 |
| 202 | Accepted | 已接受。已经接受请求,但未处理完成 |
| 203 | Non-Authoritative Information | 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本 |
| 205 | Reset Content | 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域 |
| 300 | Multiple Choices | 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
| 305 | Use Proxy | 使用代理。所请求的资源必须通过代理访问 |
| 306 | Unused | 已经被废弃的HTTP状态码 |
| 402 | Payment Required | 保留,将来使用 |
| 405 | Method Not Allowed | 客户端请求中的方法被禁止 |
| 406 | Not Acceptable | 服务器无法根据客户端请求的内容特性完成请求 |
| 407 | Proxy Authentication Required | 请求要求代理的身份认证,与401类似,但请求者应当使用代理进行授权 |
| 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict | 服务器完成客户端的PUT请求是可能返回此代码,服务器处理请求时发生了冲突 |
| 410 | Gone | 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置 |
| 411 | Length Required | 服务器无法处理客户端发送的不带Content-Length的请求信息 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
| 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed | 服务器无法满足Expect的请求头信息 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 充当网关或代理的服务器,从远端服务器接收到了一个无效的请求 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的版本,无法完成处理 |
HTTP信息头
协议结构
HTTP协议格式也比较简单,格式如下:
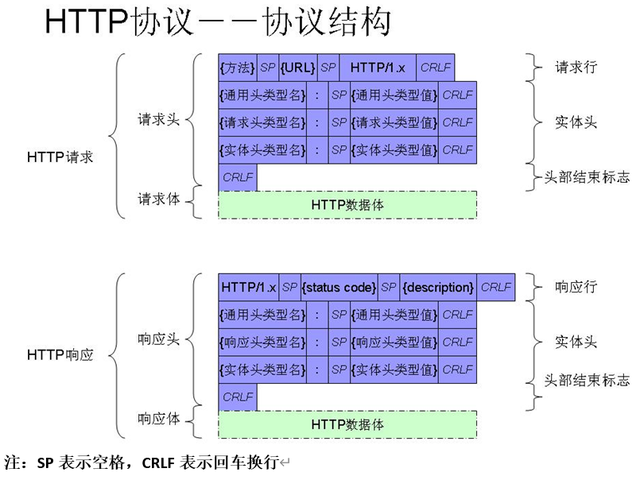
关于HTTP消息头
HTTP消息头是在,客户端请求(Request)或服务器响应(Response)时传递的,位请求或响应的第一行, HTTP消息体(请求或响应的内容)是其后传输。HTTP消息头,以明文的字符串格式传送,是以冒号分隔的键/值对,如: Accept-Charset: utf-8,每一个消息头最后以回车符( CR)和换行符( LF)结尾。HTTP消息头结束后,会用一个空白的字段来标识,这样就会出现两个连续的CR-LF。
HTTP消息头支持自定义, 自定义的专用消息头一般会添加'X-'前缀。
常用的HTTP请求头
| 协议头 | 说明 | 示例 | 状态 |
|---|---|---|---|
| Accept | 可接受的响应内容类型(Content-Types)。 | Accept: java/plain | 固定 |
| Accept-Charset | 可接受的字符集 | Accept-Charset: utf-8 | 固定 |
| Accept-Encoding | 可接受的响应内容的编码方式. | Accept-Encoding: gzip, deflate | 固定 |
| Accept-Language | 可接受的响应内容语言列表. | Accept-Language: en-US | 固定 |
| Cache-Control | 用来指定当前的请求/回复中的,是否使用缓存机制. | Cache-Control: no-cache | 固定 |
| Connection | 客户端(浏览器)想要优先使用的连接类型 | Connection: keep-alive Connection: Upgrade | 固定 |
| Cookie | 由之前服务器通过Set-Cookie(见下文)设置的一个HTTP协议Cookie | Cookie: $Version=1; Skin=new; | 固定:标准 |
| Content-Type | 请求体的MIME类型 (用于POST和PUT请求中) | Content-Type: application/x-www-form-urlencoded | 固定 |
| User-Agent | 浏览器的身份标识字符串 | User-Agent: Mozilla/…… | 固定 |
常用的HTTP响应头
| 协议头 | 说明 | 示例 | 状态 |
|---|---|---|---|
| Access-Control-Allow-Origin | 指定哪些网站可以跨域源资源共享 | Access-Control-Allow-Origin:* | 临时 |
| Location | 用于在进行重定向,或在创建了某个新资源时使用。 | Location: http://www.itbilu.com/nodejs | 固定 |
| Refresh | 用于重定向,或者当一个新的资源被创建时。默认会在5秒后刷新重定向。 | Refresh: 5; url=http://itbilu.com | |
| Server | 服务器的名称 | Server: nginx/1.6.3 | 固定 |
| Set-Cookie | 设置HTTP cookie | Set-Cookie: UserID=itbilu; Max-Age=3600; Version=1 | 固定: 标准 |
| Status | 通用网关接口的响应头字段,用来说明当前HTTP连接的响应状态。 | Status: 200 OK |
HTTP请求及响应的例子
HTTP协议举例:

协议格式详解
URL结构
HTTP使用统一资源标识符(URl)来传输数据和建立连接。URL(统一资源定位符)是一种特殊种类的URI,包含了用于查找的资源的足够的信息,我们一般常用的就是URL,而一个完整的URL包含下面几部分:
http:// www.fishbay.cn: 80/mix/76.html?name=kelvin&password=123456#first
| 格式 | 含义 |
|---|---|
| 协议部分http: | 该URL的协议部分为http:,表示网页用的是HTTP协议,后面的//为分隔符 |
| 域名部分 www.fishbay.cn | 域名是www.fishbay.cn,发送请求时,需要向DNS服务器解析IP。如果为了优化请求,可以直接用IP作为域名部分使用. |
| 端口部分 | 域名后面的80表示端口,和域名之间用:分隔,端口不是一个URL的必须的部分。如果端口是80,也可以省略不写 |
| 虚拟目录部分 | 从域名的第一个/开始到最后一个/为止,是虚拟目录的部分。其中,虚拟目录也不是URL必须的部分,本例中的虚拟目录是/mix/ |
| 文件名部分 | 从域名最后一个/开始到?为止,是文件名部分;如果没有?,则是从域名最后一个/开始到#为止,是文件名部分;如果没有?和#,那么就从域名的最后一个/从开始到结束,都是文件名部分。本例中的文件名是76.html,文件名也不是一个URL的必须部分,如果没有文件名,则使用默认文件名 |
| 锚部分 | 从#开始到最后,都是锚部分。本部分的锚部分是first,锚也不是一个URL必须的部分 |
| 参数部分 | 从?开始到#为止之间的部分是参数部分,又称为搜索部分、查询部分。本例中的参数是name=kelvin&password=123456,如果有多个参数,各个参数之间用&作为分隔符。 |
Request讲解
HTTP的请求包括:请求行(request line)、请求头部(header)、空行 和 请求数据 四个部分组成。
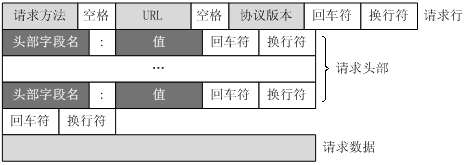
HTTP请求消息结构,抓包的request结构如下:
GET /mix/76.html?name=kelvin&password=123456 HTTP/1.1
Host: www.fishbay.cn
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36
Accept: java/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Encoding: gzip, deflate, sdch
Accept-Language: zh-CN,zh;q=0.8,en;q=0.6
1234567
(1).请求行
GET为请求类型,/mix/76.html?name=kelvin&password=123456为要访问的资源,HTTP/1.1是协议版本
(2).请求头部
从第二行起为请求头部,Host指出请求的目的地(主机域名);User-Agent是客户端的信息,它是检测浏览器类型的重要信息,由浏览器定义,并且在每个请求中自动发送。
(3).空行
请求头后面必须有一个空行
(4).请求数据
请求的数据也叫请求体,可以添加任意的其它数据。这个例子的请求体为空。
Reponse讲解
一般情况下,服务器收到客户端的请求后,就会有一个HTTP的响应消息,HTTP响应也由4部分组成,分别是:状态行、响应头、空行 和 响应体。
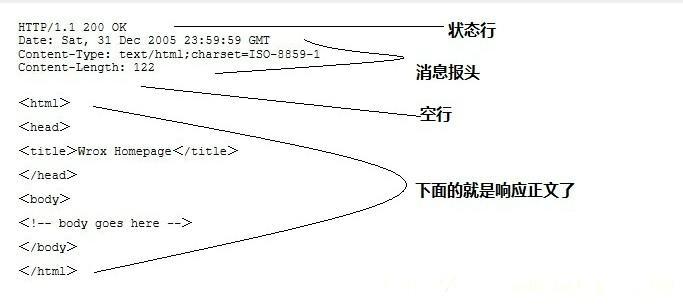
http响应消息格式,抓包的数据如下:
HTTP/1.1 200 OK
Server: nginx
Date: Mon, 20 Feb 2017 09:13:59 GMT
Content-Type: java/plain;charset=UTF-8
Vary: Accept-Encoding
Cache-Control: no-store
Pragrma: no-cache
Expires: Thu, 01 Jan 1970 00:00:00 GMT
Cache-Control: no-cache
Content-Encoding: gzip
Transfer-Encoding: chunked
Proxy-Connection: Keep-alive{"code":200,"notice":0,"follow":0,"forward":0,"msg":0,"comment":0,"pushMsg":null,"friend":{"snsCount"
1234567891011121314
(1).状态行
状态行由协议版本号、状态码、状态消息组成
(2).响应头
响应头是客户端可以使用的一些信息,如:Date(生成响应的日期)、Content-Type(MIME类型及编码格式)、Connection(默认是长连接)等等
(3).空行
响应头和响应体之间必须有一个空行
(4).响应体
响应正文,本例中是键值对信息
HTTP响应正文
-
HTML
-
XML
xml(Extensible Markup Language)可拓展标记语言
**1)**XML的简单易于在任何应用程序中读/写数据,这使XML很快成为数据交换的唯一公共语言,虽然不同的应用软件也支持其他的数据交换格式,但不久之后它们都将支持XML,那就意味着程序可以更容易的与Windows、Mac OS、Linux以及其他平台下产生的信息结合,然后可以很容易加载XML数据到程序中并分析它,并以XML格式输出结果。
**2)**xml可用作数据的说明、储存、传输
举个例子:假设一个微信群里面小明发了一条消息“你吃过没”。而这条消息发出后会被储存到服务器里,而当你进入微信的时候,这条消息就会从服务器里抓取过来显示到你的手机上。而这个抓取的过程中假设是以xml文件来传输(也有json,json和xml用途很相似,json、xml都有自己的格式,但其实都只是包装数据时格式不同而已,重要的是其中含有的数据,而不是包装的格式。这里只是举个例子)这时,我们用通俗易懂的文字来表示就是:
发送者:小明
聊天组:xxxx
信息:你吃过没
很明显我们人可以体会字面意思,并自动拆分出数据的,但机器却看不行,所以在传入之前它是通过xml的格式来让机器能识别的出来:
<msg><sender ="小明" /><groupid = 112221 /><type = test/><content = "你吃过没" />
</msg>
格式大概是这样,具体的如果感兴趣可以自己去网上看看,这里只是举个例子。这样表示就很直观,附带了对数据的说明,并且具备通用的格式规范可以让程序做解析。
**3)**xml文件现在多用于作配置文件,设置文件比较多,很多软件,框架都会采取xml作为配置文件。像在Android Studio中创建一个项目时,开始会弹出一个Configure your project(配置你的项目),而你在上面输入的项目名,包名什么的都会帮你存储到AndroidManifest.xml 文件里,此xml文件里还会默认配置好项目的一些属性和一个MainActivty以及这个activty的一些属性,并且在之后一些组件(Activty,service等)都是要在这里面注册并配置的。
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。
**1)**JSON基于 ECMAScript (欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
**2)**json和xml优缺点对比:[1]
①可读性方面。
JSON和XML的数据可读性基本相同,JSON和XML的可读性可谓不相上下,一边是建议的语法,一边是规范的标签形式,XML可读性较好些。
②可扩展性方面。
XML天生有很好的扩展性,JSON当然也有,没有什么是XML能扩展,JSON不能的。
③编码难度方面。
XML有丰富的编码工具,比如Dom4j、JDom等,JSON也有http://json.org提供的工具,但是JSON的编码明显比XML容易许多,即使不借助工具也能写出JSON的代码,可是要写好XML就不太容易了。
④解码难度方面。
XML的解析得考虑子节点父节点,让人头昏眼花,而JSON的解析难度几乎为0。这一点XML输的真是没话说。
⑤流行度方面。
XML已经被业界广泛的使用,而JSON才刚刚开始,但是在Ajax这个特定的领域,未来的发展一定是XML让位于JSON。到时Ajax应该变成Ajaj(Asynchronous Javascript and JSON)了。
⑥解析手段方面。
JSON和XML同样拥有丰富的解析手段。
⑦数据体积方面。
JSON相对于XML来讲,数据的体积小,传递的速度更快些。
⑧数据交互方面。
JSON与JavaScript的交互更加方便,更容易解析处理,更好的数据交互。
⑨数据描述方面。
JSON对数据的描述性比XML较差。
⑩传输速度方面。
JSON的速度要远远快于XML。
网络抓包
一、什么是抓包?
抓包(packet capture)就是将网络传输发送与接收的数据包进行截获、重发、编辑、转存等操作,也用来检查网络安全。抓包也经常被用来进行数据截取等。
二、抓包做什么?
不管做什么事情,首先要有明确的目的,其次是要清楚能力的范畴,最后是要有清晰的思路。原始数据->过滤->分析,这是数据处理的基本套路,抓包的目的就是为了获取到想要的原始数据,拿到数据以后,我们就可以做以下一些事情:
- 分析数据传输协议。
- 定位网络协议的问题。
- 从数据包中获取想要的信息。
- 将截取到的数据包进行修改,伪造,重发。为什么抓包?
三、为什么抓包?
1.从功能测试角度,通过抓包查看隐藏字段
Web 表单中会有很多隐藏的字段,这些隐藏字段一般都有一些特殊的用途,比如收集用户的数据,预防 CRSF 攻击,防网络爬虫,以及一些其他用途。这些隐藏字段在界面上都看不到,如果想检测这些字段,就必须要使用抓包工具。
- 通过抓包工具了解协议内容,方便开展接口和性能测试
性能测试方面,性能测试其实就是大量模拟用户的请求,所以我们必须要知道请求中的协议内容和特点,才能更好的模拟用户请求,分析协议就需要用到抓包工具;接口测试方面,在接口测试时,虽然我们尽量要求有完善的接口文档。但很多时候接口文档不可能覆盖所有的情况,或者因为文档滞后,在接口测试过程中,还时需要借助抓包工具来辅助我们进行接口测试。 - 需要通过抓包工具,检查数据加密
安全测试方面,我们需要检查敏感数据在传输过程中是否加密,也需要借助抓包工具才能检查。 - 处理前后端 bug 归属之争
在我们提交bug的时候,经常会出现前端(客户端展示)和后端(服务端的逻辑)的争议,那么可以通过抓包工具,确实是数据传递问题还是前端显示的问题。如果抓出来的数据就有问题的话,那么一般是后端的问题;如果抓出来的数据是正确的,那么基本上可以断定是前端显示的问题。
通过抓包分析,可以更好的理解整个系统
经常使用抓包工具辅助测试,可以很好的了解整个系统,比如数据传输过程前后端的关系,以及整个系统的结构。特别是对现在的微服务架构的产品,抓包能够更好的梳理和掌握整个系统各个服务之间的关系,大大增加测试的覆盖度。另外还可以增进对代码、HTTP协议方面知识的理解。
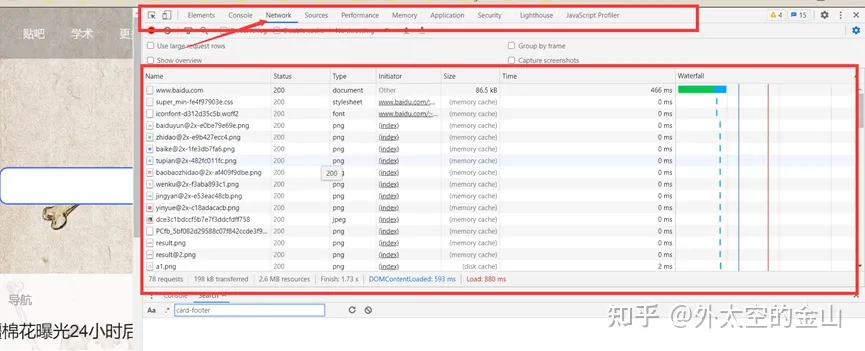
四、常用抓包工具
1、httpwatch:
httpwatch与IE和firefox浏览器集成,但不支持chrome;httpwatch界面清晰直观,发送请求后可以快速简单的查看Cookies, Headers, Query Strings and POST data,能够通过页面分组处理多页面场景。
2、Fiddler:
Fiddler是一个独立的应用,可以调试PC、Mac或Linux系统和移动设备 的之间的通信,支持大部分框架如java、.net、java、Ruby,需要设置代理
3、wireshark
wireshark是一款专业的通过抓取网络数据包进行网络检测,网络协议分析工具,可实时监测网络传输数据,全面透视整个网络的动态信息。
4、firebug
Firebug是firefox下的一个扩展,它除了能进行网络分析还能够调试所有网站语言,如js、Html、Css等,支持各种浏览器如IE、Firefox、Opera,、Safari。
3、网页内容获取
1.Jsoup的使用
可能大部分用户觉得,数据爬取方面 python 很厉害,其实 java 也很厉害,比如我们今天要介绍的这款工具库:Jsoup。
官方解释如下:
jsoup 是一个用于处理 HTML 的 Java 库。它提供了一些非常方便的 API,用于提取和操作 HTML 页面数据,比如 DOM,CSS 等元素。
由于 jsoup 的 API 方法使用上与 jQuery 极其接近,因此如果你了解过 jQuery,那么可以轻而易举地上手这款框架。
那么如何使用它呢,下面我们一起来看看!
快速入门
首先需要在项目中,添加 jsoup 依赖包,以Maven项目为例,本次采用的是1.11.2版本。
<!--添加依赖包-->
<dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.11.2</version>
</dependency>
导入 jsoup 库包之后,我们就可以使用它的 api 对 HTML 文档进行操作了。
jsoup 对 HTML 文档的解析,有三种实现方式。
- 第一种:直接通过 url 连接获取 HTML 文档,然后解析;
- 第二种:通过导入文件的方式,对 HTML 文档进行解析;
- 第三种:通过直接加载 HTML 字符串,对文档进行解析;
我们来一起来看看具体的实现思路。
直接载入 url
// 直接加载百度连接,获取百度首页页面信息
Document document = Jsoup.connect("https://www.baidu.com").get();
System.out.println(document.toString());
通过文件加载文档
创建一个demo.html文件,内容如下:
<!DOCTYPE html>
<html><head><meta charset="utf-8"><title></title></head><body>Hello World!</body>
</html>
然后通过文件加载文档,获取文档信息
// 指定 HTML 文件地址,加载文档
String fileUrl = "/html/demo.html";
Document document = Jsoup.parse(new File(fileUrl), "utf-8" );
System.out.println(document.toString());
通过字符串加载文档
// 定义一个 html 页面的字符串信息
String html = "<html><head><title></title></head><body>Hello World</body></html>";
Document document = Jsoup.parse(html);
System.out.println(document.toString());
通过以上任意的一种方式,都可以实现 HTML 页面文档的加载,获取Document对象。
具体应用
当获取到Document对象之后,我们就可以轻松抓取 HTML 页面中所有的元素信息了,包括 CSS 信息都可以解析出来,详细抓取案例如下!
从 HTML 获取标题信息
案例如下:
// 直接加载百度连接,获取百度首页页面信息
Document document = Jsoup.connect("https://www.baidu.com").get();
// 获取页面标题
System.out.println(document.title());
从 HTML 获取元信息
案例如下:
// 直接加载百度连接,获取百度首页页面信息
Document document = Jsoup.connect("https://www.baidu.com").get();
// 获取元信息中的页面描述内容
String description = document.select("meta[name=description]").first().attr("content");
System.out.println("Meta description : " + description);
从 HTML 获取头部信息
案例如下:
// 直接加载百度连接,获取百度首页页面信息
Document document = Jsoup.connect("https://www.baidu.com").get();
// 获取页面头部标签信息
System.out.println(document.head().toString());
从 HTML 获取内容信息
案例如下:
// 直接加载百度连接,获取百度首页页面信息
Document document = Jsoup.connect("https://www.baidu.com").get();
// 获取页面头部标签信息
System.out.println(document.body().toString());
从 HTML 获取页面所有超链接
案例如下:
// 直接加载百度连接,获取百度首页页面信息
Document document = Jsoup.connect("https://www.baidu.com").get();
// 获取HTML页面中的所有链接
Elements links = document.select("a[href]");
for (Element link : links) {System.out.println("link : " + link.attr("href") + ",java : " + link.java());
}
从 HTML 获取页面所有图片
案例如下:
// 直接加载百度连接,获取百度首页页面信息
Document document = Jsoup.connect("https://www.baidu.com").get();
// 获取HTML页面中的所有图片
Elements images = document.select("img[src~=(?i)\\.(png|jpe?g|gif)]");
for (Element image : images) {String print = new StringBuilder().append("src : " + image.attr("src")).append(",height : " + image.attr("height")).append(",width : " + image.attr("width")).append(",alt : " + image.attr("alt")).toString();System.out.println(print);
}
从 HTML 获取指定标签的内容
案例如下:
String html = "<p><span>hello world</span></p>";
Document document = Jsoup.parse(html);
Elements elements = document.getElementsByTag("span");
System.out.println(elements.toString());
从 HTML 获取指定标签ID的内容
案例如下:
String html = "<p><span id=\"span111\">hello world</span></p>";
Document document = Jsoup.parse(html);
Element element = document.getElementById("span111");
System.out.println(element.toString());
从 HTML 获取指定标签 class 的内容
案例如下:
String html = "<p><span class=\"class111\">hello world</span></p>";
Document document = Jsoup.parse(html);
Elements elements = document.getElementsByClass("class111");
System.out.println(elements.toString());
从 HTML 获取指定标签属性的内容
案例如下:
String html = "<p><span datafld=\"11111\">hello world</span></p>";
Document document = Jsoup.parse(html);
Elements elements = document.getElementsByAttribute("datafld");
System.out.println(elements.first().attributes().html());
从 HTML 获取页面元素中任意内容
如果我们想获取页面上任意一个指定的元素,如何获取呢?
以下面的 HTML 页面表格为例,解析全部数据。
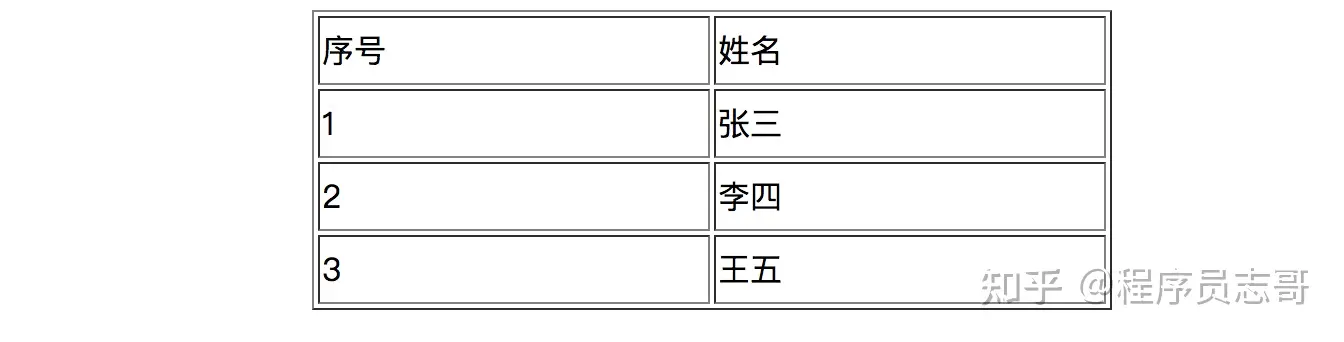
HTML 页面的源代码如下!
<!DOCTYPE html>
<html><head><meta charset="utf-8"><title></title></head><body><table align="center" border="1px" width="400px" height="150px"><tr><td>序号</td><td>姓名</td></tr><tr><td>1</td><td>张三</td></tr><tr><td>2</td><td>李四</td></tr><tr><td>3</td><td>王五</td></tr></table></body>
</html>
使用 Jsoup 库解析,详细的实现过程如下:
// 指定 HTML 文件地址,加载文档
String fileUrl = "/html/demo.html";
Document document = Jsoup.parse(new File(fileUrl), "utf-8" );// 获取table标签,一层一层的解析全部元素
Elements tables = document.body().getElementsByTag("table");
for (int i = 0; i < tables.size(); i++) {// 遍历行Elements trs = tables.get(i).getElementsByTag("tr");for (int j = 0; j < trs.size(); j++) {// 遍历列Elements tds = trs.get(j).getElementsByTag("td");for (int k = 0; k < tds.size(); k++) {int row = j + 1;int cell = k + 1;String print = new StringBuilder().append("第 : " + row + "行,").append("第 : " + cell + "列,").append("内容:" + tds.get(k).java()).toString();System.out.println(print);}}
}
消除不信任的HTML(以防止XSS)
有些时候 HTML 会植入一些恶意脚本,并将用户重定向到另一个脏网站,这可能会导致非常严重的问题,为了清理这个无效的 HTML,Jsoup 提供了Jsoup.clean()方法,可以把不合法的标签,给清理掉。
案例如下:
// 原始文件
String dirtyHTML = "<p><a href='http://www.baidu.com/' οnclick='sendCookiesToMe()'>Link</a></p>";
// 需要清理的标签
String cleanHTML = Jsoup.clean(dirtyHTML, Whitelist.basic());
// 输出结果
System.out.println(cleanHTML);
输出结果如下:
<p><a href="http://www.baidu.com/" rel="nofollow">Link</a></p>
其实现原理的就是通过白名单过滤器,将一些不合法的标签,给过滤掉。
小结
本文主要介绍了,利用 jsoup 工具库解析 HTML 页面文件信息,从而实现页面数据的抓取!
如果想要了解更多的信息,可以参考官网https://jsoup.org/文档进行数据处理!
参考
1、jsoup 官网
2、w3school 网站
请求URL
方法一:
- 创建连接,并使用get()或post()执行请求;
- 按照需求输出HTML
public static void main( String[] args ) throws IOException {Connection connect = Jsoup.connect("https://xxxx.xxxx.com.cn/");Document document = connect.get();Elements links = document.select("a[href]");for (Element link : links) {if(link.java().length()>10){System.out.println("java : " + link.java());}}
}
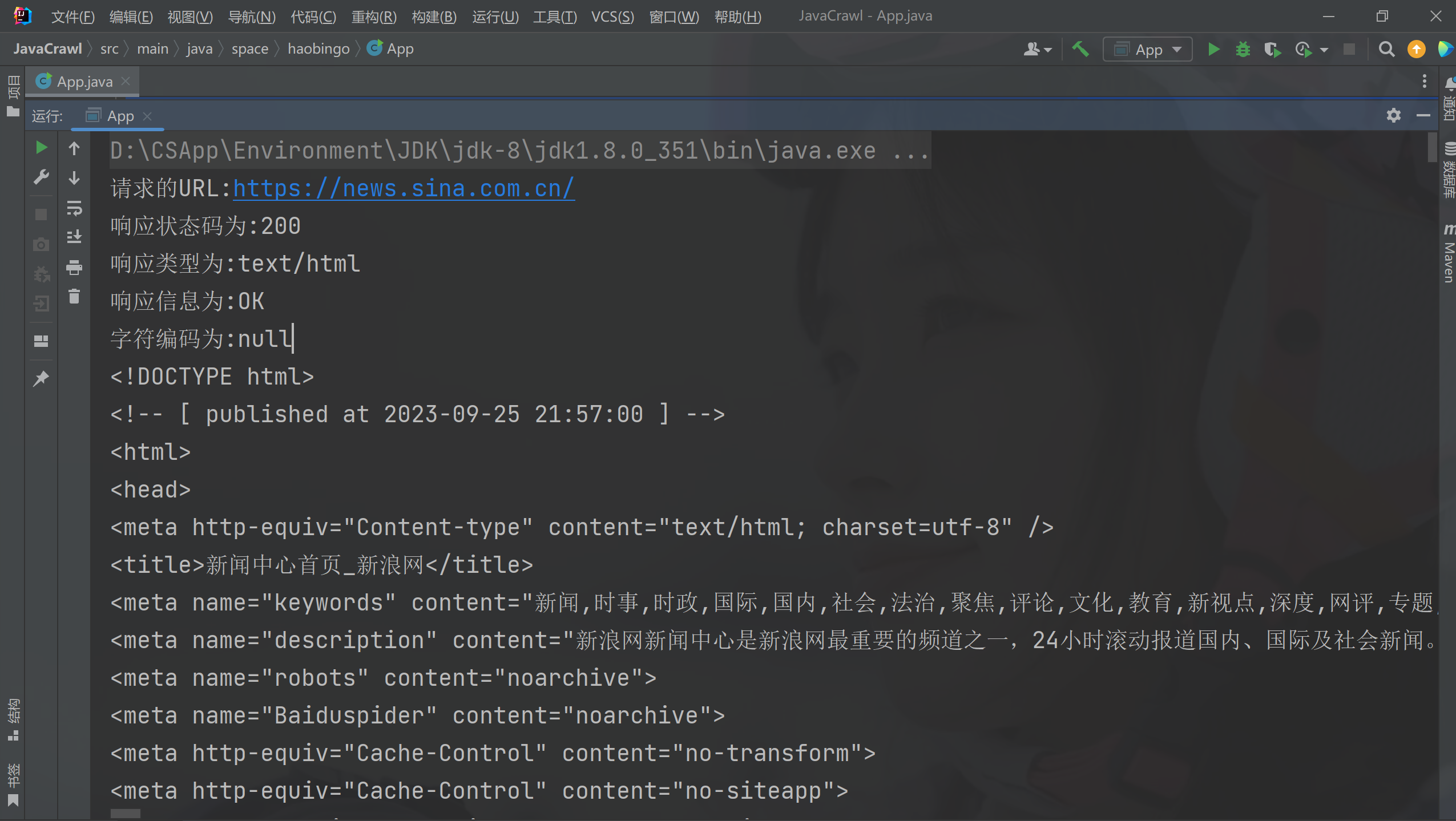
方法二:
- 先获取响应Response
- 在获取HTML内容
public static void main( String[] args ) throws IOException {Connection.Response response = Jsoup.connect("https://news.sina.com.cn/").method(Connection.Method.GET).execute();URL url = response.url();System.out.println("请求的URL:"+url);int statusCode = response.statusCode();System.out.println("响应状态码为:"+statusCode);String contentType = response.contentType();System.out.println("响应类型为:"+contentType);String statusMessage = response.statusMessage();System.out.println("响应信息为:"+statusMessage);if(statusCode==200){String html = new String(response.bodyAsBytes(), "utf-8");Document document = response.parse();System.out.println(html);}
}
设置头信息
目的伪装网络爬虫,使得网络爬虫请求网页更像浏览器访问网页,进而降低网络爬虫被网站封锁的风险。
在网络爬虫中,经常需要设置一些头信息。设置头信息的作用是伪装网络爬虫,使得网络爬虫请求网页更像浏览器访问网页(当然也可以通过java的selenium框架来实现),进而降低网络爬虫被网站封锁的风险。Jsoup中提供了两种设置头信息的方法。
第一种方法:每次只设置一个请求头,如果要设置多个请求头,需要多次调用此方法;第二种方法:添加多个请求头至Map集合。在程序1中,设置了一个请求头。在程序2中,设置了多个请求头,这些请求头来源于网络抓包的内容。
public class JsoupConnectHeader {public static void main(String[] args) throws IOException {Connection connect = Jsoup.connect("https://searchcustomerexperience.techtarget.com/info/news");//设置单个请求头Connection conheader = connect.header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36");Document document = conheader.get();System.out.println(document);}
}
登录后复制
public class JsoupConnectHeaderMap {public static void main(String[] args) throws IOException {Connection connect = Jsoup.connect("https://searchcustomerexperience.techtarget.com/info/news");//设置多个请求头,头信息保存到Map集合中Map<String, String> header = new HashMap<String, String>();header.put("Host", "searchcustomerexperience.techtarget.com");header.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36");header.put("Accept", "java/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8");header.put("Accept-Language", "zh-cn,zh;q=0.5");header.put("Accept-Encoding", "gzip, deflate");header.put("Cache-Control", "max-age=0");header.put("Connection", "keep-alive");Connection conheader = connect.headers(header);Document document = conheader.get();System.out.println(document);}
}
🔑How far you can do?
多少?做到什么程度?数量如何?质量水平如何?费用产出如何?
工作中灵活运用
🚀先看后赞,养成习惯!🚀
🚀 先看后赞,养成习惯!🚀
🎈觉得文章写得不错的老铁们,点赞评论关注走一波!谢谢啦!🎈