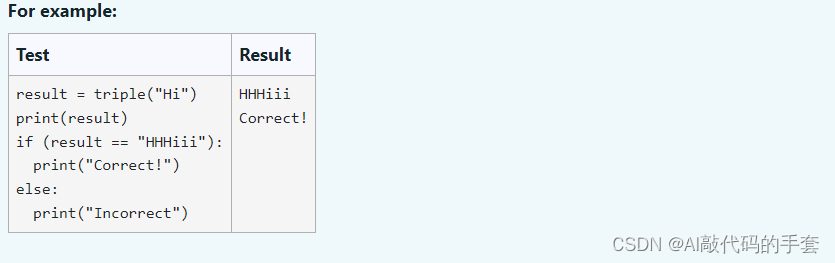
简介
在 PyTorch 中,num_workers 是 DataLoader 中的一个参数,用于控制数据加载的并发线程数。它允许您在数据加载过程中使用多个线程,以提高数据加载的效率。
具体来说,num_workers 参数指定了 DataLoader 在加载数据时将创建的子进程数量。当 num_workers 大于 0 时,DataLoader 会自动利用多个子进程来加速数据加载。这有助于减少主进程的等待时间,并使得数据加载更加并行化。
例如,如果您有一个大型数据集需要加载,而且您的系统有多个 CPU 核心可用,您可以使用 num_workers 参数来提高数据加载的效率。假设您的系统有 4 个 CPU 核心,您可以将 num_workers 设置为 4,以使 DataLoader 在每个核心上创建一个子进程,并行加载数据.
使用方法
下面是一个示例代码,演示了如何使用 num_workers 参数来加速数据加载:
python
import torch
from torch.utils.data import DataLoader
from torchvision import datasets, transforms # 定义数据预处理操作
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]) # 加载数据集
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True) # 创建 DataLoader,设置 num_workers 为 4
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=4) # 训练模型...
在上述示例中,我们使用 MNIST 数据集,设置了 num_workers 为 4,以利用系统的 4 个 CPU 核心并行加载数据。这将加速数据加载的过程,使得模型训练更加高效。
实测效果
我采用MMDetetion训练,它可以通过钩子函数统计每一iter的数据读取耗时(data_time)和总耗时(time)
当num_works设置为1时打印结果如下:
 当num_works设置为4时打印结果如下:
当num_works设置为4时打印结果如下:
 实验效果与理论一致
实验效果与理论一致