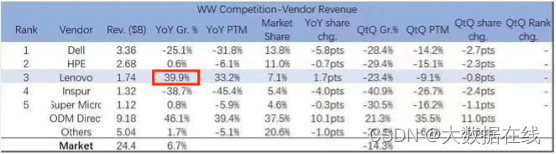
4月5日,Facebook母公司Meta在推特宣布推出SAM模型(Segment Anything Model)并开源。该模型能够查找和分割图像和视频中的任何对象,实现一键抠图。同日,Meta还发布了自称有史以来最大的图像注释数据集,以及30页详解论文《Segment Anything》。

11 亿 + 掩码数据集可提取!
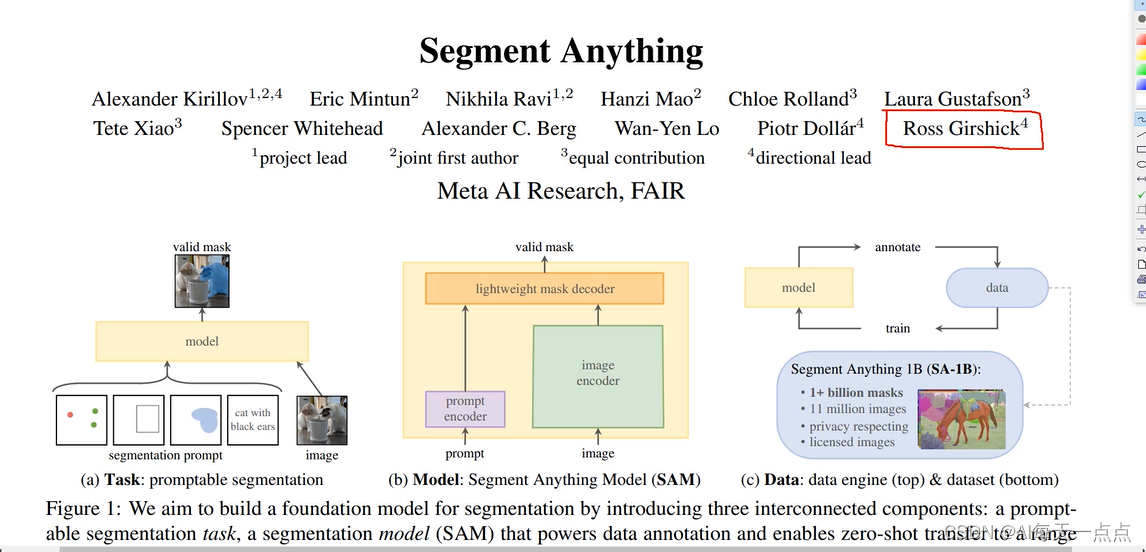
SAM的目标在于精准“分割一切”。相较于广泛可见的手动抠图功能,SAM在操作层面主要有以下几个方面的显著亮点:
第一,万物识别。“零样本性能”是它的强大之处,在面对没有见过的物体时,SAM不需要额外训练也能将它识别出来。
第二,可处理文本、关键点、边界框等多模态提示。如输入具体文字如“CAT”,SAM就可以在图片中分割出物体。第三,给出任意图片,SAM可以自动分割图像中的所有单品并一件件归类。
第四,视频方面,SAM也能准确识别并快速标记,并自动用ID给这些物品进行记录和分类。
第五,SAM接受来自其他系统的输入提示、输出物体信息到其他AI系统。

Meta研发团队在官网上发布了关于Segment Anything的论文细节。


唐宇迪博士也用视频讲解了这个论文和代码
有需要视频和论文代码可以关注公众H:咕泡AI 回复 211 获取
白嫖60G入门到进阶AI资源包(经典论文/书籍/项目课程/学习路线大纲)+带论文/学习/就业/竞赛指导+大牛技术问题答疑
内含:深度学习神经网络+CV计算机视觉学习(两大框架pytorch/tensorflow+源码课件笔记)+NLP等
适用人群
①准备毕业论文的学生
②准备跳槽,正在找工作的AI算法工程师等
③自学和准备转行到AI领域的人
④想巩固AI核心知识,查漏补缺的人