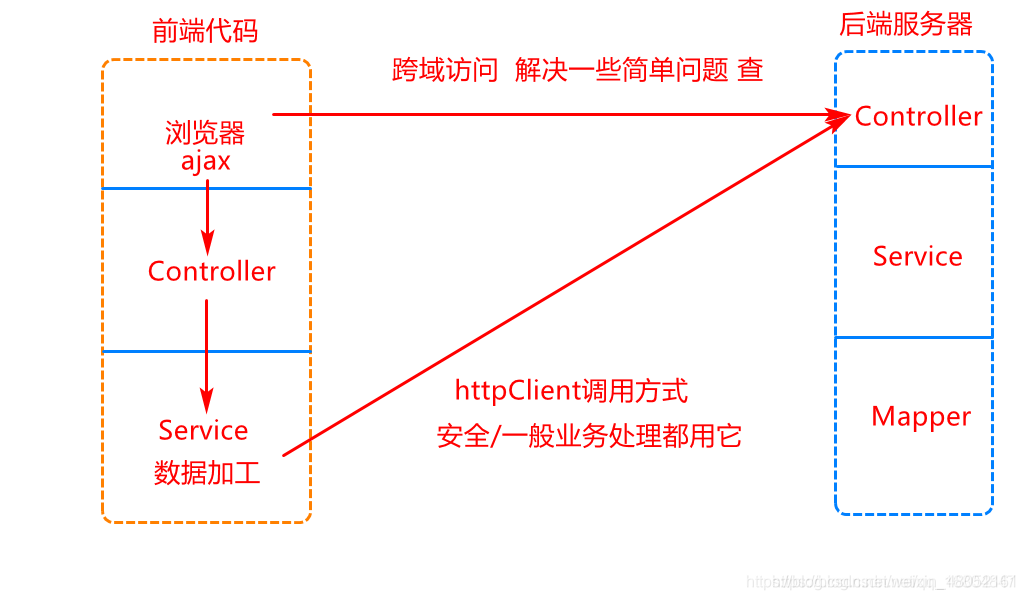
目录
一、Golang的特点
二、构建网络爬虫的步骤
三、关键技术和注意事项
使用协程进行并发处理
使用通道进行协程间的通信
合理控制并发数和处理速度
遵守网站使用协议和法律法规
防止被网站封禁或限制访问
优化网页解析和数据处理
异常处理和错误处理
日志记录和监控
资源释放和优雅退场
四、案例分析
随着互联网的快速发展,网络爬虫已经成为收集和处理大量数据的重要工具。Golang作为一种高效、并发性强的编程语言,非常适合用于构建高性能的网络爬虫。本文将介绍如何使用Golang构建网络爬虫,并探讨其性能优化和注意事项。

一、Golang的特点
Golang(也称为Go)是Google开发的一种静态类型、编译型语言,具有以下特点:
- 高效并发:Golang的并发模型是它的一大特色,支持协程(goroutine)和通道(channel)机制,非常适合处理并发任务。
- 丰富的标准库:Golang提供了丰富的标准库,涵盖了网络、数据处理、文本处理等方面,使得开发人员可以更专注于业务逻辑。
- 跨平台:Golang支持跨平台开发,可以在Windows、Linux、macOS等操作系统上运行。
- 静态类型和编译型:Golang是静态类型、编译型语言,这使得代码更加安全、高效,也便于维护。
二、构建网络爬虫的步骤
使用Golang构建网络爬虫主要包括以下几个步骤:
- 安装Golang:首先需要从官网下载并安装Golang,然后配置好环境变量。
- 创建项目:创建一个新的Golang项目,可以使用命令行工具或集成开发环境(IDE)。
- 导入必要的包:导入Golang中与网络爬虫相关的包,例如
net/http、net/url、io/ioutil等。 - 定义爬虫逻辑:根据需求定义网络爬虫的逻辑,包括请求网页、解析网页、存储数据等操作。
- 实现并发爬取:利用Golang的并发特性,实现多协程并发爬取网页,提高效率。
- 调试和测试:进行调试和测试,确保网络爬虫能够正常工作并达到预期效果。
- 性能优化:针对性能瓶颈进行优化,例如调整并发数、使用更高效的算法等。
- 部署和运行:将网络爬虫部署到服务器或云平台上,并启动运行。
三、关键技术和注意事项
在使用Golang构建网络爬虫时,需要注意以下几点:
使用协程进行并发处理
Golang的协程(goroutine)机制可以方便地实现并发处理。在爬虫中,可以使用协程来同时处理多个网页请求和数据解析任务。例如,可以使用go关键字在函数调用前启动一个协程来并发地处理多个网页爬取任务。
使用通道进行协程间的通信
通道(channel)是Golang中用于协程之间通信的重要机制。在网络爬虫中,可以使用通道来实现协程之间的数据传递和同步。例如,可以使用通道来传递网页内容、状态等信息。
合理控制并发数和处理速度
在实现并发爬取时,需要合理控制并发数和处理速度,以避免对目标网站造成过大的访问压力。可以根据网站的性能和自身需求来调整并发数和处理速度。
遵守网站使用协议和法律法规
在使用网络爬虫时,需要遵守网站的使用协议和相关法律法规。在爬取网页内容时,要尊重网站的版权和隐私权等规定,避免侵犯他人的合法权益。
防止被网站封禁或限制访问
在爬取网页时,需要防止被网站封禁或限制访问。可以设置合理的访问频率、使用代理IP或设置随机的休眠时间来避免被封禁。同时,也需要及时关注网站的动态变化,以避免被限制访问。
优化网页解析和数据处理
网页解析和数据处理是网络爬虫的核心部分,也是性能瓶颈的关键区域。因此,需要对这部分进行优化,以提高爬虫的效率。
- 选择合适的解析库:对于HTML或XML的解析,可以使用Golang自带的
html/template或xml包。但若需要更高效或更复杂的解析,可以考虑使用第三方的解析库,如goquery或jsoup。 - 采用流式数据处理:对于大量数据的处理,采用流式数据处理可以减少内存使用和提升性能。例如,可以使用
bufio包中的Scanner来逐行读取和处理网页内容。 - 利用多核CPU:对于计算密集型的任务,如数据清洗、机器学习等,可以考虑使用多核CPU的并行处理能力。Golang的
sync包提供了ParallelFor函数,可以方便地进行并行处理。
异常处理和错误处理
网络爬虫在运行过程中会遇到各种异常情况和错误,因此需要进行异常处理和错误处理。
- 异常处理:使用
try-catch语句或其他错误处理机制来捕获和处理异常情况,如网络连接失败、网页解析错误等。 - 错误处理:对于关键步骤或可能出错的步骤,应进行错误检查和处理。例如,检查URL是否有效、检查网页是否成功加载等。
日志记录和监控
为了方便调试和监控网络爬虫的运行情况,需要进行日志记录和监控。
- 日志记录:使用Golang的
log包或其他日志库进行日志记录,包括错误信息和关键事件等。 - 监控:通过网络爬虫的性能指标(如请求成功率、响应时间等)进行监控,以便及时发现并解决问题。
资源释放和优雅退场
在编写网络爬虫时,需要注意及时释放资源并优雅地结束程序。
- 关闭连接:在程序结束时,需要关闭打开的网络连接和文件句柄等资源。可以使用Golang的
defer语句来确保资源在程序结束时被关闭。 - 优雅退场:在程序遇到错误或异常情况时,应尽量保证程序的优雅退场,避免留下未完成的请求或文件句柄等资源。可以使用Golang的
os.Exit(1)来强制结束程序。
四、案例分析
这里给出一个简单的案例分析,以帮助你更好地理解如何使用Golang构建网络爬虫。假设我们需要从一个电商网站爬取商品信息并保存到数据库中。
通过遵循上述步骤和建议,你将能够构建一个高效、可扩展且健壮的网络爬虫,并能够根据实际需求进行定制和优化。请注意,在编写网络爬虫时,始终要遵守相关法律法规和网站的使用协议,尊重他人的权益和隐私。
- 环境准备:安装Golang和相关依赖库,配置数据库连接参数。
- 项目结构:创建新的Golang项目,并按照良好的软件工程实践来组织代码结构。例如,将爬虫逻辑放在
spider包中,将数据处理放在processor包中,将数据库操作放在db包中。 - 导入必要的包:导入相关的Golang库,如
net/http、net/url、io/ioutil、regexp等。 - 定义爬虫逻辑:在
spider包中定义爬虫逻辑,包括发送HTTP请求、解析HTML页面、提取商品信息等操作。可以使用正则表达式或HTML解析库来提取所需的信息。 - 实现并发爬取:在主函数中启动多个协程来并发地爬取多个商品页面,并使用通道来传递网页内容和商品信息。可以使用Golang的
sync.WaitGroup来等待所有协程完成。 - 数据处理和存储:在
processor包中定义数据处理逻辑,如清洗数据、去除重复等。然后使用数据库操作库将处理后的数据保存到数据库中。可以使用Golang的database/sql包来进行数据库操作。 - 调试和测试:进行调试和测试,确保爬虫能够正常工作并爬取到预期的商品信息。可以使用Golang的测试框架进行单元测试和集成测试。
- 性能优化:根据性能瓶颈进行优化,例如调整并发数、使用更高效的算法来提取商品信息、使用流式数据处理来减少内存使用等。
- 异常处理和错误处理:在每个关键步骤周围添加错误检查和处理代码,以确保在出现问题时能够及时捕获并处理异常。例如,当请求失败或网页解析错误时,可以记录错误信息并决定是否重新尝试请求或跳过该商品信息。
- 日志记录和监控:使用Golang的
log包或其他日志库进行详细的日志记录,包括每个步骤的执行情况、错误信息和关键事件等。这有助于后续的调试和分析。同时,可以设置监控告警,当出现异常情况或性能指标低于阈值时,及时通知开发人员处理。 - 资源释放和优雅退场:在程序结束时,确保关闭所有打开的网络连接、文件句柄和数据库连接等资源。可以使用Golang的
defer语句来确保这些资源在程序结束时被关闭。此外,当程序遇到错误或异常情况时,应尽量保证程序的优雅退场,避免留下未完成的请求或资源泄漏。 - 可扩展性和可维护性:在设计网络爬虫时,考虑可扩展性和可维护性。将功能和逻辑分离到不同的包和模块中,使得代码结构清晰、易于维护和扩展。同时,使用版本控制工具(如Git)来管理代码变更和协作开发。
- 数据清洗和去重:对于提取到的商品信息,可能需要进行数据清洗和去重处理。例如,去除重复的商品记录、填补缺失的数据字段、转换数据格式等。可以使用Golang的数据处理库(如
strings、strconv、math等)来进行这些操作。 - 多线程和并发控制:在设计网络爬虫时,需要合理控制并发数和访问频率,以避免对目标网站造成过大的访问压力。可以使用Golang的
sync包中的WaitGroup来控制协程的数量和并发访问的频率。 - 代理设置和IP轮询:为了避免被目标网站封禁或限制访问,可以考虑使用代理IP或设置随机的休眠时间来伪装IP地址。可以使用Golang的第三方库(如
goprox)来实现代理设置和IP轮询功能。