转载自:http://datartisan.com/article/detail/48.html
情感分析是一种常见的自然语言处理(NLP)方法的应用,特别是在以提取文本的情感内容为目标的分类方法中。通过这种方式,情感分析可以被视为利用一些情感得分指标来量化定性数据的方法。尽管情绪在很大程度上是主观的,但是情感量化分析已经有很多有用的实践,比如企业分析消费者对产品的反馈信息,或者检测在线评论中的差评信息。
最简单的情感分析方法是利用词语的正负属性来判定。句子中的每个单词都有一个得分,乐观的单词得分为 +1,悲观的单词则为 -1。然后我们对句子中所有单词得分进行加总求和得到一个最终的情感总分。很明显,这种方法有许多局限之处,最重要的一点在于它忽略了上下文的信息。例如,在这个简易模型中,因为“not”的得分为 -1,而“good”的得分为 +1,所以词组“not good”将被归类到中性词组中。尽管词组“not good”中包含单词“good”,但是人们仍倾向于将其归类到悲观词组中。
另外一个常见的方法是将文本视为一个“词袋”。我们将每个文本看出一个1xN的向量,其中N表示文本词汇的数量。该向量中每一列都是一个单词,其对应的值为该单词出现的频数。例如,词组“bag of bag of words”可以被编码为 [2, 2, 1]。这些数据可以被应用到机器学习分类算法中(比如罗吉斯回归或者支持向量机),从而预测未知数据的情感状况。需要注意的是,这种有监督学习的方法要求利用已知情感状况的数据作为训练集。虽然这个方法改进了之前的模型,但是它仍然忽略了上下文的信息和数据集的规模情况。
Word2Vec 和 Doc2Vec
最近,谷歌开发了一个叫做 Word2Vec 的方法,该方法可以在捕捉语境信息的同时压缩数据规模。Word2Vec实际上是两种不同的方法:Continuous Bag of Words (CBOW) 和 Skip-gram。CBOW的目标是根据上下文来预测当前词语的概率。Skip-gram刚好相反:根据当前词语来预测上下文的概率(如图 1 所示)。这两种方法都利用人工神经网络作为它们的分类算法。起初,每个单词都是一个随机 N 维向量。经过训练之后,该算法利用 CBOW 或者 Skip-gram 的方法获得了每个单词的最优向量。

现在这些词向量已经捕捉到上下文的信息。我们可以利用基本代数公式来发现单词之间的关系(比如,“国王”-“男人”+“女人”=“王后”)。这些词向量可以代替词袋用来预测未知数据的情感状况。该模型的优点在于不仅考虑了语境信息还压缩了数据规模(通常情况下,词汇量规模大约在300个单词左右而不是之前模型的100000个单词)。因为神经网络可以替我们提取出这些特征的信息,所以我们仅需要做很少的手动工作。但是由于文本的长度各异,我们可能需要利用所有词向量的平均值作为分类算法的输入值,从而对整个文本文档进行分类处理。
然而,即使上述模型对词向量进行平均处理,我们仍然忽略了单词之间的排列顺序对情感分析的影响。作为一个处理可变长度文本的总结性方法,Quoc Le 和 Tomas Mikolov 提出了 Doc2Vec方法。除了增加一个段落向量以外,这个方法几乎等同于 Word2Vec。和 Word2Vec 一样,该模型也存在两种方法:Distributed Memory(DM) 和 Distributed Bag of Words(DBOW)。DM 试图在给定上下文和段落向量的情况下预测单词的概率。在一个句子或者文档的训练过程中,段落 ID 保持不变,共享着同一个段落向量。DBOW 则在仅给定段落向量的情况下预测段落中一组随机单词的概率。(如图 2 所示)

一旦开始被训练,这些段落向量可以被纳入情感分类器中而不必对单词进行加总处理。这个方法是当前最先进的方法,当它被用于对 IMDB 电影评论数据进行情感分类时,该模型的错分率仅为 7.42%。当然如果我们无法真正实施的话,一切都是浮云。幸运的是,genism(Python 软件库)中 Word2Vec 和 Doc2Vec 的优化版本是可用的。
利用 Python 实现的 Word2Vec 实例
在本节中,我们展示了人们如何在情感分类项目中使用词向量。我们可以在 Anaconda 分发版中找到 genism 库,或者可以通过 pip 安装 genism 库。从这里开始,你可以训练自己语料库(一个文本数据集)的词向量或者从文本格式或二进制格式文件中导入已经训练好的词向量。

我发现利用谷歌预训练好的词向量数据来构建模型是非常有用的,该词向量是基于谷歌新闻数据(大约一千亿个单词)训练所得。需要注意的是,这个文件解压后的大小是 3.5 GB。利用谷歌的词向量我们可以看到单词之间一些有趣的关系:

有趣的是,我们可以从中发现语法关系,比如识别出最高级或单词形态的单词:
“biggest”-“big”+“small”=“smallest”

“ate”-“eat”+“speak”=“spoke”

从上述的例子中我们可以看出 Word2Vec 可以识别单词之间重要的关系。这使得它在许多 NLP 项目和我们的情感分析案例中非常有用。在我们将它运用到情感分析案例之前,让我们先来测试下 Word2Vec 对单词的分类能力。我们将利用三个分类的样本集:食物、运动和天气单词集合,我们可以从Enchanted Learning网中下载得到这三个数据集。由于这是一个 300 维的向量,为了在 2D 视图中对其进行可视化,我们需要利用 Scikit-Learn 中的降维算法 t-SNE 处理源数据。
首先,我们必须获得如下所示的词向量:

然后我们利用 TSNE 和 matplotlib 对分类结果进行可视化处理:

可视化结果如下图所示:

从上图可以看出,Word2Vec 很好地分离了不相关的单词,并对它们进行聚类处理。
Emoji 推文的情感分析
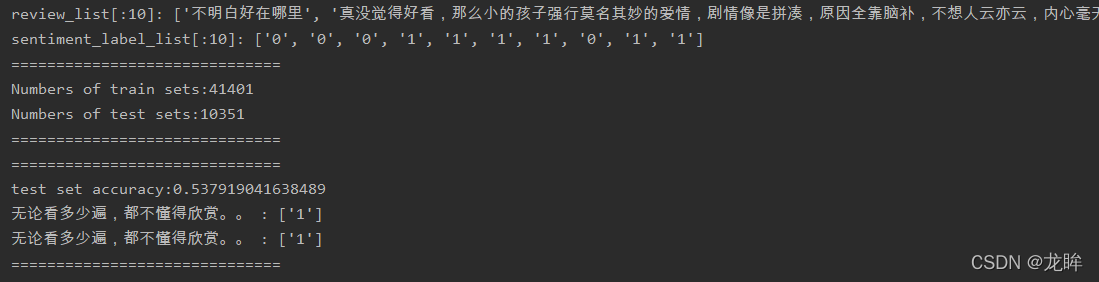
现在我们将分析带有 Emoji 表情推文的情感状况。我们利用 emoji 表情对我们的数据添加模糊的标签。笑脸表情(:-))表示乐观情绪,皱眉标签(:-()表示悲观情绪。总的 400000 条推文被分为乐观和悲观两组数据。我们随机从这两组数据中抽取样本,构建比例为 8:2 的训练集和测试集。随后,我们对训练集数据构建 Word2Vec 模型,其中分类器的输入值为推文中所有词向量的加权平均值。我们可以利用 Scikit-Learn 构建许多机器学习模型。
首先,我们导入数据并构建 Word2Vec 模型:

接下来,为了利用下面的函数获得推文中所有词向量的平均值,我们必须构建作为输入文本的词向量。

调整数据集的量纲是数据标准化处理的一部分,我们通常将数据集转化成服从均值为零的高斯分布,这说明数值大于均值表示乐观,反之则表示悲观。为了使模型更有效,许多机器学习模型需要预先处理数据集的量纲,特别是文本分类器这类具有许多变量的模型。

最后我们需要建立测试集向量并对其标准化处理:

接下来我们想要通过计算测试集的预测精度和 ROC 曲线来验证分类器的有效性。 ROC 曲线衡量当模型参数调整的时候,其真阳性率和假阳性率的变化情况。在我们的案例中,我们调整的是分类器模型截断阈值的概率。一般来说,ROC 曲线下的面积(AUC)越大,该模型的表现越好。你可以在这里找到更多关于 ROC 曲线的资料
(https://en.wikipedia.org/wiki/Receiver_operating_characteristic)
在这个案例中我们使用罗吉斯回归的随机梯度下降法作为分类器算法。

随后我们利用 matplotlib 和 metric 库来构建 ROC 曲线。

ROC 曲线如下图所示:

在没有创建任何类型的特性和最小文本预处理的情况下,我们利用 Scikit-Learn 构建的简单线性模型的预测精度为 73%。有趣的是,删除标点符号会影响预测精度,这说明 Word2Vec 模型可以提取出文档中符号所包含的信息。处理单独的单词,训练更长时间,做更多的数据预处理工作,和调整模型的参数都可以提高预测精度。我发现使用人工神经网络(ANNs)模型可以提高 5% 的预测精度。需要注意的是,Scikit-Learn 没有提供 ANN 分类器的实现工具,所以我利用了自己创建的自定义库:

分类结果的精度为 77%。对于任何机器学习项目来说,选择正确的模型通常是一种艺术而非科学的行为。如果你想要使用我自定义的库,你可以在我的 github 主页上找到它,但是这个库非常混乱而且没有定期维护!如果你想要贡献自己的力量,请随时复刻我的项目。
利用 Doc2Vec 分析电影评论数据
利用词向量均值对推文进行分析效果不错,这是因为推文通常只有十几个单词,所以即使经过平均化处理仍能保持相关的特性。一旦我们开始分析段落数据时,如果忽略上下文和单词顺序的信息,那么我们将会丢掉许多重要的信息。在这种情况下,最好是使用 Doc2Vec 来创建输入信息。作为一个示例,我们将使用 IMDB 电影评论数据及来测试 Doc2Vec 在情感分析中的有效性。该数据集包含 25000 条乐观的电影评论,25000 条悲观评论和 50000 条尚未添加标签的评论。我们首先对未添加标签的评论数据构建 Doc2Vec 模型:

这个代码创建了 LabeledSentence 类型的对象:

接下来,我们举例说明 Doc2Vec 的两个模型,DM 和 DBOW。gensim 的说明文档建议多次训练数据集并调整学习速率或在每次训练中打乱输入信息的顺序。我们从Doc2Vec 模型中获得电影评论向量。

现在我们准备利用评论向量构建分类器模型。我们将再次使用 sklearn 中的 SGDClassifier。

这个模型的预测精度为 86%,我们还可以利用下面的代码绘制 ROC 曲线:


原论文中声称:与简单罗吉斯回归模型相比,他们利用 50 个节点的神经网络分类器能获得较高的预测精度。

有趣的是,在这里我们并没有看到这样的改进效果。该模型的预测精度为 85%,我们没有看到他们所声称的 7.42% 误差率。这可能存在以下几个原因:我们没有对训练集和测试集进行足够多的训练,他们的 Doc2Vec 和 ANN 的实现方法不一样等原因。因为论文中没有详细的说明,所以我们很难知道到底是哪个原因。不管这么说,没有经过很多的数据预处理和变量选择过程,我们仍然取得了 86% 的预测精度。而且这不需要复杂的卷积和树图资料库。
结论
我希望你已经看到 Word2Vec 和 Doc2Vec 的实用性和便捷性。通过一个非常简单的算法,我们可以获得丰富的词向量和段落向量,这些向量数据可以被应用到各种各样的 NLP 应用中。更关键的是谷歌公司开放了他们自己的预训练词向量结果,这个词向量是基于一个别人难以获取的大数据集而训练得到的。如果你想要在大数据集中训练自己的向量结果,现在已经有一个基于 Apache Spark 的 Word2Vec 实现工具。
(https://spark.apache.org/mllib/)
原文链接:
https://districtdatalabs.silvrback.com/modern-methods-for-sentiment-analysis
原文作者:Michael Czerny
翻译:Fibears