1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
随着计算机视觉技术的不断发展,图像分割成为了一个重要的研究领域。图像分割可以将图像中的不同对象或区域进行分离,从而更好地理解图像内容。在农业领域,图像分割技术可以应用于农作物的生长监测、病虫害检测和果实分级等方面。其中,草莓分级分割系统是一个具有重要意义的研究方向。
草莓是一种重要的经济作物,其分级分割对于草莓的质量控制和市场竞争力具有重要意义。传统的草莓分级分割通常依赖于人工进行,效率低下且易受主观因素影响。因此,开发一种自动化的草莓分级分割系统具有重要的实际意义。
目前,基于深度学习的图像分割方法已经取得了显著的进展。YOLOV8是一种常用的目标检测算法,其通过将图像分割为多个网格,并在每个网格中预测目标的位置和类别,实现了实时目标检测。然而,YOLOV8在草莓分级分割中存在一些问题,如对小尺寸草莓的检测不准确、对草莓形状的识别能力较弱等。
为了解决这些问题,本研究提出了一种改进的YOLOV8草莓分级分割系统,该系统融合了动态蛇形卷积和DCNV2。动态蛇形卷积是一种新颖的卷积操作,可以更好地捕捉草莓的形状信息。DCNV2是一种轻量级的网络结构,可以提高模型的检测性能和运行速度。通过将这两种技术融合到YOLOV8中,我们可以提高草莓分级分割系统的准确性和效率。
本研究的意义主要体现在以下几个方面:
首先,改进的YOLOV8草莓分级分割系统可以提高草莓分级的准确性。通过引入动态蛇形卷积,我们可以更好地捕捉草莓的形状信息,从而提高对小尺寸草莓的检测准确性。同时,DCNV2的应用可以提高模型的检测性能,进一步提高分级分割的准确性。
其次,改进的系统可以提高草莓分级分割的效率。DCNV2是一种轻量级的网络结构,可以减少模型的参数量和计算量,从而提高系统的运行速度。这对于实时草莓分级分割系统来说尤为重要,可以提高生产效率和降低成本。
最后,本研究的成果对于农业领域的发展具有重要意义。自动化的草莓分级分割系统可以提高草莓的质量控制和市场竞争力,对于农民和企业来说具有重要的经济效益。同时,该系统的研究也为其他农作物的分级分割提供了借鉴和参考。
综上所述,改进的YOLOV8草莓分级分割系统具有重要的研究意义和实际应用价值。通过融合动态蛇形卷积和DCNV2,我们可以提高草莓分级分割的准确性和效率,为农业领域的发展做出贡献。
2.图片演示



3.视频演示
【改进YOLOV8】融合动态蛇形卷积&DCNV2的草莓分级分割分割系统_哔哩哔哩_bilibili
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集CMDatasets。

eiseg是一个图形化的图像注释工具,支持COCO和YOLO格式。以下是使用eiseg将图片标注为COCO格式的步骤:
(1)下载并安装eiseg。
(2)打开eiseg并选择“Open Dir”来选择你的图片目录。
(3)为你的目标对象设置标签名称。
(4)在图片上绘制矩形框,选择对应的标签。
(5)保存标注信息,这将在图片目录下生成一个与图片同名的JSON文件。
(6)重复此过程,直到所有的图片都标注完毕。
由于YOLO使用的是txt格式的标注,我们需要将VOC格式转换为YOLO格式。可以使用各种转换工具或脚本来实现。
下面是一个简单的方法是使用Python脚本,该脚本读取XML文件,然后将其转换为YOLO所需的txt格式。
import contextlib
import jsonimport cv2
import pandas as pd
from PIL import Image
from collections import defaultdictfrom utils import *# Convert INFOLKS JSON file into YOLO-format labels ----------------------------
def convert_infolks_json(name, files, img_path):# Create folderspath = make_dirs()# Import jsondata = []for file in glob.glob(files):with open(file) as f:jdata = json.load(f)jdata['json_file'] = filedata.append(jdata)# Write images and shapesname = path + os.sep + namefile_id, file_name, wh, cat = [], [], [], []for x in tqdm(data, desc='Files and Shapes'):f = glob.glob(img_path + Path(x['json_file']).stem + '.*')[0]file_name.append(f)wh.append(exif_size(Image.open(f))) # (width, height)cat.extend(a['classTitle'].lower() for a in x['output']['objects']) # categories# filenamewith open(name + '.txt', 'a') as file:file.write('%s\n' % f)# Write *.names filenames = sorted(np.unique(cat))# names.pop(names.index('Missing product')) # removewith open(name + '.names', 'a') as file:[file.write('%s\n' % a) for a in names]# Write labels filefor i, x in enumerate(tqdm(data, desc='Annotations')):label_name = Path(file_name[i]).stem + '.txt'with open(path + '/labels/' + label_name, 'a') as file:for a in x['output']['objects']:# if a['classTitle'] == 'Missing product':# continue # skipcategory_id = names.index(a['classTitle'].lower())# The INFOLKS bounding box format is [x-min, y-min, x-max, y-max]box = np.array(a['points']['exterior'], dtype=np.float32).ravel()box[[0, 2]] /= wh[i][0] # normalize x by widthbox[[1, 3]] /= wh[i][1] # normalize y by heightbox = [box[[0, 2]].mean(), box[[1, 3]].mean(), box[2] - box[0], box[3] - box[1]] # xywhif (box[2] > 0.) and (box[3] > 0.): # if w > 0 and h > 0file.write('%g %.6f %.6f %.6f %.6f\n' % (category_id, *box))# Split data into train, test, and validate filessplit_files(name, file_name)write_data_data(name + '.data', nc=len(names))print(f'Done. Output saved to {os.getcwd() + os.sep + path}')# Convert vott JSON file into YOLO-format labels -------------------------------
def convert_vott_json(name, files, img_path):# Create folderspath = make_dirs()name = path + os.sep + name# Import jsondata = []for file in glob.glob(files):with open(file) as f:jdata = json.load(f)jdata['json_file'] = filedata.append(jdata)# Get all categoriesfile_name, wh, cat = [], [], []for i, x in enumerate(tqdm(data, desc='Files and Shapes')):with contextlib.suppress(Exception):cat.extend(a['tags'][0] for a in x['regions']) # categories# Write *.names filenames = sorted(pd.unique(cat))with open(name + '.names', 'a') as file:[file.write('%s\n' % a) for a in names]# Write labels filen1, n2 = 0, 0missing_images = []for i, x in enumerate(tqdm(data, desc='Annotations')):f = glob.glob(img_path + x['asset']['name'] + '.jpg')if len(f):f = f[0]file_name.append(f)wh = exif_size(Image.open(f)) # (width, height)n1 += 1if (len(f) > 0) and (wh[0] > 0) and (wh[1] > 0):n2 += 1# append filename to listwith open(name + '.txt', 'a') as file:file.write('%s\n' % f)# write labelsfilelabel_name = Path(f).stem + '.txt'with open(path + '/labels/' + label_name, 'a') as file:for a in x['regions']:category_id = names.index(a['tags'][0])# The INFOLKS bounding box format is [x-min, y-min, x-max, y-max]box = a['boundingBox']box = np.array([box['left'], box['top'], box['width'], box['height']]).ravel()box[[0, 2]] /= wh[0] # normalize x by widthbox[[1, 3]] /= wh[1] # normalize y by heightbox = [box[0] + box[2] / 2, box[1] + box[3] / 2, box[2], box[3]] # xywhif (box[2] > 0.) and (box[3] > 0.): # if w > 0 and h > 0file.write('%g %.6f %.6f %.6f %.6f\n' % (category_id, *box))else:missing_images.append(x['asset']['name'])print('Attempted %g json imports, found %g images, imported %g annotations successfully' % (i, n1, n2))if len(missing_images):print('WARNING, missing images:', missing_images)# Split data into train, test, and validate filessplit_files(name, file_name)print(f'Done. Output saved to {os.getcwd() + os.sep + path}')# Convert ath JSON file into YOLO-format labels --------------------------------
def convert_ath_json(json_dir): # dir contains json annotations and images# Create foldersdir = make_dirs() # output directoryjsons = []for dirpath, dirnames, filenames in os.walk(json_dir):jsons.extend(os.path.join(dirpath, filename)for filename in [f for f in filenames if f.lower().endswith('.json')])# Import jsonn1, n2, n3 = 0, 0, 0missing_images, file_name = [], []for json_file in sorted(jsons):with open(json_file) as f:data = json.load(f)# # Get classes# try:# classes = list(data['_via_attributes']['region']['class']['options'].values()) # classes# except:# classes = list(data['_via_attributes']['region']['Class']['options'].values()) # classes# # Write *.names file# names = pd.unique(classes) # preserves sort order# with open(dir + 'data.names', 'w') as f:# [f.write('%s\n' % a) for a in names]# Write labels filefor x in tqdm(data['_via_img_metadata'].values(), desc=f'Processing {json_file}'):image_file = str(Path(json_file).parent / x['filename'])f = glob.glob(image_file) # image fileif len(f):f = f[0]file_name.append(f)wh = exif_size(Image.open(f)) # (width, height)n1 += 1 # all imagesif len(f) > 0 and wh[0] > 0 and wh[1] > 0:label_file = dir + 'labels/' + Path(f).stem + '.txt'nlabels = 0try:with open(label_file, 'a') as file: # write labelsfile# try:# category_id = int(a['region_attributes']['class'])# except:# category_id = int(a['region_attributes']['Class'])category_id = 0 # single-classfor a in x['regions']:# bounding box format is [x-min, y-min, x-max, y-max]box = a['shape_attributes']box = np.array([box['x'], box['y'], box['width'], box['height']],dtype=np.float32).ravel()box[[0, 2]] /= wh[0] # normalize x by widthbox[[1, 3]] /= wh[1] # normalize y by heightbox = [box[0] + box[2] / 2, box[1] + box[3] / 2, box[2],box[3]] # xywh (left-top to center x-y)if box[2] > 0. and box[3] > 0.: # if w > 0 and h > 0file.write('%g %.6f %.6f %.6f %.6f\n' % (category_id, *box))n3 += 1nlabels += 1if nlabels == 0: # remove non-labelled images from datasetos.system(f'rm {label_file}')# print('no labels for %s' % f)continue # next file# write imageimg_size = 4096 # resize to maximumimg = cv2.imread(f) # BGRassert img is not None, 'Image Not Found ' + fr = img_size / max(img.shape) # size ratioif r < 1: # downsize if necessaryh, w, _ = img.shapeimg = cv2.resize(img, (int(w * r), int(h * r)), interpolation=cv2.INTER_AREA)ifile = dir + 'images/' + Path(f).nameif cv2.imwrite(ifile, img): # if success append image to listwith open(dir + 'data.txt', 'a') as file:file.write('%s\n' % ifile)n2 += 1 # correct imagesexcept Exception:os.system(f'rm {label_file}')print(f'problem with {f}')else:missing_images.append(image_file)nm = len(missing_images) # number missingprint('\nFound %g JSONs with %g labels over %g images. Found %g images, labelled %g images successfully' %(len(jsons), n3, n1, n1 - nm, n2))if len(missing_images):print('WARNING, missing images:', missing_images)# Write *.names filenames = ['knife'] # preserves sort orderwith open(dir + 'data.names', 'w') as f:[f.write('%s\n' % a) for a in names]# Split data into train, test, and validate filessplit_rows_simple(dir + 'data.txt')write_data_data(dir + 'data.data', nc=1)print(f'Done. Output saved to {Path(dir).absolute()}')def convert_coco_json(json_dir='../coco/annotations/', use_segments=False, cls91to80=False):save_dir = make_dirs() # output directorycoco80 = coco91_to_coco80_class()# Import jsonfor json_file in sorted(Path(json_dir).resolve().glob('*.json')):fn = Path(save_dir) / 'labels' / json_file.stem.replace('instances_', '') # folder namefn.mkdir()with open(json_file) as f:data = json.load(f)# Create image dictimages = {'%g' % x['id']: x for x in data['images']}# Create image-annotations dictimgToAnns = defaultdict(list)for ann in data['annotations']:imgToAnns[ann['image_id']].append(ann)# Write labels filefor img_id, anns in tqdm(imgToAnns.items(), desc=f'Annotations {json_file}'):img = images['%g' % img_id]h, w, f = img['height'], img['width'], img['file_name']bboxes = []segments = []for ann in anns:if ann['iscrowd']:continue# The COCO box format is [top left x, top left y, width, height]box = np.array(ann['bbox'], dtype=np.float64)box[:2] += box[2:] / 2 # xy top-left corner to centerbox[[0, 2]] /= w # normalize xbox[[1, 3]] /= h # normalize yif box[2] <= 0 or box[3] <= 0: # if w <= 0 and h <= 0continuecls = coco80[ann['category_id'] - 1] if cls91to80 else ann['category_id'] - 1 # classbox = [cls] + box.tolist()if box not in bboxes:bboxes.append(box)# Segmentsif use_segments:if len(ann['segmentation']) > 1:s = merge_multi_segment(ann['segmentation'])s = (np.concatenate(s, axis=0) / np.array([w, h])).reshape(-1).tolist()else:s = [j for i in ann['segmentation'] for j in i] # all segments concatenateds = (np.array(s).reshape(-1, 2) / np.array([w, h])).reshape(-1).tolist()s = [cls] + sif s not in segments:segments.append(s)# Writewith open((fn / f).with_suffix('.txt'), 'a') as file:for i in range(len(bboxes)):line = *(segments[i] if use_segments else bboxes[i]), # cls, box or segmentsfile.write(('%g ' * len(line)).rstrip() % line + '\n')def min_index(arr1, arr2):"""Find a pair of indexes with the shortest distance. Args:arr1: (N, 2).arr2: (M, 2).Return:a pair of indexes(tuple)."""dis = ((arr1[:, None, :] - arr2[None, :, :]) ** 2).sum(-1)return np.unravel_index(np.argmin(dis, axis=None), dis.shape)def merge_multi_segment(segments):"""Merge multi segments to one list.Find the coordinates with min distance between each segment,then connect these coordinates with one thin line to merge all segments into one.Args:segments(List(List)): original segmentations in coco's json file.like [segmentation1, segmentation2,...], each segmentation is a list of coordinates."""s = []segments = [np.array(i).reshape(-1, 2) for i in segments]idx_list = [[] for _ in range(len(segments))]# record the indexes with min distance between each segmentfor i in range(1, len(segments)):idx1, idx2 = min_index(segments[i - 1], segments[i])idx_list[i - 1].append(idx1)idx_list[i].append(idx2)# use two round to connect all the segmentsfor k in range(2):# forward connectionif k == 0:for i, idx in enumerate(idx_list):# middle segments have two indexes# reverse the index of middle segmentsif len(idx) == 2 and idx[0] > idx[1]:idx = idx[::-1]segments[i] = segments[i][::-1, :]segments[i] = np.roll(segments[i], -idx[0], axis=0)segments[i] = np.concatenate([segments[i], segments[i][:1]])# deal with the first segment and the last oneif i in [0, len(idx_list) - 1]:s.append(segments[i])else:idx = [0, idx[1] - idx[0]]s.append(segments[i][idx[0]:idx[1] + 1])else:for i in range(len(idx_list) - 1, -1, -1):if i not in [0, len(idx_list) - 1]:idx = idx_list[i]nidx = abs(idx[1] - idx[0])s.append(segments[i][nidx:])return sdef delete_dsstore(path='../datasets'):# Delete apple .DS_store filesfrom pathlib import Pathfiles = list(Path(path).rglob('.DS_store'))print(files)for f in files:f.unlink()if __name__ == '__main__':source = 'COCO'if source == 'COCO':convert_coco_json('./annotations', # directory with *.jsonuse_segments=True,cls91to80=True)elif source == 'infolks': # Infolks https://infolks.info/convert_infolks_json(name='out',files='../data/sm4/json/*.json',img_path='../data/sm4/images/')elif source == 'vott': # VoTT https://github.com/microsoft/VoTTconvert_vott_json(name='data',files='../../Downloads/athena_day/20190715/*.json',img_path='../../Downloads/athena_day/20190715/') # images folderelif source == 'ath': # ath formatconvert_ath_json(json_dir='../../Downloads/athena/') # images folder# zip results# os.system('zip -r ../coco.zip ../coco')整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----datasets-----coco128-seg|-----images| |-----train| |-----valid| |-----test||-----labels| |-----train| |-----valid| |-----test|模型训练
Epoch gpu_mem box obj cls labels img_size1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]all 3395 17314 0.994 0.957 0.0957 0.0843Epoch gpu_mem box obj cls labels img_size2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]all 3395 17314 0.996 0.956 0.0957 0.0845Epoch gpu_mem box obj cls labels img_size3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代码讲解
5.1 predict.py
class DetectionPredictor(BasePredictor):def postprocess(self, preds, img, orig_imgs):preds = ops.non_max_suppression(preds,self.args.conf,self.args.iou,agnostic=self.args.agnostic_nms,max_det=self.args.max_det,classes=self.args.classes)if not isinstance(orig_imgs, list):orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)results = []for i, pred in enumerate(preds):orig_img = orig_imgs[i]pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)img_path = self.batch[0][i]results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred))return results
这个程序文件是一个名为predict.py的文件,它是一个基于检测模型进行预测的类DetectionPredictor的定义。该类继承自BasePredictor类,并实现了postprocess方法用于后处理预测结果。
在postprocess方法中,首先对预测结果进行非最大抑制操作,根据设定的置信度阈值和重叠度阈值对预测框进行筛选。然后,将输入的图像转换为numpy数组,并根据原始图像的尺寸对预测框进行缩放。最后,将处理后的结果封装成Results对象,并返回一个Results对象列表。
该程序文件使用了Ultralytics YOLO库,是一个基于AGPL-3.0许可的开源项目。它提供了一些工具函数和类,用于进行目标检测模型的预测操作。在使用该程序文件时,可以通过设置参数来指定模型文件和输入数据源,然后创建DetectionPredictor对象,并调用predict_cli方法进行预测操作。
5.2 train.py
from copy import copy
import numpy as np
from ultralytics.data import build_dataloader, build_yolo_dataset
from ultralytics.engine.trainer import BaseTrainer
from ultralytics.models import yolo
from ultralytics.nn.tasks import DetectionModel
from ultralytics.utils import LOGGER, RANK
from ultralytics.utils.torch_utils import de_parallel, torch_distributed_zero_firstclass DetectionTrainer(BaseTrainer):def build_dataset(self, img_path, mode='train', batch=None):gs = max(int(de_parallel(self.model).stride.max() if self.model else 0), 32)return build_yolo_dataset(self.args, img_path, batch, self.data, mode=mode, rect=mode == 'val', stride=gs)def get_dataloader(self, dataset_path, batch_size=16, rank=0, mode='train'):assert mode in ['train', 'val']with torch_distributed_zero_first(rank):dataset = self.build_dataset(dataset_path, mode, batch_size)shuffle = mode == 'train'if getattr(dataset, 'rect', False) and shuffle:LOGGER.warning("WARNING ⚠️ 'rect=True' is incompatible with DataLoader shuffle, setting shuffle=False")shuffle = Falseworkers = 0return build_dataloader(dataset, batch_size, workers, shuffle, rank)def preprocess_batch(self, batch):batch['img'] = batch['img'].to(self.device, non_blocking=True).float() / 255return batchdef set_model_attributes(self):self.model.nc = self.data['nc']self.model.names = self.data['names']self.model.args = self.argsdef get_model(self, cfg=None, weights=None, verbose=True):model = DetectionModel(cfg, nc=self.data['nc'], verbose=verbose and RANK == -1)if weights:model.load(weights)return modeldef get_validator(self):self.loss_names = 'box_loss', 'cls_loss', 'dfl_loss'return yolo.detect.DetectionValidator(self.test_loader, save_dir=self.save_dir, args=copy(self.args))def label_loss_items(self, loss_items=None, prefix='train'):keys = [f'{prefix}/{x}' for x in self.loss_names]if loss_items is not None:loss_items = [round(float(x), 5) for x in loss_items]return dict(zip(keys, loss_items))else:return keysdef progress_string(self):return ('\n' + '%11s' *(4 + len(self.loss_names))) % ('Epoch', 'GPU_mem', *self.loss_names, 'Instances', 'Size')def plot_training_samples(self, batch, ni):plot_images(images=batch['img'],batch_idx=batch['batch_idx'],cls=batch['cls'].squeeze(-1),bboxes=batch['bboxes'],paths=batch['im_file'],fname=self.save_dir / f'train_batch{ni}.jpg',on_plot=self.on_plot)def plot_metrics(self):plot_results(file=self.csv, on_plot=self.on_plot)def plot_training_labels(self):boxes = np.concatenate([lb['bboxes'] for lb in self.train_loader.dataset.labels], 0)cls = np.concatenate([lb['cls'] for lb in self.train_loader.dataset.labels], 0)plot_labels(boxes, cls.squeeze(), names=self.data['names'], save_dir=self.save_dir, on_plot=self.on_plot)
这个程序文件是一个用于训练目标检测模型的程序。它使用了Ultralytics YOLO库,其中包含了构建数据集、构建数据加载器、构建模型、训练模型等功能。
程序文件中的DetectionTrainer类继承自BaseTrainer类,用于基于目标检测模型进行训练。它包含了构建数据集、构建数据加载器、预处理数据、构建模型、训练模型等方法。
程序文件中的build_dataset方法用于构建YOLO数据集,get_dataloader方法用于构建数据加载器,preprocess_batch方法用于预处理数据,set_model_attributes方法用于设置模型属性,get_model方法用于获取YOLO检测模型,get_validator方法用于获取模型验证器,label_loss_items方法用于返回带有标签的训练损失项,progress_string方法用于返回训练进度的格式化字符串,plot_training_samples方法用于绘制训练样本及其注释,plot_metrics方法用于绘制指标图表,plot_training_labels方法用于创建带有标签的训练图表。
在main函数中,首先定义了训练的参数,然后创建了DetectionTrainer对象,并调用其train方法进行训练。
5.5 backbone\convnextv2.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import trunc_normal_, DropPathclass LayerNorm(nn.Module):def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):super().__init__()self.weight = nn.Parameter(torch.ones(normalized_shape))self.bias = nn.Parameter(torch.zeros(normalized_shape))self.eps = epsself.data_format = data_formatif self.data_format not in ["channels_last", "channels_first"]:raise NotImplementedError self.normalized_shape = (normalized_shape, )def forward(self, x):if self.data_format == "channels_last":return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)elif self.data_format == "channels_first":u = x.mean(1, keepdim=True)s = (x - u).pow(2).mean(1, keepdim=True)x = (x - u) / torch.sqrt(s + self.eps)x = self.weight[:, None, None] * x + self.bias[:, None, None]return xclass GRN(nn.Module):def __init__(self, dim):super().__init__()self.gamma = nn.Parameter(torch.zeros(1, 1, 1, dim))self.beta = nn.Parameter(torch.zeros(1, 1, 1, dim))def forward(self, x):Gx = torch.norm(x, p=2, dim=(1,2), keepdim=True)Nx = Gx / (Gx.mean(dim=-1, keepdim=True) + 1e-6)return self.gamma * (x * Nx) + self.beta + xclass Block(nn.Module):def __init__(self, dim, drop_path=0.):super().__init__()self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim)self.norm = LayerNorm(dim, eps=1e-6)self.pwconv1 = nn.Linear(dim, 4 * dim)self.act = nn.GELU()self.grn = GRN(4 * dim)self.pwconv2 = nn.Linear(4 * dim, dim)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()def forward(self, x):input = xx = self.dwconv(x)x = x.permute(0, 2, 3, 1)x = self.norm(x)x = self.pwconv1(x)x = self.act(x)x = self.grn(x)x = self.pwconv2(x)x = x.permute(0, 3, 1, 2)x = input + self.drop_path(x)return xclass ConvNeXtV2(nn.Module):def __init__(self, in_chans=3, num_classes=1000, depths=[3, 3, 9, 3], dims=[96, 192, 384, 768], drop_path_rate=0., head_init_scale=1.):super().__init__()self.depths = depthsself.downsample_layers = nn.ModuleList()stem = nn.Sequential(nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),LayerNorm(dims[0], eps=1e-6, data_format="channels_first"))self.downsample_layers.append(stem)for i in range(3):downsample_layer = nn.Sequential(LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),)self.downsample_layers.append(downsample_layer)self.stages = nn.ModuleList()dp_rates=[x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] cur = 0for i in range(4):stage = nn.Sequential(*[Block(dim=dims[i], drop_path=dp_rates[cur + j]) for j in range(depths[i])])self.stages.append(stage)cur += depths[i]self.norm = nn.LayerNorm(dims[-1], eps=1e-6)self.head = nn.Linear(dims[-1], num_classes)self.apply(self._init_weights)self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]def _init_weights(self, m):if isinstance(m, (nn.Conv2d, nn.Linear)):trunc_normal_(m.weight, std=.02)nn.init.constant_(m.bias, 0)def forward(self, x):res = []for i in range(4):x = self.downsample_layers[i](x)x = self.stages[i](x)res.append(x)return res
该程序文件是一个实现了ConvNeXt V2模型的Python代码。ConvNeXt V2是一个用于图像分类任务的卷积神经网络模型。该模型包含了多个不同分辨率的特征提取阶段,每个阶段由多个残差块组成。模型还包含了一些辅助的层,如LayerNorm和GRN,用于规范化和调整特征。最后,模型通过一个全连接层将提取的特征映射到类别概率。该程序文件还提供了不同规模的ConvNeXt V2模型的实例化函数,可以根据需要选择不同规模的模型进行使用。
5.6 backbone\CSwomTramsformer.py
class CSWinTransformer(nn.Module):def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000, embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24], mlp_ratio=4., qkv_bias=True, qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm):super().__init__()self.num_classes = num_classesself.depths = depthsself.num_features = self.embed_dim = embed_dimself.patch_embed = PatchEmbed(img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)self.pos_drop = nn.Dropout(p=drop_rate)dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay ruleself.blocks = nn.ModuleList([CSWinBlock(dim=embed_dim, reso=img_size // patch_size, num_heads=num_heads[i], mlp_ratio=mlp_ratio,qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate,drop_path=dpr[sum(depths[:i]):sum(depths[:i + 1])], norm_layer=norm_layer,last_stage=(i == len(depths) - 1))for i in range(len(depths))])self.norm = norm_layer(embed_dim)self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()trunc_normal_(self.head.weight, std=0.02)zeros_(self.head.bias)def forward_features(self, x):x = self.patch_embed(x)x = self.pos_drop(x)for blk in self.blocks:x = blk(x)x = self.norm(x) # B L Creturn xdef forward(self, x):x = self.forward_features(x)x = x.mean(dim=1) if x.ndim > 2 else xx = self.head(x)return x
该程序文件是一个用于实现CSWin Transformer模型的Python代码文件。CSWin Transformer是一种用于图像分类任务的Transformer模型,它使用了局部感知的注意力机制和局部位置编码,以提高模型的计算效率和性能。
该文件定义了CSWin Transformer模型的各个组件,包括Mlp模块、LePEAttention模块、CSWinBlock模块和Merge_Block模块。其中,Mlp模块实现了多层感知机,用于处理特征向量;LePEAttention模块实现了局部感知的注意力机制,用于计算特征向量之间的关联性;CSWinBlock模块实现了CSWin Transformer的基本块,包括局部感知的注意力机制和多层感知机;Merge_Block模块用于将不同分辨率的特征图进行融合。
该文件还定义了一些辅助函数,包括img2windows函数和windows2img函数,用于将图像转换为窗口形式和将窗口形式的特征图转换为图像形式。
最后,该文件还定义了CSWin_tiny、CSWin_small、CSWin_base和CSWin_large四个模型,分别对应不同规模的CSWin Transformer模型。这些模型都是基于CSWinBlock模块构建的,通过堆叠多个CSWinBlock模块来构建整个模型。
6.系统整体结构
以下是每个文件的功能的整理:
| 文件 | 功能 |
|---|---|
| export.py | 导出模型的函数和逻辑 |
| predict.py | 运行模型进行预测的函数和逻辑 |
| train.py | 训练模型的函数和逻辑 |
| ui.py | 图形界面程序,用于显示图像和识别物体 |
| backbone\convnextv2.py | ConvNeXt V2模型的定义和实现 |
| backbone\CSwomTramsformer.py | CSWin Transformer模型的定义和实现 |
| backbone\EfficientFormerV2.py | EfficientFormer V2模型的定义和实现 |
| backbone\efficientViT.py | EfficientViT模型的定义和实现 |
| backbone\fasternet.py | FasterNet模型的定义和实现 |
| backbone\lsknet.py | LSKNet模型的定义和实现 |
| backbone\repvit.py | RepVIT模型的定义和实现 |
| backbone\revcol.py | RevCoL模型的定义和实现 |
| backbone\SwinTransformer.py | Swin Transformer模型的定义和实现 |
| backbone\VanillaNet.py | VanillaNet模型的定义和实现 |
| extra_modules\afpn.py | AFPN模块的定义和实现 |
| extra_modules\attention.py | 注意力机制模块的定义和实现 |
| extra_modules\block.py | 基本块模块的定义和实现 |
| extra_modules\dynamic_snake_conv.py | 动态蛇形卷积模块的定义和实现 |
| extra_modules\head.py | 模型头部模块的定义和实现 |
| extra_modules\kernel_warehouse.py | 内核仓库模块的定义和实现 |
| extra_modules\orepa.py | OREPA模块的定义和实现 |
| extra_modules\rep_block.py | RepBlock模块的定义和实现 |
| extra_modules\RFAConv.py | RFAConv模块的定义和实现 |
| models\common.py | 通用模型函数和类的定义和实现 |
| models\experimental.py | 实验性模型函数和类的定义和实现 |
| models\tf.py | TensorFlow模型函数和类的定义和实现 |
| models\yolo.py | YOLO模型函数和类的定义和实现 |
| segment\predict.py | 分割模型的预测函数和逻辑 |
| segment\train.py | 分割模型的训练函数和逻辑 |
| segment\val.py | 分割模型的验证函数和逻辑 |
| ultralytics… | Ultralytics库的一些功能函数和类的定义和实现 |
| utils… | 一些通用的辅助函数和类的定义和实现 |
这些文件涵盖了模型的定义、训练、预测、导出等功能,以及一些辅助模块和工具函数。
7.YOLOv8算法原理
YOLOv8算法由Glenn-Jocher 提出,是跟YOLOv3算法、YOLOv5算法一脉相承的,主要的改进点如下:
(1)数据预处理。YOLOv8的数据预处理依旧采用YOLOv5的策略,在训练时,主要采用包括马赛克增强(Mosaic)、混合增强(Mixup)、空间扰动(randomperspective)以及颜色扰动(HSV augment)四个增强手段。
(2)骨干网络结构。YOLOv8的骨干网络结构可从YOLOv5略见一斑,YOLOv5的主干网络的架构规律十分清晰,总体来看就是每用一层步长为2的3×3卷积去降采样特征图,接一个C3模块来进一步强化其中的特征,且C3的基本深度参数分别为“3/6/9/3”,其会根据不同规模的模型的来做相应的缩放。在的YOLOv8中,大体上也还是继承了这一特点,原先的C3模块均被替换成了新的C2f模块,C2f 模块加入更多的分支,丰富梯度回传时的支流。下面展示了YOLOv8的C2f模块和YOLOv5的C3模块,其网络结构图所示。
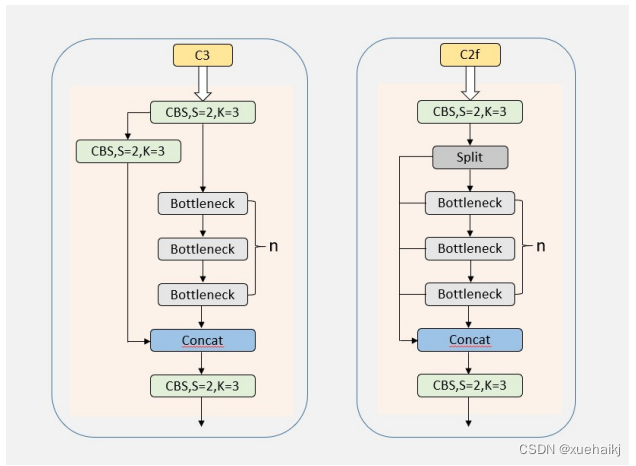
(3)FPN-PAN结构。YOLOv8仍采用FPN+PAN结构来构建YOLO的特征金字塔,使多尺度信息之间进行充分的融合。除了FPN-PAN里面的C3模块被替换为C2f模块外,其余部分与YOLOv5的FPN-PAN结构基本一致。
(4)Detection head结构。从 YOLOv3到 YOLOv5,其检测头一直都是“耦合”(Coupled)的,即使用一层卷积同时完成分类和定位两个任务,直到YOLOX的问世, YOLO系列才第一次换装“解耦头”(Decoupled Head)。YOLOv8也同样也采用了解耦头的结构,两条并行的分支分别取提取类别特征和位置特征,然后各用一层1x1卷积完成分类和定位任务。YOLOv8整体的网络结构由图所示。
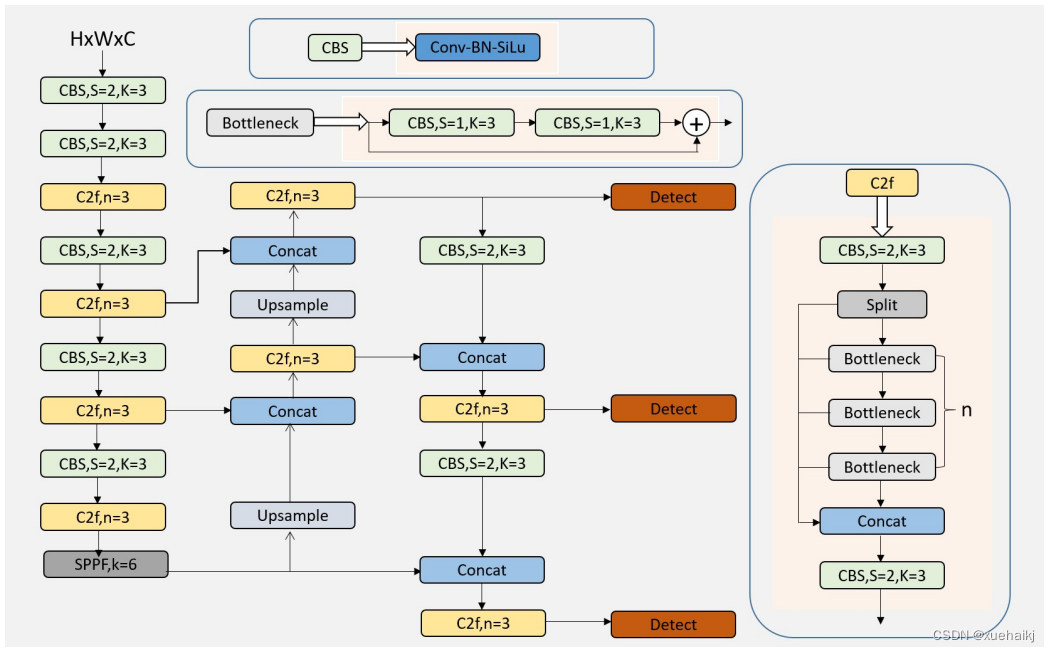
(5)标签分配策略。尽管YOLOv5设计了自动聚类候选框的一些功能,但是聚类候选框是依赖于数据集的。若数据集不够充分,无法较为准确地反映数据本身的分布特征,聚类出来的候选框也会与真实物体尺寸比例悬殊过大。YOLOv8没有采用候选框策略,所以解决的问题就是正负样本匹配的多尺度分配。不同于YOLOX所使用的 SimOTA,YOLOv8在标签分配问题上采用了和YOLOv6相同的TOOD策略,是一种动态标签分配策略。YOLOv8只用到了targetboze。和target scores,未含是否有物体预测,故 YOLOv8的损失就主要包括两大部分∶类别损失和位置损失。对于YOLOv8,其分类损失为VFLLoss(Varifocal Loss),其回归损失为CIoU Loss 与 DFL Loss 的形式。
其中 Varifocal Loss定义如下:
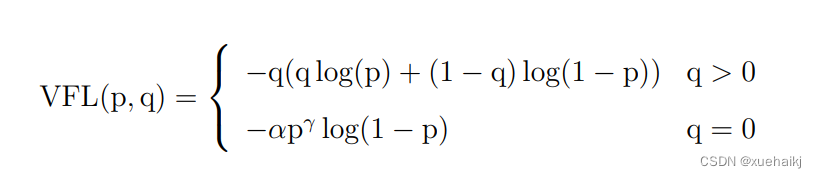
其中p为预测的类别得分,p ∈ [0.1]。q为预测的目标分数(若为真实类别,则q为预测和真值的 loU;若为其他类别。q为0 )。VFL Loss使用不对称参数来对正负样本进行加权,通过只对负样本进行衰减,达到不对等的处理前景和背景对损失的贡献。对正样本,使用q进行了加权,如果正样本的GTiou很高时,则对损失的贡献更大一些,可以让网络聚焦于那些高质量的样本上,即训练高质量的正例对AP的提升比低质量的更大一些。对负样本,使用p进行了降权,降低了负例对损失的贡献,因负样本的预测p在取次幂后会变得更小,这样就能够降低负样本对损失的整体贡献。
8.动态蛇形卷积Dynamic Snake Convolution
参考论文: 2307.08388.pdf (arxiv.org)
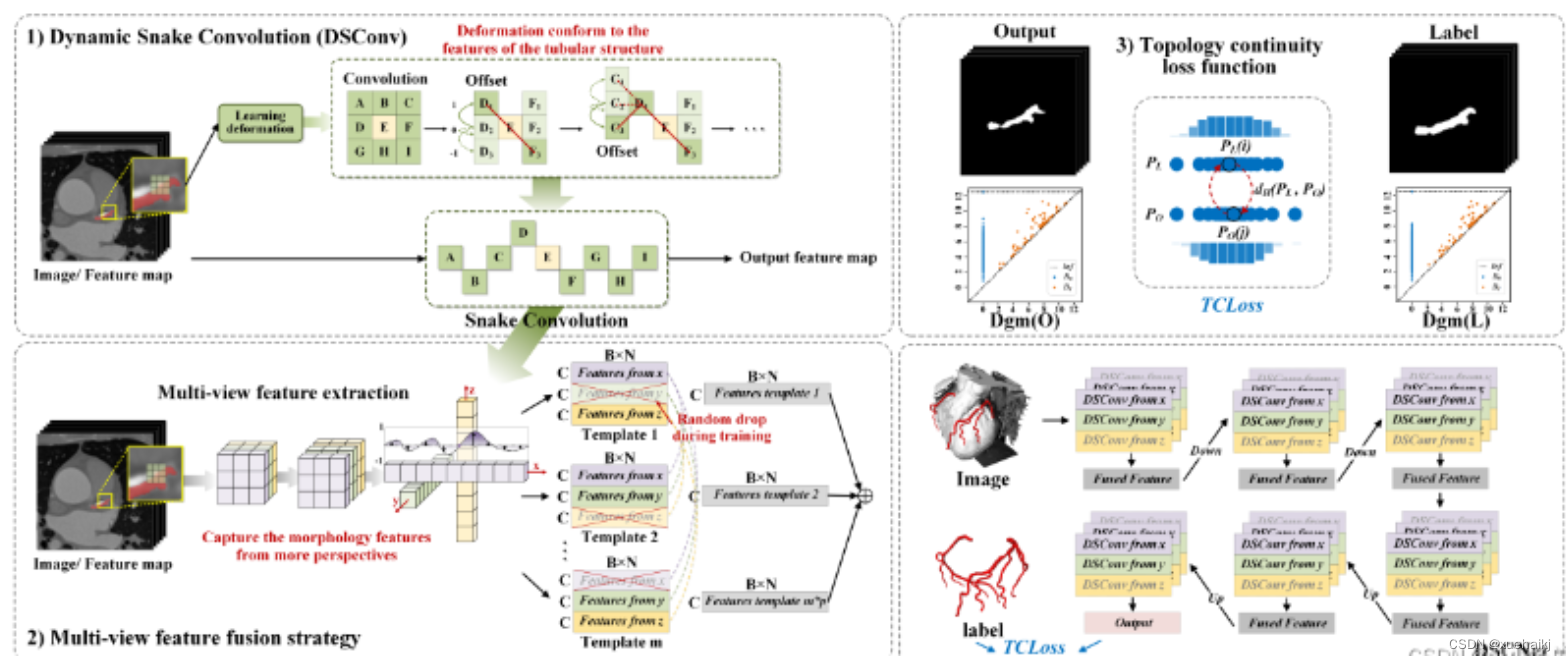
血管、道路等拓扑管状结构的精确分割在各个领域都至关重要,确保下游任务的准确性和效率。 然而,许多因素使任务变得复杂,包括薄的局部结构和可变的全局形态。在这项工作中,我们注意到管状结构的特殊性,并利用这些知识来指导我们的 DSCNet 在三个阶段同时增强感知:特征提取、特征融合、 和损失约束。 首先,我们提出了一种动态蛇卷积,通过自适应地关注细长和曲折的局部结构来准确捕获管状结构的特征。 随后,我们提出了一种多视图特征融合策略,以补充特征融合过程中多角度对特征的关注,确保保留来自不同全局形态的重要信息。 最后,提出了一种基于持久同源性的连续性约束损失函数,以更好地约束分割的拓扑连续性。 2D 和 3D 数据集上的实验表明,与多种方法相比,我们的 DSCNet 在管状结构分割任务上提供了更好的准确性和连续性。 我们的代码是公开的。
主要的挑战源于细长微弱的局部结构特征与复杂多变的全局形态特征。本文关注到管状结构细长连续的特点,并利用这一信息在神经网络以下三个阶段同时增强感知:特征提取、特征融合和损失约束。分别设计了动态蛇形卷积(Dynamic Snake Convolution),多视角特征融合策略与连续性拓扑约束损失。
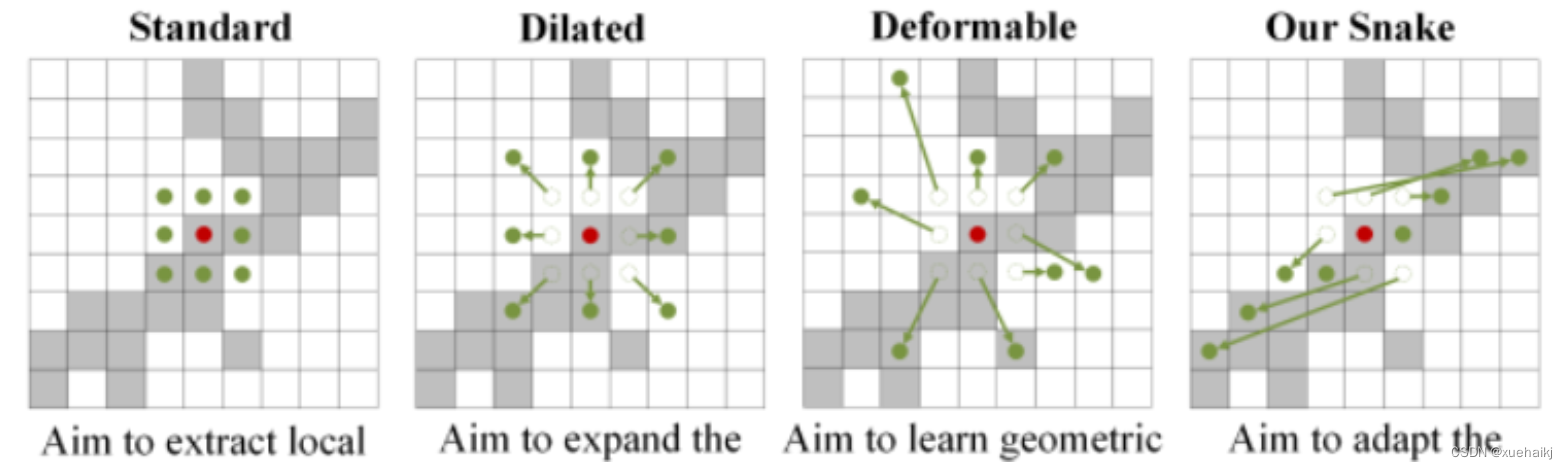
我们希望卷积核一方面能够自由地贴合结构学习特征,另一方面能够在约束条件下不偏离目标结构太远。在观察管状结构的细长连续的特征后,脑海里想到了一个动物——蛇。我们希望卷积核能够像蛇一样动态地扭动,来贴合目标的结构。
我们希望卷积核一方面能够自由地贴合结构学习特征,另一方面能够在约束条件下不偏离目标结构太远。在观察管状结构的细长连续的特征后,脑海里想到了一个动物——蛇。我们希望卷积核能够像蛇一样动态地扭动,来贴合目标的结构。
9.DCNV2融入YOLOv8
DCN和DCNv2(可变性卷积)
网上关于两篇文章的详细描述已经很多了,我这里具体的细节就不多讲了,只说一下其中实现起来比较困惑的点。(黑体字会讲解)
DCNv1解决的问题就是我们常规的图像增强,仿射变换(线性变换加平移)不能解决的多种形式目标变换的几何变换的问题。如下图所示。
可变性卷积的思想很简单,就是讲原来固定形状的卷积核变成可变的。如下图所示:
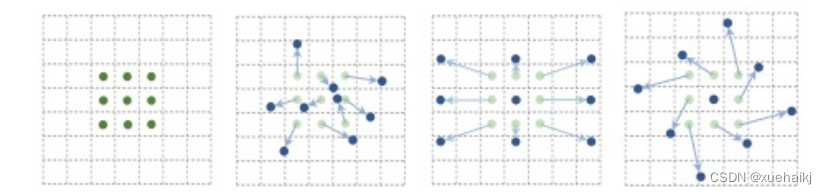
首先来看普通卷积,以3x3卷积为例对于每个输出y(p0),都要从x上采样9个位置,这9个位置都在中心位置x(p0)向四周扩散得到的gird形状上,(-1,-1)代表x(p0)的左上角,(1,1)代表x(p0)的右下角,其他类似。
用公式表示如下:

可变性卷积Deformable Conv操作并没有改变卷积的计算操作,而是在卷积操作的作用区域上,加入了一个可学习的参数∆pn。同样对于每个输出y(p0),都要从x上采样9个位置,这9个位置是中心位置x(p0)向四周扩散得到的,但是多了 ∆pn,允许采样点扩散成非gird形状。
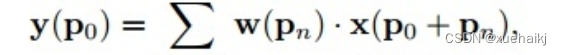
偏移量是通过对原始特征层进行卷积得到的。比如输入特征层是w×h×c,先对输入的特征层进行卷积操作,得到w×h×2c的offset field。这里的w和h和原始特征层的w和h是一致的,offset field里面的值是输入特征层对应位置的偏移量,偏移量有x和y两个方向,所以offset field的channel数是2c。offset field里的偏移量是卷积得到的,可能是浮点数,所以接下来需要通过双向性插值计算偏移位置的特征值。在偏移量的学习中,梯度是通过双线性插值来进行反向传播的。
看到这里是不是还是有点迷茫呢?那到底程序上面怎么实现呢?
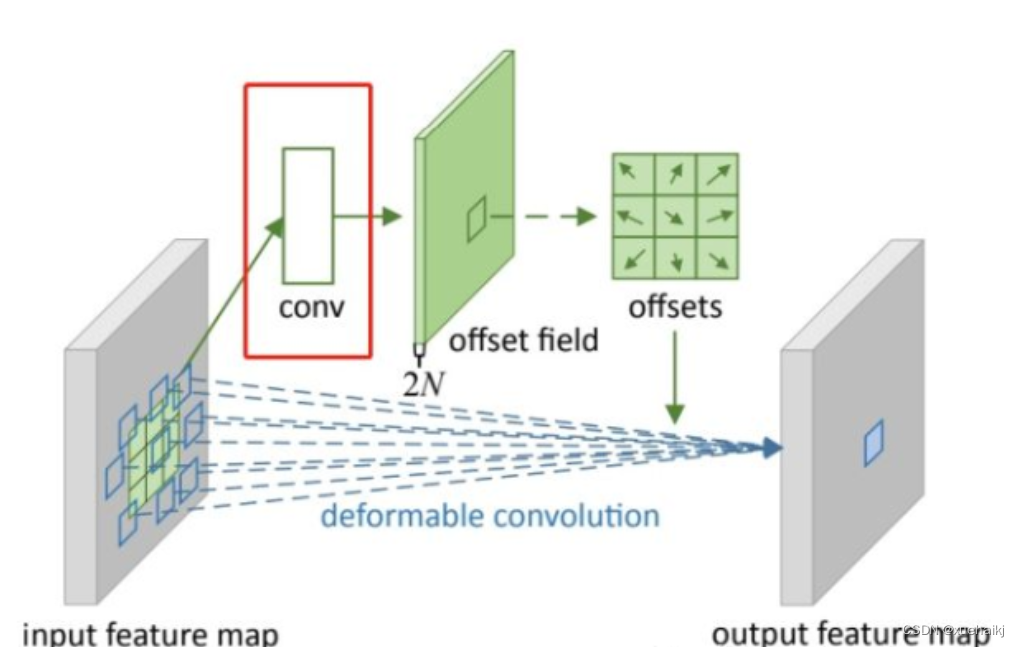
事实上由上面的公式我们可以看得出来∆pn这个偏移量是加在原像素点上的,但是我们怎么样从代码上对原像素点加这个量呢?其实很简单,就是用一个普通的卷积核去跟输入图片(一般是输入的feature_map)卷积就可以了卷积核的数量是2N也就是23*3==18(前9个通道是x方向的偏移量,后9个是y方向的偏移量),然后把这个卷积的结果与正常卷积的结果进行相加就可以了。
然后又有了第二个问题,怎么样反向传播呢?为什么会有这个问题呢?因为求出来的偏移量+正常卷积输出的结果往往是一个浮点数,浮点数是无法对应到原图的像素点的,所以自然就想到了双线性差值的方法求出浮点数对应的浮点像素点。
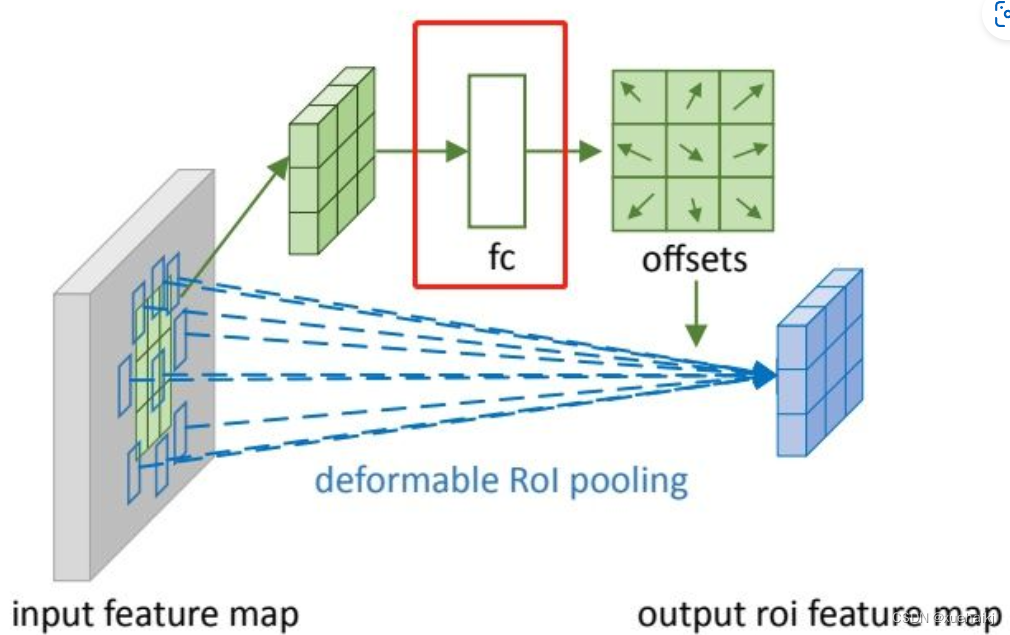
DCN v2
对于positive的样本来说,采样的特征应该focus在RoI内,如果特征中包含了过多超出RoI的内容,那么结果会受到影响和干扰。而negative样本则恰恰相反,引入一些超出RoI的特征有助于帮助网络判别这个区域是背景区域。
DCNv1引入了可变形卷积,能更好的适应目标的几何变换。但是v1可视化结果显示其感受野对应位置超出了目标范围,导致特征不受图像内容影响(理想情况是所有的对应位置分布在目标范围以内)。
为了解决该问题:提出v2, 主要有
1、扩展可变形卷积,增强建模能力
2、提出了特征模拟方案指导网络培训:feature mimicking scheme
上面这段话是什么意思呢,通俗来讲就是,我们的可变性卷积的区域大于目标所在区域,所以这时候就会对非目标区域进行错误识别。
所以自然能想到的解决方案就是加入权重项进行惩罚。(至于这个实现起来就比较简单了,直接初始化一个权重然后乘(input+offsets)就可以了)
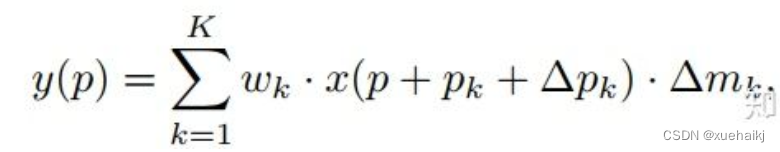
可调节的RoIpooling也是类似的,公式如下:
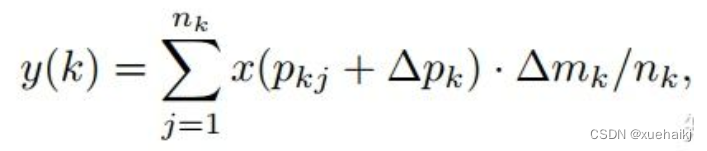
10.训练结果可视化分析
评价指标
Epoch:训练纪元数。
Train Losses:训练过程中不同类型的损失,例如框损失、分割损失、对象损失和类损失。
指标:两个类别的精度、召回率和平均精度 (mAP),表示为 (B) 和 (M)。
验证损失:与训练损失类似,但针对验证数据集。
学习率:不同参数的学习率,表示为x/lr0、x/lr1和x/lr2。
训练结果可视化
为了分析这些数据,我们将从几个方面来看:
损失趋势:训练和验证损失如何随时代演变。
性能指标:两个类别的精确度、召回率和 mAP 在历元内的进展。
学习率变化:观察学习率的趋势。
# Correcting the mAP plotting function with the right column names
def plot_map_metrics(data, category, title):plt.figure(figsize=(15, 6))# Filtering columns for mAPmap_cols = [col for col in data.columns if col.startswith(f'metrics/mAP') and col.endswith(f'({category})')]# Plotting the mAP metricsfor col in map_cols:sns.lineplot(data=data, x='epoch', y=col.strip(), label=col.strip()) # Stripping whitespace from column namesplt.title(title)plt.xlabel('Epoch')plt.ylabel('mAP')plt.legend()plt.show()# Replotting the mAP for categories B and M with corrected column names
plot_map_metrics(data, 'B', 'Mean Average Precision (mAP) for Category B Over Epochs')
plot_map_metrics(data, 'M', 'Mean Average Precision (mAP) for Category M Over Epochs')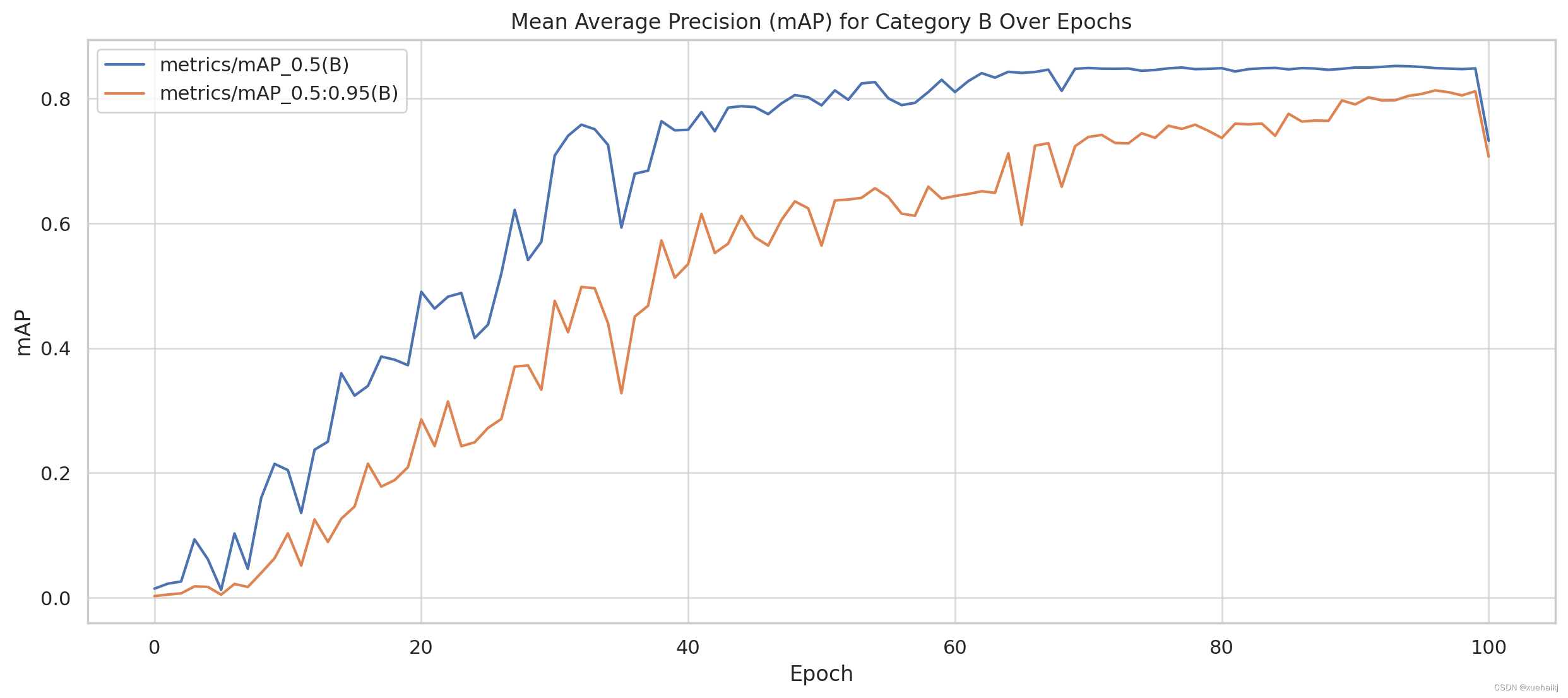
平均精度 (mAP) 分析
校正后的图现在成功显示了历元内类别 B 和 M 的平均精度 (mAP)。以下是主要观察结果:
B 类 mAP:
mAP_0.5 和 mAP_0.5:0.95 均呈现增加趋势,表明 B 类模型预测的准确性有所提高。
mAP_0.5:0.95 是更严格的衡量标准,其绝对值较低,但遵循类似的增长趋势。这表明,虽然该模型在 50% IoU 阈值下表现良好,但其在更严格的 IoU 阈值下的性能也在提高。
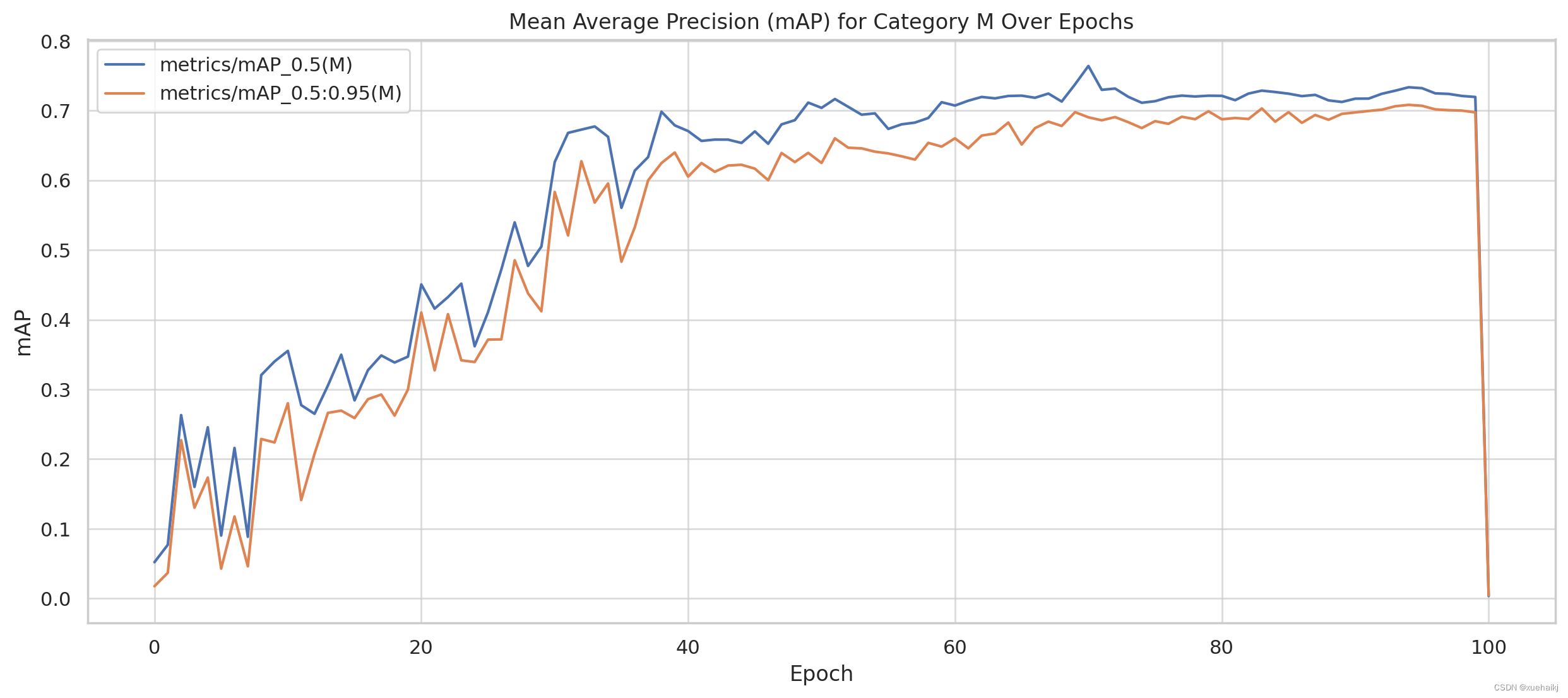
M 类的 mAP:
与 B 类类似,M 类的 mAP 值呈增加趋势,表明模型预测的逐步改进。
mAP_0.5:0.95 再次低于 mAP_0.5,但显示出显着的改善,尤其是在早期时期的急剧上升中尤为明显。
mAP 的这些趋势表明,该模型准确分类和分割草莓(根据 B 类和 M 类)的能力随着时间的推移而不断提高,这是模型功效的积极指标。
最后,我将简要查看各个时期的学习率变化以完成分析。这将帮助我们理解学习率调整方面的训练策略。让我们继续最后一部分。
学习率变化分析
x/lr0该图显示了学习率 ( 、x/lr1、x/lr2) 在历元内的变化。以下是主要见解:
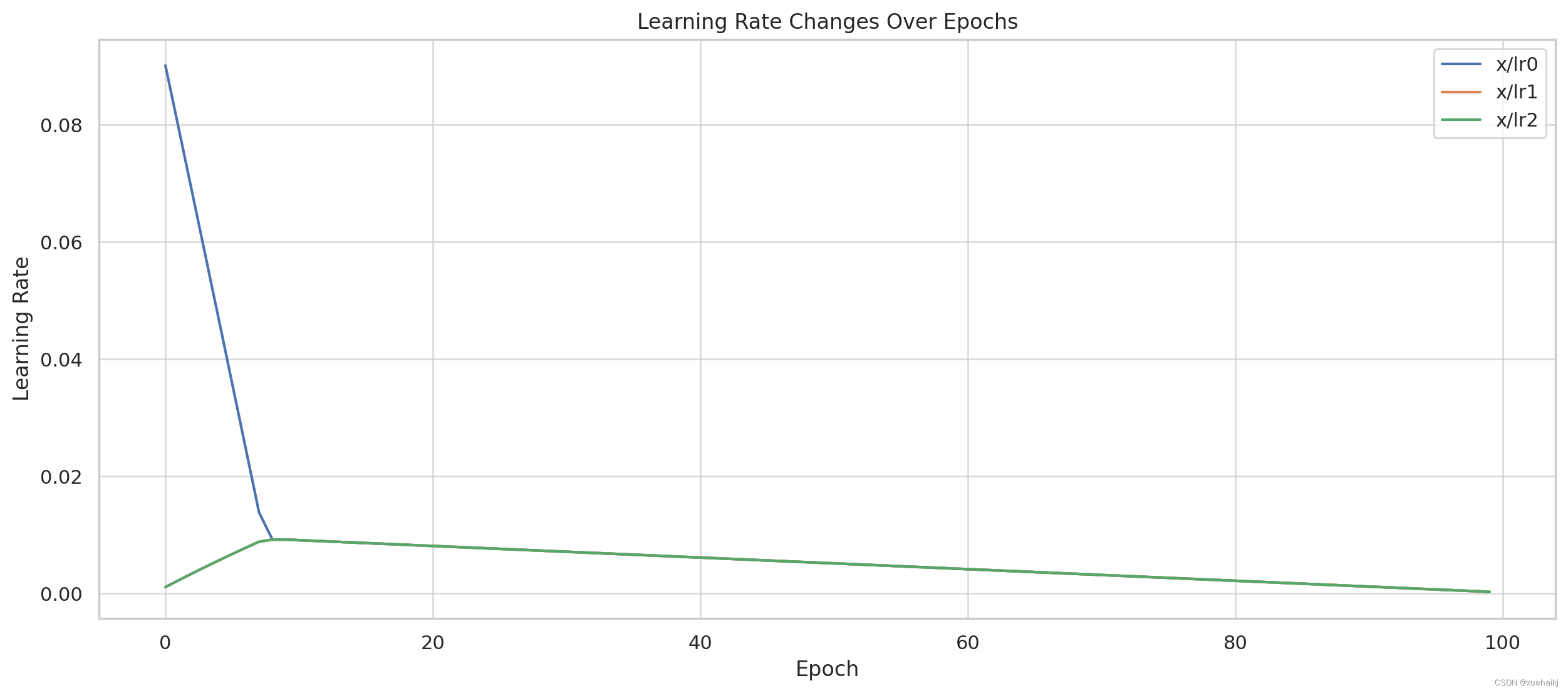
学习率逐渐增加:所有三个学习率都在各个时期内呈现逐渐增加的趋势。这表明学习率随时间推移而增加,可能是为了让模型在最初收敛到有希望的区域后能够更广泛地探索参数空间。
不同参数的不同速率x/lr0: 、x/lr1、 和之间的区别x/lr2表明模型中的不同参数集正在以不同的速率更新。这可能是一种比其他方面更积极地调整模型某些方面的策略。
速率之间的一致性:所有三个学习速率的并行增加表明更新模型参数的协调策略。这种协调对于维持模型不同组件之间的学习平衡至关重要。
整体分析总结
损失趋势:训练和验证损失随着时间的推移而减少,表明模型学习和泛化良好。
精确度和召回率:该模型显示了 B 类和 M 类的精确度和召回率指标的改进,表明分类和分割能力得到了增强。
平均精度 (mAP):在更严格的 IoU 阈值下增加两个类别的 mAP 值表明模型的准确性不断提高。
学习率策略:学习率的逐步协调增加表明了经过深思熟虑的训练策略,使模型能够探索和完善其学习。
11.系统整合
下图完整源码&数据集&环境部署视频教程&自定义UI界面

参考博客《【改进YOLOV8】融合动态蛇形卷积&DCNV2的草莓分级分割分割系统》
12.参考文献
[1]贾世娜.基于改进YOLOv5的小目标检测算法研究[D].2022.
[2]He, Kaiming,Zhang, Xiangyu,Ren, Shaoqing,等.Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence.2015,37(9).1904-1916.DOI:10.1109/TPAMI.2015.2389824 .
[3]Everingham, Mark,Eslami, S. M. Ali,Van Gool, Luc,等.The PASCAL Visual Object Classes Challenge: A Retrospective[J].International Journal of Computer Vision.2015,111(1).98-136.DOI:10.1007/s11263-014-0733-5 .
[4]Felzenszwalb, Pedro F.,Girshick, Ross B.,McAllester, David,等.Object Detection with Discriminatively Trained Part-Based Models[J].IEEE Transactions on Pattern Analysis and Machine Intelligence.2010,32(9).1627-1645.
[5]Mark Everingham,Luc Van Gool,Christopher K. I. Williams,等.The Pascal Visual Object Classes (VOC) Challenge[J].International Journal of Computer Vision.2009,88(2).303-338.DOI:10.1007/s11263-009-0275-4 .
[6]Viola P,Jones MJ.Robust real-time face detection[J].International Journal of Computer Vision.2004,57(2).137-154.
[7]Ojala, T.,Pietikainen, M.,Maenpaa, T..Multiresolution gray-scale and rotation invariant texture classification with local binary patterns[J].Pattern Analysis & Machine Intelligence, IEEE Transactions on.2002,24(7).971-987.DOI:10.1109/TPAMI.2002.1017623 .
[8]Freund Y.,Schapire RE..A Decision-Theoretic Generalization of on-Line Learning and an Application to Boosting[J].Journal of Computer and System Sciences.1997,55(1).119-139.
[9]CorinnaCortes,VladimirVapnik.Support-Vector Networks[J].Machine Learning.1995,20(3).273-297.DOI:10.1023/A:1022627411411 .
[10]Dalai, N.,Triggs, B..Histograms of oriented gradients for human detection[C].2005.