OpenKG

大模型专辑
导读 知识图谱和大型语言模型都是用来表示和处理知识的手段。大模型补足了理解语言的能力,知识图谱则丰富了表示知识的方式,两者的深度结合必将为人工智能提供更为全面、可靠、可控的知识处理方法。在这一背景下,OpenKG组织新KG视点系列文章——“大模型专辑”,不定期邀请业内专家对知识图谱与大模型的融合之道展开深入探讨。本期特别邀请到华为大模型技术专家李芳明和浙江大学研究员张文分享“知识与大模型融合技术在电信领域应用探索”。
分享嘉宾 | 李芳明(华为)、张文(浙江大学)
笔记整理 | 邓鸿杰(OpenKG)
内容审定 | 陈华钧

摘要:本次分享是我们团队近两年做的一些知识与大模型融合技术在电信领域应用的一些工作。主要包括两部分内容:
1. 知识图谱与大模型融合故障定界
2. 知识与大模型融合电信领域知识问答
01
知识图谱与大模型融合故障定界
1.1 背景介绍:
云核心网的特点是为了完成对应的业务功能需要不同网元之间的相互调用,所以当一个网元故障发生时,与其有业务调用关系的网元也会业务受损,表现出故障状态。故障网元实例定界就是在多个网元都出现故障现象时,定位到真正的故障网元,即“始作俑者”。下图是云核心网的逻辑架构图。
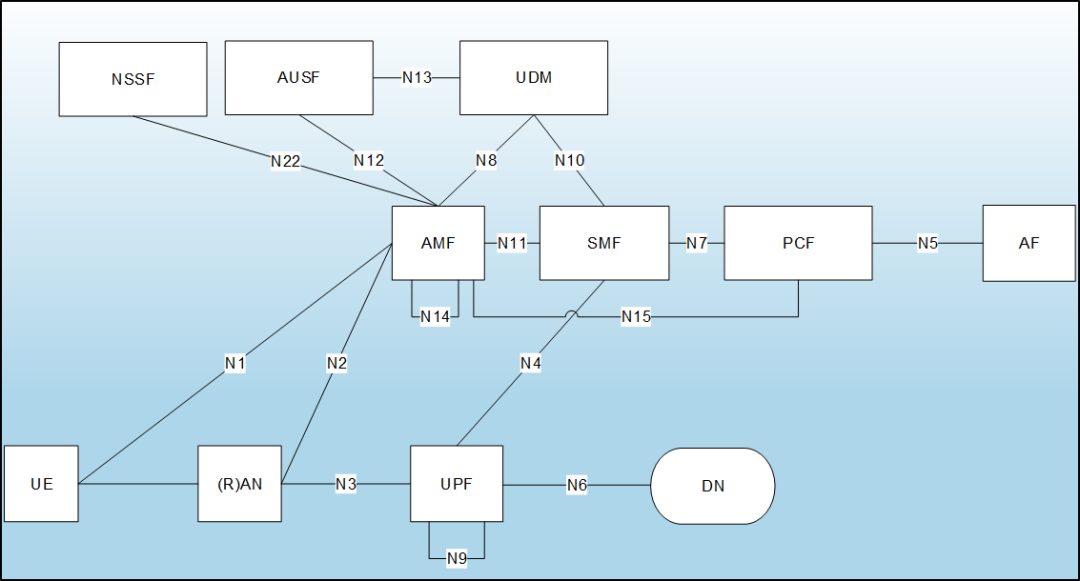
整体方案的输入为故障数据包,输出故障网元,目标最大化提升运维工程师的定位效率。PS:机器语言大模型是我们决策式大模型的名字。

1.2 技术方案:
1.2.1 技术方案概述
在ChatGPT出来之前,“模型+知识双驱动”的研究方向是很火的,我们团队之前也做了基于知识图谱的故障定界方案,所以接下来我们就想探索一个基于模型的故障定界方案,说到基于模型那肯定要上大模型,虽然当时大模型没有火热到今天这种地步,也还是很热门的研究方向。
整体方案的设计思路是将故障发生时的异常事件向量化后全部挂载到对应网元上去,得到一个故障时刻的数字网络快照,然后通过图神经网络的方法去完成不同网元之间的异常事件信息交换,经过信息交换后,每个网元都是“知己知彼”,既知道自己发生了什么异常事件,又知道周边网元发生了什么异常事件,接下来就可以通过全连接神经网络推断每个网元是否是根因网元。(有点类似于剧本杀的逻辑,大家都拿到各自剧本,最开始只知道自己身份相关的一些信息,然后和其他玩家交换的信息,逐渐根据自己和别人提供的信息就能推断出嫌疑人了)。接下来,根据知识图谱中的相关知识对以上结果进行校正,最终实现了根因网元定位。根据以上设计思路,形成了以下的具体技术方案。
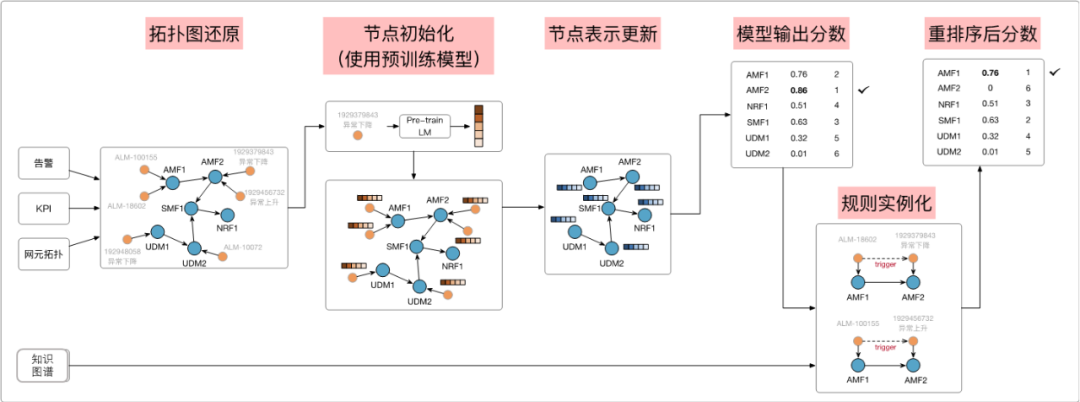
步骤1:故障异常事件提取:这里包括对不同类型机器数据的异常事件提取,例如KPI异常事件,日志的异常事件,告警本身就是异常事件,因为我们注意到专家在故障定界的过程中主要是看不同类型的异常事件去定界的。
步骤2:异常事件挂载,形成故障快照:首先现网的配置情况,还原各个网元之间的业务调用关系,形成一个有向的图结构,并把上一步提取的异常事件按照发生位置挂载到具体网元上去,这样就形成了如下的故障快照,蓝色代表网元实例,橙色代表异常事件,网元之间的单向箭头代表业务调用关系。
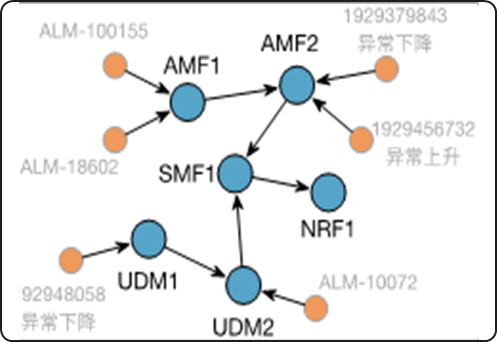
步骤3:故障快照数字化:前面的故障快照是人能看懂的,神经网络是看不懂的,那我们要把它变成神经网络也能看懂的形式,即数字化,也就是向量化。这里数字化的具体方案与下游任务有关,因为我的下游任务选择的是用图神经网络的技术栈,所有结构信息可以简单数字化为邻接矩阵传递给图神经网络。主要技术难度在于异常事件数字化,因为这里面包括对于KPI异常事件,日志异常事件、告警等不同类型异常事件的向量化。我们的思路就是用bert类大模型(机器语言大模型)对不同类型异常事件根据语义来进行向量化。例如一个KPI异常事件是“5GC 会话成功率下降”,把这句话输入给机器语言大模型,它就会给我输出一个768维的向量,即为这个异常事件的数字化结果。接下来我们又发现一个问题,告警本质上属于结构化数据,一条告警有很多个字段,每个字段有对应的具体到这条告警的值。我们就想了一个办法,把告警的关键字段的key:value提取出来,拼接后送给大模型,最终每个告警也会得到一个768维的数字化结果。我们也尝试了把每个key:value分别送给大模型做数字化在融合,并做了对比试验,效果没有拼接后送给大模型好。

最终我们实现了故障快照的数字化,如下图:

这个地方省略了一个重要细节,就是我们的机器语言大模型具体怎么训练的,为了保持整体方案的逻辑性,在这先不讲,后面会单独讲机器语言大模型怎么得到的,具体参数量有多大。
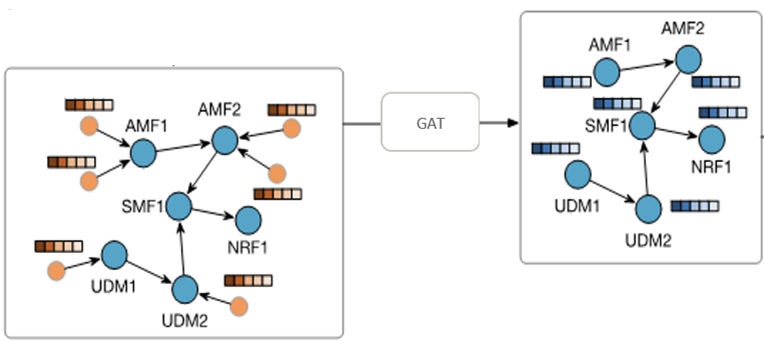
步骤4:网元之间信息交换:不同网元之间的信息交换是通过图神经网络的技术栈实现的,具体选用的GAT(Graph Attention Networks)方案,功能上就是实现了相邻网元之间的信息交换,做到了“知己知彼”,这里的建模思路是受到云核运维专家定位过程的启示,即判定一个网元是不是真正发生了故障不仅要看网元本身发生了什么异常事件,还要看对端网元发生了什么异常事件。
这有个关键问题“是不是每个网元都只是吸收了它相邻网元的信息?”:答案是否定的,因为如果我们让网元之间交换两次信息的话,那就是每个网元都吸收了它两跳网元的信息,因为相邻网元在第一次信息交换时已经吸收了它相邻网元的信息。(比较绕)。
步骤5:逐一判断网元是故障网元的概率:在经过几轮信息交换后,每个网元都知道自己发生了哪些异常,其他网元发生了哪些异常,接下来就可以逐一判断每个网元是否真的发生了故障,只要通一个MLP就可以实现(当然需要一些历史数据训练MLP)。
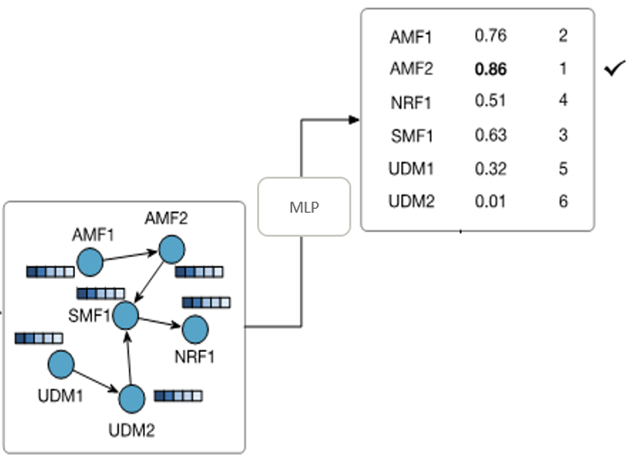
步骤6:根据知识图谱进行结果校正:首先梳理主要异常事件的发生网元,然后在知识图谱中,提取本次故障主要异常事件的故障传播关系,识别根因事件,如下图中的ALARM5和ALARM1,然后初始化一个网元的根因权重矩阵,初始值均为1,然后根据每个网元上的根因事件更新权重矩阵,每有一个根因事件,权重增加0.1,最终得到加权后的网元根因权重矩阵。
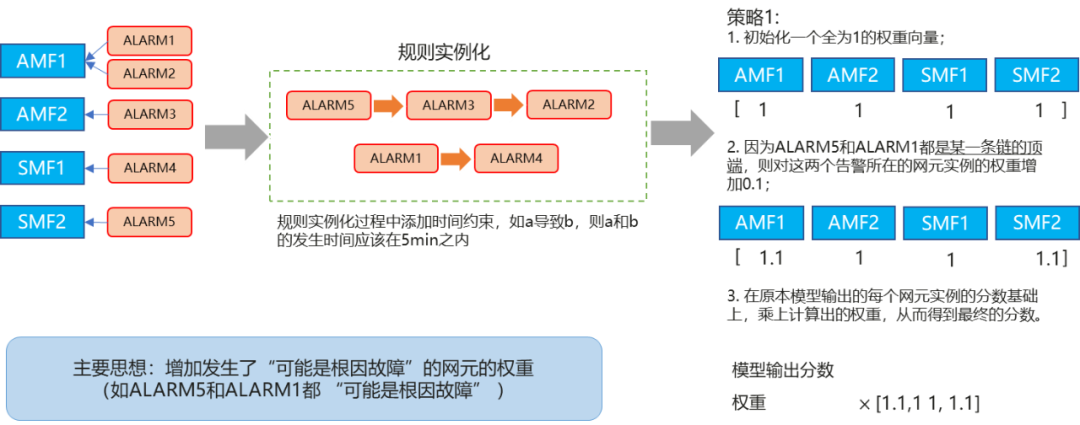
接下来,用步骤五得到的每个网元的故障概率乘以网元根因权重矩阵各自的权重系数,得到最终的每个网元是根因网元的概率,超过阈值的网元即为故障网元。
1.2.2 机器语言大模型
介绍到这还没讲一个关键问题,就是我们的机器语言大模型是怎么来的,它的特点是什么,为什么叫机器语言大模型?接下来就用一个小节揭开机器语言大模型的神秘面纱。
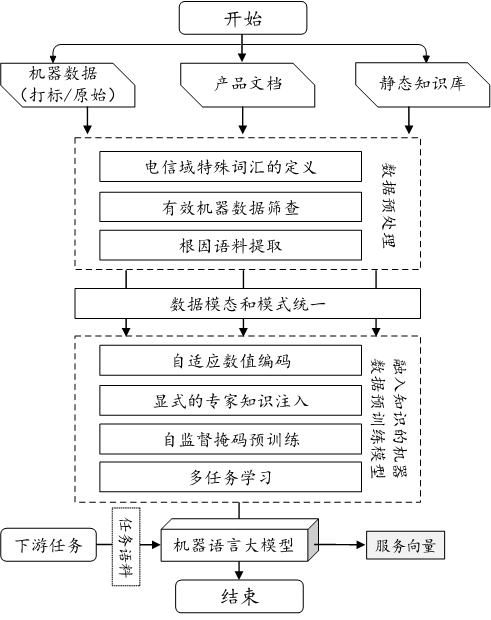
首先说为什么叫机器语言大模型,因为像KPI、告警、日志等数据我们统称为机器语言大模型,我们的大模型设计初衷也就是对各类机器数据的异常事件进行embedding,所以我们的大模型叫机器语言大模型。至此,大家可能也猜到了,机器语言的预训练数据肯定是电信领域的数据,的确如此,包括了电信领域的基础知识数据和不同类型的机器语言数据。基础知识数据包括通用的电信领域知识和华为产品的专有知识,机器数据就是现网采集回来的告警、日志、KPI等数据。
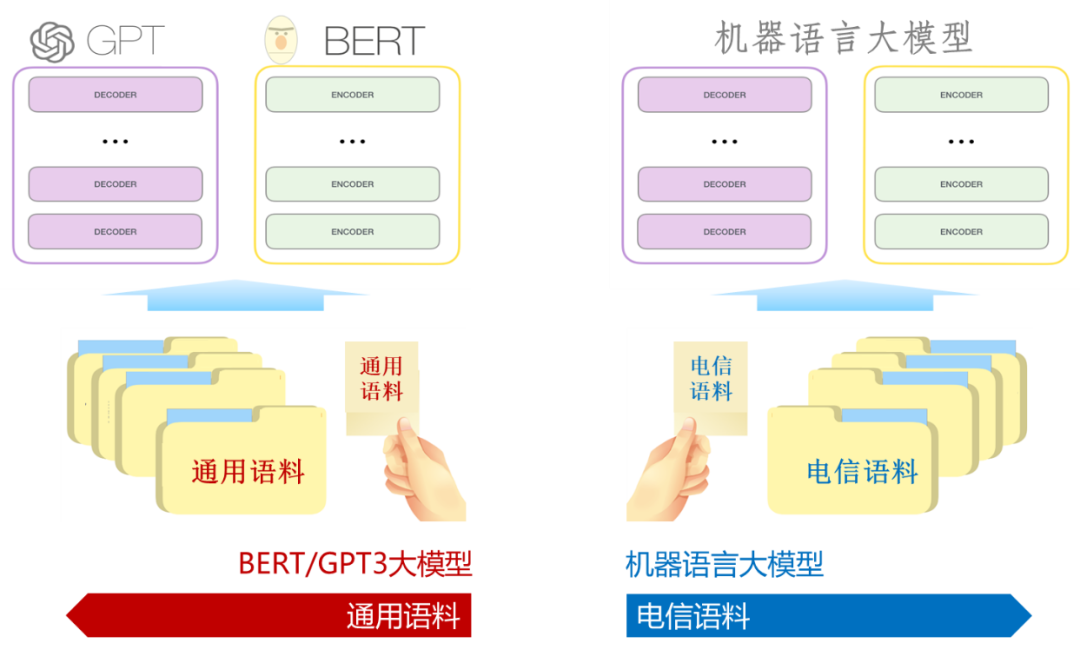
机器语言大模型的构建是与浙江大学陈华钧老师团队合作完成的,具体细节可参考论文“Tele-Knowledge Pre-training for Fault Analysis”,使用下图中的服务向量作为机器数据异常事件的embedding结果。
1.3 关键技术及应用效果
我们在两个数据集上验证了方案的应用效果:团泊洼镜像实验环境样本集和仿真数据集,随着我们样本的持续累积,精度不断在提升,最终我们共获得629个团泊洼镜像实验环境样本和1251个仿真故障样本,在两个样本集每次随机选取70%作为训练集训练GAT和MLP,30%作为测试集,经过50次实验,在两个样本集上的平均精度分别是91.55%和94.1%。
02
知识与大模型融合电信领域知识问答
2.1应用背景
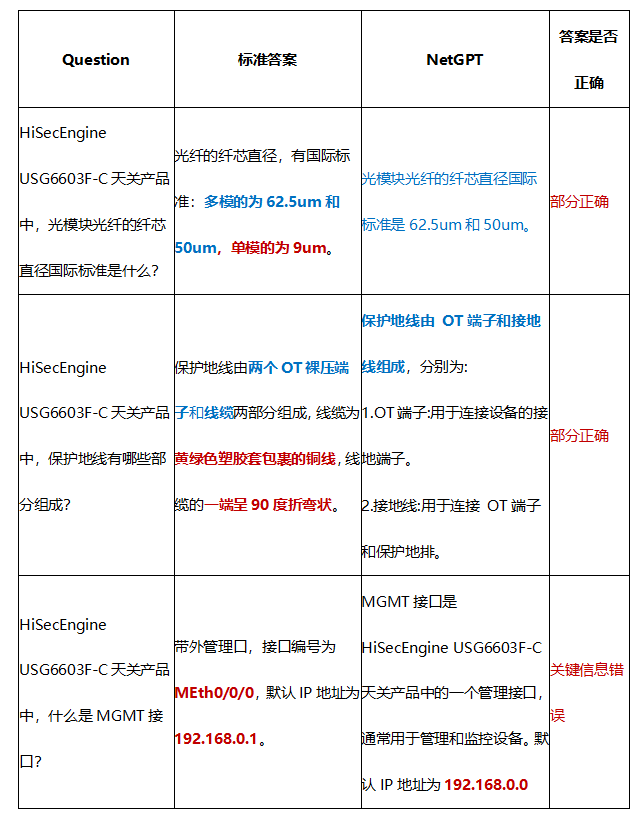
盘古通信L1大模型NetGPT是基于盘古NLP大模型构建的电信行业大模型,虽然NetGPT在很多行业知识问答虽然已经取得了很好的效果,但是强如GPT4也会存在幻觉和事实性错误,这个问题同样出现在我们的电信行业模型上,我们发现用户问题知识点分布在不同预训练语料块时,模型的回答可能是部分答案,不够完全。还有就是对于预训练数据中表格里面的知识,尤其与数字相关的知识,模型在回答的时候可能会存在事实性错误的情况。如下表所示,是典型的三个回答部分正确和事实性错误的知识问答实例。可以看到前两个问题,大模型回答的时候遗漏了部分关键信息,如红色部分所示。第三个问题答案部分的192.168.0.1被大模型回答为了192.168.0.0。毕竟大模型是概率模型,难免会记忆混淆。
2.2 NetGPT结合向量化数据库知识问答方案
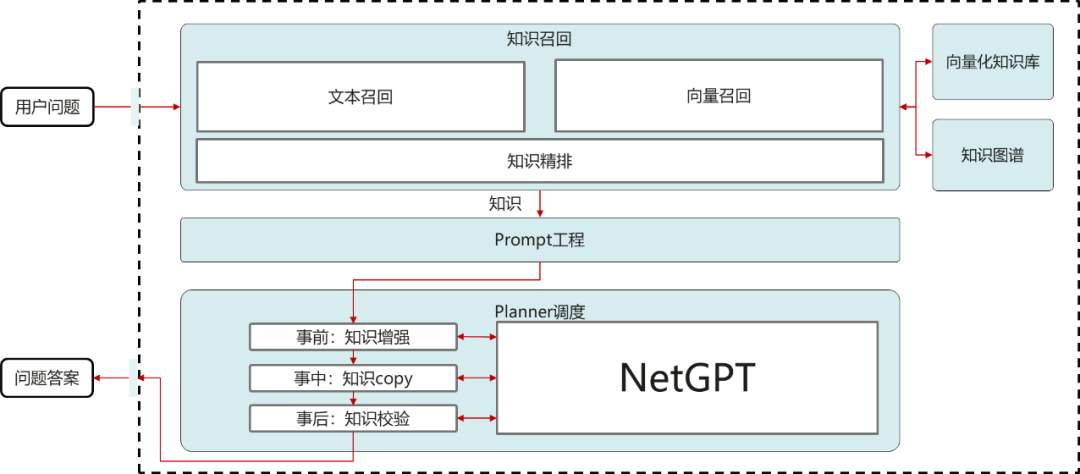
为了提升NetGPT知识问答的准确性,我们设计了如下的NetGPT结合向量化数据库的知识问答架构方案。
首先要保证知识召回的准确率,总体使用文本召回+向量混合召回再精排的组合方案。在使用的知识的过程中我们设计了“事前:知识增强,事中:知识copy,事后:知识校验”。
“事前:知识增强”:知识增强即为,讲检索回来的知识作为背景信息放到prompt中,作为大模型输入。
“事中:知识copy”:知识copy即为在大模型生成答案过程中,适当从检索回来的知识中copy关键片段到答案中。这个能力较为复杂,需要选择合适的生成内容位置插入copy片段,验证copy内容合理性对模型并发推理性能要求比较高。
“事后:知识校验”:事后校验为在答案生成完成后,对生成内容的关键信息,如关键数值等信息做校验。
2.3 应用效果
基于以上方案,我们再次验证了上述回答不全或者错误的问题,结果如下,可以看到三个问题全部回答正确。

03
总结
在ChatGPT出来之前,“知识+模型双驱动”就是很火的研究方向,ChatGPT出来后,有一些“是否还需要继续投入知识图谱的研究”的讨论,事实证明知识图谱在后ChatGPT大模型时代依然存在较高的研究价值。
以上就是本次分享的内容,谢谢。


作者简介
INTRODUCTION

李芳明

华为大模型技术专家,盘古通信大模型NetGPT技术负责人

李芳明博士长期从事AI技术在智能运维领域的应用研究工作,目前负责电信行业大模型的设计与开发,以及大模型与知识结合技术在电信行业应用研究工作。

作者简介
INTRODUCTION

张文

浙江大学特聘研究员

张文,浙江大学软件学院特聘研究员,研究方向为知识图谱、知识表示、知识推理。个人主页:https://person.zju.edu.cn/zhangwen
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。