一、环境准备
flink 1.14写入Kafka,首先在pom.xml文件中导入相关依赖
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><flink.version>1.14.6</flink.version><spark.version>2.4.3</spark.version><hadoop.version>2.8.5</hadoop.version><hbase.version>1.4.9</hbase.version><hive.version>2.3.5</hive.version><java.version>1.8</java.version><scala.version>2.11.8</scala.version><mysql.version>8.0.22</mysql.version><scala.binary.version>2.11</scala.binary.version><maven.compiler.source>${java.version}</maven.compiler.source><maven.compiler.target>${java.version}</maven.compiler.target></properties>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.12</artifactId><version>${flink.version}</version></dependency>
二、Flink将Socket数据写入Kafka(精准一次)
注意:如果要使用 精准一次 写入 Kafka,需要满足以下条件,缺一不可
1、开启 checkpoint
2、设置事务前缀
3、设置事务超时时间: checkpoint 间隔 < 事务超时时间 < max 的 15 分钟
package com.flink.DataStream.Sink;import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.Properties;public class flinkSinkKafka {public static void main(String[] args) throws Exception {StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();streamExecutionEnvironment.setParallelism(1);// 如果是精准一次,必须开启 checkpointstreamExecutionEnvironment.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);DataStreamSource<String> streamSource = streamExecutionEnvironment.socketTextStream("localhost", 8888);/*** TODO Kafka Sink* TODO 注意:如果要使用 精准一次 写入 Kafka,需要满足以下条件,缺一不可* 1、开启 checkpoint* 2、设置事务前缀* 3、设置事务超时时间: checkpoint 间隔 < 事务超时时间 < max 的 15 分钟*/Properties properties=new Properties();properties.put("transaction.timeout.ms",10 * 60 * 1000 + "");KafkaSink<String> kafkaSink = KafkaSink.<String>builder()// 指定 kafka 的地址和端口.setBootstrapServers("localhost:9092")// 指定序列化器:指定Topic名称、具体的序列化(产生方需要序列化,接收方需要反序列化).setRecordSerializer(KafkaRecordSerializationSchema.<String>builder().setTopic("testtopic01")// 指定value的序列化器.setValueSerializationSchema(new SimpleStringSchema()).build())// 写到 kafka 的一致性级别: 精准一次、至少一次.setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE)// 如果是精准一次,必须设置 事务的前缀.setTransactionalIdPrefix("flinkkafkasink-")// 如果是精准一次,必须设置 事务超时时间: 大于 checkpoint间隔,小于 max 15 分钟.setKafkaProducerConfig(properties)//.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 10 * 60 * 1000 + "").build();streamSource.sinkTo(kafkaSink);streamExecutionEnvironment.execute();}
}
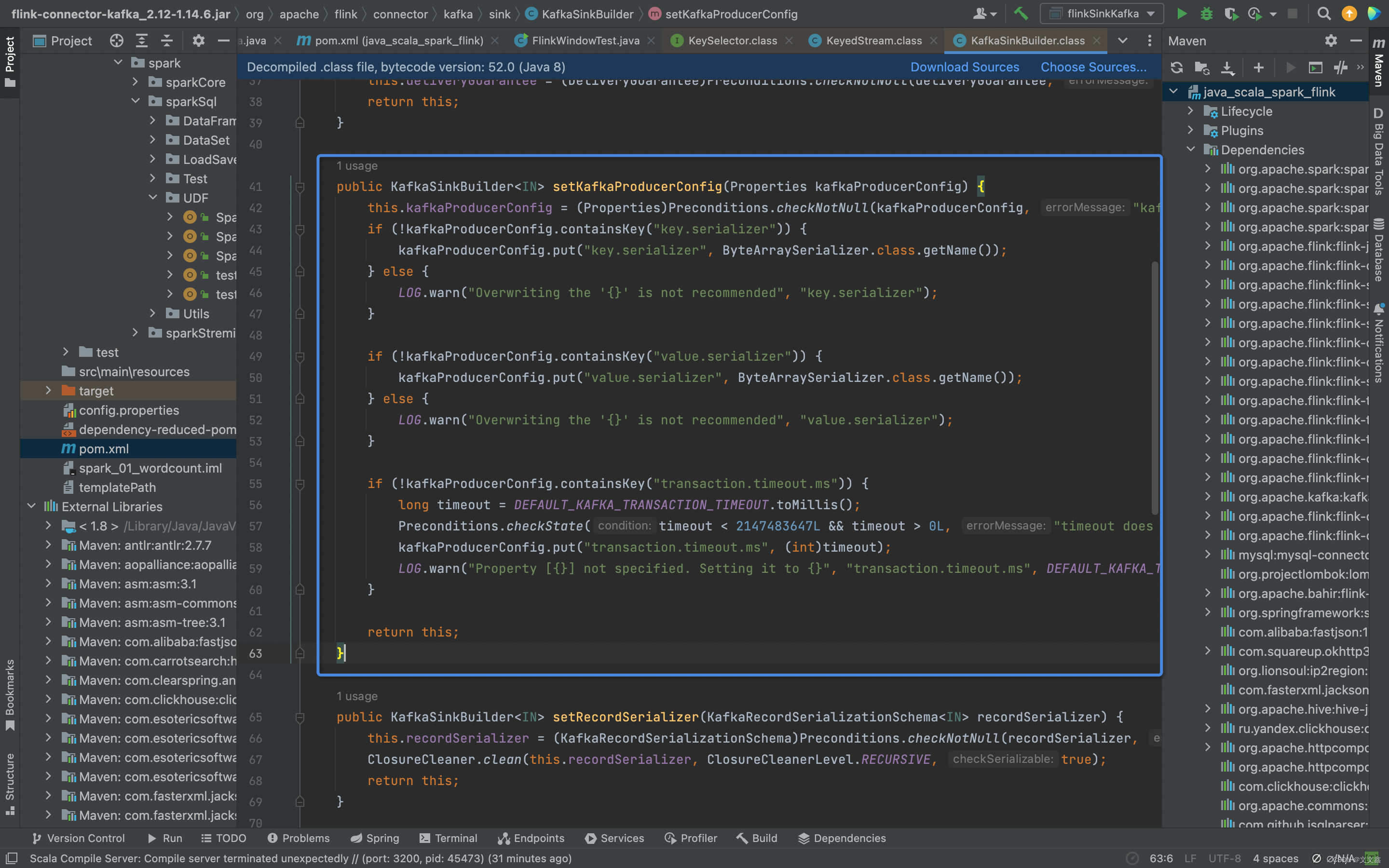
查看ProduceerConfig配置
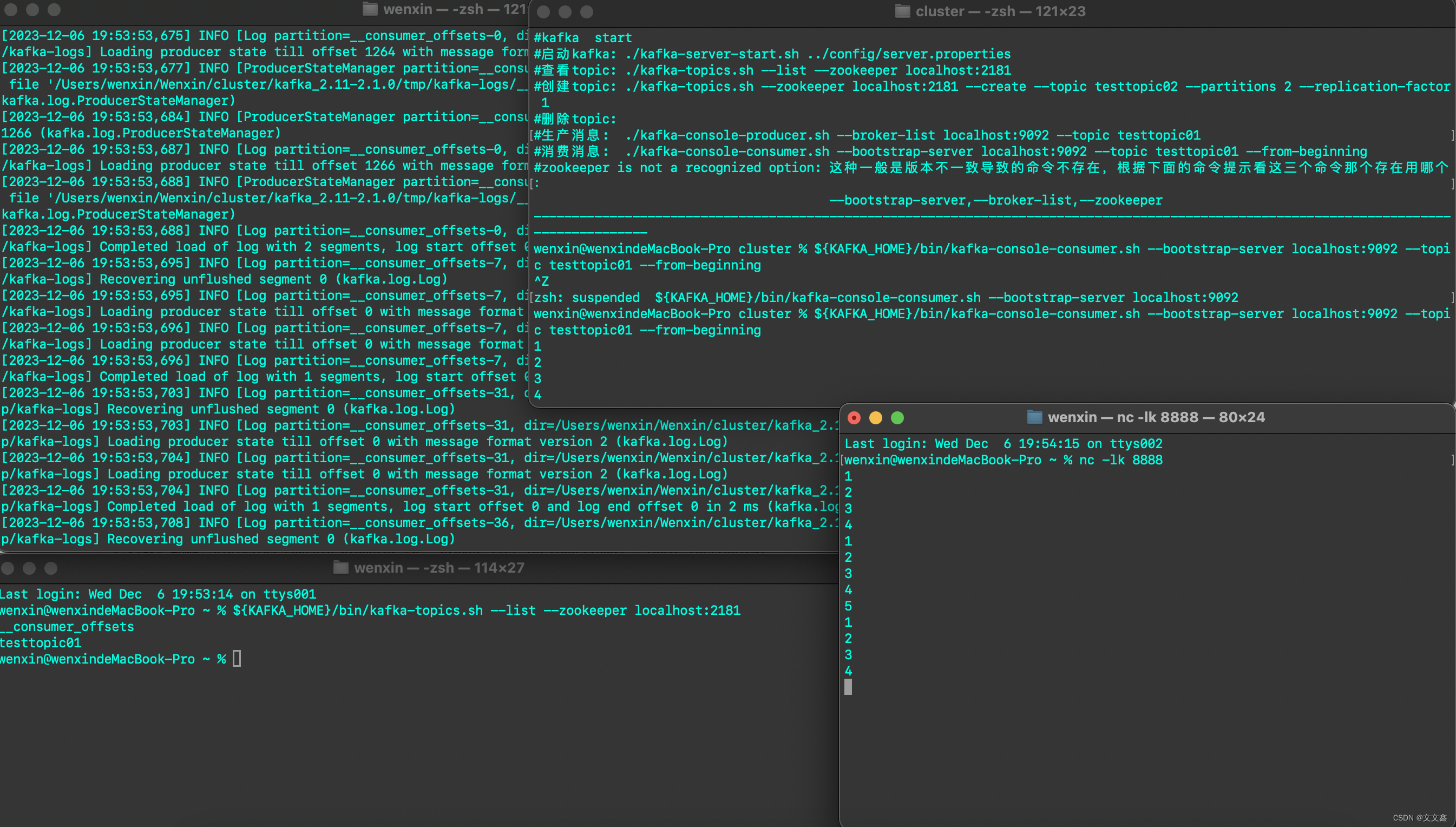
三、启动Zookeeper、Kafka
#启动zookeeper
${ZK_HOME}/bin/zkServer.sh start
#查看zookeeper状态
${ZK_HOME}/bin/zkServer.sh status
#启动kafka
${KAFKA_HOME}/bin/kafka-server-start.sh ${KAFKA_HOME}/config/server.properties
#查看topic
${KAFKA_HOME}/bin/kafka-topics.sh --list --zookeeper localhost:2181
#创建topic
${KAFKA_HOME}/bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic testtopic02 --partitions 2 --replication-factor 1
#删除topic
${KAFKA_HOME}/bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic testtopic02
#生产消息
${KAFKA_HOME}/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testtopic01
#消费消息
${KAFKA_HOME}/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testtopic01 --from-beginning
通过socket模拟数据写入Flink之后,Flink将数据写入Kafka