由于Redis 支持比较丰富的数据结构,因此他能实现的功能并不仅限于缓存,而是可以运用到各种业务场景中,开发出既简洁、又高效的系统
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
1. 缓存
Redis 的几个常用数据结构都可以用于缓存
2. 抽奖(Set 结构)
抽个奖吧!一堆用户参与进来,然后随机抽取几个幸运用户给予实物/虚拟的奖品;此时,开发人员就需要写上一个抽奖的算法,来实现幸运用户的抽取;其实我们完全可以利用 Redis 的集合(Set),就能轻松实现抽奖的功能
①:所需命令:
SADD key member1 [member2]:添加一个或者多个参与用户SRANDMEMBER KEY [count]:随机返回一个或者多个用户SPOP key:随机返回一个或者多个用户,并删除返回的用户
SRANDMEMBER 和 SPOP 主要用于两种不同的抽奖模式:SRANDMEMBER 适用于一个用户可中奖多次的场景(就是中奖之后,不从用户池中移除,继续参与其他奖项的抽取);而 SPOP 就适用于仅能中一次的场景(一旦中奖,就将用户从用户池中移除,后续的抽奖,就不可能再抽到该用户); 通常 SPOP 会用的会比较多
②:Redis-cli 操作:
# 添加一个用户
127.0.0.1:6379> SADD lottery user1
(integer) 1
# 添加九个用户
127.0.0.1:6379> SADD lottery user2 user3 user4 user5 user6 user7 user8 user9 user10
(integer) 9
# 随机抽奖两个用户(不移除抽奖池)
127.0.0.1:6379> SRANDMEMBER lottery 2
1) "user5"
2) "user4"
# 随机抽奖两个用户(移除抽奖池:user2、user5)
127.0.0.1:6379> SPOP lottery 2
1) "user2"
2) "user5"
# 随机抽奖两个用户(移除抽奖池:user7、user4)
127.0.0.1:6379> SPOP lottery 2
1) "user7"
2) "user4"
127.0.0.1:6379>
③:SpringBoot 实现:
@RestController
@RequestMapping("/test")
public class TestController {private static final String LOTTERY_PREFIX = "lottery:";@Autowiredprivate RedisTemplate<String, Object> redisTemplate;@GetMapping("/lottery")public void lottery(Integer count) {Integer lotteryId = 1;String key = LOTTERY_PREFIX + lotteryId;redisTemplate.opsForSet().add(key, 1001, 1002, 1003, 1004, 1005);// 随机抽取:抽完之后将用户移除奖池List<Object> results = redisTemplate.opsForSet().pop(key, count);// 随机抽取:抽完之后用户保留在池子里//List<Object> list = redisTemplate.opsForSet().randomMembers(key, num);System.out.println(results);}
}
3. 实现点赞/收藏功能(Set)
有互动属性APP一般都会有点赞/收藏/喜欢等功能,来提升用户之间的互动。
-
传统的实现:用户点赞之后,在数据库中记录一条数据,同时一般都会在主题库中记录一个点赞/收藏汇总数,来方便显示;
-
Redis 方案:基于 Redis 的集合(Set),记录每个帖子/文章对应的收藏、点赞的用户数据,同时set还提供了检查集合中是否存在指定用户,用户快速判断用户是否已经点赞过
①:所需命令:
SADD key member1 [member2]:添加一个或者多个成员(点赞)SCARD key:获取所有成员的数量(点赞数量)SISMEMBER key member:判断成员是否存在(是否点赞)SREM key member1 [member2]:移除一个或者多个成员(取消点赞)SMEMBERS key:查看所有成员
②:Redis-cli 操作:
# user1 给文章点赞
127.0.0.1:6379> SADD like:article:1 user1
(integer) 1
# user2 给文章点赞
127.0.0.1:6379> SADD like:article:1 user2
(integer) 1
# 获取点赞数量
127.0.0.1:6379> SCARD like:article:1
(integer) 2
# 判断 user3 是否给文章点赞
127.0.0.1:6379> SISMEMBER like:article:1 user3
(integer) 0
# 判断 user1 是否给文章点赞
127.0.0.1:6379> SISMEMBER like:article:1 user1
(integer) 1
# user1 取消点赞
127.0.0.1:6379> SREM like:article:1 user1
(integer) 1
# 获取点赞数量
127.0.0.1:6379> SCARD like:article:1
(integer) 1
127.0.0.1:6379> SMEMBERS like:article:1
1) "user2"
127.0.0.1:6379>
③:SpringBoot 实现:
private static final String LIKE_ARTICLE_PREFIX = "like:article:";@GetMapping("/doLike")
public void doLike() {Integer articleId = 100;String key = LIKE_ARTICLE_PREFIX + articleId;// 点赞Long likeNum = redisTemplate.opsForSet().add(key, 1001, 1002, 1003, 1004, 1005);// 取消点赞Long unlikeNum = redisTemplate.opsForSet().remove(key, 1002);// 点赞数量Long size = redisTemplate.opsForSet().size(key);// 某个用户是否点赞Boolean aBoolean = redisTemplate.opsForSet().isMember(key, 1005);
}
4. 排行榜(ZSet)
排名、排行榜、热搜榜是很多APP、游戏都有的功能,常用于用户活动推广、竞技排名、热门信息展示等功能
-
常规的做法:就是将用户的名次、分数等用于排名的数据更新到数据库,然后查询的时候通过Order by + limit 取出前50名显示,如果是参与用户不多,更新不频繁的数据,采用数据库的方式也没有啥问题,但是一旦出现爆炸性热点资讯,短时间会出现爆炸式的流量,瞬间的压力可能让数据库扛不住
-
Redis 方案:将热点资讯全页缓存,采用Redis的有序队列(Sorted Set)来缓存热度(SCORES),即可瞬间缓解数据库的压力,同时轻松筛选出热度最高的50条
①:所需命令:
ZADD key score1 member1 [score2 member2]:添加并设置 SCORES,支持一次性添加多个;ZREVRANGE key start stop [WITHSCORES]:根据 SCORES 降序排列;ZRANGE key start stop [WITHSCORES]:根据 SCORES 升序排列
②:Redis-cli 操作:
# 添加一个成员
127.0.0.1:6379> ZADD ranking 1 user1
(integer) 1
# 添加 4 个成员
127.0.0.1:6379> ZADD ranking 10 user2 50 user3 3 user4 25 user5
(integer) 4
# 所有成员降序排列
127.0.0.1:6379> ZREVRANGE ranking 0 -1
1) "user3"
2) "user5"
3) "user2"
4) "user4"
5) "user1"
# 前三成员降序排列
127.0.0.1:6379> ZREVRANGE ranking 0 2 WITHSCORES
1) "user3"
2) "50"
3) "user5"
4) "25"
5) "user2"
6) "10"
127.0.0.1:6379>
③:SpringBoot 实现:
private final String RANKING_PREFIX = "ranking";
@GetMapping("/doRanking")
public void doRanking() {redisTemplate.opsForZSet().add(RANKING_PREFIX, 1001, (double)60);redisTemplate.opsForZSet().add(RANKING_PREFIX, 1002, (double)70);redisTemplate.opsForZSet().add(RANKING_PREFIX, 1003, (double)80);redisTemplate.opsForZSet().add(RANKING_PREFIX, 1004, (double)75);redisTemplate.opsForZSet().add(RANKING_PREFIX, 1005, (double)50);// 获取所有Set<ZSetOperations.TypedTuple<Object>> set = redisTemplate.opsForZSet().reverseRangeWithScores(RANKING_PREFIX, 0, -1);// 前三名set = redisTemplate.opsForZSet().reverseRangeWithScores(RANKING_PREFIX, 0, 2);
}
5. PV 统计(incr 自增计数)
Page View(PV)指的是页面浏览量,是用来衡量流量的一个重要标准,也是数据分析很重要的一个依据;通常统计规则是页面被展示一次,就加一
①:所需命令:
INCR:将 key 中储存的数字值增一
②:Redis-cli 操作:
127.0.0.1:6379> INCR pv:article:1
(integer) 1
127.0.0.1:6379> INCR pv:article:1
(integer) 2
127.0.0.1:6379>
6. UV 统计(HeyperLogLog)
前面,介绍了通过(INCR)方式来实现页面的PV;除了PV之外,UV(独立访客)也是一个很重要的统计数据;
但是如果要想通过计数(INCR)的方式来实现UV计数,就非常的麻烦,增加之前,需要判断这个用户是否访问过;那判断依据就需要额外的方式再进行记录
你可能会说,不是还有 Set 嘛!一个页面弄个集合,来一个用户塞(SADD)一个用户进去,要统计 UV 的时候,再通过 SCARD 汇总一下数量,就能轻松搞定了;此方案确实能实现 UV 的统计效果,但是忽略了成本;如果是普通页面,几百、几千的访问,可能造成的影响微乎其微,如果一旦遇到爆款页面,动辄上千万、上亿用户访问时,就一个页面 UV 将会带来非常大的内存开销,对于如此珍贵的内存来说,这显然是不划算的
此时,HeyperLogLog 数据结构,就能完美的解决这一问题,它提供了一种不精准的去重计数方案,注意!这里强调一下,是不精准的,会存在误差,不过误差也不会很大,标准的误差率是0.81%,这个误差率对于统计 UV 计数,是能够容忍的;所以,不要将这个数据结构拿去做精准的去重计数
另外,HeyperLogLog 是会占用 12KB 的存储空间,虽然说,Redis 对 HeyperLogLog 进行了优化,在存储数据比较少的时候,采用了稀疏矩阵存储,只有在数据量变大,稀疏矩阵空间占用超过阈值时,才会转为空间为 12KB 的稠密矩阵;相比于成千、上亿的数据量,这小小的 12KB,简直是太划算了;但是还是建议,不要将其用于数据量少,且频繁创建 HeyperLogLog 的场景,避免使用不当,造成资源消耗没减反增的不良效果
①:所需命令:
PFADD key element [element ...]:增加计数(统计 UV)PFCOUNT key [key ...]:获取计数(货物 UV)PFMERGE destkey sourcekey [sourcekey ...]:将多个 HyperLogLog 合并为一个 HyperLogLog(多个合起来统计)
②:Redis-cli 操作:
# 添加三个用户的访问
127.0.0.1:6379> PFADD uv:page:1 user1 user2 user3
(integer) 1
# 获取 UV 数量
127.0.0.1:6379> PFCOUNT uv:page:1
(integer) 3
# 再添加三个用户的访问 user3 是重复用户
127.0.0.1:6379> PFADD uv:page:1 user3 user4 user5
(integer) 1
# 获取 UV 数量 user3 是重复用户 所以这里返回的是 5
127.0.0.1:6379> PFCOUNT uv:page:1
(integer) 5
127.0.0.1:6379>
③:SpringBoot 实现:
模拟测试 10000 个用户访问 id 为 2 的页面
private final String UV_PAGE_PREFIX = "uv:page:";
@GetMapping("/doUv")
public void doUv() {Integer pageId = 2;String key = UV_PAGE_PREFIX + pageId;for (int i = 0; i < 10000; i++) {redisTemplate.opsForHyperLogLog().add(key, i);}Long uvSize = redisTemplate.opsForHyperLogLog().size(key);
}
7. 去重(BloomFiler)
通过上面 HeyperLogLog 的学习,我们掌握了一种不精准的去重计数方案,但是有没有发现,他没办法获取某个用户是否访问过;理想中,我们是希望有一个 PFEXISTS 的命令,来判断某个key是否存在,然而 HeyperLogLog 并没有;要想实现这一需求,就得 BloomFiler 上场了。
loom Filter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法。通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合。基于一种概率数据结构来实现,是一个有趣且强大的算法。
举个例子:假如你写了一个爬虫,用于爬取网络中的所有页面,当你拿到一个新的页面时,如何判断这个页面是否爬取过?
普通做法:每爬取一个页面,往数据库插入一行数据,记录一下URL,每次拿到一个新的页面,就去数据库里面查询一下,存在就说明爬取过;
- 缺点:少量数据,用传统方案没啥问题,如果是海量数据,每次爬取前的检索,将会越来越慢;如果你的爬虫只关心内容,对来源数据不太关心的话,这部分数据的存储,也将消耗你很大的物理资源;
此时通过 BloomFiler 就能以很小的内存空间作为代价,即可轻松判断某个值是否存在。
同样,BloomFiler 也不那么精准,在默认参数情况下,是存在 1% 左右的误差;但是 BloomFiler 是允许通过 error_rate(误差率)以及 initial_size(预计大小)来设置他的误差比例
- error_rate:误差率,越低,需要的空间就越大;
- initial_size:预计放入值的数量,当实际放入的数量大于设置的值时,误差率就会逐渐升高;所以为了避免误差率,可以提前做好估值,避免再次大的误差
①:所需命令:
bf.reserve创建布隆过滤器bf.add添加单个元素bf.madd批量添加bf.exists检测元素是否存在bf.mexists批量检测
②:SpringBoot 实现:
需要下载布隆过滤器插件:redis安装布隆过滤器 windows redis 实现布隆过滤器
@Component
public class RedisBloomUtil {private static final RedisScript<Boolean> BFRESERVE_SCRIPT = new DefaultRedisScript<>("return redis.call('bf.reserve', KEYS[1], ARGV[1], ARGV[2])", Boolean.class);private static final RedisScript<Boolean> BFADD_SCRIPT = new DefaultRedisScript<>("return redis.call('bf.add', KEYS[1], ARGV[1])", Boolean.class);private static final RedisScript<Boolean> BFEXISTS_SCRIPT = new DefaultRedisScript<>("return redis.call('bf.exists', KEYS[1], ARGV[1])", Boolean.class);private static final String BFMEXISTS_SCRIPT = "return redis.call('bf.mexists', KEYS[1], %s)";@Autowiredprivate RedisTemplate<String, Object> redisTemplate;/*** 设置错误率和大小(需要在添加元素前调用,若已存在元素,则会报错)* 错误率越低,需要的空间越大** @param key* @param errorRate 错误率,默认0.01* @param initialSize 默认100,预计放入的元素数量,当实际数量超出这个数值时,误判率会上升,尽量估计一个准确数值再加上一定的冗余空间* @return*/public Boolean bfreserve(String key, double errorRate, int initialSize) {return redisTemplate.execute(BFRESERVE_SCRIPT, Collections.singletonList(key), String.valueOf(errorRate), String.valueOf(initialSize));}/*** 添加元素** @param key* @param value* @return true表示添加成功,false表示添加失败(存在时会返回false)*/public Boolean bfadd(String key, String value) {return redisTemplate.execute(BFADD_SCRIPT, Collections.singletonList(key), value);}/*** 查看元素是否存在(判断为存在时有可能是误判,不存在是一定不存在)** @param key* @param value* @return true表示存在,false表示不存在*/public Boolean bfexists(String key, String value) {return redisTemplate.execute(BFEXISTS_SCRIPT, Collections.singletonList(key), value);}/*** 批量添加元素** @param key* @param values* @return 按序 1表示添加成功,0表示添加失败*/public List<Integer> bfmadd(String key, String... values) {String bfmaddScript = "return redis.call('bf.madd', KEYS[1], %s)";return (List<Integer>) redisTemplate.execute(this.generateScript(bfmaddScript, values), Arrays.asList(key), values);}/*** 批量检查元素是否存在(判断为存在时有可能是误判,不存在是一定不存在)** @param key* @param values* @return 按序 1表示存在,0表示不存在*/public List<Integer> bfmexists(String key, String... values) {return (List<Integer>) redisTemplate.execute(this.generateScript(BFMEXISTS_SCRIPT, values), Arrays.asList(key), values);}private RedisScript<List> generateScript(String script, String[] values) {StringBuilder sb = new StringBuilder();for (int i = 1; i <= values.length; i++) {if (i != 1) {sb.append(",");}sb.append("ARGV[").append(i).append("]");}return new DefaultRedisScript<>(String.format(script, sb.toString()), List.class);}}
测试:
private final String WEB_CRAWLER_PREFIX = "web:crawler1";
@Autowired
private RedisBloomUtil redisBloomUtil;@GetMapping("/doBloom")
public void doBloom() {Boolean hasKey = redisTemplate.hasKey(WEB_CRAWLER_PREFIX);if (Boolean.FALSE.equals(hasKey)) {redisBloomUtil.bfreserve(WEB_CRAWLER_PREFIX, 0.0001, 10000);}List<Integer> madd = redisBloomUtil.bfmadd(WEB_CRAWLER_PREFIX, "baidu", "google");Boolean baidu = redisBloomUtil.bfexists(WEB_CRAWLER_PREFIX, "baidu");Boolean bing = redisBloomUtil.bfexists(WEB_CRAWLER_PREFIX, "bing");
}
8. 用户签到(BitMap)
很多 APP 为了拉动用户活跃度,往往都会做一些活动,比如连续签到领积分/礼包等等
-
传统做法:用户每次签到时,往是数据库插入一条签到数据,展示的时候,把本月(或者指定周期)的签到数据获取出来,用于判断用户是否签到、以及连续签到情况;此方式,简单,理解容易;
-
Redis 做法:由于签到数据的关注点就2个:是否签到(0/1)、连续性,因此就完全可以利用 BitMap(位图)来实现;
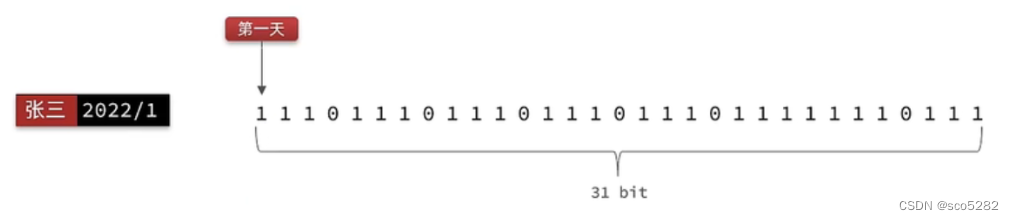
如上图所示,将一个月的 31 天,用 31 个位(4个字节)来表示,偏移量(offset)代表当前是第几天,0/1 表示当前是否签到,连续签到只需从右往左校验连续为 1 的位数;
由于 String 类型的最大上限是 512M,转换为 bit 则是 2^32 个 bit 位
①:所需命令:
SETBIT key offset value:向指定位置 offset 存入一个 0 或 1GETBIT key offset:获取指定位置 offset 的 bit 值BITCOUNT key [start] [end]:统计 BitMap 中值为 1 的 bit 位的数量BITFIELD: 操作(查询,修改,自增)BitMap 中 bit 数组中的指定位置 offset 的值
BITFIELD 命令:https://deepinout.com/redis-cmd/redis-bitmap-cmd/redis-cmd-bitfield.html
场景:假如当前为 8 月 4 号,检测本月的签到情况,用户 ID 为 8899 分别于 1、3、4 号签到过
②:Redis-cli 操作:
# 8月1号的签到
127.0.0.1:6379> SETBIT rangeId:sign:1:8899 0 1
(integer) 0
# 8月3号的签到
127.0.0.1:6379> SETBIT rangeId:sign:1:8899 2 1
(integer) 0
# 8月4号的签到
127.0.0.1:6379> SETBIT rangeId:sign:1:8899 3 1
(integer) 0
# 查询2号
127.0.0.1:6379> GETBIT rangeId:sign:1:8899 1
(integer) 0
# 查询3号
127.0.0.1:6379> GETBIT rangeId:sign:1:8899 2
(integer) 1
# 查询指定区间的签到情况
127.0.0.1:6379> BITFIELD rangeId:sign:1:8899 GET u4 0
1) (integer) 11
127.0.0.1:6379>
1-4号的签到情况为:1011(二进制) ==> 11(十进制)
9. 搜附近(GEO)
Redis 在 3.2 的版本新增了 Redis GEO,用于存储地址位置信息,并对支持范围搜索;基于 GEO 就能轻松且快速的开发一个搜索附近的功能
①:所需命令:
-
GEOADD key longitude latitude member [longitude latitude member ...]:新增位置坐标 -
GEOPOS key member [member ...]:获取位置坐标 -
GEODIST key member1 member2 [unit]:计算两个位置之间的距离- m :米,默认单位
- km :千米
- mi :英里
- ft :英尺
-
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC]:根据用户给定的经纬度坐标来获取指定范围内的地理位置集合m|km|ft|mi:同上WITHDIST: 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回WITHCOORD:将位置元素的经度和纬度也一并返回WITHHASH:以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。这个选项主要用于底层应用或者调试, 实际中的作用并不大COUNT:限定返回的记录数ASC:查找结果根据距离从近到远排序DESC:查找结果根据从远到近排序
-
GEORADIUSBYMEMBER key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC]:根据储存在位置集合里面的某个地点获取指定范围内的地理位置集合功能和上面的georadius类似,只是georadius是以经纬度坐标为中心,这个是以某个地点为中心
-
GEOHASH key member [member ...]:返回一个或多个位置对象的 geohash 值
②:Redis-cli 操作:
# 新增位置坐标(3 个)
127.0.0.1:6379> GEOADD drinks 116.62445 39.86206 starbucks 117.3514785 38.7501247 yidiandian 116.538542 39.75412 xicha
(integer) 3
# 获取位置坐标
127.0.0.1:6379> GEOPOS drinks starbucks yidiandian
1) 1) "116.62445157766342163"2) "39.86206038535793539"
2) 1) "117.35148042440414429"2) "38.75012383773680114"
# 计算两个位置之间的距离
127.0.0.1:6379> GEODIST drinks starbucks xicha
"14072.1255"
127.0.0.1:6379> GEORADIUS drinks 116 39 100 km WITHDIST WITHCOORD
1) 1) "xicha"2) "95.8085"3) 1) "116.53854042291641235"2) "39.75411928478748536"
10. 简单限流
为了保证项目的安全稳定运行,防止被恶意的用户或者异常的流量打垮整个系统,一般都会加上限流,比如常见的 sential、hystrix,都是实现限流控制;如果项目用到了 Redis,也可以利用 Redis,来实现一个简单的限流功能
①:所需命令:
INCR:将 key 中储存的数字值增一Expire:设置 key 的有效期
11. 全局 ID
在分布式系统中,很多场景下需要全局的唯一 ID,由于 Redis 是独立于业务服务的其他应用,就可以利用 Incr 的原子性操作来生成全局的唯一递增 ID
①:所需命令:
INCR:将 key 中储存的数字值增一
12. 简单分布式锁
在分布式系统中,很多操作是需要用到分布式锁,防止并发操作带来一些问题;因为 Redis 是独立于分布式系统外的其他服务,因此就可以利用 Redis,来实现一个简单的不完美分布式锁
①:所需命令:
SETNX:key 不存在,设置;key 存在,不设置
13. 认识的人/好友推荐(Set)
在支付宝、抖音、QQ等应用中,都会看到好友推荐;
好友推荐往往都是基于你的好友关系网来推荐,将你可能认识的人推荐给你,让你去添加好友,如果随意在系统找个人推荐给你,那你认识的可能性是非常小的,此时就失去了推荐的目的;
比如,A和B是好友,B和C是好友,此时A和C认识的概率是比较大的,就可以在A和C之间的好友推荐;
基于这个逻辑,就可以利用 Redis 的 Set 集合,缓存各个用户的好友列表,然后以差集的方式,来实现好友推荐;
①:所需命令:
SADD key member [member …]:集合中添加元素,缓存好友列表SDIFF key [key …]:取两个集合间的差集,找出可以推荐的用户
②:Redis-cli 操作:
# 记录 用户1 的好友列表
127.0.0.1:6379> SADD fl:user1 user2 user3
(integer) 2
# 记录 用户2 的好友列表
127.0.0.1:6379> SADD fl:user2 user1 user4
(integer) 2
# 用户1 可能认识的人 ,把自己(user1)去掉,user4是可能认识的人
127.0.0.1:6379> SDIFF fl:user2 fl:user1
1) "user1"
2) "user4"
127.0.0.1:6379>
14. 发布/订阅
发布/订阅是比较常用的一种模式;在分布式系统中,如果需要实时感知到一些变化,比如:某些配置发生变化需要实时同步,就可以用到发布,订阅功能
①:所需命令:
PUBLISH channel message:将消息推送到指定的频道SUBSCRIBE channel [channel …]:订阅给定的一个或多个频道的信息
15. 消息队列(List)
说到消息队列,常用的就是Kafka、RabbitMQ等等,其实 Redis 利用 List 也能实现一个消息队列
①:所需命令:
RPUSH key value1 [value2]:在列表中添加一个或多个值BLPOP key1 [key2] timeout:移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止BRPOP key1 [key2] timeout:移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止
16. 商品筛选(Set)
商城类的应用,都会有类似于下图的一个商品筛选的功能,来帮用户快速搜索理想的商品
①:所需命令:
SADD key member [member …]:添加一个或多个元素SINTER key [key …]:返回给定所有集合的交集
②:Redis-cli 操作:
假如现在iphone 100 、华为mate 5000 已发布,在各大商城上线
# 将iphone100 添加到品牌为苹果的集合
127.0.0.1:6379> sadd brand:apple iphone100
(integer) 1# 将meta5000 添加到品牌为苹果的集合
127.0.0.1:6379> sadd brand:huawei meta5000
(integer) 1# 将 meta5000 iphone100 添加到支持5T内存的集合
127.0.0.1:6379> sadd ram:5t iphone100 meta5000
(integer) 2# 将 meta5000 添加到支持10T内存的集合
127.0.0.1:6379> sadd ram:10t meta5000
(integer) 1# 将 iphone100 添加到操作系统是iOS的集合
127.0.0.1:6379> sadd os:ios iphone100
(integer) 1# 将 meta5000 添加到操作系统是Android的集合
127.0.0.1:6379> sadd os:android meta5000
(integer) 1# 将 iphone100 meta5000 添加到屏幕为6.0-6.29的集合中
127.0.0.1:6379> sadd screensize:6.0-6.29 iphone100 meta5000
(integer) 2# 筛选内存5T、屏幕在6.0-6.29的机型
127.0.0.1:6379> sinter ram:5t screensize:6.0-6.29
1) "meta5000"
2) "iphone100"# 筛选内存10T、屏幕在6.0-6.29的机型
127.0.0.1:6379> sinter ram:10t screensize:6.0-6.29
1) "meta5000"# 筛选内存5T、系统为iOS的机型
127.0.0.1:6379> sinter ram:5t screensize:6.0-6.29 os:ios
1) "iphone100"# 筛选内存5T、屏幕在6.0-6.29、品牌是华为的机型
127.0.0.1:6379> sinter ram:5t screensize:6.0-6.29 brand:huawei
1) "meta5000"
17. 购物车(Hash)
商品缓存: 电商项目中,商品消息,都会做缓存处理,特别是热门商品,访问用户比较多,由于商品的结果比较复杂,店铺信息,产品信息,标题、描述、详情图,封面图;为了方便管理和操作,一般都会采用 Hash 的方式来存储(key为商品ID,field用来保存各项参数,value保存对于的值)
购物车: 当商品信息做了缓存,购物车需要做的,就是通过Hash记录商品ID,以及需要购买的数量(其中key为用户信息,field为商品ID,value用来记录购买的数量)
①:所需命令:
HSET key field value:将哈希表 key 中的字段 field 的值设为 valueHMSET key field1 value1 [field2 value2 ]:同时将多个 field-value (域-值)对设置到哈希表 key 中HGET key field:获取存储在哈希表中指定字段的值HGETALL key:获取在哈希表中指定 key 的所有字段和值HINCRBY key field increment:为哈希表 key 中的指定字段的整数值加上增量 incrementHLEN key:获取哈希表中字段的数量
②:Redis-cli 操作:
# 购物车添加单个商品
127.0.0.1:6379> HSET sc:u1 c001 1
(integer) 1
# 购物车添加多个商品
127.0.0.1:6379> HMSET sc:u1 c002 1 coo3 2
OK
# 添加商品购买数量
127.0.0.1:6379> HINCRBY sc:u1 c002 1
(integer) 2
# 减少商品的购买数量
127.0.0.1:6379> HINCRBY sc:u1 c003 -1
(integer) 1
# 获取单个的购买数量
127.0.0.1:6379> HGET sc:u1 c002
"2"
# 获取购物车的商品数量
127.0.0.1:6379> HLEN sc:u1
(integer) 3
# 购物车详情
127.0.0.1:6379> HGETALL sc:u1
1) "c001"
2) "1"
3) "c002"
4) "2"
5) "coo3"
6) "2"
18. 物流信息(List)
寄快递、网购的时候,查询物流信息,都会给我们展示xxx时候,快递到达什么地方了,这就是一个典型的时间线列表
数据库的做法:每次变更就插入一条带时间的信息记录,然后根据时间和ID(ID是必须的,如果出现两个相同的时间,单纯时间排序,会造成顺序不对),来排序生成时间线
也可以通过 Redis 的 List 来实现时间线功能,由于 List 采用的是双向链表,因此升序,降序的时间线都能正常满足
①:所需命令:
RPUSH key value1 [value2]:在列表中添加一个或多个值,(升序时间线)LPUSH key value1 [value2]:将一个或多个值插入到列表头部(降序时间线)LRANGE key start stop:获取列表指定范围内的元素
②:Redis-cli 操作:
升序:
127.0.0.1:6379> RPUSH time:line:asc 20220805170000
(integer) 1
127.0.0.1:6379> RPUSH time:line:asc 20220805170001
(integer) 2
127.0.0.1:6379> RPUSH time:line:asc 20220805170002
(integer) 3
127.0.0.1:6379> LRANGE time:line:asc 0 -1
1) "20220805170000"
2) "20220805170001"
3) "20220805170002"
降序:
127.0.0.1:6379> LPUSH time:line:desc 20220805170000
(integer) 1
127.0.0.1:6379> LPUSH time:line:desc 20220805170001
(integer) 2
127.0.0.1:6379> LPUSH time:line:desc 20220805170002
(integer) 3
127.0.0.1:6379> LRANGE time:line:desc 0 -1
1) "20220805170002"
2) "20220805170001"
3) "20220805170000"
好了,关于Redis 的妙用,就介绍到这里;有了这些个场景的运用,下次再有面试官问你,Redis除了缓存还做过什么,相信聊上个1把小时,应该不成问题了