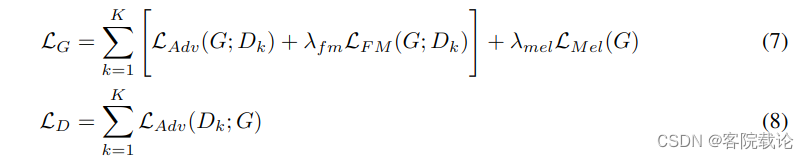【时间序列】单变量单步预测方法总结
目录
- 【时间序列】单变量单步预测方法总结
- 前言
- 一、探索性数据分析
- 1. 平稳性检测
- 2. 白噪声检测
- 3. 自相关与偏自相关图
- 4. 搜索最佳`ARIMA`模型参数
- 5. 可视化分析
- 6. 异常数据检测
- 二、建模预测
- 1. ARIMA模型
- 2. LightGBM模型
- 3. LSTM模型
- 4. Transformer模型
- 三、不同数据集的评分情况
- 四、总结
- 五、参考链接
- 写在最后
前言
- 好久不见呀,朋友们~
- 距离上一篇博客已经是半年前的了
- 相信大家最近都有关注到
ChatGPT、Segment Anything Model、AutoGPT吧,这些大模型正席卷NLP和CV领域,试图将它们统一。目前看来,推荐系统和时间序列这两座大山被统一还有很长的路要走 - 所以我再三思考,决定先从时间序列开始,系统地学习这两座大山,并把学习过程记录下来,大家一起交流交流~
一、探索性数据分析
PS:数据源:每日最低气温
1. 平稳性检测
from statsmodels.tsa.stattools import adfuller
# H0:具有单位根,属于非平稳序列。
# H1:没有单位根,属于平稳序列,说明这个序列不具有时间依赖型结构。
data,train,valid,test = get_data()
result = adfuller(train)
print('The ADF Statistic of yarn yield: %f' % result[0])
print('The p value of yarn yield: %f' % result[1])
# p < 0.05,拒绝原假设,即是平稳序列。
2. 白噪声检测
from statsmodels.stats.diagnostic import acorr_ljungbox
# H0:序列的每个值是独立的,即纯随机
# H1:序列之间不是独立的,即存在相关性acorr_ljungbox(train,lags=6,return_df=True)
# p < 0.05,拒绝原假设,即不是纯随机的。
3. 自相关与偏自相关图
from matplotlib import pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf,plot_pacffig,ax=plt.subplots(1,2,figsize=(16,4))
plot_acf(train,ax=ax[0],lags=70) # 生成自相关图
plot_pacf(train,ax=ax[1]) # 生成偏自相关图
plt.show()

4. 搜索最佳ARIMA模型参数
statsmodels模块的方法
import statsmodels.api as smtrend_evaluate = sm.tsa.arma_order_select_ic(train, ic=['aic', 'bic'], trend='nc', max_ar=5,max_ma=5)
print('train AIC', trend_evaluate.aic_min_order)
print('train BIC', trend_evaluate.bic_min_order)# train AIC (3, 5)
# train BIC (3, 1)
pmdarima模块的方法
from pmdarima.arima import AutoARIMAauto_arima = AutoARIMA(start_p=1,start_q=1,max_p=5,max_q=5,trace=True,information_criterion='aic',random_state=2023)
auto_arima.fit(train)
auto_arima.summary()# Best model: ARIMA(3,0,1)(0,0,0)[0] intercept
# Total fit time: 17.270 seconds
5. 可视化分析
def get_trend(timeseries, deg=3):# 多项式拟合x = list(range(len(timeseries)))y = timeseries.valuescoef = np.polyfit(x, y, deg)trend = np.poly1d(coef)(x)return pd.Series(data=trend, index = timeseries.index)plt.figure(figsize=(12,8))
plt.plot(data.set_index('Date')['Temp'],label='data')
plt.plot(get_trend(data.set_index('Date')['Temp']),label='trend')
plt.legend()
plt.show()

fig,ax=plt.subplots(2,2,figsize=(22,8))
tmp=data.sort_values('month').groupby(pd.to_datetime(data['Date']).dt.month_name(),sort=False)['Temp'].mean()
ax[0][0].bar(tmp.index,tmp.values.flatten())
tmp=data.sort_values('quarter').groupby('第 '+data['quarter'].astype(str)+' 季度',sort=False)['Temp'].mean()
ax[0][1].bar(tmp.index,tmp.values.flatten())
tmp=data.sort_values('week').groupby(pd.to_datetime(data['Date']).dt.day_name(),sort=False)['Temp'].mean()
ax[1][0].bar(tmp.index,tmp.values.flatten())
tmp=data.sort_values('weeknum').groupby(data['weeknum'].astype(str),sort=False)['Temp'].mean()
ax[1][1].bar(tmp.index,tmp.values.flatten())
ax[1][1].set_xlabel('weeknum')
plt.show()
# 所以是有季节性的,按周算也有很大的差异

6. 异常数据检测
PS:罗列几个相对简单的异常检测方法,因为异常检测也是一个比较大的方向,后续也会系统地研究。
- μ ± 3 σ 方法
def outlier_detection_from_sigma_std(series,sigma=3):mean=series.mean()std=series.std()outlier_data=series[(series>mean+sigma*std)|((series<mean-sigma*std))].copy()return outlier_data
- 箱线图分位数法
def outlier_detection_from_sigma_box_plot(series,sigma=3):q1 = series.quantile(0.25)q3 = series.quantile(0.75)gap = q3 - q1outlier_data=series[(series>q3+sigma*gap)|((series<q1-sigma*gap))].copy()return outlier_data
- 基于密度的检测
def outlier_detection_from_kde(series,threshold=0.001):# https://www.heywhale.com/mw/project/63fb0b0d7c8294eafa28e5f6from scipy.stats import gaussian_kde# Estimate the probability density functionkde = gaussian_kde(series)# Compute the probability density for each data pointprobs = kde.pdf(series)# Find the anomalies (data points with probability density less than threshold)outlier_data = series.loc[probs < threshold]return outlier_data
二、建模预测
PS:将最后的两个月,一个月作为验证集,一个月作为测试集,其余都用来训练模型。
1. ARIMA模型
从上面的探索性数据分析可知,ARIMA模型的最佳参数是:ARIMA(3,0,1),则通过statsmodels模块提供的接口建立此模型,对训练集进行训练,并预测出验证集和测试集,结果如下:
| 预测训练集、验证集和测试集 | 预测未来一个月 |
|---|---|
 |  |
all: mse=5.847751826452781 mae=1.8933863604592667
valid: mse=6.3922606422321016 mae=1.9229397467968572
test: mse=10.03178887453495 mae=2.4026584529298383
- 从预测的结果可以看出,效果不是很好,像是用平均值来填充的,因为这是连续的预测
- 但从训练集的预测上看,似乎还行呀,我猜其实相当于是one by one的预测
- 下面再来看看one by one的预测,即只预测未来一个值,然后将真实值代入训练集重新训练模型
- 然后再预测未来一个值,直至预测完验证集和测试集所有数据,但未来一个月的预测则还是得连续预测
| 预测训练集、验证集和测试集 | 预测未来一个月 |
|---|---|
 |  |
all: mse=5.795908770551495 mae=1.8859580404463674
valid: mse=5.772103587834295 mae=1.8762061001351766
test: mse=4.524494406162047 mae=1.572780540437619
- 可以发现,one by one的预测方式效果好了很多,测试集的平均绝对误差降到了1.57
- 但是由于未来一个月目前是不能one by one去预测完的,所以还是一条直线不是很准确
2. LightGBM模型
要使用LightGBM模型,相当于要把时间序列问题转化为一个回归问题,则需手工构造并筛选一系列特征,且只能使用当前时刻过去的历史时刻的数据进行构造,一般是对时间点提取月、周、日等特征,对变量取lag、rolling之后的mean、sum、std等特征,如下代码为我的特征工程函数:
# 特征工程
def feature_engineering(data):df=data.copy()df['month']=df['Date'].apply(lambda x:x.month - 1)df['week']=df['Date'].apply(lambda x:x.weekday())# df['weeknum']=df['Date'].apply(lambda x:x.isocalendar()[1] - 1)df['day']=df['Date'].apply(lambda x:x.day - 1)df['quarter']=df['month'].apply(lambda x:x//3)# df['date']=df['Date'].apply(lambda x:x.strftime('%m-%d'))# df['date']=LabelEncoder().fit_transform(df['date'])lags = 12for i in range(1,lags+1):df[f'shift_{i}']=df['Temp'].shift(i)for i in range(2,lags+1):df[f'shift1_diff_{i}']=df['shift_1']-df[f'shift_{i}']# df[f'shift1_mul_{i}']=df['shift_1']*df[f'shift_{i}']# df[f'shift1_add_{i}']=df['shift_1']+df[f'shift_{i}']# df[f'shift1_div_{i}']=df['shift_1']/df[f'shift_{i}']for i in [3, 6, 12]:if i > lags:breakdf[f'shift_min_{i}'] = df[[f'shift_{i}' for i in range(1, i+1)]].min(axis=1)df[f'shift_max_{i}'] = df[[f'shift_{i}' for i in range(1, i+1)]].max(axis=1)df[f'shift_mean_{i}'] = df[[f'shift_{i}' for i in range(1, i+1)]].mean(axis=1)df[f'shift_std_{i}'] = df[[f'shift_{i}' for i in range(1, i+1)]].std(axis=1)df[f'shift_median_{i}'] = df[[f'shift_{i}' for i in range(1, i+1)]].median(axis=1)# df[f'shift_kurt_{i}'] = df[[f'shift_{i}' for i in range(1, i+1)]].kurt(axis=1)# df[f'shift_skew_{i}'] = df[[f'shift_{i}' for i in range(1, i+1)]].skew(axis=1)return df
构建完特征,训练后预测的结果如下:
| 预测训练集、验证集和测试集 | 预测未来一个月 |
|---|---|
 |  |
all: mse=4.339431964743159 mae=1.6335664977147377
valid: mse=5.05086647611983 mae=1.8041600166666014
test: mse=4.836091594359972 mae=1.5431264031611909
- 从结果以及评价指标来看,效果明显比
ARIMA模型要好的多 - 且未来一个月的连续预测稍微有了一点波动了,并不是一条直线了
- 能有这样的预测效果,是我经过了一遍又一遍的构建和筛选特征所换来的
- 所以,机器学习模型唯一的缺点呢就是需要手工构造并筛选特征了
3. LSTM模型
鉴于机器学习模型需要手工构造并筛选特征,那么与之对应的就是模型自动构造和筛选特征了,那就需要用上深度学习模型了。下面就让我们构建LSTM模型来预测吧
其中,一个关键在于将原始单变量构建为一个滑窗序列数据集,然后不断地输入到LSTM模型,让模型进行学习。下面为我构建的TimeSeriesDataSet类,主要是将这一时间序列按照固定长度seq_len的窗口进行滑窗,且令seq_len=30来构建数据集。
class TimeSeriesDataSet(Dataset):def __init__(self, data, seq_len, valid_len, test_len, scaler=None,is_valid=False, is_test=False, is_all=False):self.data_raw = dataif scaler is not None:assert scaler in ['minmax','std']if scaler == 'minmax':self.scaler = MinMaxScaler().fit(data[:-valid_len-test_len].values.reshape(-1, 1))elif scaler == 'std':self.scaler = StandardScaler().fit(data[:-valid_len-test_len].values.reshape(-1, 1))self.data = self.scaler.transform(data.values.reshape(-1,1))else:self.data = data.values.reshape(-1,1)self.seq_len = seq_lenself.valid_len = valid_lenself.test_len = test_lenself.is_valid = is_validself.is_test = is_testself.is_all = is_allself.sequences_data = self.create_sequences_data()def __len__(self):return len(self.sequences_data)def create_sequences_data(self):if self.is_valid:idx_start = len(self.data) - self.valid_len - self.test_len - self.seq_lenidx_end = len(self.data) - self.seq_len - self.test_lenelif self.is_test:idx_start = len(self.data) - self.test_len - self.seq_lenidx_end = len(self.data) - self.seq_lenelif self.is_all:idx_start = 0idx_end = len(self.data) - self.seq_lenelse:idx_start = 0idx_end = len(self.data) - self.seq_len - self.valid_len - self.test_lensequences_data = []for idx in range(idx_start,idx_end):start = idxend = start+self.seq_lenseq = self.data[start:end]label = self.data[end]sequences_data.append([seq,label])return sequences_datadef __getitem__(self, idx):seq = torch.from_numpy(self.sequences_data[idx][0]).float()label = torch.from_numpy(self.sequences_data[idx][1]).float()return seq, labeldef inverse_transform(self, data):if self.scaler is not None:return self.scaler.inverse_transform(data)else:return data
构建的LSTM模型来源于:https://github.com/curiousily/Getting-Things-Done-with-Pytorch/blob/master/05.time-series-forecasting-covid-19.ipynb
训练后预测的结果如下:
| 预测训练集、验证集和测试集 | 预测未来一个月 |
|---|---|
 |  |
all: mse=5.841430415198538 mae=1.8973894142387386
valid: mse=5.663222648173579 mae=1.8673052131869985
test: mse=4.279558615604504 mae=1.5494373785626525
- 从结果来看,综合来看,
LSMT模型的效果略微比LightGBM要好一点点 - 并且呢,因为是深度学习模型,所以完全不用手工构建和筛选特征,这一点比机器学习好太多
- 但是,未来一个月的预测值几乎也还是一条直线,差不多就是均值的样子,毫无波动
4. Transformer模型
PS:由于本人对Transformer只是了解个大概,就不说模型的细节了,怕误导你们了哈哈,我的目的只是想要达到能用这个模型来做时间序列预测即可。网上已经有很多大佬写过很详细的模型说明的,我们只需站在巨人的肩膀上前进就好了~
相比LSTM模型,Transformer模型是最近几年才出来的,而且还不是用在时间序列预测上面,而是NLP领域,而时间序列与NLP有着太多相似之处,所以众多大佬把Transformer模型的核心逻辑迁移到时间序列上来,进行时间序列的预测,并且取得了很好的拟合效果。
下面让我们来构建Transformer模型对我们的数据集进行训练并预测吧,模型以及训练过程参考https://github.com/thuml/Autoformer
为了与前面的LSTM模型作对比,此处的seq_len同样也是30,即根据当前时间点的前30个历史数据,来预测当前时间点的值。
训练后预测的结果如下:
| 预测训练集、验证集和测试集 | 预测未来一个月 |
|---|---|
 |  |
all: mse=5.828854147944343 mae=1.9098987558018363
valid: mse=5.237968544799083 mae=1.7916155497233073
test: mse=3.852115935158198 mae=1.4951607981035784
- 从结果上来看,综合来看,效果比
LSTM模型又要好一点点,测试集的mae达到了1.495,为目前最优,这其实在比赛中就相当于这样,valid是A榜,test是B榜,目前这个结果是B榜最好的。 - 且从未来一个月的预测中看出,并不是跟前面的几个模型一样一条直线,而是有了一点波动,这样其实是更加能够符合实际的。
三、不同数据集的评分情况

四、总结
- 上图是6个时间序列数据集分别在4个模型上的评分情况(基本没怎么调参,只是调到收敛)
- 单单看第一个数据集,也即本文的例子,从预测的结果上来看,模型越复杂效果越好,单单从test集的
mae即平均绝对误差来看,这四个模型其实相差是不大的,但是从6个数据集上来看,LightGBM几乎都是最好的,除了第一个数据集是Transformer之外,再者,LSTM的效果其实也还是可以的,仅次于LightGBM - 在预测验证集和测试集中,
ARIMA和LightGBM都是使用了one by one的策略的,即模型只预测训练数据的下一个日期的值,然后把下一个日期的实际值加入到训练集中,重新构造特征和训练模型,迭代地将验证集和测试集预测出来,而LSTM和Transformer是没有重新训练模型的,因为太耗时了 - 这可能也说明了为什么
ARIMA和LightGBM的效果几乎都好一点点,在一两个数据集中ARIMA要好于LSTM - 所以,我个人认为,单变量单步预测的话,
LightGBM这类模型能够one by one预测的能力是最好的,而深度学习模型就不太理想了(可能是我没有认真地调参,说不定调下参数会好很多),但可能在多步预测中,深度学习模型可能会是更好的选择,之后的文章我也会继续研究多步预测,大家期待一下~
五、参考链接
- 时间序列数据集
- ARIMA模型one by one预测
- LSTM模型
- Transformer模型
以上即为本文的全部内容,若需要全部源代码的,请关注公众号《Python王者之路》,回复关键词:20230501,即可获取。
写在最后
在没有动态的日子里,都有在好好生活呀~
在没有更新博客的日子里,都有在好好学习呀~
刚好今天是5月1日,那就祝大家五一劳动节快乐吧~