内核media驱动目录结构
目录media/driver,子目录说明如下,主要列举本文中使用到的目录
| 目录 | 功能 |
| I2C | 摄像头,解串器(max9296/9295等) |
| platform | 控制器的驱动,例如mipi控制等 |
| v4l2_core | ioctl 入口等 |
| media\common\videobuf2\ | 通用buffer分配及管理等 |
通过此目录结构,我们可以得知: 摄像头的控制路径很多是通过I2C通道。
用户态编程的几个关键IOCTL
VIDIOC_REQBUFS
功能: 向控制器驱动申请接收视频流的buffer个数。如下代码总共申请5个buffer,也就是最多缓存5帧数据。
req.count = 5;req.type = V4L2_BUF_TYPE_VIDEO_CAPTURE_MPLANE;req.memory = V4L2_MEMORY_MMAP;if (ioctl(fd, VIDIOC_REQBUFS, &req) < 0) {printf("Reqbufs fail\n");goto err1;}VIDIOC_QUERYBUF
功能: 获取驱动分配的buffer信息,以便用户态进行mmap映射
for(i = 0; i < req.count; i++) {memset(&buf, 0, sizeof(buf));planes_buffer = calloc(num_planes, sizeof(*planes_buffer));plane_start = calloc(num_planes, sizeof(*plane_start));memset(planes_buffer, 0, sizeof(*planes_buffer));buf.type = V4L2_BUF_TYPE_VIDEO_CAPTURE_MPLANE;buf.memory = V4L2_MEMORY_MMAP;buf.m.planes = planes_buffer;buf.length = num_planes;buf.index = i;if (-1 == ioctl (fd, VIDIOC_QUERYBUF, &buf)) {printf("Querybuf fail\n");req.count = i;goto err2;}VIDIOC_DQBUF
功能: 等待有视频数据的buf。可以是阻塞与非阻塞,后续在分析驱动时,着重介绍。
memset(&buf, 0, sizeof(buf));buf.type = V4L2_BUF_TYPE_VIDEO_CAPTURE_MPLANE;buf.memory = V4L2_MEMORY_MMAP;buf.m.planes = tmp_plane;buf.length = num_planes;if (ioctl (fd, VIDIOC_DQBUF, &buf) < 0)printf("dqbuf fail\n");VIDIOC_QBUF
功能:虽然如下两个功能最终操作一样,但应用的时间点不一样。
1) 在接收完数据后,用户态应用将buf还给驱动,进而驱动可以继续往buffer里面填数据
if (ioctl (fd, VIDIOC_QBUF, &buf) < 0)printf("failture VIDIOC_QBUF\n");2) 在初始化时,将申请到的buffer挂载到驱动的队列上
for (i = 0; i < req.count; ++i) {memset(&buf, 0, sizeof(buf));buf.type = V4L2_BUF_TYPE_VIDEO_CAPTURE_MPLANE;buf.memory = V4L2_MEMORY_MMAP;buf.length = num_planes;buf.index = i;buf.m.planes = (buffers + i)->planes_buffer;if (ioctl (fd, VIDIOC_QBUF, &buf) < 0)printf ("VIDIOC_QBUF failed\n");}对应代码入口
\kernel\drivers\media\v4l2-core\v4l2-ioctl.c
static const struct v4l2_ioctl_info v4l2_ioctls[] = {IOCTL_INFO(VIDIOC_QUERYCAP, v4l_querycap, v4l_print_querycap, 0),IOCTL_INFO(VIDIOC_ENUM_FMT, v4l_enum_fmt, v4l_print_fmtdesc, 0),IOCTL_INFO(VIDIOC_G_FMT, v4l_g_fmt, v4l_print_format, 0),IOCTL_INFO(VIDIOC_S_FMT, v4l_s_fmt, v4l_print_format, INFO_FL_PRIO),IOCTL_INFO(VIDIOC_REQBUFS, v4l_reqbufs, v4l_print_requestbuffers, INFO_FL_PRIO | INFO_FL_QUEUE),IOCTL_INFO(VIDIOC_QUERYBUF, v4l_querybuf, v4l_print_buffer, INFO_FL_QUEUE | INFO_FL_CLEAR(v4l2_buffer, length)),IOCTL_INFO(VIDIOC_G_FBUF, v4l_stub_g_fbuf, v4l_print_framebuffer, 0),IOCTL_INFO(VIDIOC_S_FBUF, v4l_stub_s_fbuf, v4l_print_framebuffer, INFO_FL_PRIO),IOCTL_INFO(VIDIOC_OVERLAY, v4l_overlay, v4l_print_u32, INFO_FL_PRIO),IOCTL_INFO(VIDIOC_QBUF, v4l_qbuf, v4l_print_buffer, INFO_FL_QUEUE),总体而言:由于dma操作对物理地址的要求,buffer的分配由内核驱动完成。进而映射到用户空间,用户空间仅仅负责将数据取出,buffer的管理都有内核统一完成。
因而在内核中抽象出对buffer的统一管理。
buffer的管理
首先,从用户态入手,了解几个关键的数据结构。
struct v4l2_requestbuffers
req.count = 5;req.type = V4L2_BUF_TYPE_VIDEO_CAPTURE_MPLANE;req.memory = V4L2_MEMORY_MMAP;count: 即申请5个buffer
type: MPLANE,V4L2_BUF_TYPE_VIDEO_CAPTURE 等,影响buffer的分布。
struct v4l2_buffer
for(i = 0; i < req.count; i++) {memset(&buf, 0, sizeof(buf));planes_buffer = calloc(num_planes, sizeof(*planes_buffer));plane_start = calloc(num_planes, sizeof(*plane_start));memset(planes_buffer, 0, sizeof(*planes_buffer));buf.type = V4L2_BUF_TYPE_VIDEO_CAPTURE_MPLANE;buf.memory = V4L2_MEMORY_MMAP;buf.m.planes = planes_buffer;buf.length = num_planes;buf.index = i;if (-1 == ioctl (fd, VIDIOC_QUERYBUF, &buf)) {printf("Querybuf fail\n");req.count = i;goto err2;}mplane之宏定义
在让驱动分配内存,已经应用向驱动获取内存信息时,都用到一个字段,即type:
此字段的取值包括:
\kernel\include\uapi\linux\videodev2.h
V4L2_BUF_TYPE_VIDEO_CAPTURE
V4L2_BUF_TYPE_VIDEO_CAPTURE_MPLANEconst char *v4l2_type_names[] = {[0] = "0",[V4L2_BUF_TYPE_VIDEO_CAPTURE] = "vid-cap",[V4L2_BUF_TYPE_VIDEO_OVERLAY] = "vid-overlay",[V4L2_BUF_TYPE_VIDEO_OUTPUT] = "vid-out",[V4L2_BUF_TYPE_VBI_CAPTURE] = "vbi-cap",[V4L2_BUF_TYPE_VBI_OUTPUT] = "vbi-out",[V4L2_BUF_TYPE_SLICED_VBI_CAPTURE] = "sliced-vbi-cap",[V4L2_BUF_TYPE_SLICED_VBI_OUTPUT] = "sliced-vbi-out",[V4L2_BUF_TYPE_VIDEO_OUTPUT_OVERLAY] = "vid-out-overlay",[V4L2_BUF_TYPE_VIDEO_CAPTURE_MPLANE] = "vid-cap-mplane",[V4L2_BUF_TYPE_VIDEO_OUTPUT_MPLANE] = "vid-out-mplane",[V4L2_BUF_TYPE_SDR_CAPTURE] = "sdr-cap",[V4L2_BUF_TYPE_SDR_OUTPUT] = "sdr-out",[V4L2_BUF_TYPE_META_CAPTURE] = "meta-cap",[V4L2_BUF_TYPE_META_OUTPUT] = "meta-out",
};此处我们关注两个video_capture
mplane之定义
1) 何为mplane?
所谓plane,即为一个分量所占的内存空间。mplane即多个plane表示一帧图像。如下图Y U V分布占用一个plane。
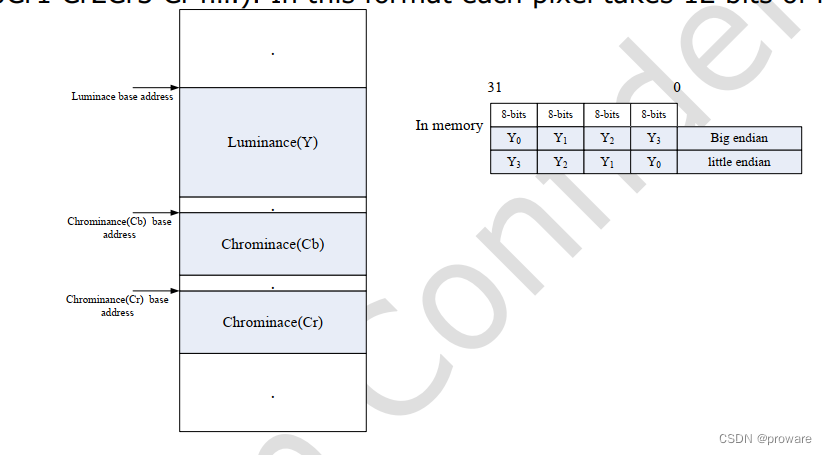
如下,Y与UV分别占用一个plane
常见的NV12 NV16等都属于此范畴。
2) 与之相对应的 Interleaved,即一块内存即为完整的一帧图像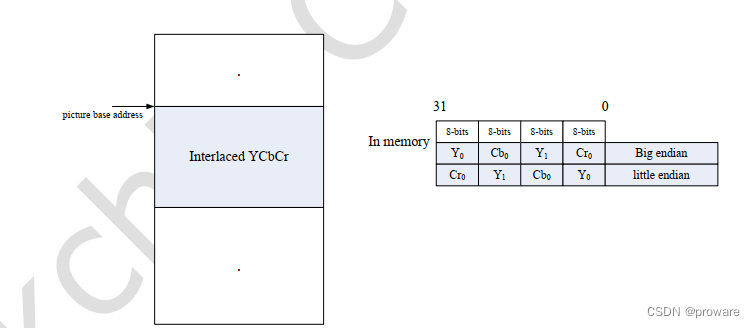
例如: YUYV ;YVYU等采用此方式。
了解了上述结构后,不同的存储形式对内存分配的要求不同。如果采用plane方式,则可能需要分配2-3块内存。而如果采用interlaced 方式,则只分配一块内存即可。
内存分配
内存分配入口
\kernel\drivers\media\v4l2-core\v4l2-ioctl.c
static int v4l_reqbufs(const struct v4l2_ioctl_ops *ops,struct file *file, void *fh, void *arg)
{struct v4l2_requestbuffers *p = arg;int ret = check_fmt(file, p->type);if (ret)return ret;CLEAR_AFTER_FIELD(p, capabilities);return ops->vidioc_reqbufs(file, fh, p);
}驱动层接口
kernel\drivers\media\platform\rockchip\cif\capture.c
驱动层最终调用了buff的通用管理接口
static const struct v4l2_ioctl_ops rkcif_v4l2_ioctl_ops = {.vidioc_reqbufs = vb2_ioctl_reqbufs,.vidioc_querybuf = vb2_ioctl_querybuf,.vidioc_create_bufs = vb2_ioctl_create_bufs,.vidioc_qbuf = vb2_ioctl_qbuf,.vidioc_expbuf = vb2_ioctl_expbuf,.vidioc_dqbuf = vb2_ioctl_dqbuf,.vidioc_prepare_buf = vb2_ioctl_prepare_buf,.vidioc_streamon = vb2_ioctl_streamon,.vidioc_streamoff = vb2_ioctl_streamoff,.vidioc_enum_input = rkcif_enum_input,.vidioc_try_fmt_vid_cap_mplane = rkcif_try_fmt_vid_cap_mplane,.vidioc_enum_fmt_vid_cap = rkcif_enum_fmt_vid_cap_mplane,.vidioc_s_fmt_vid_cap_mplane = rkcif_s_fmt_vid_cap_mplane,.vidioc_g_fmt_vid_cap_mplane = rkcif_g_fmt_vid_cap_mplane,.vidioc_querycap = rkcif_querycap,.vidioc_s_selection = rkcif_s_selection,.vidioc_g_selection = rkcif_g_selection,.vidioc_enum_frameintervals = rkcif_enum_frameintervals,.vidioc_enum_framesizes = rkcif_enum_framesizes,.vidioc_default = rkcif_ioctl_default,
};通用分配接口
两套入口
kernel\drivers\media\v4l2-core\videobuf-core.c
int videobuf_reqbufs(struct videobuf_queue *q,struct v4l2_requestbuffers *req)
{q->ops->buf_setup(q, &count, &size);.............retval = __videobuf_mmap_setup(q, count, size, req->memory);}第二套为我们所关心
\kernel\drivers\media\common\videobuf2\videobuf2-v4l2.c
首先 查询,然后分配
int vb2_ioctl_reqbufs(struct file *file, void *priv,struct v4l2_requestbuffers *p)
{int vb2_core_reqbufs(struct vb2_queue *q, enum vb2_memory memory,unsigned int *count)
{/** Ask the driver how many buffers and planes per buffer it requires.* Driver also sets the size and allocator context for each plane.* 获取驱动buffer的数目以及每个bufffer里面plane的数目*/ret = call_qop(q, queue_setup, q, &num_buffers, &num_planes,plane_sizes, q->alloc_devs);}驱动层提供plane信息
在通用buffer代码分配内存前,需要了解分配几个内存区域。而这由控制器驱动具体提供。
以 3588 为例:
static struct vb2_ops rkcif_vb2_ops = {.queue_setup = rkcif_queue_setup,.buf_queue = rkcif_buf_queue,.wait_prepare = vb2_ops_wait_prepare,.wait_finish = vb2_ops_wait_finish,.stop_streaming = rkcif_stop_streaming,.start_streaming = rkcif_start_streaming,
};q->ops = &rkcif_vb2_ops;//输出mplanes数目,而mplanes数目
static int rkcif_queue_setup(struct vb2_queue *queue,unsigned int *num_buffers,unsigned int *num_planes,unsigned int sizes[],struct device *alloc_ctxs[])
{struct rkcif_stream *stream = queue->drv_priv;struct rkcif_extend_info *extend_line = &stream->extend_line;struct rkcif_device *dev = stream->cifdev;const struct v4l2_pix_format_mplane *pixm = NULL;const struct cif_output_fmt *cif_fmt;const struct cif_input_fmt *in_fmt;bool is_extended = false;u32 i, height;pixm = &stream->pixm;cif_fmt = stream->cif_fmt_out;in_fmt = stream->cif_fmt_in;*num_planes = cif_fmt->mplanes;//具体说明根据类型不同而定,例如
static const struct cif_output_fmt out_fmts[] = {{.fourcc = V4L2_PIX_FMT_NV16,.cplanes = 2,.mplanes = 1,.fmt_val = YUV_OUTPUT_422 | UV_STORAGE_ORDER_UVUV,.bpp = { 8, 16 },.csi_fmt_val = CSI_WRDDR_TYPE_YUV422,.fmt_type = CIF_FMT_TYPE_YUV,},核心分配buffer接口
nel\drivers\media\common\videobuf2\videobuf2-core.c
/** __vb2_queue_alloc() - allocate videobuf buffer structures and (for MMAP type)* video buffer memory for all buffers/planes on the queue and initializes the* queue** Returns the number of buffers successfully allocated.*/
static int __vb2_queue_alloc(struct vb2_queue *q, enum vb2_memory memory,unsigned int num_buffers, unsigned int num_planes,const unsigned plane_sizes[VB2_MAX_PLANES])
{unsigned int buffer, plane;struct vb2_buffer *vb;int ret;/* Ensure that q->num_buffers+num_buffers is below VB2_MAX_FRAME */num_buffers = min_t(unsigned int, num_buffers,VB2_MAX_FRAME - q->num_buffers);for (buffer = 0; buffer < num_buffers; ++buffer) {/* Allocate videobuf buffer structures */vb = kzalloc(q->buf_struct_size, GFP_KERNEL);if (!vb) {dprintk(q, 1, "memory alloc for buffer struct failed\n");break;}vb->state = VB2_BUF_STATE_DEQUEUED;vb->vb2_queue = q;vb->num_planes = num_planes;vb->index = q->num_buffers + buffer;vb->type = q->type;vb->memory = memory;/** We need to set these flags here so that the videobuf2 core* will call ->prepare()/->finish() cache sync/flush on vb2* buffers when appropriate. However, we can avoid explicit* ->prepare() and ->finish() cache sync for DMABUF buffers,* because DMA exporter takes care of it.*/if (q->memory != VB2_MEMORY_DMABUF) {vb->need_cache_sync_on_prepare = 1;vb->need_cache_sync_on_finish = 1;}for (plane = 0; plane < num_planes; ++plane) {vb->planes[plane].length = plane_sizes[plane];vb->planes[plane].min_length = plane_sizes[plane];}call_void_bufop(q, init_buffer, vb);q->bufs[vb->index] = vb;/* Allocate video buffer memory for the MMAP type */// 这里即采用我们的分配接口if (memory == VB2_MEMORY_MMAP) {ret = __vb2_buf_mem_alloc(vb);if (ret) {dprintk(q, 1, "failed allocating memory for buffer %d\n",buffer);q->bufs[vb->index] = NULL;kfree(vb);break;}__setup_offsets(vb);/** Call the driver-provided buffer initialization* callback, if given. An error in initialization* results in queue setup failure.*/ret = call_vb_qop(vb, buf_init, vb);if (ret) {dprintk(q, 1, "buffer %d %p initialization failed\n",buffer, vb);__vb2_buf_mem_free(vb);q->bufs[vb->index] = NULL;kfree(vb);break;}}}dprintk(q, 3, "allocated %d buffers, %d plane(s) each\n",buffer, num_planes);return buffer;
}
/** __vb2_buf_mem_alloc() - allocate video memory for the given buffer*/
static int __vb2_buf_mem_alloc(struct vb2_buffer *vb)
{struct vb2_queue *q = vb->vb2_queue;void *mem_priv;int plane;int ret = -ENOMEM;/** Allocate memory for all planes in this buffer* NOTE: mmapped areas should be page aligned*/for (plane = 0; plane < vb->num_planes; ++plane) {/* Memops alloc requires size to be page aligned. */unsigned long size = PAGE_ALIGN(vb->planes[plane].length);/* Did it wrap around? */if (size < vb->planes[plane].length)goto free;// 此处调用实际的内存分配接口mem_priv = call_ptr_memop(vb, alloc,q->alloc_devs[plane] ? : q->dev,q->dma_attrs, size, q->dma_dir, q->gfp_flags);if (IS_ERR_OR_NULL(mem_priv)) {if (mem_priv)ret = PTR_ERR(mem_priv);goto free;}/* Associate allocator private data with this plane */vb->planes[plane].mem_priv = mem_priv;}return 0;
free:/* Free already allocated memory if one of the allocations failed */for (; plane > 0; --plane) {call_void_memop(vb, put, vb->planes[plane - 1].mem_priv);vb->planes[plane - 1].mem_priv = NULL;}return ret;
}
驱动提供的内存分配接口
kernel\drivers\media\platform\rockchip\cif\capture.c
\kernel\drivers\media\platform\rockchip\cif\hw.c
static int rkcif_init_vb2_queue(struct vb2_queue *q,struct rkcif_stream *stream,enum v4l2_buf_type buf_type)
{struct rkcif_hw *hw_dev = stream->cifdev->hw_dev;q->type = buf_type;q->io_modes = VB2_MMAP | VB2_DMABUF;q->drv_priv = stream;q->ops = &rkcif_vb2_ops;q->mem_ops = hw_dev->mem_ops;//驱动探测时,赋值mem_ops
static int rkcif_plat_hw_probe(struct platform_device *pdev)
{struct rkcif_hw *cif_hw;cif_hw->mem_ops = &vb2_cma_sg_memops;............................
}
真正内存分配接口
\kernel\drivers\media\common\videobuf2\videobuf2-cma-sg.c
const struct vb2_mem_ops vb2_cma_sg_memops = {.alloc = vb2_cma_sg_alloc,.put = vb2_cma_sg_put,.get_userptr = vb2_cma_sg_get_userptr,.put_userptr = vb2_cma_sg_put_userptr,.prepare = vb2_cma_sg_prepare,.finish = vb2_cma_sg_finish,.vaddr = vb2_cma_sg_vaddr,.mmap = vb2_cma_sg_mmap,.num_users = vb2_cma_sg_num_users,.get_dmabuf = vb2_cma_sg_get_dmabuf,.map_dmabuf = vb2_cma_sg_map_dmabuf,.unmap_dmabuf = vb2_cma_sg_unmap_dmabuf,.attach_dmabuf = vb2_cma_sg_attach_dmabuf,.detach_dmabuf = vb2_cma_sg_detach_dmabuf,.cookie = vb2_cma_sg_cookie,
};接口流程综述
经过了core与具体设备的交替,其中驱动向core层注册的接口包括:
1) 采用的buffer分配入口注册
2) buffer信息的注册。例如控制器的plane信息等
3) 实际的分配内存接口注册。

mmap映射
针对RK的芯片,其存在mplane与cplane,两者之间的关系是怎么样的?这里查询到的plane_num是多少?
for(i = 0; i < req.count; i++) {memset(&buf, 0, sizeof(buf));planes_buffer = calloc(num_planes, sizeof(*planes_buffer));plane_start = calloc(num_planes, sizeof(*plane_start));memset(planes_buffer, 0, sizeof(*planes_buffer));buf.type = V4L2_BUF_TYPE_VIDEO_CAPTURE_MPLANE;buf.memory = V4L2_MEMORY_MMAP;buf.m.planes = planes_buffer; //记录每个plane的长度,偏移量信息buf.length = num_planes;buf.index = i;if (-1 == ioctl (fd, VIDIOC_QUERYBUF, &buf)) {printf("Querybuf fail\n");req.count = i;goto err2;}(buffers + i)->planes_buffer = planes_buffer;(buffers + i)->plane_start = plane_start;for(j = 0; j < num_planes; j++) { //针对每个plane映射printf("plane[%d]: length = %d\n", j, (planes_buffer + j)->length);printf("plane[%d]: offset = %d\n", j, (planes_buffer + j)->m.mem_offset);(plane_start + j)->start = mmap (NULL /* start anywhere */,(planes_buffer + j)->length,PROT_READ | PROT_WRITE /* required */,MAP_SHARED /* recommended */,fd,(planes_buffer + j)->m.mem_offset);if (MAP_FAILED == (plane_start +j)->start) {printf ("mmap failed\n");req.count = i;goto unmmap;}}sun4i-csi驱动
在 明了内存分配后,通过一个驱动示例,了解其接收数据的流程。
问题: 数据到来后,通过中断通知,用户通过ioctl dqbuf接口调用时,是否一直阻塞中?
该驱动结构及流程相对简单,但采用了V4L2的主要接口,利于分析。涉及到的文件
media\platform\sunxi\sun4i-csi
中断入口
请思考,此处csi->qlock保护的是什么?
static irqreturn_t sun4i_csi_irq(int irq, void *data)
{struct sun4i_csi *csi = data;u32 reg;reg = readl(csi->regs + CSI_INT_STA_REG);/* Acknowledge the interrupts */writel(reg, csi->regs + CSI_INT_STA_REG);if (!(reg & CSI_INT_FRM_DONE))return IRQ_HANDLED;spin_lock(&csi->qlock); //这里加锁的目的是什么?保护什么?if (sun4i_csi_buffer_flip(csi, csi->sequence++)) {dev_warn(csi->dev, "%s: Flip failed\n", __func__);sun4i_csi_capture_stop(csi);}spin_unlock(&csi->qlock);return IRQ_HANDLED;
}static int sun4i_csi_buffer_flip(struct sun4i_csi *csi, unsigned int sequence)
{u32 reg = readl(csi->regs + CSI_BUF_CTRL_REG);unsigned int next;/* Our next buffer is not the current buffer */next = !(reg & CSI_BUF_CTRL_DBS);/* Report the previous buffer as done *///此处调用V4L2的接口,将带有视频帧的buffer通知用户sun4i_csi_buffer_mark_done(csi, next, sequence);//然后将新的buffer的地址 填写到CSI控制器中,这样控制器就可以采用新的内存/* Put a new buffer in there */return sun4i_csi_buffer_fill_slot(csi, next);
}buffer done
此接口主要完成两个事情:
1) 将buffer添加到 done_list 队列
2) 唤醒等候在此工作队列的进程
void vb2_buffer_done(struct vb2_buffer *vb, enum vb2_buffer_state state)
{struct vb2_queue *q = vb->vb2_queue;/* Add the buffer to the done buffers list */spin_lock_irqsave(&q->done_lock, flags); //锁控制对done链表list_add_tail(&vb->done_entry, &q->done_list);spin_unlock_irqrestore(&q->done_lock, flags);wake_up(&q->done_wq);
}buffer 的申请
在一次buffer提交用户后,需要从驱动里面再申请一个buffer填写到控制器的相关寄存器。
static int sun4i_csi_buffer_fill_slot(struct sun4i_csi *csi, unsigned int slot)
{struct sun4i_csi_buffer *c_buf;struct vb2_v4l2_buffer *v_buf;unsigned int plane;/** We should never end up in a situation where we overwrite an* already filled slot.*/if (WARN_ON(csi->current_buf[slot]))return -EINVAL;//如下buffer list即为中断的锁所保护的对象。也就是锁加在此处即可。if (list_empty(&csi->buf_list))return sun4i_csi_setup_scratch_buffer(csi, slot);c_buf = list_first_entry(&csi->buf_list, struct sun4i_csi_buffer, list);list_del_init(&c_buf->list);v_buf = &c_buf->vb;csi->current_buf[slot] = v_buf;for (plane = 0; plane < csi->fmt.num_planes; plane++) {dma_addr_t buf_addr;buf_addr = vb2_dma_contig_plane_dma_addr(&v_buf->vb2_buf,plane);writel(buf_addr, csi->regs + CSI_BUF_ADDR_REG(plane, slot));}return 0;
}
dqbuf的实现
流程走到此处已经需要查看被阻塞进程对收到的buffer的处理了。
根据上一章 《内存分配》的代码流程,很容易得知dqbuf的代码实现。
\kernel\drivers\media\common\videobuf2\videobuf2-v4l2.c
int vb2_core_dqbuf(struct vb2_queue *q, unsigned int *pindex, void *pb,bool nonblocking)
{struct vb2_buffer *vb = NULL;int ret;ret = __vb2_get_done_vb(q, &vb, pb, nonblocking);。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。call_void_vb_qop(vb, buf_finish, vb);}/** __vb2_get_done_vb() - get a buffer ready for dequeuing** Will sleep if required for nonblocking == false.*/
static int __vb2_get_done_vb(struct vb2_queue *q, struct vb2_buffer **vb,void *pb, int nonblocking)
{unsigned long flags;int ret = 0;/** Wait for at least one buffer to become available on the done_list.*/// 这个接口中的函数与中断处理中的wake up工作队列相对应,注意有nonblocking参数,// 也就是说支持nonblocking的操作ret = __vb2_wait_for_done_vb(q, nonblocking);if (ret)return ret;/** Driver's lock has been held since we last verified that done_list* is not empty, so no need for another list_empty(done_list) check.*/spin_lock_irqsave(&q->done_lock, flags); //这里再次对done_lock进行了操作,此处即//和 中断处理中,buffer的添加对应了。这里为删除。*vb = list_first_entry(&q->done_list, struct vb2_buffer, done_entry);/** Only remove the buffer from done_list if all planes can be* handled. Some cases such as V4L2 file I/O and DVB have pb* == NULL; skip the check then as there's nothing to verify.*/if (pb)ret = call_bufop(q, verify_planes_array, *vb, pb);if (!ret)list_del(&(*vb)->done_entry);spin_unlock_irqrestore(&q->done_lock, flags);return ret;
}//等待done_list 非空/** __vb2_wait_for_done_vb() - wait for a buffer to become available* for dequeuing** Will sleep if required for nonblocking == false.*/
static int __vb2_wait_for_done_vb(struct vb2_queue *q, int nonblocking)
{/** All operations on vb_done_list are performed under done_lock* spinlock protection. However, buffers may be removed from* it and returned to userspace only while holding both driver's* lock and the done_lock spinlock. Thus we can be sure that as* long as we hold the driver's lock, the list will remain not* empty if list_empty() check succeeds.*/for (;;) { //死循环int ret;if (q->waiting_in_dqbuf) {dprintk(q, 1, "another dup()ped fd is waiting for a buffer\n");return -EBUSY;}if (!q->streaming) {dprintk(q, 1, "streaming off, will not wait for buffers\n");return -EINVAL;}if (q->error) {dprintk(q, 1, "Queue in error state, will not wait for buffers\n");return -EIO;}if (q->last_buffer_dequeued) {dprintk(q, 3, "last buffer dequeued already, will not wait for buffers\n");return -EPIPE;}if (!list_empty(&q->done_list)) { /** Found a buffer that we were waiting for.*/break;}if (nonblocking) {dprintk(q, 3, "nonblocking and no buffers to dequeue, will not wait\n");return -EAGAIN;}q->waiting_in_dqbuf = 1;/** We are streaming and blocking, wait for another buffer to* become ready or for streamoff. Driver's lock is released to* allow streamoff or qbuf to be called while waiting.*/call_void_qop(q, wait_prepare, q); //休眠前释放锁vb2_queue->lock//为了保证qbuf接口和stream off接口被调用/** All locks have been released, it is safe to sleep now.*/dprintk(q, 3, "will sleep waiting for buffers\n");//将休眠在done_wq的队列上,和中断相对应ret = wait_event_interruptible(q->done_wq,!list_empty(&q->done_list) || !q->streaming ||q->error);/** We need to reevaluate both conditions again after reacquiring* the locks or return an error if one occurred.*/call_void_qop(q, wait_finish, q);q->waiting_in_dqbuf = 0;if (ret) {dprintk(q, 1, "sleep was interrupted\n");return ret;}}return 0;
}
至此,带有一帧图像的buffer 被传递到用户APP中。
qbuf的实现
int vb2_core_qbuf(struct vb2_queue *q, unsigned int index, void *pb,struct media_request *req)
{/** Add to the queued buffers list, a buffer will stay on it until* dequeued in dqbuf.*/注意: 这里对queued_list的操作没有锁。那么buffer从list里面删除的时候和这个add的过程不冲突,这个过程又在哪里呢?orig_state = vb->state;list_add_tail(&vb->queued_entry, &q->queued_list);q->queued_count++;q->waiting_for_buffers = false;vb->state = VB2_BUF_STATE_QUEUED;/** If already streaming, give the buffer to driver for processing.* If not, the buffer will be given to driver on next streamon.*/这里将buffer 由具体的驱动管理。为何?if (q->start_streaming_called)__enqueue_in_driver(vb);}控制器驱动回收buffer
static void sun4i_csi_buffer_queue(struct vb2_buffer *vb)
{struct sun4i_csi *csi = vb2_get_drv_priv(vb->vb2_queue);struct sun4i_csi_buffer *buf = vb2_to_csi_buffer(vb);unsigned long flags;//此处由用户空间操作,进行buffer归还驱动,相关链表加锁spin_lock_irqsave(&csi->qlock, flags); list_add_tail(&buf->list, &csi->buf_list);spin_unlock_irqrestore(&csi->qlock, flags);
}至此,完成了视频数据接收过程。
总结
整个视频流接收过程中,涉及到buffer的管理,都是从具体驱动进行分配而来的。
1) 从驱动获得buffer,填写到控制器中,并将其从空闲list删除;
2) 收到数据后,此buffer被添加到 buffer done list。
3) 视频数据由用户处理完毕后,再添加到空闲list。
其中在空闲buffer的获取和放回时,都涉及到具体的控制器驱动,控制器驱动要实现buf_queue,由qbuf ioctl系统调用。而done buffer的管理则由v4l2 core部分就可以完成。
相应的增加两个锁。
后续部分:
camera驱动与platform驱动
camera驱动与platform调用及加载关系。