Zilliz Cloud 正式上线 Pipelines!
Zilliz Cloud Pipelines 可以将文档、文本片段和图像等非结构化数据转换成可搜索的向量并存储在 Collection 中,帮助开发者简化工程开发,助力其实现多种场景的 RAG 应用,将复杂生产系统的搭建和维护简化成 API 调用。
01.我们为什么需要 Zilliz Cloud Pipelines?
基于语义的信息检索系统被广泛地运用在众多应用和互联网服务中,从我们熟知的网页搜索、电商图片搜索到最近非常流行的检索增强生成 (RAG) 应用。最新的检索系统通常采用深度学习模型将文本、图像等非结构化数据提取特征,转换成高维向量。这个过程业界称为“Embedding”。提取出来的向量需要用如 Zilliz Cloud 和 Milvus 这样的专用向量数据库进行存储和检索。随着深度学习的发展,采用向量进行检索的方式在近年来越来越普遍。
然而,构建上述检索系统需要深厚的专业知识和工程经验。很多开发者朋友想尝试向量检索但却苦于必须搭建复杂的数据处理和模型推理系统才能实现 Embedding。现在,利用 Zilliz Cloud Pipelines 可以方便有效地解决这一问题!Zilliz Cloud Pipelines 提供了简单易用的 API,可以将文档、文本片段和图像等非结构化数据转换成可搜索的向量并存储在 Collection 中。
选择 Zilliz Cloud Pipelines 的理由:
-
简化开发流程,开发者无需搭建复杂系统即可将非结构化数据转换为可搜索的向量,并在向量数据库进行数据检索。
-
即使不具备专业的深度学习和检索系统经验,也可以有效地生成高质量的 Embedding 满足业务上的检索需求。
-
无需担心扩展性,即便数据量和查询频次提高几个数量级,系统也能轻松应对。
目前,我们发布的公开预览版 Zilliz Cloud Pipelines 支持对文档进行语义搜索。后续我们将推出更多类型的 Pipelines,以满足更多样化的信息检索场景,例如更灵活的数据预处理,图片和视频搜索,多模态搜索等。
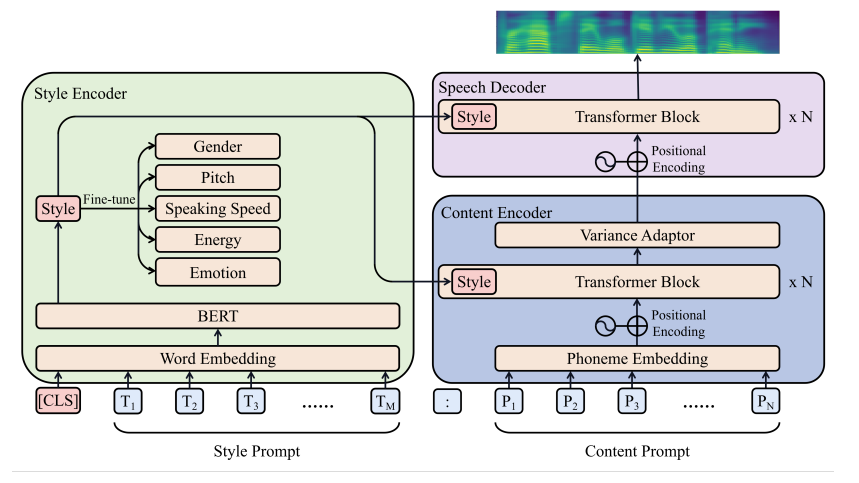
02.Zilliz Cloud Pipelines 的工作原理
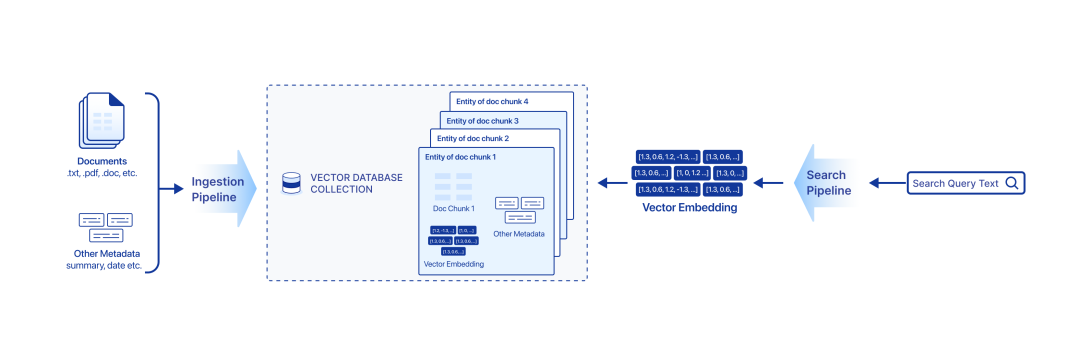
Zilliz Cloud Pipelines 由 Ingestion pipeline、Search pipeline、Deletion pipeline 三种类型构成:
Ingestion Pipeline
Ingestion pipeline 能够将非结构化数据转化为可搜索的向量,并将向量导入 Zilliz Cloud 向量数据库中,用作之后的查询。
1 个 Ingestion pipeline 中可配置多个 function,用于将输入字段通过转换逻辑,生成输出字段。例如,我们可以将文档作为输入,function 会将这些文档自动切分并转换为向量,同时 function 也可以保留用户赋予文档的一些额外信息,以便后续进行向量搜索时过滤搜索结果。
在 Zilliz Cloud 中,1 个 Ingestion pipeline 对应 1 个 Collection。当创建 Ingestion pipeline 时,Zilliz Cloud 会自动创建 1 个对应的 Collection,并根据配置自动为新建的 Collection 指定数据格式 (Schema)。
INDEX_DOC Function
INDEX_DOC function 将输入文本文档拆分成片段,并将每一个片段转换为向量。它将输入字段(doc_name)映射为四个输出字段(doc_name、chunk_id、chunk_text 和 embedding)。这四个字段构成新建 Collection 中的标量和向量字段,字段名称不可更改。
注意,1 个 Ingestion pipeline 需要添加且只能添加 1 个 INDEX_DOC function。
PRESERVE Function
PRESERVE function 将用户定义的输入字段存储为新建 Collection 中额外的标量字段,用于存储一些额外信息来描述一个文档的特征。该信息会保存在每一个文档片段的条目中。一个 PRESERVE function 仅保存一个标量字段,一个 Ingestion pipeline 中最多可添加 5 个 PRESERVE function。
示例:创建知识库
借助 Ingestion pipeline,我们可以基于已有的文档和相关数据(如文档作者、发布日期等)轻松构建支持语义检索的知识库。文档片段的原文及其向量和文档的额外信息都存储于向量数据库中。

Search Pipeline
Search pipeline 将查询文本(字符串)转换为向量,并在向量数据库中进行向量相似性搜索,从而获取 Top-k 相似向量、对应的片段原文和文档的额外信息。我们可以用 Search pipeline 实现语义检索,1 个 Search pipeline 中仅可添加 SEARCH_DOC_CHUNK 1 种 function。
SEARCH_DOC_CHUNK Function
SEARCH_DOC_CHUNK function 将查询文本转换为向量,并在向量数据库中检索与查询向量最相关的 k 个文档片段。
示例:基于语义的检索
如果用户已经创建了 1 个 Ingestion Pipeline,可以在其对应的 Collection 中使用 Search pipeline 检索相似文本片段向量,Embedding 模型的特性保证了他们是知识库中与查询文本语义最相似的片段。

Deletion Pipeline
Deletion pipeline 从 Collection 中删除指定文档的所有片段。1 个 Deletion pipeline 中仅可添加 PURGE_DOC_INDEX 1 种 function。
PURGE_DOC_INDEX Function
PURGE_DOC_INDEX function 删除具有指定 `doc_name 的所有文档片段。用户可以用 PURGE_DOC_INDEX function 从向量数据库中高效删除文档。
示例:高效删除文档数据
如果你已经创建了 1 个 Ingestion Pipeline,可以在其对应的 Collection 中使用 Deletion pipeline 指定 doc_name`轻松删除对应文档,无需对每个片段单独执行删除操作。

点击链接可在文章中查看 Zilliz Pipelines demo
03.总结
作为一个专为开发者设计的平台,Zilliz Cloud Pipelines 为 AI 应用开发带来了更多的可能性:
-
通过补充领域特定或私有知识,将用户提问转化为向量匹配知识库中的向量,补充高度相关的知识,提高了大规模语言模型(LLM)在 RAG 应用中的准确性,有效解决 LLM 过度依赖潜在过时数据的问题。通过将用户提问转化为向量匹配知识库中的向量,尤其是在聊天机器人和内容生成系统等应用中,能提高其准确性和相关性。
-
提升基于关键字检索的应用的召回能力。关键字检索经常存在无法有效感知语义近似的问题。许多传统应用,例如独立网站的页面搜索是基于关键字检索构建的,改用 Embedding 和向量召回能够大大增加命中关键信息的概率,提升搜索质量。
目前,开发者可以通过在 Zilliz Cloud 中创建 Serverless Cluster 来免费使用这一功能,下一步该功能将陆续覆盖标准版和企业版 Cluster。未来,我们也会持续提升 Zilliz Cloud Pipelines 的定制化功能,拓展到图像和视频等模态的检索场景。欢迎大家试用!
i
本文由 mdnice 多平台发布