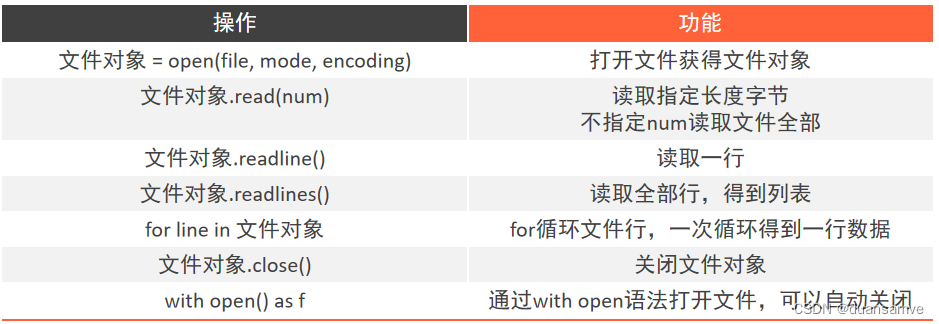
批量筛选docx文档中关键词
文章目录
- 批量筛选docx文档中关键词
- 前言
- 一、做成什么样子
- 二、基本架构
- 三、前期输入模块
- 1.引入库
- 2.路径输入
- 3.关键词输入
- 三、数据处理模块
- 1.基本架构
- 2.如果是docx文档
- 2.1.读取当前文档内容
- 2.2.遍历匹配关键字
- 2.3.触发匹配并记录日志
- 3.如果目录下还有一个目录
- 3.1.判断并生成新目录
- 3.2.获取子目录里的东西并遍历它
- 3.3.接着判断如果是docx文档
- 3.4.遍历匹配关键字
- 3.5.触发匹配并记录日志
- 总结
前言
在工作中经常会遇到,需要检查文档千万不能出现某个关键词,一个文档那还好说。但如果有成千上百个需要检查呢?
下面来给大家介绍一个批量检查的教程。

一、做成什么样子
- 支持当前目录下所有docx文档内容的检查。
- 支持当前目录下的子目录里面所有的docx文档内容的检查。
- 当前目录出现的问题会在当前目录生成日志文件记录下来。
- 日志格式为:<<文件绝对路径>> 文档中出现了关键词:《关键词》。
- 支持批量输入关键词,所有关键词都会进行逐一对比。
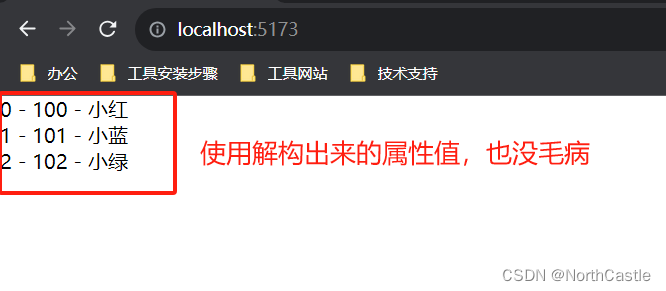
下面给大家展示一下效果图。

二、基本架构
主要包括以下几部分:
- 库输入模块
- 路径输入模块
- 关键词输入模块
- 数据处理模块
三、前期输入模块
库、路径、关键词比较简单。我就把它们全部写到这一节。
1.引入库
代码如下:
import docx
import os
import re
docx:用来读取文档内容的。
os:用来搞定一系列路径问题。
re:正则表达式模块,用来给关键词搞精确匹配的。
2.路径输入
代码如下:
print(r'请输入文档完整路径(例子:E:\vtest):', end='')
file_path = input()# 获取目录下的所有条目
entries = os.listdir(file_path)
print(entries)
输入路径后,程序会先获取一下当前路径下的东西,形成一个列表并打印出来。
3.关键词输入
代码如下:
# 获取关键词列表
Prohibited_lists = []
while True:print('请输入要查询的关键字(例子:奥利给),按q退出输入:', end='')Prohibited_words = input()if Prohibited_words == 'q':breakProhibited_lists.append(Prohibited_words)print("退出循环,禁止词汇列表:", Prohibited_lists)
首先,创建一个空列表,用来存储用户输入的关键词。
其次,一个while循环,用来保持用户可以一直输入关键词。
然后,关键词触发,当用户输入q可以退出输入关键程序。
最后,打印一条信息,告诉用户都有哪些关键词会进行匹配。
三、数据处理模块
这里我先写一下处理逻辑。
1.基本架构
代码如下:
for entry in entries:if entry.endswith('.docx'): # 如果是docx文档........... elif os.path.isdir(os.path.join(file_path, entry)): # 如果目录里的东西还是个目录...........首先,搞个循环结构,遍历一下用户输入的路径下的东西。
其次,对这些东西进行判断,进行两中不同的操作。
下面我将会按照这个结构顺序来写。
2.如果是docx文档
2.1.读取当前文档内容
代码如下:
for entry in entries:if entry.endswith('.docx'): # 如果是docx文档# 使用os.path.join()构造完整文件路径full_entry_path = os.path.join(file_path, entry)# 使用 python-docx 打开文档doc = docx.Document(full_entry_path)# 将每一个段落的文本合并为一个字符串text = " ".join([para.text for para in doc.paragraphs])首先,根据当前遍历的文件和用户输入的路径来共同构成完整文件路径。
其次,根据完整文件路径,读取文件内容。
最后,将每一个段落的文本合并为一个字符串,便于后面的关键字匹配。
2.2.遍历匹配关键字
代码如下:
# 遍历关键字列表for Prohibited_list in Prohibited_lists:# 正则表达式匹配关键字ProhibitedRegex = re.compile(rf'.*{Prohibited_list}+.*')mo = ProhibitedRegex.search(text)
这里我们用的是正则表达式匹配关键字。看不懂的同学要去看下正则表达式的知识点喽。
ProhibitedRegex = re.compile(rf’.{Prohibited_list}+.') 这行代码创建了一个正则表达式对象,用于查找包含在 Prohibited_list 关键词。
mo = ProhibitedRegex.search(text) 这行代码使用了上面创建的正则表达式对象来搜索 text 中是否存在匹配的禁止词汇。如果找到匹配项,则返回一个匹配对象(MatchObject),否则返回 None。
2.3.触发匹配并记录日志
代码如下:
# 如果匹配到了关键字if mo is not None:# 使用os.path.join()构造完整文件路径full_text_path = os.path.join(file_path, 'problems.txt')# 将问题写入text文档,并保存到当前目录with open(full_text_path, 'a') as f:f.write(f'<<{full_entry_path}>> 文档中出现了关键词:{Prohibited_list}\n')# 如果没有匹配到关键字else:print(f'<<{full_entry_path}>> 文档没有出现关键词:{Prohibited_list}。')
一目了然,共分成两部分:一是匹配到了关键字;二是没有匹配到关键字。
匹配到了:第一步先构建日志文件的路径;第二步将问题写入到text文档,并保存到当前目录(如果当前目录没有该文件,会自动创建。)
没匹配到:就简单提示一下啦。
3.如果目录下还有一个目录
3.1.判断并生成新目录
代码如下:
# 判断目录下是否还有目录elif os.path.isdir(os.path.join(file_path, entry)):# 使用字符串拼接一下路径,生成新路径(给子目录下的文档使用)file_path = file_path + '\\' + entry
一般我们保存文件不会一股脑的都保存到一个目录中。最起码目录中再搞一个子目录分一下类。
这个代码就是处理这个问题的。
3.2.获取子目录里的东西并遍历它
代码如下:
# 获取目录下的所有条目entries = os.listdir(file_path)print(entries)# 遍历当前所有条目for entry_1 in entries:
接下来就是获取一下子录下的所有东西啦。
然后再搞一个遍历结构,一个一个的处理它们。
3.3.接着判断如果是docx文档
代码如下:
if entry_1.endswith('.docx'):# 使用os.path.join()构造完整文件路径full_entry_path = os.path.join(file_path, entry_1)# 使用 python-docx 打开文档doc = docx.Document(full_entry_path)# 将每一个段落的文本合并为一个字符串text = " ".join([para.text for para in doc.paragraphs])
请参考 《2.1.读取当前文档内容》
3.4.遍历匹配关键字
代码如下:
# 正则表达式匹配关键字for Prohibited_list in Prohibited_lists:ProhibitedRegex = re.compile(rf'.*{Prohibited_list}+.*')mo = ProhibitedRegex.search(text)
请参考 《2.2.遍历匹配关键字》
3.5.触发匹配并记录日志
代码如下:
if mo is not None:# 使用os.path.join()构造完整文件路径full_text_path = os.path.join(file_path, 'problems.txt')# 将问题写入text文档,并保存到当前目录with open(full_text_path, 'a') as f:f.write(f'<<{full_entry_path}>> 文档中出现了关键词:{Prohibited_list}\n')else:print(f'<<{full_entry_path}>> 文档没有出现关键词:{Prohibited_list}。')
请参考 《2.3.触发匹配并记录日志》
总结
以上的代码,包括我之前写的所有代码,都是在Python 3.11版本下写的,其它版本下运行可能会有问题。并且以上代码可以直接按顺序复制粘贴就可以使用,不用再调格式(可以发现越往后代码前面的空格越多,这个就是格式)。用起来有问题可以私信或者评论给我哦。