文件读写
- 文件读写
- 一、普通文件读写
- 1.1 读取
- 1.1.1 读取文件的操作流程
- 1.1.2 打开文件语法
- 1.1.3 正反斜杠
- 1.1.4 代码演示
- 1.2 写入
- 1.2.1 读取文件的操作流程
- 1.2.3 代码演示
- 二、with上下文
- 2.1 语法
- 2.2 说明
- 2.3 代码演示
- 三、二进制文件读写
- 四、CSV文件读写
- 4.1 csv文件
- 4.2 读取
- 4.3 写入
- 五、对象的序列化和反序列化
- 5.1 pickle模块
- 5.2 json模块
- 5.2.1 JSON
- 5.2.2 JSON和Python中数据类型的对应关系
- 5.2.3 代码演示
文件读写
常见文件的读写分类:
- 普通文本文件:
txt、py、md、html等 - csv文件:
.csv,需要借助于系统模块csv - 二进制文件:图片,音频,视频,压缩包等
- 对象的序列化和反序列化:
pickle和json - 办公文件:
excel,word,需要借助于第三方模块
一、普通文件读写
1.1 读取
1.1.1 读取文件的操作流程
-
打开文件:
f = open(file,mode,encoding)- 传递需要读取的文件的路径:相对路径/绝对路径
- 选择打开文件的模式
- 传递需要书写读取文件的编码格式,注意使用关键字参数
f = open(),f表示被打开的文件对象,后续操作都需要通过f完成
-
读取内容:
read()/readline()/readlines()read():一次全部读取完毕,适用于数据量少的文件readline():一次只能读取一行readlines():一次性全部读完,同样适用于数据量少的情况的,但是返回列表,每一行内容是列表中的元素,使用较多
-
关闭文件:
close()- 关闭文件,为了节约内存空间
1.1.2 打开文件语法
open(file,mode,encoding)
-
说明:
-
file:需要打开的文件名称或文件的路径- 文件名称:需要打开的文件和当前py文件在同一个目录下,不常用
- 文件路径:需要打开的文件和当前py文件不在同一个目录下,可以使用相对路径或绝对路径
- 相对路径:相对当前工程的路径,如:
aaa/file1.txt,推荐 - 绝对路径:从系统盘符开始的路径,如:
c:/users/xxxx/Desktop/Coding5/Day21Code/aaa/file1.txt
-
mode:打开文件的模式模式 说明 'r'open for reading (default) 普通文件的读取 'w'open for writing, truncating the file first 普通文件的写入(删除原文件,生成一个空的新的文件) 'a'open for writing, appending to the end of the file if it exists 普通文件的写入(追加,在原文件内容后添加) 'rb'打开二进制文件用于读取 'wb'打开二进制文件用于写入 -
encoding:- 常用的编码格式:
utf-8、gbk
- 常用的编码格式:
-
1.1.3 正反斜杠
在Python中,文件路径可以使用正斜杠(/)或反斜杠(\)来表示。这两种方式在大多数情况下都是等效的,但是在某些特定情况下可能会有一些差异。
在Windows操作系统中,反斜杠(\)被用作路径分隔符。因此,如果你在Windows上编写Python代码,通常会使用反斜杠来表示文件路径,例如:
path = 'C:\\Users\\Username\\Documents\\file.txt'
然而,Python也支持使用正斜杠(/)来表示文件路径,即使在Windows上也是如此。这是因为Python解释器会自动将正斜杠转换为适当的路径分隔符。因此,你也可以这样写:
path = 'C:/Users/Username/Documents/file.txt'
在其他操作系统(如Linux和macOS)中,正斜杠(/)被用作路径分隔符。因此,在这些系统上,使用正斜杠表示文件路径是常见的做法。
总而言之,Python中使用正斜杠或反斜杠来表示文件路径都是可以的。选择哪种方式主要取决于你所使用的操作系统和个人偏好。如果你的代码需要在不同操作系统上运行,可以考虑使用os.path模块提供的函数来处理文件路径,这样可以确保代码在不同平台上都能正常工作。
1.1.4 代码演示
以访问
txt文件为例
-
打开文件:
open()- 采用绝对路径访问
- 注:因为路径表达含有反斜杠
\,所以使用r使转义失效
- 注:因为路径表达含有反斜杠
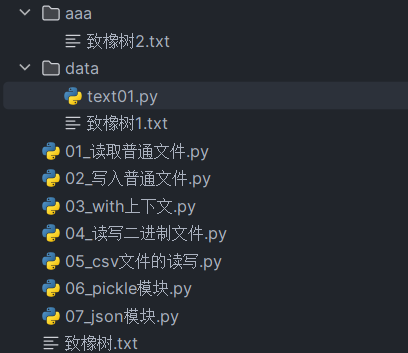
f = open(r"d:/word.txt", "r", encoding="utf-8")- 情况一:如果py文件和txt文件平级,直接写txt文件的名称
- 在文件
01_读取普通文件.py中访问文件致橡树.txt
- 在文件
f1 = open(r"致橡树.txt", "r", encoding="utf-8")- 情况二:如果py文件和txt文件的上级目录平级,则需要从上级目录开始书写
- 在文件
01_读取普通文件.py中访问文件夹aaa中的文件致橡树2.txt
- 在文件
f2 = open(r"aaa/致橡树2.txt", "r", encoding="utf-8")- 情况三:虽然py文件和txt文件都在一个子目录中,只要二者是平级的关系,则可以直接书写文件名
- 在文件夹
data中的text01.py中访问文件致橡树1.txt
- 在文件夹
f3 = open("致橡树1.txt", "r", encoding="utf-8")- 情况四:如果py文件的上级目录和txt文件平级,则需要回退路径,
..表示回退一级- 在文件夹
data中的text01.py中访问文件致橡树.txt
- 在文件夹
f4 = open("../致橡树.txt", "r", encoding="utf-8")- 情况五:如果py文件的上级目录和txt文件的上级目录平级
- 在文件夹
data中的text01.py中访问文件夹aaa中的文件致橡树2.txt
- 在文件夹
f5 = open("../aaa/致橡树2.txt", "r", encoding="utf-8") - 采用绝对路径访问
# 2.读取内容:read()/readline()/readlines() # 一次全部读取完毕,适用于数据量少的文件 # r1 = f1.read() # print(r1) # 一次只能读取一行 # r2 = f1.readline() # print(r2) # 一次性全部读完,同样适用于数据量少的情况的,但是返回列表,每一行内容是列表中的元素,使用较多 r3 = f1.readlines() print(r3)# 3.关闭文件:close() # 关闭文件,为了节约内存空间 f1.close()# 扩展:结合异常读取文件 # FileNotFoundError # ValueError # LookupErrorf = None try: f = open(r'致橡树.txt', 'r', encoding='gbk56') print(f.read()) except FileNotFoundError as e: print("文件路径错误:",e) except ValueError as e: print("打开模式错误:",e) except LookupError as e: print("编码错误",e) finally: if f:f.close()
-
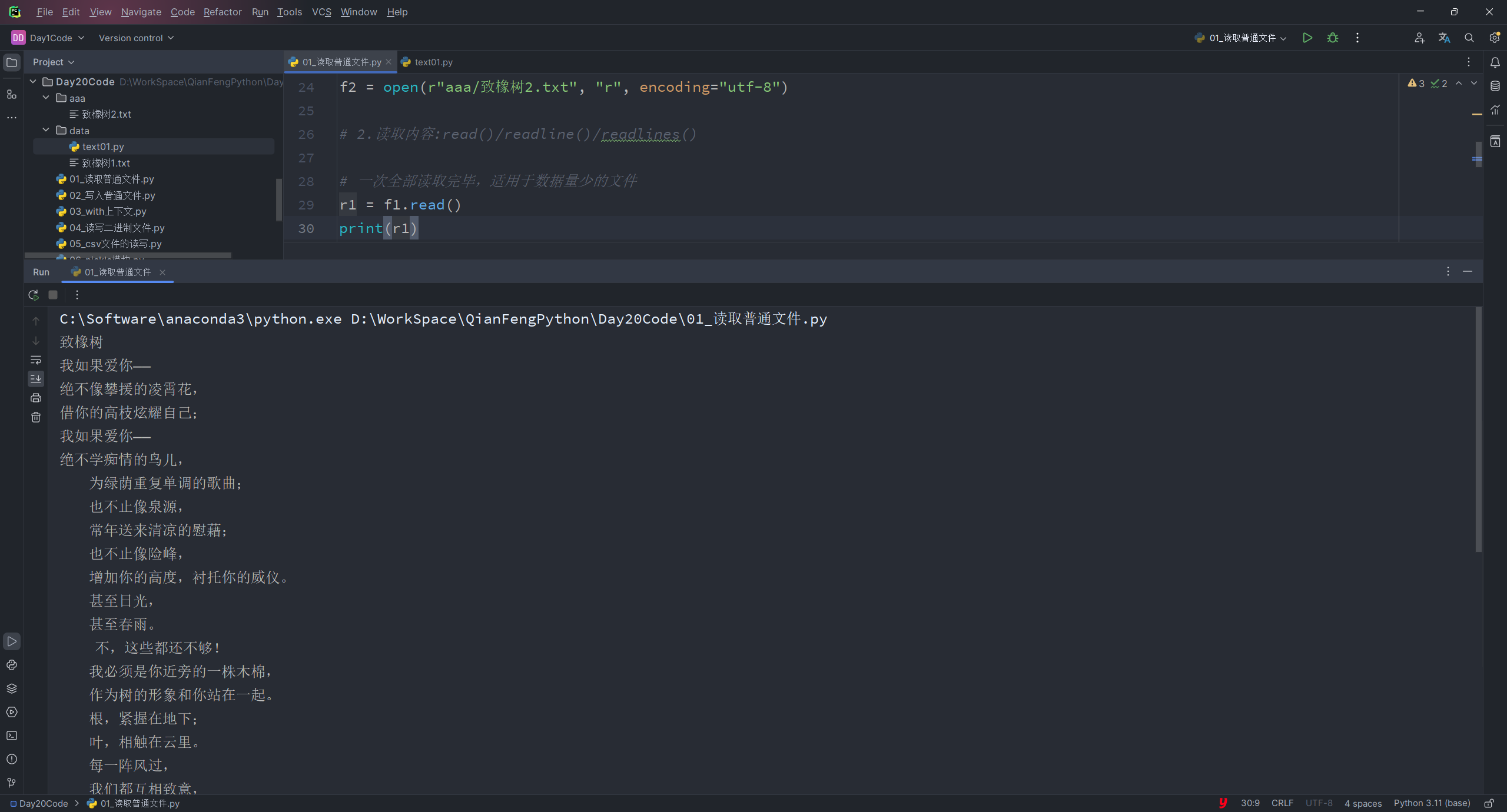
读取文件
read():一次全部读取完毕,适用于数据量少的文件
r1 = f1.read() print(r1)输出结果
readline():一次只能读取一行
r2 = f1.readline() print(r2)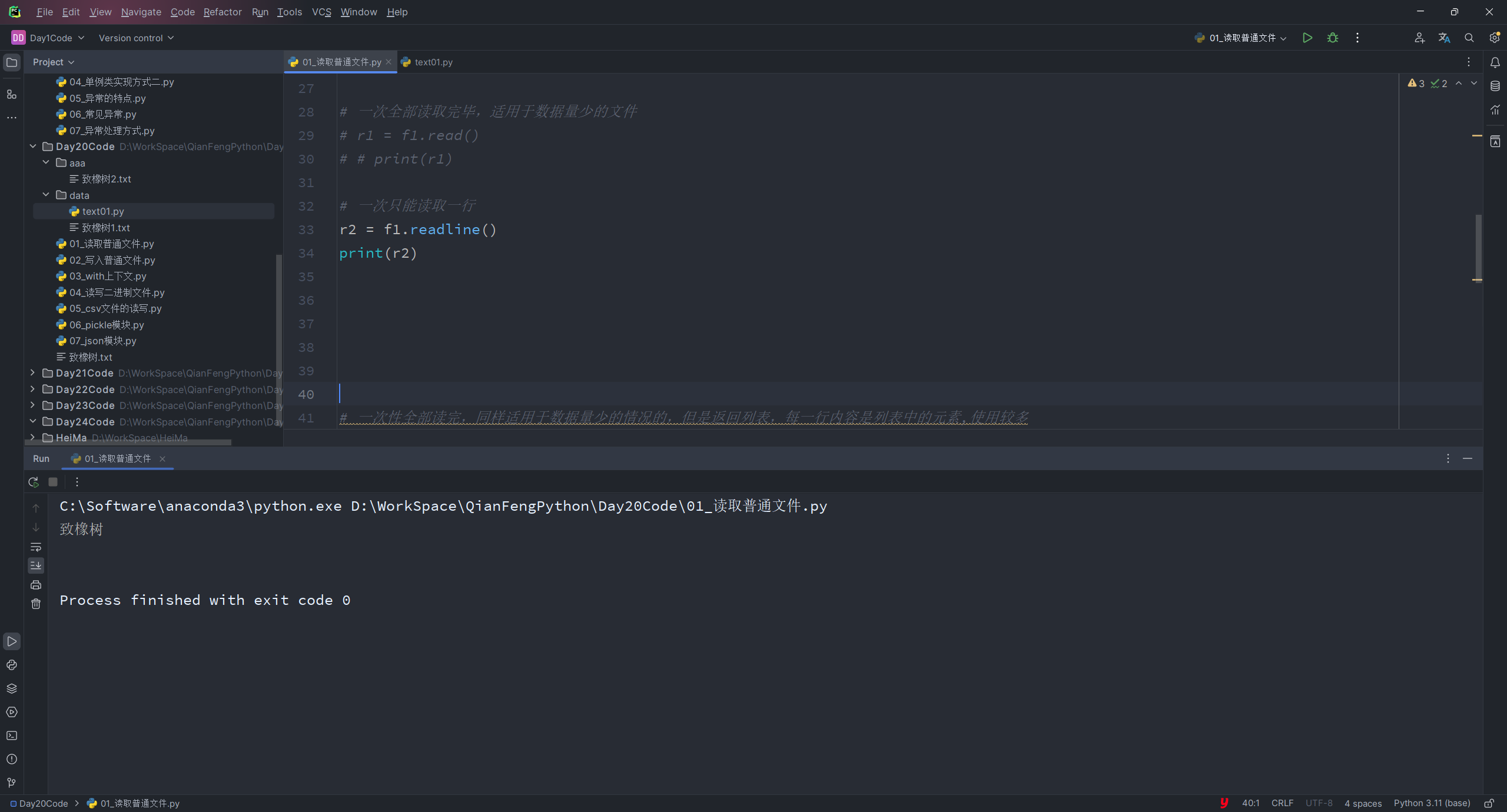
readlines():一次性全部读完,同样适用于数据量少的情况的,但是返回列表,每一行内容是列表中的元素,使用较多
r3 = f1.readlines() print(r3)
-
完整流程
# 1.打开文件:open()
f1 = open(r"致橡树.txt", "r", encoding="utf-8")# 2.读取内容:readlines()
r3 = f1.readlines()
print(r3)# 3.关闭文件:close()
f1.close()
-
拓展
- 在编写中,如果文件名写错,会报异常;模式写错,也会报异常;编码写错,也会报异常。所以可以添加捕获异常的代码
f = None try:f = open("致橡树.txt", "r", encoding="utf-8")read = f.readlines()print(read) except FileNotFoundError as e:print("文件路径错误:", e) except ValueError as e:print("操作模式错误:", e) except LookupError as e:print("编码格式错误:", e) finally:if f:f.close()
1.2 写入
1.2.1 读取文件的操作流程
-
打开文件:
f = open(file,mode,encoding)- 写入文件内容(
w或a)的时候,文件路径可以不存在,自动生成 - 不管是读取还是写入,
encoding的值和源文件的编码格式保持一致 'w':open for writing, truncating the file first,达到了覆盖的效果'a':open for writing, appending to the end of the file if it exit,达到追加内容的效果
- 写入文件内容(
-
读取内容:
write()- 如果需要写入的数据量较大,则可以借助于刷新提高写入效率
xxx.flush()
- 如果需要写入的数据量较大,则可以借助于刷新提高写入效率
-
关闭文件:
close()- 关闭文件,为了节约内存空间
1.2.3 代码演示
# 1.打开文件
# 文件路径存在,直接打开
f2 = open("aaa/file.txt", "w", encoding="utf-8")
# 文件路径不存在,创建并打开
# f2_2 = open("aaa/file2.txt", "w", encoding="utf-8")
# "w"覆盖原文件内容,"a"追加源文件内容
# f2_3 = open("aaa/file2.txt", "a", encoding="utf-8")# 2.写入文件
f2.write("123")# 3.关闭文件
f2.close()
二、with上下文
在实际应用中,进行读写时,往往会忘记最后的关闭操作,所以可以使用with语法,简化代码。
所以也更推荐这种写法
2.1 语法
- 通用语法
with 对象 as 变量:pass
- 在文件读写中
with open() as f:读/写
2.2 说明
- with上下文管理器一般用于简化代码,如:文件读写,数据库操作等
- 使用with上下文管理器进行文件的读写之后,无需手动关闭文件,当with代码块执行完毕,对应的文件会自动关闭
- 变量表示文件描述符,也就是打开的文件对象
- 当通过with的方式打开文件,则文件读取和写入的操作一定要在with代码块中完成,否则文件会被关闭导致无法操作
ValueError: I/O operation on closed file.
2.3 代码演示
# 读取操作
with open("致橡树.txt", "r", encoding="utf-8") as f1:r1 = f1.readlines()print(r1)# 写入操作
with open("aaa/file.txt", "w", encoding="utf-8") as f2:f2.write("123123")
三、二进制文件读写
- 二进制文件:图片,音视频,压缩包等
- 读取和写入二进制文件需要使用
rb和wb'rb':打开二进制文件用于读取'wb':打开二进制文件用于写入
- 因为二进制文件是由二进制(字节,byte)组成,没有编码一说,所以需要省略encoding参数,如果设置encoding,报错
ValueError: binary mode doesn't take an encoding argument
# 读取
with open(r"data/py.jpg", "rb") as f1:data = f1.read()print(data)# 写入
with open(r"data/new_py.jpg", "wb") as f2:f2.write(data)f2.flush()
四、CSV文件读写
4.1 csv文件
- CSV:Comma Separated Values,逗号分隔值
- .csv是一种文件格式(如.txt、.doc等),也可理解.csv文件就是一种特殊格式的纯文本文件。
- 即是一组字符序列,字符之间用英文字符的逗号或制表符(Tab)分隔
- CSV文件本身就是是个纯文本文件,这种文件格式经常用来作为不同程序之间的数据交互的格式
- .csv文件打开方式有多种,如记事本、excel、Notepad++,sublime等,只要是文本编辑器都能正确打开
4.2 读取
- csv文件的读写较为特殊,所以需要借助于系统模块
csv - 读取csv文件时,使用
csv.reader(),返回迭代器
# csv文件的读写较为特殊,所以需要借助于系统模块csv
import csv# 1.读取
with open(r'aaa/t1.csv', 'r', encoding='utf-8') as f1:# 读取csv文件时,使用csv.reader(),返回迭代器reader = csv.reader(f1) # 相当于f1.read()print(reader) # <_csv.reader object at 0x00000209A4FAEF40># 转成列表,获取元素datalist = list(reader)print(datalist)
4.3 写入
- 写入csv文件时,使用
csv.writer(),结合writerow()或writerows()完成写入操作writerow(可迭代对象):写入一行- ``writerows(可迭代对象)`:写入多行
- 如果写入内容之后,每行后面出现了空行,则可以通过设置
newline=''解决
# 如果写入内容之后,每行后面出现了空行,则可以通过设置newline=''解决
with open(r'aaa/t2.csv', 'w', encoding='utf-8', newline='') as f2:# 注意3:写入csv文件时,使用csv.writer(),结合writerow()或writerows()完成写入操作writer = csv.writer(f2)# 注意4:writerow(可迭代对象)或writerows(可迭代对象)# writer.writerow('hello')datalist = [['name', 'age', 'height', 'address'],['张三', '10', '180', '北京'],['李四', '20', '165', '上海'],['王五', '15', '175', '深圳']]# 逐行写入# for data in datalist:# writer.writerow(data)# 一次性写入多行writer.writerows(datalist)
五、对象的序列化和反序列化
Python中一切皆对象
-
对象的序列化:将Python中的对象持久化到磁盘上
-
对象的反序列化:将磁盘上一个文件中的内容转换为Python对象
-
注意事项
- 对象的序列化(写入)和反序列化(读取)通过pickle模块和json模块完成
- Python中一切皆对象,可以使用pickle或json模块的类型:数字,字符串,列表,字典,元组,集合,类,函数,模块等
- pickle可以序列化一切类型,json常用于操作字典和列表
5.1 pickle模块
pickle可以序列化一切类型
需要pickle序列化对象,则文件的打开方式一定要使用wb或rb,类似二进制文件的读写
序列化:pickle.dump(对象,文件对象)
反序列化:pickle.load(文件对象)
需求:将类对象写入文件中,并校验
# 导入模块
import pickle# 创建类
class Person():def __init__(self, name, age):self.name = nameself.age = agedef show(self):print(f"姓名:{self.name},年龄:{self.age}")# 创建类对象
per = Person('张三', 10)# 1.序列化(写入)
# 需要pickle序列化对象,则文件的打开方式一定要使用wb或rb,类似二进制文件的读写
with open(r"data/a1.txt", 'wb') as f:pickle.dump(per, f) # pickle.dump(对象,文件对象)# 2.反序列化(读取),校验
with open(r"data/a1.txt", 'rb') as f:r = pickle.load(f) # pickle.load(文件对象)print(r)print(r.name, r.age)r.show()
5.2 json模块
5.2.1 JSON
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。它以易于阅读和编写的文本形式表示结构化数据,并且可以被多种编程语言解析和生成。JSON最初是由Douglas Crockford在2001年提出的,它在Web开发中得到广泛应用。
JSON数据由键值对组成,类似于Python中的字典或JavaScript中的对象。每个键值对由一个键(key)和对应的值(value)组成,键和值之间使用冒号(:)分隔,键值对之间使用逗号(,)分隔。JSON支持以下数据类型作为值:
- 字符串(string):由双引号括起来的文本。
- 数字(number):整数或浮点数。
- 布尔值(boolean):表示真或假的值。
- 数组(array):由方括号括起来的值的有序列表。
- 对象(object):由花括号括起来的键值对的无序集合。
- 空值(null):表示空值的特殊关键字。
下面是一个简单的JSON示例:
{"name": "John","age": 30,"isStudent": False,"hobbies": ["reading", "coding", "traveling"],"address": {"street": "123 Main St","city": "上海"},"isEmployed": None
}
JSON具有广泛的应用场景,特别是在Web开发中。它常用于在客户端和服务器之间传输数据,以及存储和交换结构化数据。在Python中,可以使用json模块来解析和生成JSON数据。
5.2.2 JSON和Python中数据类型的对应关系
| JSON | Python | 表示 |
|---|---|---|
| object | dict | {} |
| array | list | [] |
5.2.3 代码演示
- 方法说明
如果中文不需要编码,则可以设置ensure_ascii=False
ensure_ascii的默认值为True,表示对中文进行编码
| 序列化 | 说明 |
|---|---|
| json.dump() | 将Python中的字典或列表对象序列化到指定的文件中 |
| json.dumps() | 将Python中的字典或列表对象序列化为json字符串 |
| 反序列化 | 说明 |
| json.load() | 将指定的文件中的json字符串反序列化为Python中的字典或列表对象 |
| json.loads() | 将json字符串反序列化为Python中的字典或列表对象 |
- 原数据,为字典
data = {"name": "John","age": 30,"isStudent": False,"hobbies": ["reading", "coding", "traveling"],"address": {"street": "123 Main St","city": "上海"},"isEmployed": None
}print(data)
print(type(data)) # <class 'dict'>
- 将数据序列化和反序列化
# 导入模块
import json# json.dumps():将Python中的字典或列表对象序列化为json字符串
new_json = json.dumps(data, ensure_ascii=False)
print(new_json)
print(type(new_json)) # <class 'str'># json.loads():将json字符串反序列化为Python中的字典或列表对象
new_data = json.loads(new_json)
print(new_data)
print(type(new_data)) # <class 'dict'>
- 将数据序列化和反序列化(文件操作)
# 导入模块
import json# json.dump():将Python中的字典或列表对象序列化到指定的文件中
with open(r"data/person.json", "w", encoding="utf-8") as f1:json.dump(data, f1, ensure_ascii=False)# json.load():将指定的文件中的json字符串反序列化为Python中的字典或列表对象
with open(f"data/person.json", "r", encoding="utf-8") as f2:new_data = json.load(f2)print(new_data)print(type(new_data)) # <class 'dict'>