LLM相关的6篇重要的论文,其中4篇来自谷歌,2篇来自openai。技术路径演进大致是:SSL (Self-Supervised Learning) -> SFT (Supervised FineTune) == IT (Instruction Tuning) -> RLHF。
word embedding的问题:新词如何处理,新词的embedding如何表征;但LLM根据token或字做输出的方式,很大程度上可以解决这个问题。

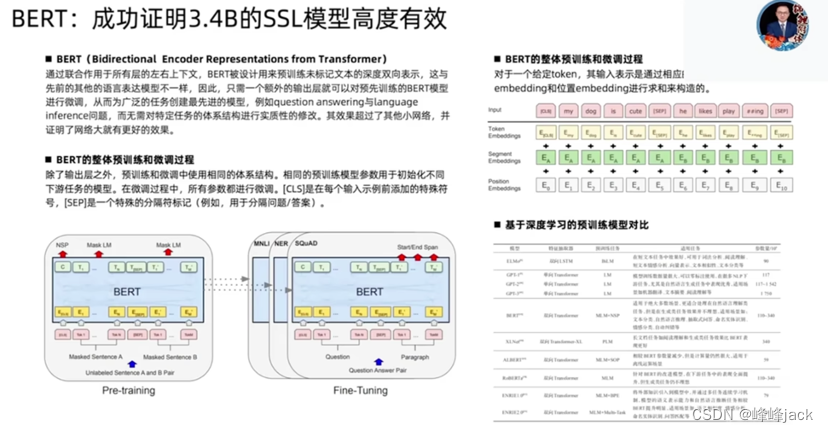
在谷歌有很大的机器资源去调用,使得BERT有机会做成大模型;BERT出来后,NLP之前所有的trick都失效了;BERT证明了大模型这条路是可行的。
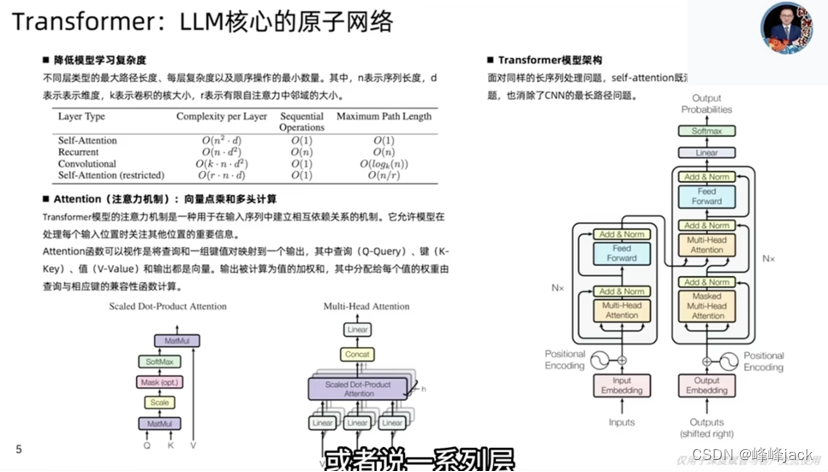
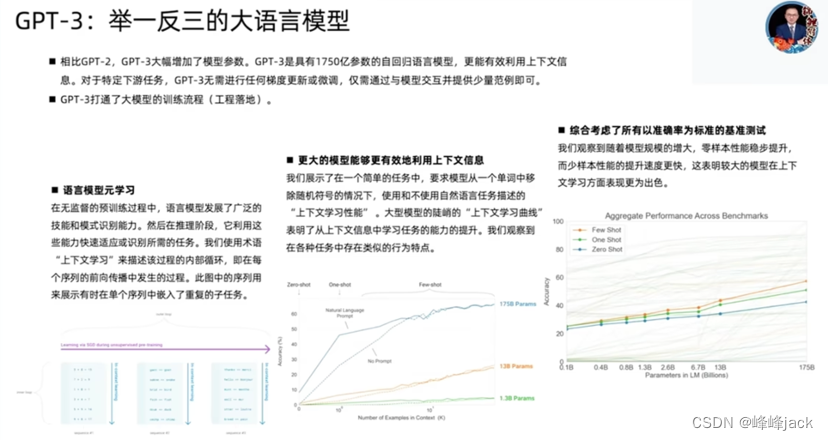
Openai是把所有资源都集中到LLM这一件事情上,集中所有资源于一点,这就是战略选择。
Instruction tuning非常重要,带来了范式的转化。
![[图片]](https://img-blog.csdnimg.cn/direct/ffe6259bc6154c54a18b28d75aa222ec.png)
RLHF将模型毒性从40%降低到0.6%。
![[图片]](https://img-blog.csdnimg.cn/direct/943821d922384d3fb497877512d8b640.png)
GPT3.5 turbo,据业界推测,是个20-30B的蒸馏版本模型
![[图片]](https://img-blog.csdnimg.cn/direct/a1b0110ebeaf4c20a219b5d5d2ce094c.png)
![[图片]](https://img-blog.csdnimg.cn/direct/c51e8bb4f20f4d1eb781dbfb14e82463.png)
GPT有可能会开源,如果是这样,LLM水平面上升,可能会淹没其它很多开源模型。
![[图片]](https://img-blog.csdnimg.cn/direct/03285ca22f8f4e158cdfbc5892f956f2.png)
什么是智能体?智能体= LLM + 记忆 + 规划 + 工具 + 神经 + 直觉
![[图片]](https://img-blog.csdnimg.cn/direct/a6c326c186fe463da08c16b4c905f610.png)
Agent需要有硬件支持,是一个全新的物种。暴露度:编程是63.4%,所以编程在很大程度上也是可被替代的。
![[图片]](https://img-blog.csdnimg.cn/direct/9d837e57b7044fec88ed83c3936e6671.png)
langchain的设计比较糟糕,复杂度太高了;违背了单接口原则。
![[图片]](https://img-blog.csdnimg.cn/direct/f90df0d897944380a11c8e214cf9df9c.png)
更关注MMLU榜单:https://paperswithcode.com/sota/multi-task-language-understanding-on-mmlu
![[图片]](https://img-blog.csdnimg.cn/direct/ab5eff7545c246168a9155208a1aae70.png)
![[图片]](https://img-blog.csdnimg.cn/direct/220b48f31e3c4494a6bf71f6eb4fed02.png)
数据结构和API设计图,有较高价值;LLM具有很强的信息收集、处理能力。一个200w人民币架构师的工作,有可能花几美元就解决。
![[图片]](https://img-blog.csdnimg.cn/direct/26a973100df445cb8ef5246a842518ab.png)
人类在这里主要扮演投资者。
![[图片]](https://img-blog.csdnimg.cn/direct/218de4b91e7343859f7f5853ea42909a.png)