联邦蒸馏中的分布式知识一致性 | TIST 2024
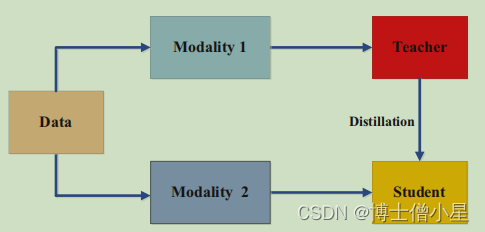
联邦学习是一种隐私保护的分布式机器学习范式,服务器可以在不汇集客户端私有数据的前提下联合训练机器学习模型。通信约束和系统异构是联邦学习面临的两大严峻挑战。为同时解决上述两个问题,联邦蒸馏技术被提出,它在服务器和客户端之间交换知识(模型输出),既支持异构客户端模型,又降低了通信开销。
本文探究了免代理数据集联邦蒸馏方法中的知识不一致性问题,即:由于客户端模型异构的特性,会导致本地知识置信度之间存在显著差异,服务器学习到的表征因此存在偏差,进而降低整个联邦学习系统的性能。
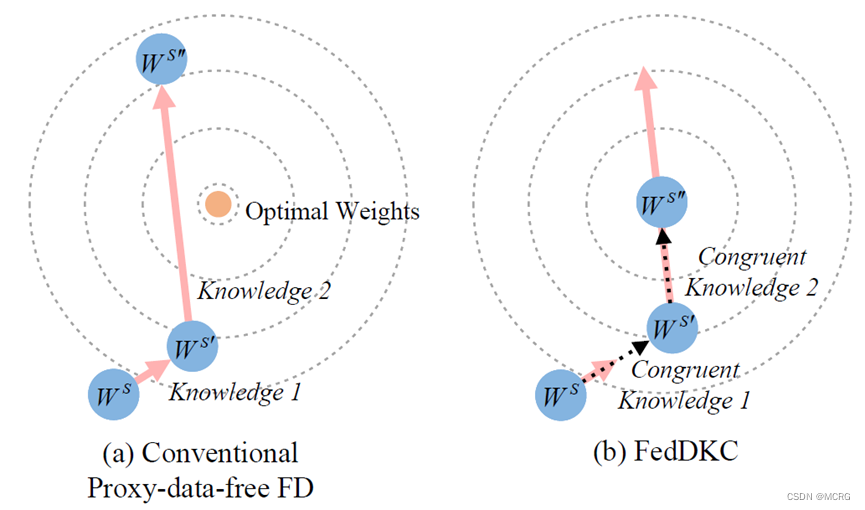
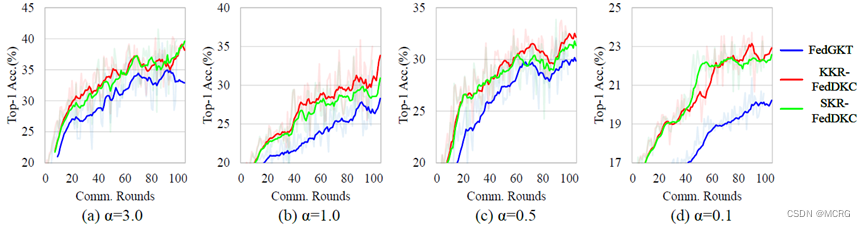
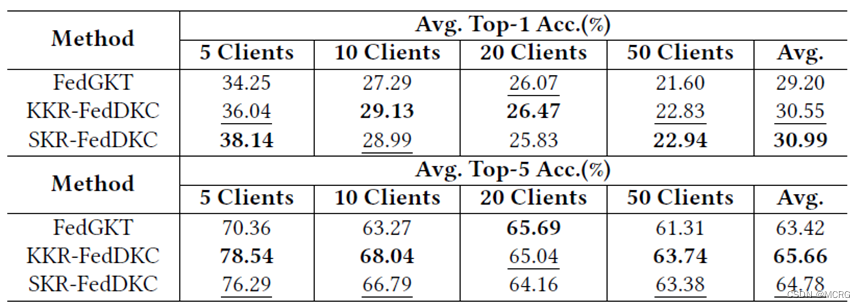
为解决知识不一致带来的准确率下降问题,本文从一个新角度出发:在异构客户端之间实现分布式的知识一致性。论文提出了一种基于分布式知识一致性的无代理数据联邦蒸馏算法FedDKC,它通过精心设计的知识精化策略,将本地知识差异缩小到可接受的上界,以减轻知识不一致的负面影响。具体来说,论文从峰值概率和香农熵两个角度设计了基于核和基于搜索的两种策略,理论上保证优化后的本地知识可满足近似的置信度分布,并被视为一致的。在服务器端蒸馏时基于一致的本地知识,全局模型可以稳定地朝正确的方向收敛,从而帮助客户端提升模型精度。
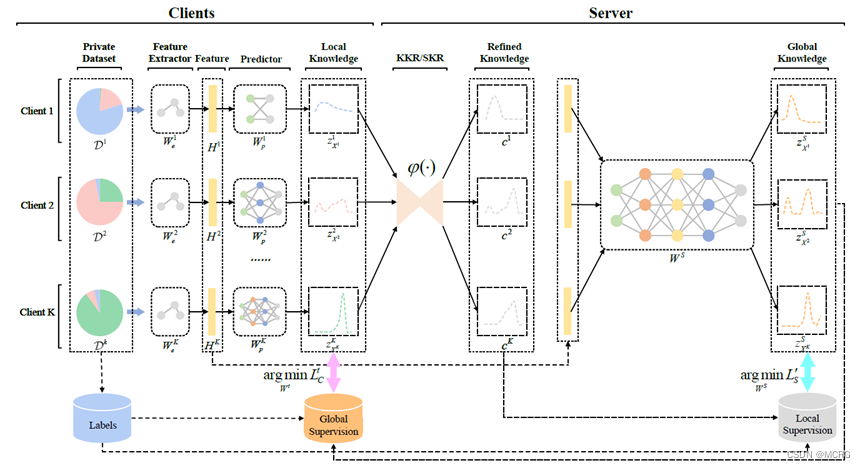
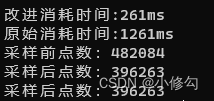
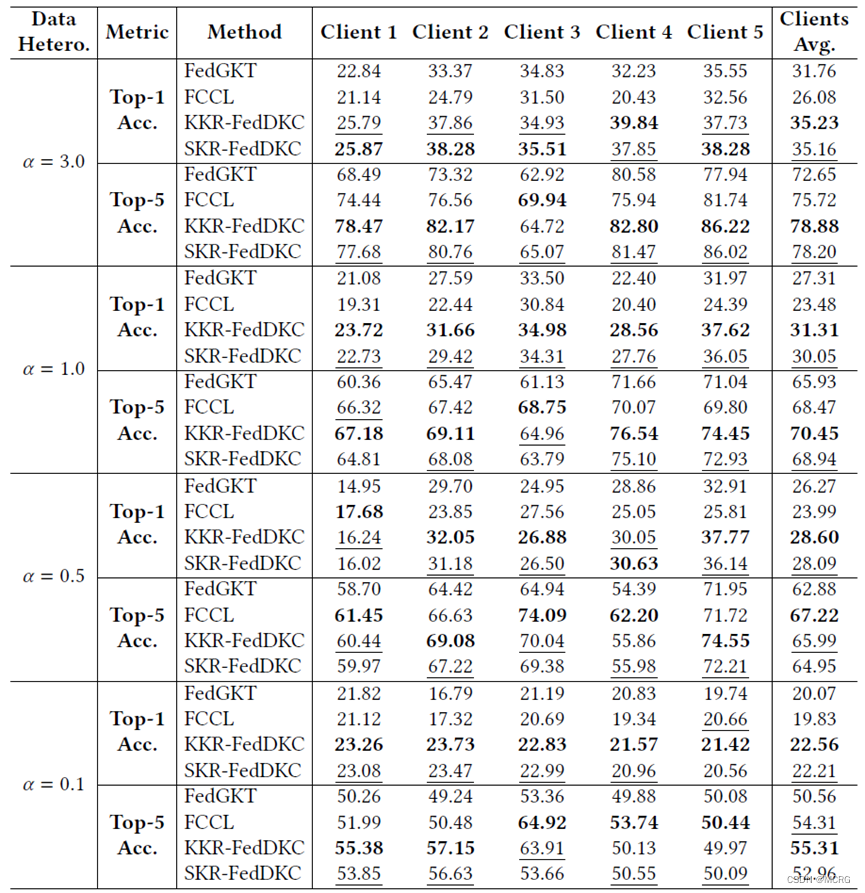
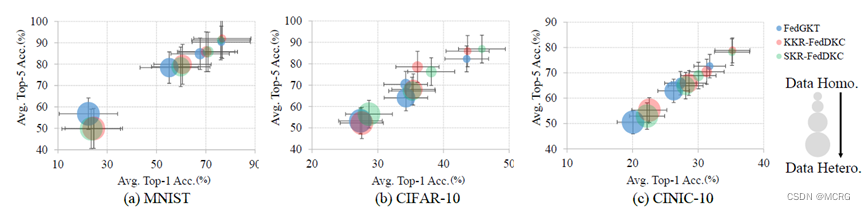
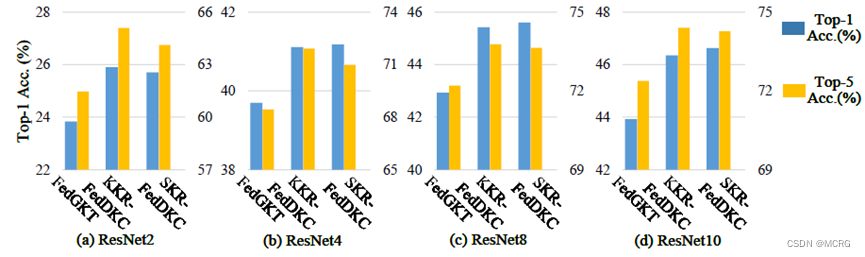
论文在多个公开数据集上开展了实验,结果表明,相比基准算法,FedDKC显著提高了模型异构的设置下准确率,并明显提升了收敛速度。
论文链接:https://arxiv.org/abs/2204.07028