目录
1.Spark 概念
2. Hadoop和Spark的对比
3. Spark特点
3.1 运行速度快
3.2 简单易用
3.3 通用性强
3.4 可以允许运行在很多地方
4. Spark框架模块
4.1 Spark Core
4.2 SparkSQL
4.3 SparkStreaming
4.4 MLlib
4.5 GraphX
5. Spark的运行模式
5.1 本地模式(单机) Local运行模式
5.2 Standalone模式(集群)
5.3 HadoopYARN模式(集群)
5.4 Kubernetes模式(容器集群)
5.5 云服务模式(运行在云平台上)
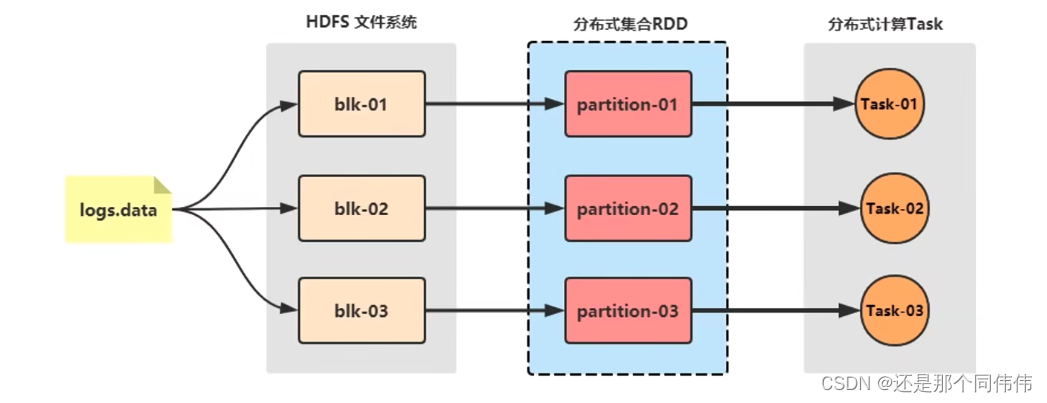
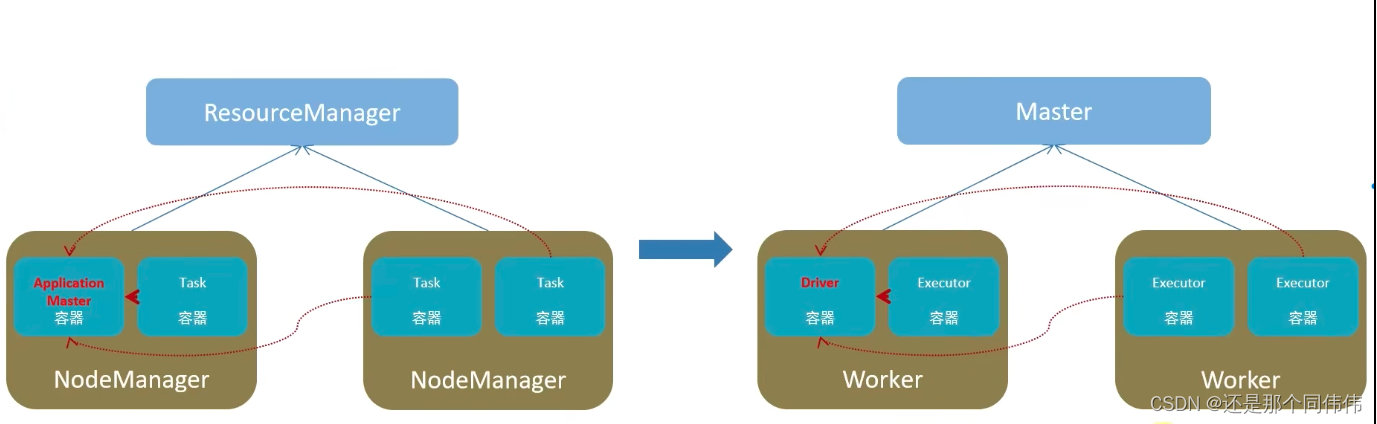
6. Spark架构
6.1 在Spark中任务运行层面
6.2 在Spark中资源层面
1.Spark 概念
- 定义:Apache Spark 是用于大规模数据处理的统一分析引擎
- 其特点就是对任意类型的数据进行自定义计算。
- Spark可以计算:结构化、半结构化、非结构化等各种类型的数据结构,同时也支持使用Python、Java、Scala、R以及SQL语言去开发应用程序计算数据。
- Spark的适用面非常广泛,所以,被称之为统一的(适用面广)的分析引擎(数据处理)
- Spark最早源于一篇论文 Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing, 该论文是由加州大学柏克莱分校的Matei Zaharia等人发表的。论文中提出了一种弹性分布式数据集(即RDD)的概念。
- RDD是一种分布式内存抽象,其使得程序员能够在大规模集群中做内存运算,并且有一定的容错方式。而这也是整个Spark的核心数据结构,Spark整个平台都围绕着RDD进行。
2. Hadoop和Spark的对比
尽管Spark相对于Hadoop而言具有较大优势,但Spark并不能完全替代Hadoop
- 在计算层面,Spark相比较MR(MapReduce)有巨大的性能优势,但至今仍有许多计算工具基于MR构架,比如非常成熟的Hive
- Spark仅做计算,而Hadoop:生态圈不仅有计算(MR)也有存储(HDFS)和资源管理调度(YARN),HDFS和YARN仍是许多大数据体系的核心架构。
3. Spark特点
3.1 运行速度快
Spark处理数据与MapReduce处理数据相比,有如下两个不同点:
- Spark处理数据时,可以将中间处理结果数据存储到内存中;
- Spark提供了非常丰富的算子(APi),可以做到复杂任务在一个Spark程序中完成.
3.2 简单易用
3.3 通用性强
3.4 可以允许运行在很多地方
4. Spark框架模块
4.1 Spark Core
Spark的核心,Spark核心功能均由SparkCore模块提供,是Spark:运行的基础。
SparkCorel以RDD为数据抽象,提供Python、Java、Scala、R语言的API,可以编程进行海量离线数据批处理计算。
4.2 SparkSQL
基于SparkCore之上,提供结构化数据的处理模块。
SparkSQL支持以sQL语言对数据进行处理,SparkSQL本身针对离线计算场景。
同时基于SparkSQL,Spark提供了StructuredStreaming模块,可以以SparkSQL为基础,进行数据的流式计算。
4.3 SparkStreaming
以SparkCore为基础,提供数据的流式计算功能。
4.4 MLlib
以SparkCore为基础,进行机器学习计算,内置了大量的机器学习库和APi算法等。方便用户以分布式计算的模式进行机器学习计算。
4.5 GraphX
以SparkCore为基础,进行图计算,提供了大量的图计算APl,方便用于以分布式计算模式进行图计算。
5. Spark的运行模式
5.1 本地模式(单机) Local运行模式
本地模式就是以一个独立的进程,通过其内部的多个线程来模拟整个Spark运行时的环境
5.2 Standalone模式(集群)
Spark中的各个角色以独立进程的形式存在,并组成Spark:集群环境
5.3 HadoopYARN模式(集群)
Spark中的各个角色运行在YARN的容器内部,并组成Spark集群环境
5.4 Kubernetes模式(容器集群)
Spark中的各个角色运行在Kubernetesl的容器内部,并组成Spark:集群环境
5.5 云服务模式(运行在云平台上)
6. Spark架构
左边是YARN框架,右边是Spark框架
6.1 在Spark中任务运行层面
- Driver, 负责对一个任务的运行进行管理(单个任务的管理)
- Executor,单个任务的计算(干活的)
- 正常情况下Executor是干活的角色,不过特殊场景下,(local模式)Driver可以即管又干活
6.2 在Spark中资源层面:
- Master角色:集群资源管理
- Worker的角色: 单机资源管理
Spark与PySpark(1.概述、框架、模块)


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/217649.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
《PCL多线程加速处理》-滤波-统计滤波
《PCL多线程加速处理》-滤波-统计滤波 一、效果展示二、实现方式三、代码一、效果展示
提升速度随着点云越多效果越明显
二、实现方式
1、原始的统计滤波实现方式
#include <pcl/filters/statistical_outlier_removal.h>pcl::PointCloud<pcl::PointXYZ

vue2-elementUI部分组件样式修改
el-radio样式:
/deep/ .el-radio__input .el-radio__inner {width: 20px;height: 20px;position: relative;cursor: pointer;-webkit-appearance: none;-moz-appearance: none;appearance: none;border: 1px solid #999;border-radius: 0;outline: none;transition…

【C语言】超详解strncpystrncatstrncmpstrerrorperror的使⽤和模拟实现
🌈write in front :🔍个人主页 : 啊森要自信的主页 ✏️真正相信奇迹的家伙,本身和奇迹一样了不起啊! 欢迎大家关注🔍点赞👍收藏⭐️留言📝>希望看完我的文章对你有小小的帮助&am…

张驰课堂:如何应用六西格玛法则优化你的工作流?
作为职场发展的坚实支柱,六西格玛不仅是企业提质增效的利器,同时也是那些渴望在职业生涯中脱颖而出的专业人士的的秘密武器。以下是通过培养个人技能,借助六西格玛优化工作与人生的途径。
团队合作:聚沙成塔的力量
六西格玛教我…

SQL进阶理论篇(四):索引的结构原理(B树与B+树)
文章目录 简介如何评价索引的数据结构设计好坏二叉树的局限性什么是B树什么是B树总结参考文献 简介
我们在上一节中说过,索引其实是一种数据结构,那它到底是一种什么样的数据结构呢?本节将简单介绍一下几个问题:
什么样的数据结…
Vue3-18-侦听器watch()、watchEffect() 的基本使用
什么是侦听器
个人理解:当有一个响应式状态(普通变量 or 一个响应式对象)发生改变时,我们希望监听到这个改变,并且能够进行一些逻辑处理。那么侦听器就是来帮助我们实现这个功能的。侦听器 其实就是两个函数ÿ…
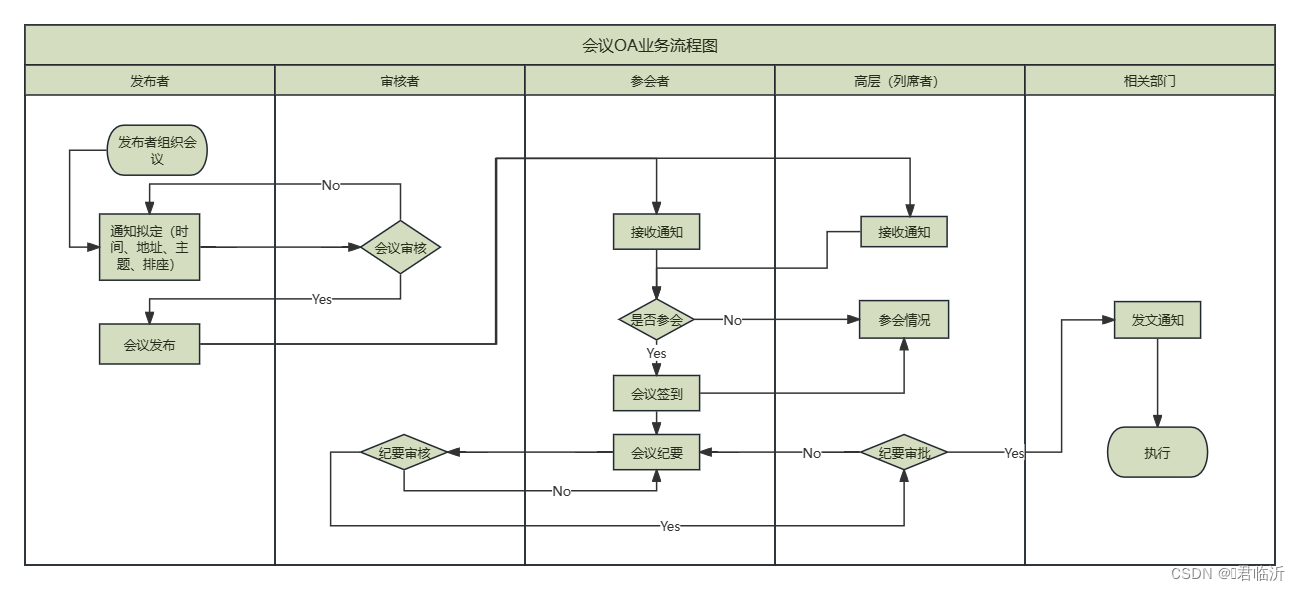
Process On在线绘制流程图
目录 一.ProcessOn
1.1.介绍
1.2.直接网上使用
二.绘制门诊流程图
三.绘制住院流程图
四.绘制药库采购入库流程图
五.绘制OA会议流程图 今天就到这里了哦!!!希望能帮到你哦!!! 一.ProcessOn
1.1.介绍 ProcessOn(流程&#…

智能优化算法应用:基于蝠鲼觅食算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于蝠鲼觅食算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于蝠鲼觅食算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.蝠鲼觅食算法4.实验参数设定5.算法结果6.…

Vue学习计划-Vue2--VueCLi(五)全局事件总线、消息订阅与发布(pubsub)
抛出问题:我们多级组件,或者任意不想关的子组件如何传递数据呢?
1. 全局事件总线($bus) 一种组件间通信的方式,适用于任意组件间通信 全局事件总线示意图: 安装全局事件总线:
new Vue({..…
无人机高空巡查+智能视频监控技术,打造森林防火智慧方案
随着冬季的到来,森林防火的警钟再次敲响,由于森林面积广袤,地形复杂,且人员稀少,一旦发生火灾,人员无法及时发现,稍有疏忽就会酿成不可挽救的大祸。无人机高空巡查智能视频监控是一种非常有效的…
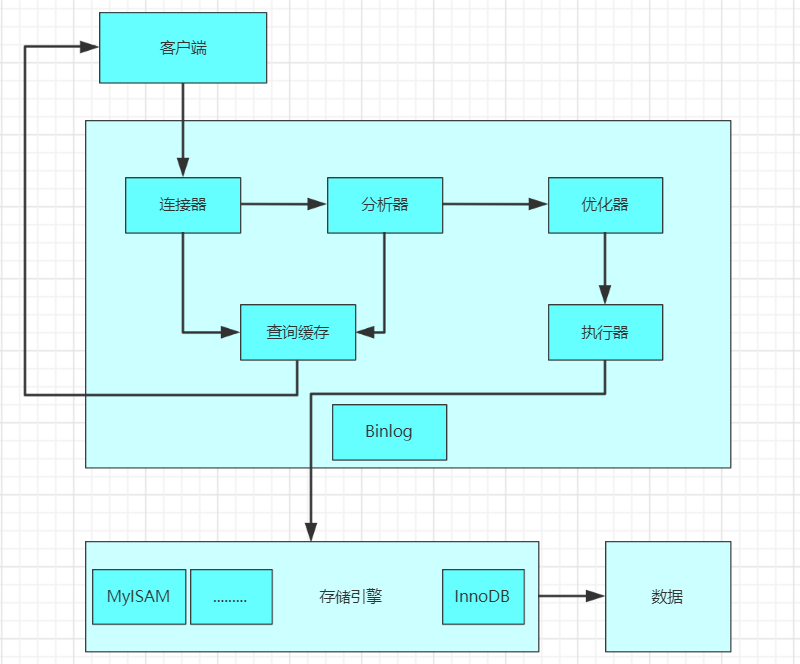
MySQL如何进行Sql优化
(1)客户端发送一条查询语句到服务器;
(2)服务器先查询缓存,如果命中缓存,则立即返回存储在缓存中的数据;
(3)未命中缓存后,MySQL通过关键字将SQ…

19.(vue3.x+vite)v-if和v-for哪个优先级更高
前端技术社区总目录(订阅之前请先查看该博客) v-if和v-for哪个优先级更高
(1)实践中不应该把v-for和v-if放一起,可以包一层template (2)在vue2中,v-for的优先级是高于v-if (3)在vue3中,v-for的优先级是低于v-if
组件代码
<template><div><!--包一…
Hazel引擎学习(十二)
我自己维护引擎的github地址在这里,里面加了不少注释,有需要的可以看看
参考视频链接在这里
这是这个系列的最后一篇文章,Cherno也基本停止了Games Engine视频的更新,感觉也差不多了,后续可以基于此项目开发自己想要…

树莓派,opencv,Picamera2利用舵机云台追踪人脸
一、需要准备的硬件
Raspiberry 4b两个SG90 180度舵机(注意舵机的角度,最好是180度且带限位的,切勿选360度舵机)二自由度舵机云台(如下图)Raspiberry CSI 摄像头 组装后的效果:
二、项目目标…
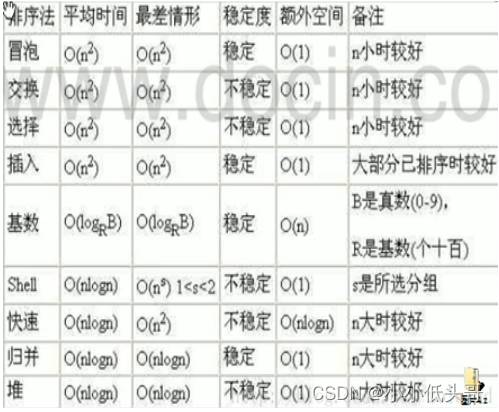
数据结构与算法—排序算法(一)时间复杂度和空间复杂度介绍
排序算法 文章目录 排序算法1.排序算法的介绍1.1 排序的分类 2.算法的时间复杂度2.1 度量一个程序(算法)执行时间的两种方法2.2 时间频度2.2.1 忽略常数项2.2.2 忽略低次项2.2.3 忽略系数 2.3 时间复杂度2.3.1 常见的时间复杂度2.3.1.1 常数阶 O ( 1 ) O(1) O(1)2.3.1.2 对数阶…

Excel高效办公:文秘与行政办公的智能化革新
💂 个人网站:【 海拥】【神级代码资源网站】【办公神器】🤟 基于Web端打造的:👉轻量化工具创作平台🤟 代理 IP 推荐:👉品易 HTTP 代理 IP 💅 想寻找共同学习交流的小伙伴,…
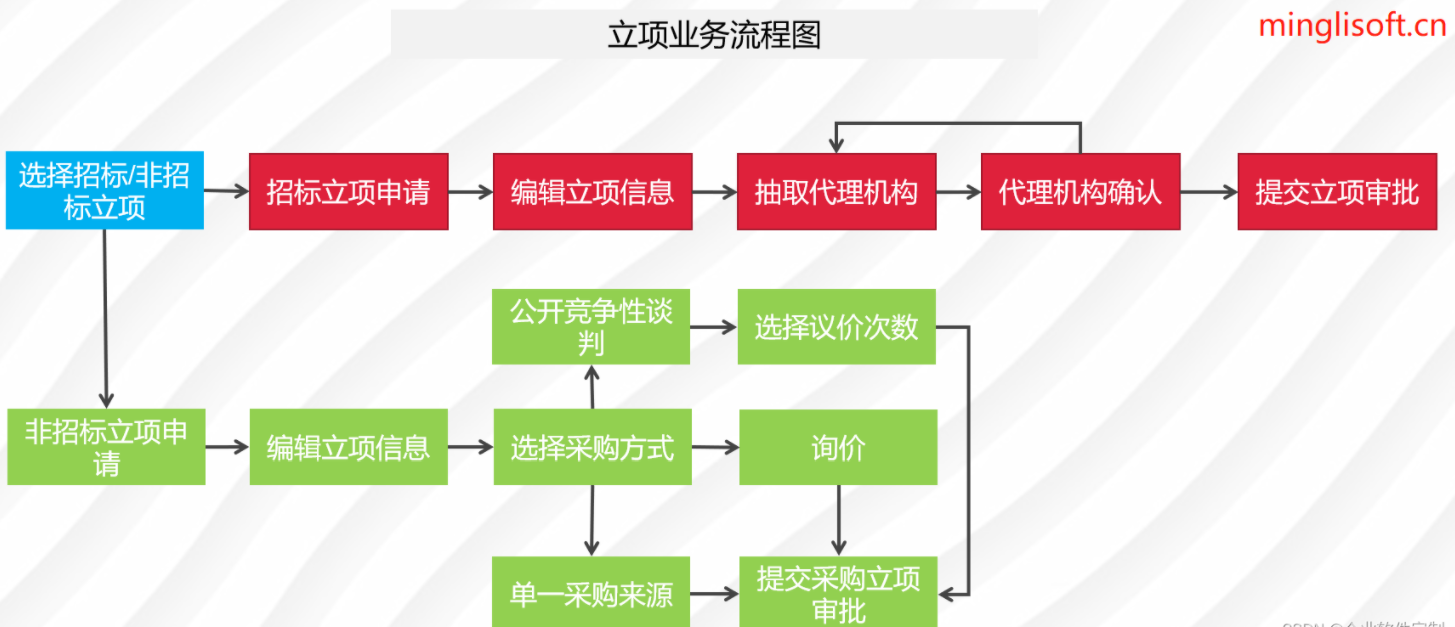
Java版本+鸿鹄企业电子招投标系统源代码+支持二开+Spring cloud +鸿鹄电子招投标系统
项目说明
随着公司的快速发展,企业人员和经营规模不断壮大,公司对内部招采管理的提升提出了更高的要求。在企业里建立一个公平、公开、公正的采购环境,最大限度控制采购成本至关重要。为了符合国家电子招投标法律法规及相关规范࿰…
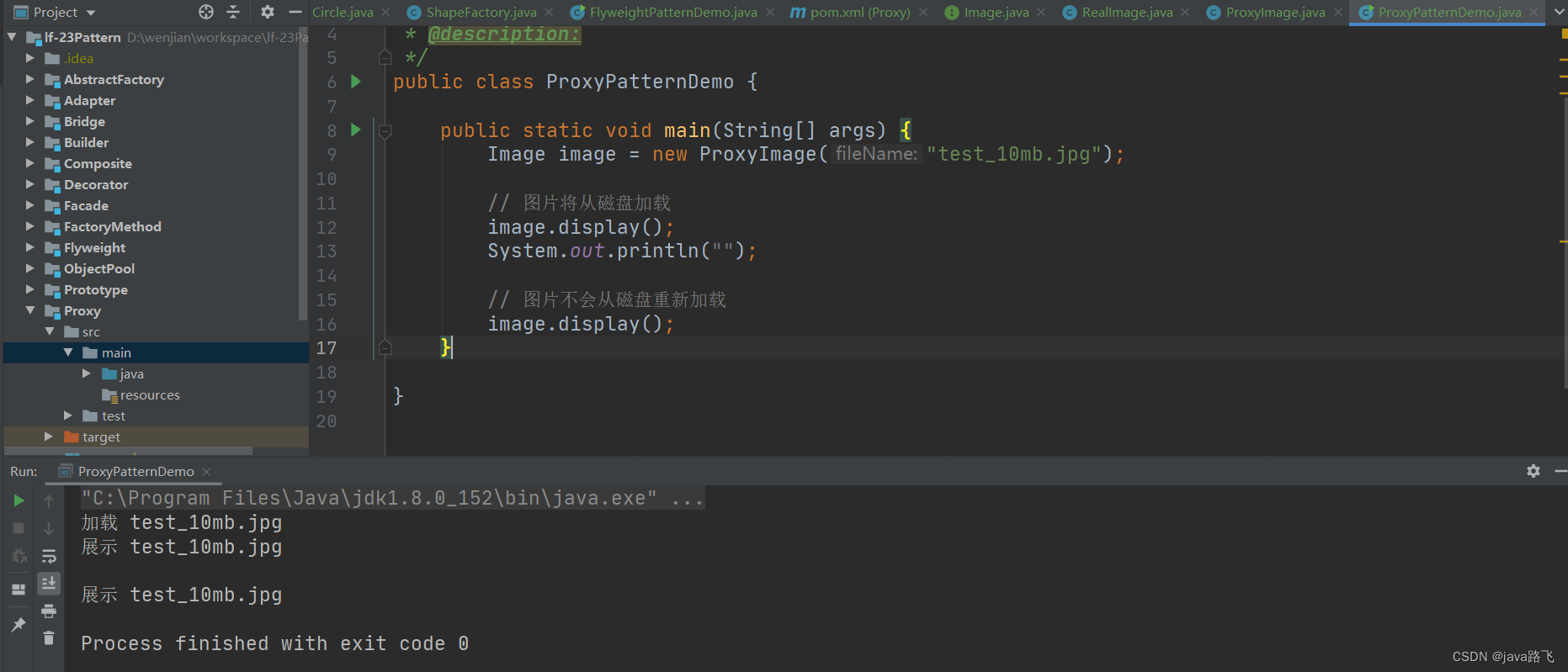
java设计模式学习之【代理模式】
文章目录 引言代理模式简介定义与用途实现方式 使用场景优势与劣势在Spring框架中的应用图片加载示例代码地址 引言
在现实生活中,我们经常使用代理来处理我们不想直接参与或无法直接参与的事务,例如,使用律师来代表法庭上的案件。在软件开发…
![克隆图[中等]](https://img-blog.csdnimg.cn/direct/b88623227d314c23bf96de03d697817b.png)

最新文章
- 自助下单网站怎么做/东莞搜索优化十年乐云seo
- 昆明微网站搭建/社交媒体营销策略有哪些
- 政府网站建设项目背景/网站运营指标
- PHP做的网站能容纳多少人/搜索引擎营销的方法
- wordpress菜单选项如何链接/网站备案流程
- 莆田网站建设方案优化/简述提升关键词排名的方法
- 【小程序】自定义组件的data、methods、properties
- Python 敲电子木鱼,见机甲佛祖,修赛博真经
- 【Android】application@label 属性属性冲突报错
- acitvemq AMQP:因为消息映射策略配置导致的MQTT接收JMS消息乱码问题 x-opt-jms-dest x-opt-jms-msg-type
- 树形查询转成TreeNode[],添加新节点
- viva-bus 航空机票网站 Akamai3 分析
推荐文章
- 银发经济:老龄化社会中的机遇与挑战
- # Go学习-Day3
- #华为推送# 电商应用如何提高用户购买率?推送服务助您一臂之力,现在接入更有专人为您解决技术问题
- #循循渐进学51单片机#1602液晶与串口通信实例#not.12
- (24)(24.1) FPV和仿真的机载OSD(三)
- (5h)Unity3D快速入门之Roll-A-Ball游戏开发
- (c语言进阶)字符串函数、字符分类函数和字符转换函数
- (JavaEE)(多线程案例)线程池 (简单介绍了工厂模式)(含经典面试题ThreadPoolExector构造方法)
- (北京政务服务满意度公司)满意度调查助力服务质量提升
- (长期更新)《零基础入门 ArcGIS(ArcMap) 》实验三----学校选址与路径规划(超超超详细!!!)
- (二十三)大数据实战——Flume数据采集之采集数据聚合案例实战
- (论文解读)Domain Adaptation via Prompt Learning