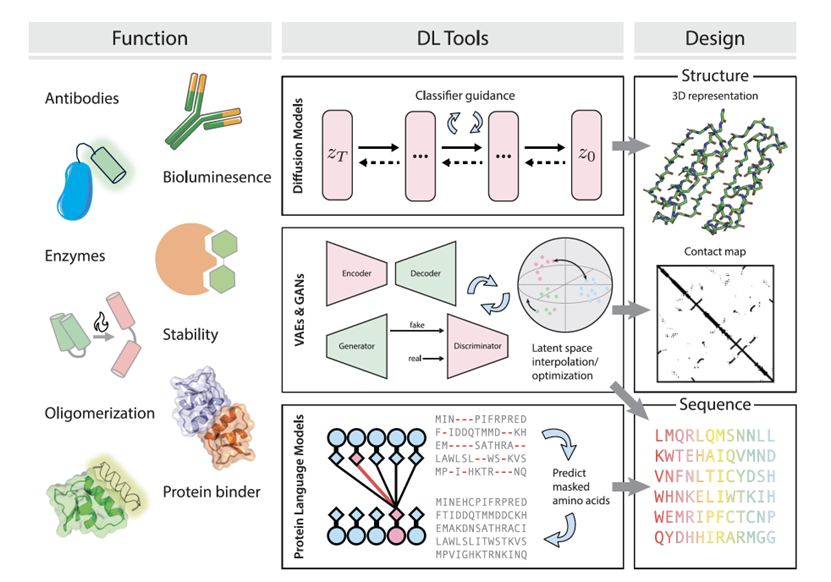
数据库中查询优化器是数据库的核心组件,其决定着 SQL 查询的性能。Cascades 优化器是 Goetz 在 volcano optimizer generator 的基础上优化之后诞生的一个搜索框架。
本期技术贴将带大家了解 Cascades 查询优化器。首先介绍 SQL 查询优化器,接着分析查询优化基本原理,最后对 Cascades 查询优化器进行重点介绍。
一、SQL 查询优化器
用户与数据库交互时只需要输入声明式 SQL 语句,数据库优化器则负责将用户输入的 SQL 语句进行各种规则优化,生成最优的执行计划,并交由执行器执行。优化器对于 SQL 查询具有十分重要的意义。
如图 1 所示,SQL 语句经过语法和词法解析生成抽象语法树(AST),经过基于规则的查询优化(Rule-Based Optimizer)和基于代价的查询优化(Cost-Based Optimizer)生成可执行计划。
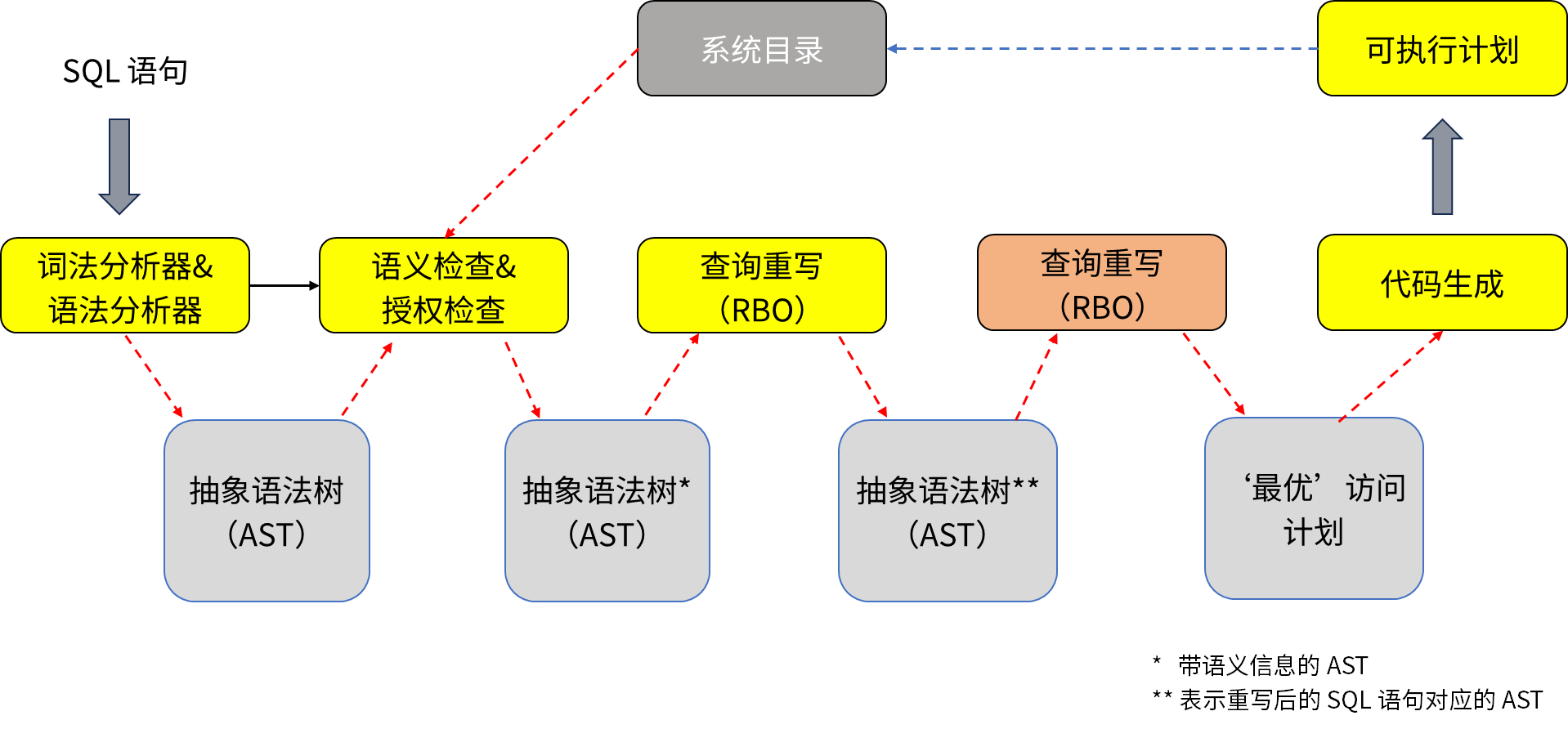
图 1
-
基于规则的优化算法: 基于规则的优化方法的要点在于结构匹配和替换。应用规则的算法一般需要先在关系代数结构上匹配一部分局部的结构,再根据结构的特点进行变换乃至替换操作。
-
基于成本的优化算法: 现阶段主流的方法都是基于成本(Cost)估算的方法。给定某一关系代数代表的执行方案,对这一方案的执行成本进行估算,最终选择估算成本最低的方案。尽管被称为基于成本的方法,这类算法仍然往往要结合规则进行方案的探索。基于成本的方法其实是通过不断的应用规则进行变换得到新的执行方案,然后对比方案的成本优劣进行最终选择。
二、查询优化的基本原理
优化器一般由三个组件组成:统计信息收集、开销模型、计划列举。
如图 2 所示,开销模型使用收集到的统计信息以及构造的不同开销公式,估计某个特定查询计划的成本,帮助优化器从众多备选方案中找到开销最低的计划。
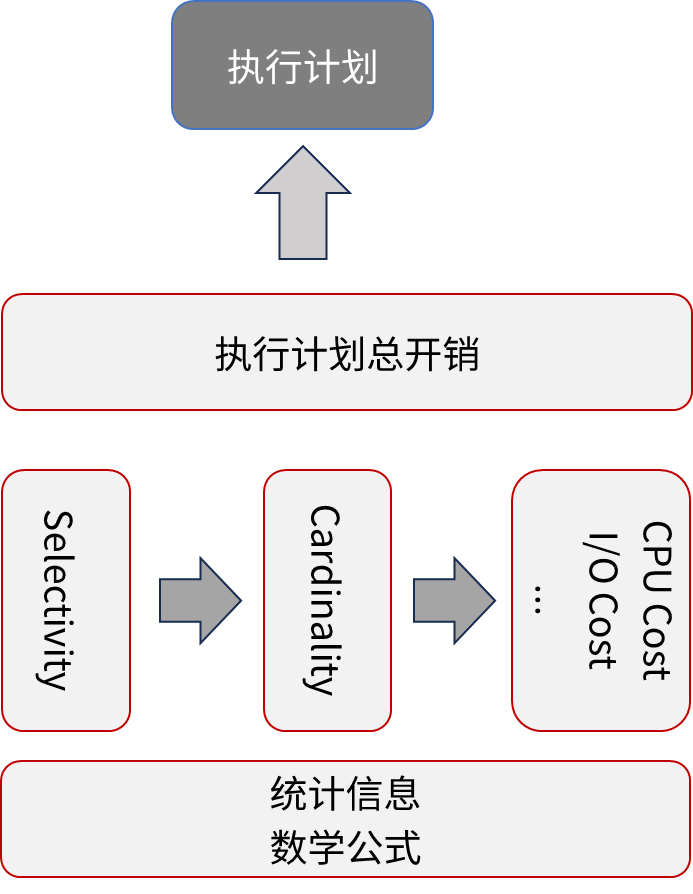
图 2
SQL 语句查询优化基于关系代数这一模型:
-
SQL 查询可以转化为关系代数;
-
关系代数可以进行局部的等价变换,变换前后返回的结果不变但是执行成本不同;
-
通过寻找执行成本最低的关系代数表示,我们就可以将一个 SQL 查询优化成更为高效的方案。
寻找执行成本最低的关系代数表示,可以分为基于动态规划的自底向上和基于 Cascades/Volcano 的自顶向下两个流派。
-
自底向上搜索:从叶子节点开始计算最低成本,并利用已经计算好的子树成本计算出母树的成本,就可以得到最优方案;
-
自顶向下搜索:先从关系算子树的顶层开始,以深度优先的方式来向下遍历,遍历过程中进行剪枝。
自底向上的优化器从零开始构建最优计划,这类方法通常采用动态规划策略进行优化,采用这类方法的优化器包括 IBMSystem R。自顶向下的优化策略的优化器包括基于 Volcano 和 Cascades 框架的优化器。
三、Cascades 查询优化器
Cascades 查询优化器采用自顶向下的搜索策略,并在搜索过程中利用 Memo 结构保存搜索的状态。
Cascades 关键组件构成:
-
Expression:Expression 表示一个逻辑算子或物理算子。如 Scan、Join 算子;
-
Group:表示等价 Expression 的集合,即同一个 Group 中的 Expression 在逻辑上等价。Expression 的每个子节点都是以一个 Group 表示的。一个逻辑算子可能对应多个物理算子,例如一个逻辑算子 Join(a,b),它对应的物理算子包括{HJ(a, b), HJ(b, a), MJ(a, b), MJ(b, a), NLJ(a, b), NLJ(b, a)}。我们将这些逻辑上等价的物理算子称为一个 Group(组)。注:HJ 表示 HashJoin 算子,MJ 表示 MergeJoin 算子,NLJ 表示 NestLoopJoin 算子;
-
Memo:由于 Cascades 框架采用自顶向下的方式进行枚举,因此,枚举过程中可能产生大量的重复计划。为了防止出现重复枚举,Cascades 框架采用 Memo 数据结构。Memo 采用一个类似树状(实际是一个图状)的数据结构,它的每个节点对应一个组,每个组的成员通过链表组织起来;
-
Transformation Rule:是作用于 Expression 和 Group 上的等价变化规则,用来扩大优化器搜索空间。
Cascades 首先将整个 Operator Tree 按节点拷贝到一个 Memo 的数据结构中,Memo 由一系列的 Group 构成,每个算子放在一个 Group,对于有子节点的算子来说,将原本对算子的直接引用,变成对 Group 的引用。

图 3
如图 3 所示,生成该语法树的 Memo 初始结构。Memo 结构中一个圆角框代表一个算子,圆角框右下角是对其 Children’s Groups 的引用,左下角是唯一标识符。生成初始的 Memo 结构后,可以采用 transform rule 进行逻辑等价转换,规则如下:
-
对于一个逻辑算子,其所有基于关系代数的等价表达式保存在同一个 Group 内,例如 join(A,B) -> join(B,A);
-
在一个 Group 内,对于一个逻辑算子,会生成一个或多个物理算子,例如 join -> hash join,merge join,NestLoop join;
-
一个 Group 内,一个算子,其输入(也可以理解为subplan)可以来自多个 Group 的表达式。
在图 4 中,描述了一个部分扩展的 Memo 结构,与图 1 中的初始 Memo 相比,在同一个 Group 内,增加了等价的逻辑算子,以及对应的物理算子。

图 4
在探索的过程中,优化器就会通过开销模型 Coster 借助统计信息来计算子步骤的开销,遍历完每个 Memo Group之后,归总得到每个完整计划的总开销,最终选择 Memo 中开销最低的计划。
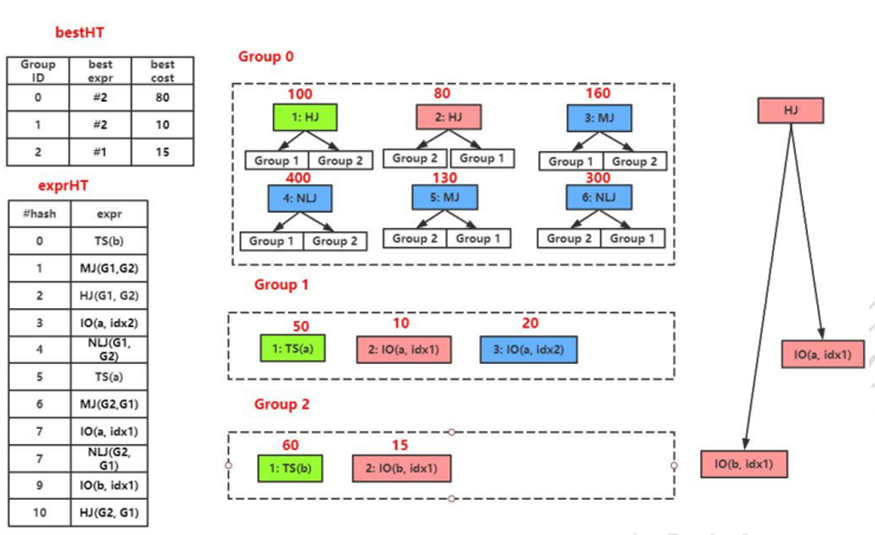
图 5
图 5 中有三个 Group,分别对应三个逻辑算子:Join(a, b), GET(a) 和 GET(b)。Group 1(Group 2)中包含了所有对应 GET(a) (GET(b))的物理算子,我们可以估算每个物理算子的代价,选取其中最优的算子保留下来。
为了防止枚举过程出现重复枚举某个表达式,Memo 结构体中还包含一个哈希表(exprHT),它以表达式为哈希表的键,用来快速查找某个表达式是否已经存在于 Memo 结构体中。
Cascades 采用自顶向下的方式来进行优化,以计划树的根节点为输入,递归地优化每个节点或表达式组。如图所示,整个优化过程从 Group 0 开始,实际上要先递归地完成两个子节点(Group 1 和 Group 2)的优化。
因此,实际的优化完成次序是 Group 1 -> Group2 -> Group 0。在优化每个 Group 时,依次优化每个组员;在优化每个组员时,依次递归地优化每个子节点。依次估算当前组里每个表达式 e 的代价 cost(e),选择最低得代价结果保存在 bestHT 中。优化结束时,查询 Join(a,b)对应的 Memo 结构体,获取最低的执行计划。