1 Load(加载数据)
1.1 概述

1.2 语法
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] [INPUTFORMAT 'inputformat' SERDE 'serde'] (3.0 or later)
1.2.1 filepath

1.2.2 local


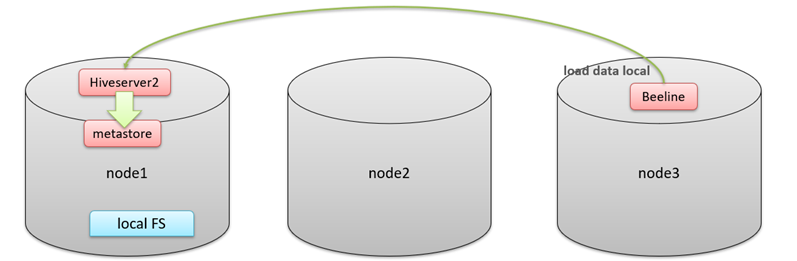
1.2.3 overwrite

1.4 Hive 3.0 Load新特性

CREATE TABLE if not exists tab1 (col1 int, col2 int)PARTITIONED BY (col3 int)row format delimited fields terminated by ',';
--tab1.txt内容如下
11,22,1
33,44,2
LOAD DATA LOCAL INPATH '/root/data/tab1.txt' INTO TABLE tab1;
1.5 案例
1.5.1 创建表
--step1:建表
--建表student_local 用于演示从本地加载数据
create table student_local(num int,name string,sex string,age int,dept string) row format delimited fields terminated by ',';
--建表student_HDFS 用于演示从HDFS加载数据
create external table student_HDFS(num int,name string,sex string,age int,dept string) row format delimited fields terminated by ',';
--建表student_HDFS_p 用于演示从HDFS加载数据到分区表
create table student_HDFS_p(num int,name string,sex string,age int,dept string) partitioned by(country string) row format delimited fields terminated by ',';
1.5.1 加载数据
-- 从本地加载数据 数据位于HS2(node1)本地文件系统 本质是hadoop fs -put上传操作
LOAD DATA LOCAL INPATH '/root/hivedata/students.txt' INTO TABLE student_local;--从HDFS加载数据 数据位于HDFS文件系统根目录下 本质是hadoop fs -mv 移动操作
--先把数据上传到HDFS上 hadoop fs -put /root/hivedata/students.txt /
LOAD DATA INPATH '/students.txt' INTO TABLE student_HDFS;----从HDFS加载数据到分区表中并制定分区 数据位于HDFS文件系统根目录下
--先把数据上传到HDFS上 hadoop fs -put /root/hivedata/students.txt /
LOAD DATA INPATH '/students.txt' INTO TABLE student_HDFS_p partition(country ="China");
2 insert(插入数据)
2.1 insert
执行过程非常非常慢,原因在于底层是使用MapReduce把数据写入Hive表中
create table t_test_insert(id int,name string,age int);
insert into table t_test_insert values(1,"allen",18);
Hive官方推荐加载数据的方式:清洗数据成为结构化文件,再使用Load语法加载数据到表中。这样的效率更高。
2.2 insert+select
- insert+select表示:将后面查询返回的结果作为内容插入到指定表中,注意OVERWRITE将覆盖已有数据。
- 需要保证查询结果列的数目和需要插入数据表格的列数目一致。
- 如果查询出来的数据类型和插入表格对应的列数据类型不一致,将会进行转换,但是不能保证转换一定成功,转换失败的数据将会为NULL。
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;insert into table student_from_insert select num,name from student;
2.3 Multiple Inserts(多次插入)
翻译为多次插入,多重插入,其核心功能是:一次扫描,多次插入。
语法目的就是减少扫描的次数,在一次扫描中。完成多次insert操作。
--当前库下已有一张表student
select * from student;
--创建两张新表
create table student_insert1(sno int);
create table student_insert2(sname string);
--多重插入
from student
insert overwrite table student_insert1
select num
insert overwrite table student_insert2
select name;
2.4 dynamic partition insert(动态分区)
2.4.1 概述
- 动态分区插入指的是:分区的值是由后续的select查询语句的结果来动态确定的。
- 根据查询结果自动分区。动态分区将最后一个字段作为分区
2.4.2 配置参数

set hive.exec.dynamic.partition = true;
set hive.exec.dynamic.partition.mode = nonstrict;<property><name>hive.exec.dynamic.partition</name><value>true</value><description>Whether or not to allow dynamic partitions in DML/DDL.</description>
</property>
<property><name>hive.exec.dynamic.partition.mode</name><value>strict</value><description>In strict mode, the user must specify at least one static partitionin case the user accidentally overwrites all partitions.In nonstrict mode all partitions are allowed to be dynamic.
</description>2.4 insert Directory(导出数据)
2.4.1 概述
Hive支持将select查询的结果导出成文件存放在文件系统中。语法格式如下
注意:导出操作是一个OVERWRITE覆盖操作,慎重。
2.4.2 语法
- 目录可以是完整的URI。如果未指定scheme,则Hive将使用hadoop配置变量fs.default.name来决定导出位置;
- 如果使用LOCAL关键字,则Hive会将数据写入本地文件系统上的目录;
- 写入文件系统的数据被序列化为文本,列之间用\001隔开,行之间用换行符隔开。如果列都不是原始数据类型,那么这些列将序列化为JSON格式。也可以在导出的时候指定分隔符换行符和文件格式。
标准语法
INSERT OVERWRITE [LOCAL] DIRECTORY directory1[ROW FORMAT row_format] [STORED AS file_format]
SELECT ... FROM ...
多重多出
FROM from_statement
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 select_statement1[INSERT OVERWRITE [LOCAL] DIRECTORY directory2 select_statement2] ...导出格式
DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char][MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
10.2.4.3 案例
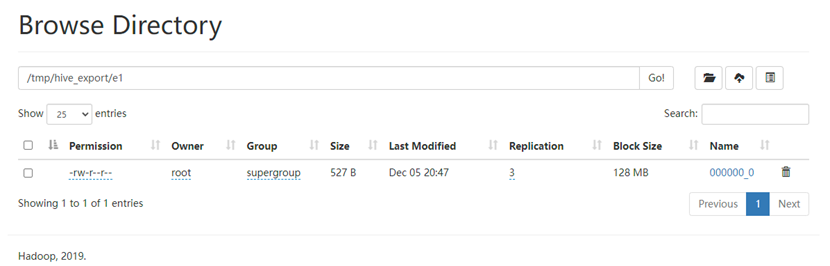
导出到hdfs文件系统
insert overwrite directory '/tmp/hive_export/e1' select * from student;
导出时指定分隔符和文件存储格式
insert overwrite directory '/tmp/hive_export/e2' row format delimited fields terminated by ',' stored as orc select * from student;
导出数据到本地文件系统指定目录下
insert overwrite local directory '/root/data/e1' select * from student;
3 事务表
3.1 实现原理
3.1.1 概述
- Hive的文件是存储在HDFS上的,而HDFS上又不支持对文件的任意修改,只能是采取另外的手段来完成。
- 用HDFS文件作为原始数据(基础数据),用delta保存事务操作的记录增量数据;
正在执行中的事务,是以一个staging开头的文件夹维护的,执行结束就是delta文件夹。每次执行一次事务操作都会有这样的一个delta增量文件夹; - 当访问Hive数据时,根据HDFS原始文件和delta增量文件做合并,查询最新的数据。
3.1.2 目录
- INSERT语句会直接创建delta目录;
- DELETE目录的前缀是delete_delta;
- UPDATE语句采用了split-update特性,即先删除、后插入;
3.1.3 命名格式
- delta_minWID_maxWID_stmtID,即delta前缀、写事务的ID范围、以及语句ID;删除时前缀是delete_delta,里面包含了要删除的文件;
- Hive会为写事务(INSERT、DELETE等)创建一个写事务ID(Write ID),该ID在表范围内唯一;
- 语句ID(Statement ID)则是当一个事务中有多条写入语句时使用的,用作唯一标识。
3.1.4 delta目录下的文件
每个事务的delta文件夹下,都有两个文件:

- _orc_acid_version的内容是2,即当前ACID版本号是2。和版本1的主要区别是UPDATE语句采用了split-update特性,即先删除、后插入。这个文件不是ORC文件,可以下载下来直接查看。
- bucket_00000文件则是写入的数据内容。如果事务表没有分区和分桶,就只有一个这样的文件。文件都以ORC格式存储,底层二级制,需要使用ORC TOOLS查看,详见附件资料。
3.1.5 bucket 文件

- operation:0 表示插入,1 表示更新,2 表示删除。由于使用了split-update,UPDATE是不会出现的,所以delta文件中的operation是0 , delete_delta 文件中的operation是2。
- originalTransaction、currentTransaction:该条记录的原始写事务ID,当前的写事务ID。
- rowId:一个自增的唯一ID,在写事务和分桶的组合中唯一。
- row:具体数据。对于DELETE语句,则为null,对于INSERT就是插入的数据,对于UPDATE就是更新后的数据。
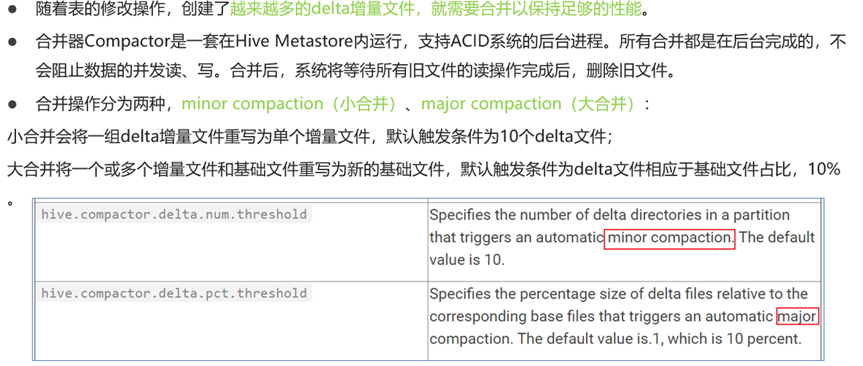
3.1.5 合并器
3.2 局限性

3.3 创建使用
--Hive中事务表的创建使用
--1、开启事务配置(可以使用set设置当前session生效 也可以配置在hive-site.xml中)
set hive.support.concurrency = true; --Hive是否支持并发
set hive.enforce.bucketing = true; --从Hive2.0开始不再需要 是否开启分桶功能
set hive.exec.dynamic.partition.mode = nonstrict; --动态分区模式 非严格
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; --
set hive.compactor.initiator.on = true; --是否在Metastore实例上运行启动压缩合并
set hive.compactor.worker.threads = 1; --在此metastore实例上运行多少个压缩程序工作线程。
--2、创建Hive事务表
create table trans_student(id int,name String,age int
) stored as orc TBLPROPERTIES('transactional'='true');
4 update、delete
只有事务表才可以更新删除。